
Trabajar con reglas de normalización
- Administrador de catalogación
- Gerente de catálogo
- Catalogador
- Para aplicar reglas de normalización a un registro individual, utilice la opción Mejorar registro (consulte la sección Opciones de menú y barra de herramientas del Editor MD) o Aplicar cambios a un registro individual, al usar la función de vista preliminar de las reglas de normalización (consulte Vista preliminar del resultado de una regla).
- Para aplicar reglas de normalización a un conjunto de registros, se debe crear un proceso usando las tareas MarcDroolNormalization o DcDroolNormalization (véase Trabajar con procesos de normalización) y especificar la regla de normalización que se crea con el Editor MD (ir al procedimiento Crear un nuevo fichero de reglas de normalización). Una vez que se haya creado el proceso, se puede ejecutar una tarea usando dicho proceso (véase Ejecutar tareas manuales en conjuntos definidos). Además, puede crear un proceso que habilite aplicar las reglas de normalización cuando se hace clic en Guardar en el Editor MD (consulte Trabajar con los procesos de normalización).
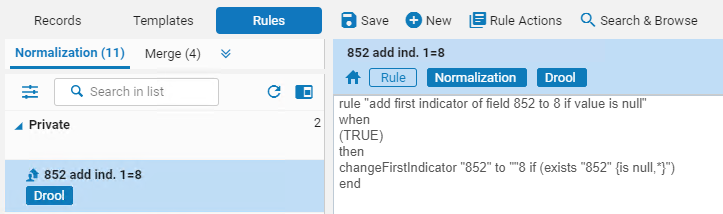
- Ver las reglas de normalización y los registros de metadatos unos junto a otros
- Tener una vista preliminar del resultado de una regla al ejecutarla en un registro de metadatos
- Alternar entre la regla y los cambios de la vista preliminar
- Editar reglas y probarlas de inmediato
- Para obtener una descripción general breve de las Reglas de normalización, véase Reglas de normalización (6:00).
- Para obtener información detallada sobre las Reglas de normalización con ejemplos, vea Reglas de normalización (1 hora).
Crear Reglas de normalización
- En la página del Editor MD (Recursos > Catalogación > Abrir editor de metadatos), abra el Área de reglas.
- Para crear una regla de normalización para un registro MARC o Dublin Core, seleccione Nuevo > Normalización. Se abrirá el cuadro de diálogo Propiedades de reglas de normalización (nueva regla).
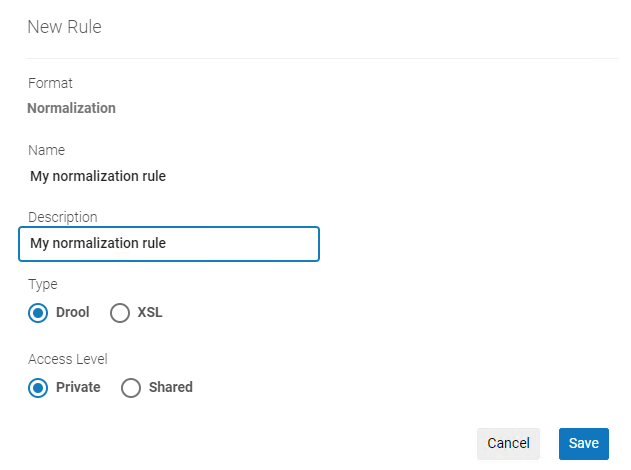 Cuadro de diálogo Propiedades de reglas de normalización
Cuadro de diálogo Propiedades de reglas de normalización - Introducir un nombre y una descripción para la regla de normalización.
La palabra "regla" no debe estar en mayúscula si se utiliza en el nombre de la regla. Si se escribe con mayúsculas, la regla no funcionará.
¡No use una barra invertida (\) en el nombre de una regla! Si lo hace, la regla no se podrá usar para la funcionalidad del conjunto de filtros. - Para crear una regla de normalización para un registro MARC, seleccione Drool. Para crear una regla de normalización para un registro DC (Dublin Core), seleccionar 'XSL'.
