
Créer du contenu numérique par lot
Pour gérer des ressources numériques, vous devez avoir les rôles suivants :
- Opérateur d'inventaire numérique
- Opérateur d'inventaire numérique étendu (requis pour les opérations de suppression)
- Opérateur d'inventaire de collection (requis lors de l'ajout d'une nouvelle représentation numérique)
Créer du contenu numérique par lot
Le flux de travail pour les téléchargements par lot dans Alma comprend les étapes suivantes :
- La configuration d'un profil d'import numérique qui indique à Alma comment gérer les ressources numériques lors d'un téléchargement par lot dans Alma. Pour plus d'informations, voir Gérer les profils d'import.
- La préparation d'un fichier de métadonnées relatif aux notices bibliographiques que le profil d'import utilise lors de l'import des fichiers. Pour plus d'informations, voir Préparer le fichier de métadonnées XML et Préparer le fichier de métadonnées CSV.
- Le téléchargement des fichiers et des métadonnées qu'ils contiennent dans Alma via le Téléchargeur numérique. Pour plus d'informations, voir Télécharger des fichiers dans Alma.
Télécharger des fichiers dans Alma
Le Téléchargeur numérique d'Alma vous permet de télécharger des fichiers par lot dans Alma. Les titres (notices bibliographiques) sont placés dans la collection que vous sélectionnez lors du téléchargement. Pour plus d'informations sur les collections, voir Gérer les collections.
Chaque groupe de fichiers que vous préparez dans Alma pour le téléchargement constitue un apport.
La préparation d'un apport nécessite quatre étapes :
- Création de l'apport
- Ajout des fichiers à l'apport (y compris des fichiers de métadonnées)
- Téléchargement des fichiers
- Soumission de l'apport
Les informations dans le dossier de l'apport sont enregistrées dans l'emplacement de stockage local de votre navigateur. Par conséquent, si vous accédez au Téléchargeur numérique depuis un autre navigateur (ou depuis votre navigateur, mais sous un autre nom d'utilisateur) ou si vous supprimez le stockage local de votre navigateur, les dossiers d'apport précédemment créés ne seront plus accessibles. Cela n'a aucune incidence sur les données déjà soumises.
Pour télécharger et soumettre des fichiers dans Alma :
- Ouvrez la page Téléchargeur numérique (Ressources > Téléchargeur numérique).
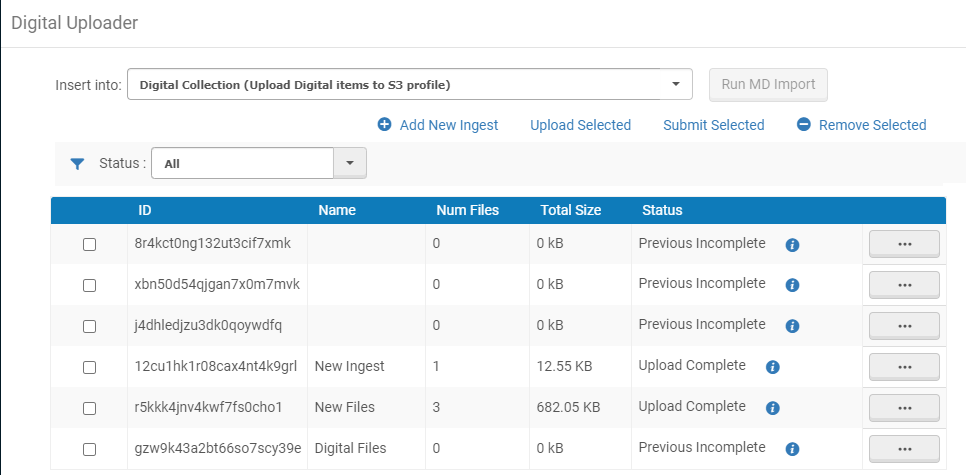
- Dans la liste déroulante Insérer dans, sélectionnez la collection dans laquelle placer les fichiers ainsi que le profil d'import numérique qui définit la manière dont les fichiers sont importés dans la collection.
- Ajoutez des fichiers à soumettre à Alma grâce aux actions suivantes :
- Glisser-déposer – Ajoute un apport par glisser-déposer d'un dossier dans la Liste des apports ; ajoute des fichiers à un apport existant en les faisant glisser dans ce dernier dans la Liste des apports.