- Seleccionar una opción de acceso, Privado o Compartido Si se selecciona Privado, solo usted podrá trabajar en la regla y dicha regla no podrá incluirse en un proceso de normalización. Si se selecciona Compartido, la regla será compartida entre los catalogadores. En este caso, más de un usuario podrá ver la regla al mismo tiempo y, si dos o más personas tienen la regla abierta para editarla, aparecerá un mensaje de advertencia cuando alguna intente guardar los cambios. (Existe la opción de conservar los cambios propios o permitir que el otro usuario realice y guarde sus propios cambios.)
- Seleccionar Guardar. Se abre el panel de edición del Editor MD.
Puede incluir sintaxis de reglas existentes (Editar > Añadir regla > {type of rule}) o definir una regla (para obtener detalles, véase Sintaxis de reglas de normalización). - Seleccionar Guardar. La regla se añade a la lista de ficheros de reglas en la pestaña Reglas de normalización.
- En la página del Editor MD (Recursos > Catalogación > Abrir el editor de metadatos), seleccione la pestaña Reglas y expanda la carpeta de Normalización.
- Para copiar, abrir la carpeta Comunidad. Hacer clic derecho sobre la regla que se desea copiar y seleccionar Duplicar.
Se abre el diálogo de Duplicar regla. Indicar su nombre y descripción, e indicar si se desea guardar como regla privada (disponible sobre para usted) o compartida (disponible para todos los usuarios en su institución).
El nombre y el correo electrónico de contacto del usuario de Alma que contribuyó la regla a la ZC se indican en el diálogo; se puede contactar a este usuario en caso de tener preguntas. - Para realizar su propia contribución a la ZC, hacer clic derecho sobre la regla y seleccionar Contribuir a la ZC.
Se abre el diálogo de Compartir regla. Proporcionar un nombre descriptivo y una descripción, y seleccionar Guardar para guardar la regla en la ZC.
- En la página del Editor MD (Recursos > Catalogación > Abrir el editor de metadatos), seleccione la pestaña Reglas y expanda la carpeta Normalización para mostrar las reglas guardadas.
- Seleccionar la regla con la que se desea trabajar y seleccionar una de las siguientes opciones:
- Editar – Abre el cuadro de texto con la sintaxis de la(s) regla(s) que permite su modificación (para más detalles, véase Sintaxis de reglas de normalización).
- Borrar – Seleccionar Sí para confirmar la eliminación del fichero de reglas.
- Duplicar – Duplica la regla seleccionada y permite modificarla y guardarla como una nueva regla, sin afectar la regla original.
- Propiedades – Abre el cuadro de diálogo Propiedades de reglas de normalización, permitiendo modificar las propiedades del fichero de reglas.
- Para cambiar el nombre de la regla, duplicar la regla, dar el nombre deseado al duplicado y luego borrar la regla vieja.
- Ubicar el registro bibliográfico con el que se desea trabajar (usando la pestaña Búsqueda en el repositorio o dentro del Editor MD > Registros) y abrirlo en el Editor MD.
- Pulse (F6) o seleccione el icono Dividir editor.
- Seleccione la pestaña Reglas en el panel izquierdo y expanda la carpeta Normalización.
- Seleccione con el botón derecho la regla para la que desea obtener una vista preliminar o que quiere probar en la carpeta Privado o Compartido (no Comunidad) y seleccione Editar.
La regla se muestra en el panel derecho del Editor de metadatos.
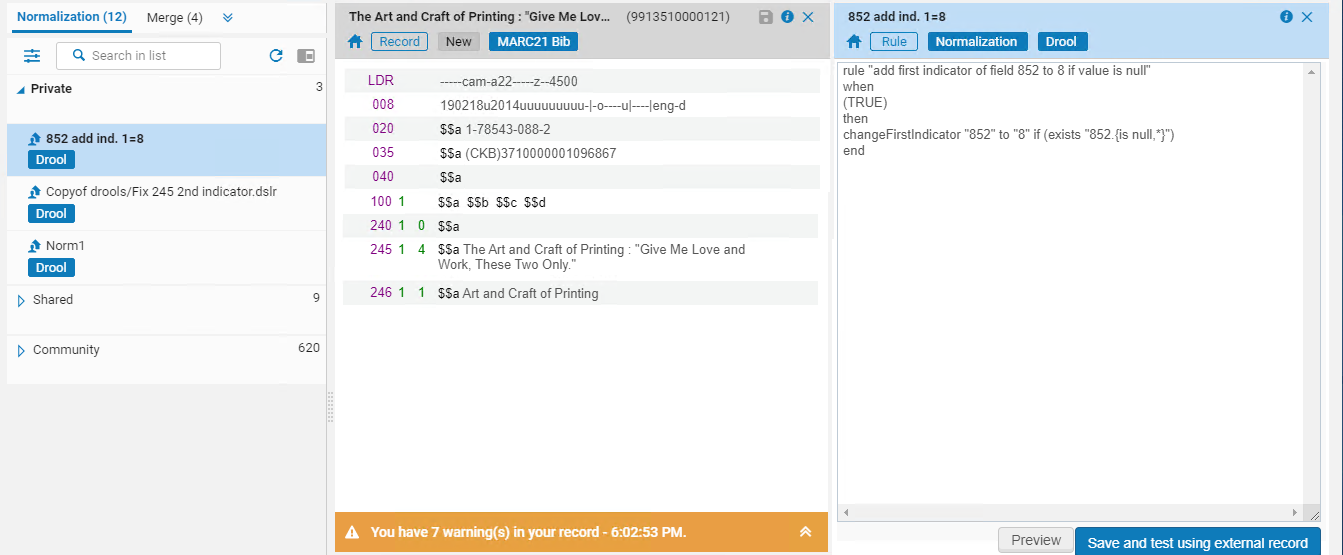
- Seleccionar Vista preliminar. La regla se aplica al registro y aparece el resultado.
Para actualizar registros de Red, la normalización debe ser ejecutada por la institución de la Red (no por un miembro). Una institución no puede actualizar registros de Red, por lo tanto, la normalización se aplicará solo en los campos locales (las extensiones locales del miembro). En la vista preliminar de una regla para un registro de red, se muestra el siguiente mensaje: Se debe tener en cuenta que las reglas se aplicarán solo a los campos locales cuando se ejecute el proceso de normalización.
- Seleccionar Aplicar cambios para guardar las modificaciones del registro o seleccionar Regresar a reglas de normalización para realizar más ediciones.
- Cuando se hayan realizado los cambios finales a la regla de normalización, seleccionar Guardar y probar utilizando un registro externo para guardar la versión final de la regla de normalización. Para obtener detalles, véase Probar reglas de normalización para fuentes de datos externos.
Reglas de normalización para registros de Dublin Core
En el Editor de metadatos, existen los siguientes tipos de reglas relacionadas con Dublin Core:
- Reglas de indicación XSL
- Regla de normalización XSL
La Regla de normalización de XSL no admite discovery:local.
Las Reglas de normalización de Dublin Core no se pueden escribir en un formato de Regla de normalización habitual, solo como un XSL. Esto significa que se redacta el XSL directamente en el Editor de metadatos (como se explicó anteriormente), o bien se puede redactar en Notepad (u otra aplicación externa que se elija) y luego copiarla al Editor de metadatos.
Se pueden ver los siguientes ejemplos de Reglas de normalización de XSL en la Zona de la Comunidad, en el Editor de metadatos:
- EXL: Cambiar el valor dc:language en a Inglés
- EXL: Regla genérica que reemplaza la secuencia en el registro Dublin Core
- EXL_Add_field_accessRights
- Escribir el XSL en la aplicación externa que se elija.
- Abra el Editor de metadatos > sección de Reglas.
- Copiar y pegar el XSL en el Editor de metadatos y guardar la regla.
Reglas de normalización para Primo VE y Esploro.
Además de las reglas de normalización de Alma, puede crear reglas de normalización para Primo VE y Esploro. Para crear estas reglas, clicar Nueva y luego seleccionar:
-
Normalización (Descubrimiento) - Esta opción aparece solo si Primo VE está definido en el sistema. Seleccionar esta opción si se crearán reglas de normalización DC o XML para registros bibliográficos cargados en Primo VE y no gestionados en Alma. Para obtener información sobre la sintaxis de estas reglas, véase Sintaxis de reglas de normalización para formatos DC y XML.