Le glisser-déposer des dossiers est actuellement uniquement supporté par Chrome. Les fichiers peuvent être glissés et déposés en utilisant tous les navigateurs supportés.
- Dans la fenêtre Ajouter un nouvel apport :
- Sur la page du Téléchargeur numérique, cliquez sur Ajouter un nouvel apport. Ce qui suit apparaît :
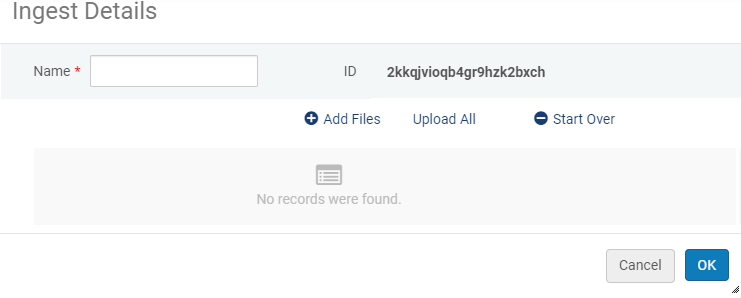 Ajouter un nouvel apport
Ajouter un nouvel apport - Indiquez un nom pour l'apport.
- Cliquez sur Ajouter des fichiers et sélectionnez les fichiers à télécharger. Le nom et la taille du fichier, ainsi que, si possible, une vignette générée automatiquement pour les formats d'image suivants apparaissent dans la boîte de dialogue Apport.
- jpg
- png
- mp4
- wav
- m4v
- doc
- ppt
- docx
- pptx
- jpeg2000
- La taille maximale de chaque fichier est de 1 Go.
- Vous pouvez inclure un maximum de 1000 fichiers dans un seul apport.
- Pour les apports dépassant ces limites, vous pouvez télécharger les fichiers directement sur le stockage S3. Pour plus d'informations, consultez le Réseau des développeurs.
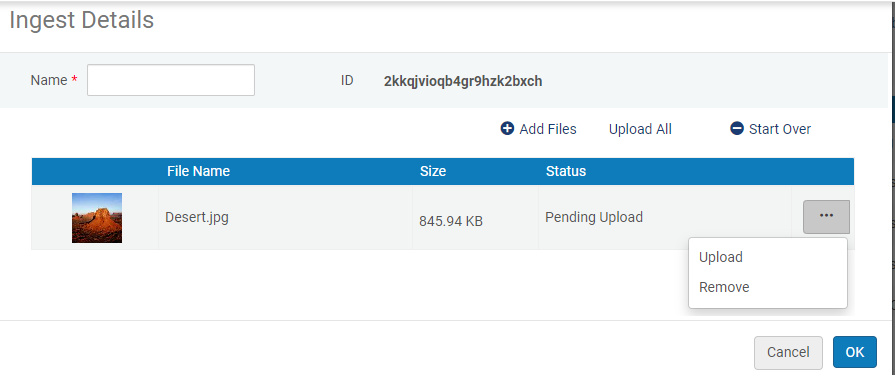 Démarrer l'apport
Démarrer l'apport- Vous pouvez inclure un fichier de vignette dans l'apport. Il apparaîtra dans les résultats de recherche du répertoire et dans la Visionneuse numérique, par exemple. Pour plus d'informations, voir Ajouter un fichier de vignette à l'apport.
- Vous pouvez inclure un fichier de sous-titres au format .vtt portant le même nom que le fichier vidéo à l'ingestion pour afficher des sous-titres lors de la lecture de la vidéo. Pour plus d'informations, voir La nouvelle visionneuse numérique.
- Ajoutez un ou plusieurs fichiers de métadonnées à l'apport (voir Préparer le fichier de métadonnées XML ou Préparer le fichier de métadonnées CSV).
Si vous n'ajoutez pas de fichier de métadonnées à l'apport, une icône d'avertissement
 apparaît dans la liste des apports.
apparaît dans la liste des apports. - Pour télécharger un fichier dans l'apport, cliquez sur Télécharger. Si vous souhaitez télécharger tous les fichiers de l'ingestion en une seule fois, cliquez sur Tout charger. Pour supprimer les fichiers et recommencer, cliquez sur Recommencer à zéro.
- Cliquez sur OK pour revenir à la page du Téléchargeur numérique. Voir Téléchargeur numérique.