-
Normalización (Investigación) - Esta opción aparece solo si Esploro está definido en el sistema. Para obtener más detalles, véase Gestionar reglas de normalización de activos (Esploro).
Sintaxis de las reglas de normalización
(<conditions on MARC record>) then
Action
End
- “When” debe ser la única palabra en la primera línea. La condición debe ubicarse en una línea separada.
- Puede usar múltiples condiciones en el registro completo solo en la condición "Cuando". Cada regla debe tener solo una acción (después de la línea "Entonces"). Si desea usar varias acciones después de la línea "Entonces", divida esto en varias reglas, cada una con una sola acción.
- Aunque se permite incluir varios operadores booleanos en las reglas, cuando son seleccionados un gran número de operadores booleanos, es probable que el rendimiento se ralentice. Por lo tanto, cada regla debe incluir como máximo 200 operadores booleanos.
- Si no se especifica, la condición funcionará a nivel de registro. Si desea que la condición funcione en cada campo MARC21 por separado, deberá especificar la condición por campo. Por ejemplo, cuando hay varios campos MARC21 con la misma etiqueta.
- \b
- \t
- \n
- \f
- \r
- \"
- \'
- \\
-
reemplazar \\\ con \\
-
reemplazar \. con .
-
reemplazar \ con \\
-
reemplazar \( con (
-
reemplazar \) con )
-
reemplazar \\\| con \\|
Elementos de registro
| Expresión | Significado |
|---|---|
| "<tag>", "<new tag>" | Representa una etiqueta de campo, por ejemplo, 001, 245, etc. |
| "<oldCode>", "<newCode>" | Representa un código de subcampo, por ejemplo, a, b, c. |
| "<element>" para un campo de datos | Los siguientes son valores posibles para el campo de datos:
|
| "<element>" para un campo de control | Los siguientes son valores posibles para un campo de control:
|
| "<elemento>" para un campo de posición fija. |
Los siguientes son valores posibles para un campo de posición fija UNIMARC/CNMARC 1XX:
Relevante solo para campos UNIMARC/CNMARC 1XX. |
| CONDICIÓN a nivel del registro | Las siguientes son opciones de condición posibles. Consultar la siguiente sección (Condiciones) para conocer información importante.
Las siguientes son las posibles opciones de condición relevantes solo para campos UNIMARC/CNMARC 1XX:
|
Condiciones
- Cláusula WHEN – Una condición que debe ser satisfecha por el registro entero para determinar si la regla se aplica al registro
- IF (dentro de una acción) – Una condición que se aplica a un único campo para determinar si la acción específica debe llevarse a cabo en ese campo
-
containsScript: Use esta condición pra detectar un idioma específico. La condicióncontainsScript usa la siguiente lista fija de idiomas para los cuales puede revisar: Árabe, armenio, bengalí, bopomofo, braille, buhid, canadiense_aborigen, cherokee, cirílico, devanagari, etíope, georgiano, griego, gujarati, gurmukhi, han, hangul, hanunoo, hebreo, hiragana, heredado, kannada, katakana, khmer, lao, latín, limbu, malayalam, mongol, myanmar, ogham, oriya, rúnico, cingalés, siríaco, tagalog, tagbanwa, taiLe, tamil, telugu, thaana, tailandés, tibetano y yi. Véase el ejemplo siguiente de sintaxis:regla "Es CJK en autoridad"
cuando
containsScript "Han" "1**"
entonces
establecer indicación."verdadero"
fin -
exists <element> – Se encuentra al menos una coincidencia
- exists <element> – Se aplica a los campos de datos. Al utilizarla en una cláusula IF, tanto el elemento de la acción como el elemento evaluado por la condición deben ser el mismo campo (de datos).
- existsControl <element> – Se aplica a los campos de control. Al utilizarla en una cláusula IF, tanto el elemento de la acción como el elemento evaluado por la condición deben ser el mismo campo (de control).
-
existsMoreThanOnce <element> – Se encuentran múltiples coincidencias. Se aplica a campos de datos. Al utilizarla en una cláusula IF, tanto el elemento de la acción como el elemento evaluado por la condición deben ser el mismo campo (de datos).
-
not exists <element> – No se encuentran coincidencias
- not exists <element> – Se aplica a los campos de datos. Al utilizarla en una cláusula IF, tanto el elemento de la acción como el elemento evaluado por la condición deben ser el mismo campo (de datos).
- not existsControl <element> – Se aplica a los campos de control. Al utilizarla en una cláusula IF, tanto el elemento de la acción como el elemento evaluado por la condición deben ser el mismo campo (de control).
-
recordHasDuplicateSubfields (para reglas de indicación, véase Trabajar con reglas de indicación) – Devuelve el valor verdadero si se encuentran subcampos duplicados (subcampo y sus contenidos) para el registro actual según los campos, subcampos y los caracteres a ignorar (charsToIgnore) cadena que se pasó como parámetros en el siguiente formato:recordHasDuplicateSubfields "<tag>" "<code>" "<charsToIgnore>"Se pueden especificar múltiples etiquetas (campos) separados por comas. Se pueden especificar múltiples códigos (subcampos) sin espacios para separarlos. Uno o más caracteres (alfanumérico o puntuación) sin espacios de separación se pueden especificar como caracteres que se ignorarán al final del contenido en los subcampos que se evalúan para duplicar. Véase Ejemplo 6 para más información.Se crea un conjunto de registros que cumplen con la condición recordHasDuplicateSubfields (devuleve el resultado verdadero).
- Se aplica si una condición específica no es verdadera, por ejemplo: addControlField "{element}" if(not exists "{condition}")
- Se aplica si una condición específica es verdadera, por ejemplo: addControlField "{element}" if(exists "{condition}")
- Se aplica incondicionalmente, por ejemplo: addControlField "{element}"
Lista de acciones
| Acción | Formato / Ejemplo | Comentario |
|---|---|---|
| Reemplazar campos y subcampos con otros campos y subcampos |
changeControlField "<tag>" to "<new tag>"
Ejemplo: changeControlField "007" to "008"
|
Cambia el identificador de etiqueta de un campo controlado; no modifica los contenidos. |
|
changeField "<tag>" to "<new tag>"
Ejemplo: changeField "245" to "246"
|
Cambia el identificador de etiqueta; no modifica los indicadores ni los subcampos. | |
|
changeSubField "<tag>.<code>" to "<new code>"
changeSubFieldOnlyFirst "<tag>.<code>" to "<new code>"
changeSubFieldExceptFirst "<tag>.<code>" to "<new code>"
Ejemplo: changeSubField "035.b" to "a"
|
Cambia los subcampos (o solo el primer subcampo, o todos excepto el primer subcampo) "<code>" por el subcampo "<new code>" en el campo "<tag>". | |
|
changeFirstIndicator "<tag>" to "<value>"
changeSecondIndicator "<tag>" to "<value>"
Ejemplo: changeFirstIndicator "245" to "3"
|
Establece el valor del indicador especificado en la etiqueta <tag>. | |
|
combineFields "<tag>" excluding "<comma-separated subfield list>"
Ejemplo: combineFields "852" excluding "a,b"
|
Combinar todos los campos del número especificado. Copiar todos los subcampos de la segunda línea y las subsiguientes líneas a la primera línea, excluyendo los subcampos nombrados; solo las primeras ocurrencias de los subcampos excluidos son copiadas, y solo si no existen ya en la primera línea. | |
| Añadir campos y subcampos |
addField "<tag>.<code>.<value>"
addField "<tag>.{<ind1>,<ind2>}.<code>. <value>"
Ejemplo: addField "999.a.RESTRICTED"
|
Añadir el campo al registro MARC. Establecer el valor indicado como el valor del subcampo. |
|
addControlField "<tag>.<value>"
Ejemplo: addControlField "008.820305s1991####nyu###########001#0#eng##"
|
Añade el campo controlado al registro MARC. | |
|
addSubField "<tag>.<code>.<value>"
addSubField "<tag>.{<ind1>,<ind2>}.<code>.<value>"
Ejemplo: addSubField "245.h.[Journal]"
|
Añade el subcampo <code> con el valor <value> al campo <tag>. Si el campo no existe, no se hace nada. | |
|
addSystemNumber "<element>" from "<tag>" prefixed by "<prefix tag>"
Ejemplo: addSystemNumber "035.a" from "001" prefixed by "003"
|
Iguala el campo de datos <element> a los contenidos del segundo campo de control <prefix tag> entre paréntesis seguido de los contenidos del primer campo de control <tag>.