- Sur la page du Téléchargeur numérique, cliquez sur Ajouter un nouvel apport. Ce qui suit apparaît :
- L'identifiant de l'apport
- Le nom de l'apport
- Le nombre de fichiers dans l'apport
- La taille totale de l'apport
- Le statuts de l'apport. Les valeurs possibles des statuts sont les suivantes :
- Nouveau – L'apport ne contient pas de fichier.
- Téléchargement en attente – L'apport n'a pas été téléchargé.
- Téléchargement terminé – L'apport n'a pas été soumis.
- Soumis – L'apport a été soumis.
- Pour supprimer un fichier d'une ingestion, sélectionnez le bouton d'action sur la liste des actions pour la ligne de l'ingestion concernée, puis cliquez sur Supprimer.
- Pour supprimer une ingestion, sélectionnez-la et cliquez sur Supprimer la sélection.
- Glisser-déposer – Ajoute un apport par glisser-déposer d'un dossier dans la Liste des apports ; ajoute des fichiers à un apport existant en les faisant glisser dans ce dernier dans la Liste des apports.
- Pour télécharger des apports, sélectionnez-les et cliquez sur Télécharger la sélection.
- Pour traiter des apports, sélectionnez ceux que vous voulez soumettre et cliquez sur Soumettre la sélection.
- L'étape de soumission est nécessaire pour que vous puissiez continuer à ajouter en toute sécurité des fichiers à votre apport. L'apport n'est pas traité jusqu'à ce que vous cliquiez sur Soumettre.
- Pour que l'apport soit soumis, le champ Nom de fichier de métadonnées dans le profil d'import associé à l'apport doit contenir le bon chemin d'accès et le bon nom de fichier du fichier de métadonnées.
- En règle générale, le traitement Import de métadonnées fonctionne selon un échéancier. Pour exécuter ce traitement manuellement, cliquez sur Exécuter le traitement d'import.
Le traitement Import de métadonnées se lance et l'apport est traité.
Les fichiers de plus de 30 jours (à l'exception des fichiers de verrouillage) sont supprimés, hebdomadairement, lors du traitement de maintenance.
Préparer le fichier de métadonnées XML
Pour utiliser le Téléchargeur numérique en vue d'un transfert de fichiers par lot, vous pouvez préparer un fichier XML soit en format MARC soit en DC contenant les métadonnées des notices bibliographiques. Chaque fichier de métadonnées peut contenir des informations sur plusieurs notices bibliographiques. Alma s'en sert pour créer les notices bibliographiques et les représentations associées.
Les éléments de la notice dans le fichier doivent être imbriqués dans un seul élément de collection.
Le type d'information requis dans le fichier de métadonnées dépend de la façon dont vous avez configuré le profil d'import. Par exemple, si vous configurez le profil d'import pour qu'il recherche le nom de fichier dans le sous-champ u du champ MARC 856, le fichier de métadonnées doit contenir ces informations dans ce champ.
Si la notice bibliographique contient des informations sur les fonds, elle sera associée à la collection mentionnée dans la notice. Sinon, elle sera associée à la collection sélectionnée dans le champ Assignation de collection par défaut défini dans le profil d'import de ressources numériques.
MARC XML Assignation de collection
Pour des notices MARC, si vous activez un processus de normalisation qui contient le addBibToCollectionNormalizationTask, l'import attribue la notice à une collection selon la règle de priorité suivante :
- Si le champ MARC 787$w contient un identifiant de collection Alma valide, la notice est assignée à cette collection.
- Si le champ MARC 787$w contient les valeurs de l'identifiant et du système externes, comme cela est configuré dans une collection Alma existante, la notice est assignée à cette collection. Le champ doit contenir le système et l'identifiant au format suivant : ({system}){ID}, par exemple, (Rosetta)123454321 (similaire à la structure du champ 035).
- Si le champ MARC 787$w contient le nom d'une collection Alma de niveau supérieur, la notice est assignée à cette collection.
- Si aucune des règles ci-dessus n'est satisfaite, la notice est assignée à la collection Alma définie par défaut pour le profil d'import.
Lorsque vous téléchargez un fichier de métadonnées contenant une seule notice, aucun champ 856 n'est nécessaire. La notice créée inclut tous les fichiers qui se trouvent dans le dossier de l'apport.
Ce qui suit est un exemple d'un fichier de métadonnées XML :
<?xml version="1.0" encoding="UTF-8" ?>
<collection>
<record>
<leader>01139cam a2200277 a 4500</leader>
<controlfield tag="001">ocm27832725113 </controlfield>
<controlfield tag="003">OCoLC</controlfield>
<controlfield tag="005">20131108731707.4</controlfield>
<controlfield tag="008">970910r19451931pk b 000 0 eng </controlfield>
<datafield tag="035" ind1=" " ind2=" ">
<subfield code="a">(OCoLC)27832725113</subfield>
</datafield>
<datafield tag="100" ind1="1" ind2=" ">
<subfield code="a">Representation of rec 1</subfield>
<subfield code="b">jpg files</subfield>
</datafield>
<datafield tag="245" ind1="1" ind2="2">
<subfield code="a">Record 1 - Civil war</subfield>
</datafield>
<datafield tag="856" ind1=" " ind2=" ">
<subfield code="a">Soldier on a Horse</subfield>
<subfield code="u">civil war.jpg</subfield>
</datafield>
<datafield tag="856" ind1=" " ind2=" ">
<subfield code="a">North and South</subfield>
<subfield code="u">civil2.jpg</subfield>
</datafield>
<datafield tag="650" ind1=" " ind2="0">
<subfield code="a">Digital items loaded to Amazon</subfield>
</datafield>
</record>
</collection>
<collection>
<record>
<leader>01139cam a2200277 a 4500</leader>
<controlfield tag="001">ocm27832725113 </controlfield>
<controlfield tag="003">OCoLC</controlfield>
<controlfield tag="005">20131108731707.4</controlfield>
<controlfield tag="008">970910r19451931pk b 000 0 eng </controlfield>
<datafield tag="035" ind1=" " ind2=" ">
<subfield code="a">(OCoLC)27832725113</subfield>
</datafield>
<datafield tag="100" ind1="1" ind2=" ">
<subfield code="a">Representation of rec 1</subfield>
<subfield code="b">jpg files</subfield>
</datafield>
<datafield tag="245" ind1="1" ind2="2">
<subfield code="a">Record 1 - Civil war</subfield>
</datafield>
<datafield tag="856" ind1=" " ind2=" ">
<subfield code="a">Soldier on a Horse</subfield>
<subfield code="u">civil war.jpg</subfield>
</datafield>
<datafield tag="856" ind1=" " ind2=" ">
<subfield code="a">North and South</subfield>
<subfield code="u">civil2.jpg</subfield>
</datafield>
<datafield tag="650" ind1=" " ind2="0">
<subfield code="a">Digital items loaded to Amazon</subfield>
</datafield>
</record>
</collection>
Voici quelques exemples de l'utilisation du champ 787 MARC pour attribuer une notice à une collection :
- La notice suivante :
<datafield tag="245" ind1="1" ind2="4">
<subfield code="a">The politics of our lives :</subfield>
<subfield code="b">the Raising Her Voice in Pakistan experience /</subfield>
<subfield code="c">Jacky Repila.</subfield>
</datafield>
<datafield tag="787" ind1=" " ind2=" ">
<subfield code="w">8131549940000121</subfield>
</datafield>Sera ajoutée à cette collection :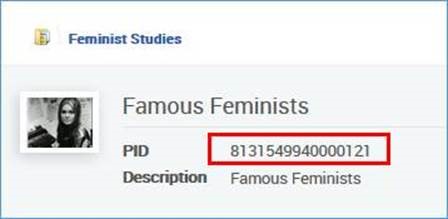 Exemple 1
Exemple 1 - La notice suivante :
<datafield tag="245" ind1="0" ind2="0"><subfield code="a">New South Asian feminisms :</subfield><subfield code="b">paradoxes and possibilities /</subfield><subfield code="c">edited by Srila Roy.</subfield></datafield><datafield tag="787" ind1=" " ind2=" "><subfield code="w">8131549960000121</subfield></datafield>Sera ajoutée à cette collection :
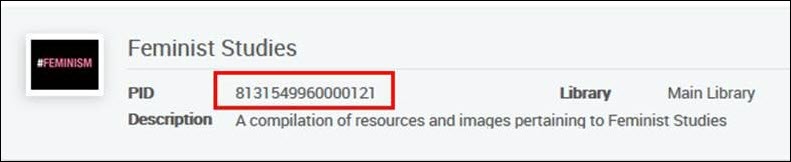 Exemple 2
Exemple 2
DC XML Assignation de collection
Pour les Dublin Core, si vous activez un processus de normalisation qui contient la addBibToCollectionNormalizationTask, Alma vérifie les champs dc:relation et dcterms:isPartOf. Alma vérifie chacun de ces champs dans l'ordre suivant puis attribue les notices importées à cette collection.