Por ejemplo: si 001 tiene el valor 9945110100121 y 003 tiene el valor DAV, la condición del ejemplo a la izquierda producirá 035 con el valor ‡(DAV)9945110100121.
|
|
| Copia campos |
copyField "<tag>" to "<new tag>"
copyField "<tag>.<code>" to "<new tag>.<new code>"
copyField "<tag>" to "<new tag>.{<ind1>,<ind2>}"
Ejemplo: copyField "971.a" to "100.u"
|
Copia el campo a otro campo. En la primera versión, los subcampos no están especificados (<code> y <new code>), y el nuevo campo contiene los mismos subcampos que el campo anterior. En la segunda versión, si tan solo <new code> no está especificado, el nuevo subcampo es igual al especificado para <code>.
copyField crea un campo separado en lugar de agregarlo a un campo existente. Puede que se desee combinar el nuevo campo con un campo combinado (consultar combineFields).
|
| Elimina campos y subcampos |
removeControlField "<tag>"
Ejemplo: removeControlField "009"
|
Elimina todas las ocurrencias del campo controlado.
Tenga en cuenta que si elimina el campo de control 008, Alma vuelve a crearlo inmediatamente si usted no lo hace. Considere volver a añadir el campo después de eliminarlo, por ejemplo: Regla"remove 008"
si (VERDADERO) luego removeControlField "008" addControlField "008.######s2013####xx######r#####000#0#eng#d" fin |
|
removeField "<tag>"
Ejemplo: removeField "880"
|
Elimina todas las ocurrencias del campo <tag>. | |
|
removeSubField "<tag>.<code>"
Ejemplo: removeSubField "245.h"
|
Elimina todas las ocurrencias del subcampo <code> del campo indicado. | |
| Substituye texto en campos o subcampos |
replaceControlContents "<tag>.{<position>,<length>}. <value>" with "<new value>"
Ejemplo: replaceControlContents "LDR.{7,1}.s" with "m"
|
Reemplaza <value> por "<new value>" en la posición inicial <position> hasta <position>+<length> del campo de control <tag>. Substituye solo el texto que coincide con <value>. |
|
replaceContents "<tag>.<code>.<value>" with "<new value>"
replaceContentsOnlyFirst "<tag>.<code>.<value>" with "<new value>"
replaceContentsExceptFirst "<tag>.<code>.<value>" with "<new value>"
Ejemplo: replaceContents "245.h.[Journal]" with "[Book]"
|
Substituye las cadenas coincidentes (o cada instancia de la cadena coincidente en el primer subcampo coincidente, o todas las cadenas coincidentes en todos los subcampos coincidentes excepto el primer subcampo coincidente) <value> en el subcampo <code> del campo "<tag>" con "<new value>". La cadena o parte de la cadena que no coincida con <value> no se modificará. | |
|
replaceSubFieldContents "<tag>.<code>" with "<tag>.<code>"
Ejemplo: replaceSubFieldContents "245.b" with "100.a"
|
Substituye los contenidos del subcampo por contenidos de otro subcampo. | |
|
replaceFixedContents "<tag>.{<1_ind>,<2_ind>}.<code>.{<position>,<length>}.<value>" with "<new value>" Example: replaceFixedContents "100.{1,2}.a.{0,8}.20150226" with "20220724" |
Reemplaza <valor> por <valor nuevo> en campos de posición fija UNIMARC y CNMARC. Relevante solo para campos UNIMARC/CNMARC 1XX. |
|
| Añade texto en subcampos
|
prefix "<tag>.<code>" with "<value>"
Ejemplo: prefix "035.b" with "(OCoLC)"
|
Añade un prefijo al valor del subcampo "<code>"en el campo "<tag>".
El nuevo valor será <value> seguido del valor anterior.
|
|
prefixSubField "<tag>.<code>" with "<source tag>.<source code>"
Ejemplo: prefixSubField "910.a" with "906.a"
|
Añade el valor del subcampo "<source code>" en el campo "<source tag>" como prefijo del subcampo "<code>" en el campo "<tag>".
El nuevo valor será el valor del subcampo "<source code>" en el campo "<source tag>" seguido del valor anterior.
|
|
|
suffix "<tag>.<code>" with "<value>"
Ejemplo: suffix "035.b" with "(OCoLC)"
|
Añade un sufijo al valor del subcampo "<code>" en el campo "<tag>".
El nuevo valor será el valor anterior seguido de <value>.
|
|
|
suffixSubField "<tag>.<code>" with "<source tag>.<source code>"
Ejemplo: suffixSubField "910.a" with "907.c"
|
Añade el valor del subcampo "<source code>" en el campo "<source tag>" como sufijo del subcampo "<code>" en el campo "<tag>".
El nuevo valor será el valor anterior seguido del valor del subcampo "<source code>" en el campo "<source tag>".
|
|
| Mantener información de agencia en registros bibliográficos y de autoridad
Por ejemplo, esta sintaxis puede usarse en reglas de normalización que estén seleccionadas en la Lista de tareas de configuración de metadatos bibliográficos MARC 21 para normalizar los registros bibliográficos de la Zona de red al guardar.
Esta función está en construcción. Para activar esta sintaxis, contactar al soporte de Ex Libris.
|
addCreatingAgency "<tag>.<code>"
Ejemplo: addCreatingAgency "040.a"
|
Añade el código ISIL de la agencia creadora al subcampo "<code>" en el campo "<tag>". |
|
addModifyingAgency "<tag>.<code>"
Ejemplo: addModifyingAgency "040.d"
|
Añade el código ISIL de la agencia modificadora al subcampo "<code>" en el campo "<tag>". Si ya hay una agencia modificadora en "<tag>.<code>", añade otro código ISIL de agencia. | |
|
replaceModifyingAgency "<tag>.<code>"
Ejemplo: replaceModifyingAgency "040.d"
|
Añade el código ISIL de la agencia modificadora al subcampo "<code>" en el campo "<tag>". Si ya existen agencias modificadoras en "<tag>.<code>", son todas substituidas. | |
| Dividir subcampos |
splitSubField "<tag>.{ind1,ind2}.<code>.<delimiter>" to "<tag>.{<ind1>,<ind2>}.<code>" addSeq "<code>"
Ejemplo 1: splitSubField "866.a.;" to "555.{0,0}.a" addSeq "8"
Ejemplo 2: splitSubField "555.a.;" – " to "859.{0,0}.a" addSeq "8"
Ejemplo 3: splitSubField "859.a.\\\\."
Ejemplo 4: splitSubField "999.a.;" to "555.a" addSeq "8"
|
La etiqueta es obligatoria.
Los indicadores son opcionales.
Dado que la división se produce en el nivel del subcampo, el código es obligatorio.
El delimitador puede ser cualquier cadena. Si el delimitador no existe, el subcampo completo se copia como la primera (y única) ocurrencia, y la secuencia es añadida.
El componente to es opcional. Si está especificado, se crean múltiples ocurrencias del tag.code to, cada una con los datos hasta el delimitador. Ver los ejemplos 1 y 2. Si el componente to no está especificado, el subcampo se divide en los mismos subcampos adicionales en el mismo campo, como se muestra en el ejemplo 3.
El componente addSeq es opcional. No es relevante si el componente to no está especificado. Cuando se especifica addSeq, el subcampo con una secuencia será añadido como en el ejemplo 1; y si el subcampo ya existe en el campo original, una secuencia (precedida de un punto) se añadirá a ese campo, como en el ejemplo 2.
|
|
correctDuplicateSubfields "<tag>" "<code>" Ejemplo: Elimina los subcampos duplicados x, y, z de los campos 610 y 630. |
Corrige los subcampos duplicados (por ejemplo, subcampos con el mismo código Y valor) manteniendo el primero y eliminando los demás del registro actual según los campos y subcampos que se hayan pasado como parámetros. Se puede usar recordHasDuplicateSubfields para crear el conjunto de la regla de normalización que utiliza correctDuplicateSubfields. Véase Ejemplo 6 para más información. Para la deduplicación de subcampos con valores diferentes, véase: |
|
|
moveSubfieldsToEndOfField "<tag>" "<code>" Ejemplo: Mueve los subcampos 9 y 2 al final del campo 650. |
Mueve la primera ocurrencia de cada subcampo al final del campo y elimina las demás ocurrencias del mismo subcampo. Si se especifica más de un subcampo, estos se colocan al final en la misma secuencia, según se indique en la regla. En este ejemplo, el subcampo 9 se coloca al final seguido del subcampo 2. Tenga en cuenta que la declaración si no es compatible con la acción moveSubfieldsToEndOfField. |
|
|
Corregir campos duplicados del registro actual |
correctDuplicateFields "{fields}" Ejemplo: correctDuplicateFields "610,630,650" |
Esta acción toma un parámetro, campos, que contiene valores de campos separados por coma como 610,630,650. Esta acción corrige campos duplicados del registro actual de acuerdo a los campos que se aprobaron como parámetros. |
|
Buscar campos duplicados (Reglas de indicación; véase Trabajar con reglas de indicación) |
recordHasDuplicateFields "{fields}" Ejemplo: correctDuplicateFields "610,630,650" |
Esta acción toma un parámetro, campos, que contiene valores de campo separados por coma como 610,630,650. Esta acción puede ser verdadera o falsa. El resultado es verdadero si se encuentran campos duplicados en el registro actual de acuerdo a los campos que se aprobaron como parámetro. |
Comodines y caracteres especiales
when
(TRUE)
then
replaceContents "300.a.1 v\\\\." with "Leaves"
end
when
(exists '245.{*, }.c.\"')
then
replaceControlContents "008.{7,4}" with "2016"
end
when
((exists '260.{*, }.c.תשע\\"ו') OR (exists '264.{*, }.c.תשע\\"ו'))
then
replaceControlContents "008.{7,4}" with "2016"
end
- No pueden usarse comodines como primer carácter de una condición o un valor.
- Para usar una barra invertida (\) como tal, utilizar una barra adicional para escaparla: \\.
- Utilizar cuatro barras invertidas (\\\\) para escapar un punto que sea el último carácter de una cadena. Cuando el punto es seguido inmediatamente por otro caracter, no requiere de cuatro barras invertidas (como en addField "907.a.F.L.T\\\\."). Sin embargo, es una práctica recomendada utilizar siempre cuatro barras invertidas en la regla de normalización para asegurarse de que los resultados deseados sean consistentes. Véase los siguientes ejemplos:
- Como se indicó más arriba, si se utiliza una comilla doble (solo) en una condición que es escapada usando comillas simples, o una comilla simple que es escapada usando comillas simples, se debe usar, a su vez, dos barras invertidas para escapar la comilla doble o simple.
- Si la pleca es parte de la condición, utilice cuatro barras invertidas (\\\\) para escaparla, por ejemplo: removeField "866" if (exists "866.8.0\\\\|99"). Esto solo es necesario cuando se usa la pleca en la condición.
Ejemplo: uso del punto en una regla de normalización con replaceContents
when
(TRUE)
then
replaceContents "245.a.\\\\." with ""
replaceContents "246.a.\\\\." with ""
end
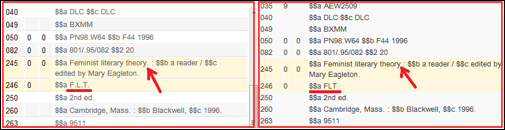
Ejemplo: uso del punto en una regla de normalización con addField
salience 100
when
TRUE
then
addField "906.a.Architecture\\\\."
addField "907.a.F\\\\.L\\\\.T\\\\."
end