- Par identifiant de collection interne :
<dc:relation>alma:{INST_CODE}/bibs/collections/{COLLECTION_ID}</dc:relation>
- Par identifiant de collection externe :
<dc:relation>n'importe quel texte</dc:relation>
- Par nom de collection (premier niveau uniquement) :
<dc:relation>n'importe quel texte</dc:relation>
- Collection par défaut (seulement si 1-3 ne correspond à aucune collection existante).
Attribution de collection MODS XML
Créez la règle de normalisation Ajouter BIB à la collection pour MODS. Le fonctionnement est le même que pour DC, et permet l'attribution par identifiant de collection, identifiant externe de collection et nom de collection :
- <relatedItem@type="host"><identifier>alma:{INST_CODE}/bibs/collections/{COLLECTION_ID}</identifier></relatedItem>
- <relatedItem@type="host"><identifier>{external_id}</identifier></relatedItem>
- <relatedItem@type="host"><identifier>{collection_name - top level only}</identifier></relatedItem>
Préparer le fichier de métadonnées CSV
Pour utiliser le Téléchargeur numérique en vue d'un transfert de fichiers par lot, vous pouvez préparer un fichier CSV avec des métadonnées pour les notices bibliographiques. Ce fichier CSV est basé sur un inventaire, chaque ligne représente donc une représentation. Les informations bibliographiques sur chaque ligne peuvent être complètes (ce qui génère une nouvelle notice bibliographique) ou il peut être fait référence à une notice bibliographique existante, liée par des règles de correspondance. Un inventaire numérique est alors ajouté à la notice bibliographique référencée. Le contenu de niveau fichier est inclus sur une même ligne et comprend le chemin d'accès complet du fichier (relativement au dossier de l'apport) et une étiquette (facultatif). Une représentation peut contenir plusieurs fichiers. De multiples représentations pour une seule notice bibliographique sont représentées par deux lignes contenant la notice bibliographique complète (avec des règles pour empêcher la création de plusieurs notices). Dans ce cas, la colonne group_id doit être utilisée.
Le fichier CSV doit être encodé en UTF-8 (et non en UTF-8-BOM).
Lors de l'import des métadonnées, vous pouvez fournir des notices CSV avec un système externe et un identifiant pour les attribuer à une collection, dans la colonne collection_external (avec le même format que les notices MARC). Le champ est répétable.
Le fichier CSV peut contenir quatre types de champs :
- Collection – Réservé aux attributions de collection. Ce champ contient le nom ou l'identifiant d'une collection (collection_name concerne la collection au niveau supérieur seulement) à laquelle la notice bibliographique est attribuée. Ce champ est facultatif. (Si les champs de collection n'existent pas, la notice bibliographique est attribuée à la collection par défaut définie dans le profil d'import de métadonnées). Répétable.
Si le format cible est défini à MARC dans le profil d'import, les noms des en-têtes CSV sont convertis aux champs MARC comme suit :
- collection_name – 787 t
- collection_id – 787 w
- collection_external – 787 o
Si le format cible est défini sur Dublin Core dans le profil d'import, les noms des en-têtes CSV sont convertis au champ dc:relation.Vous devez définir la règle de normalisation Ajouter BIB à la collection dans le profil d'import pour que le travail d'importation attribue la collection en fonction de ces champs. Sinon, la collection par défaut est utilisée. - Champs au niveau de la notice bibliographique – Il en existe deux sous-types :
- mms_id et originating_system_id – Ce sous-type permet de faire correspondre des notices aux notices existantes. Les deux champs peuvent exister, si vous voulez faire correspondre le champ mms_id et ajouter un champ originating_system_id (cela est géré par des règles). Le champ mms_id n'est pas répétable.
- Autres champs de notice bibliographique – Ce sous-type renvoie au format de métadonnées cible selon la table du réseau du développeur (https://developers.exlibrisgroup.com/alma/integrations/digital/almadigital/ingest. Voir la table pour les détails de répétabilité. (Les champs non répétables sont marqués comme NR.)
- Champs au niveau de la représentation – Ils correspondent aux propriétés concernant la représentation. Les champs réservés sont non répétables (sauf rep_note).
- Champs au niveau du fichier. Répétable.
Le contenu CSV doit être créé et traité en fonction de l'analyse Excel. Par exemple, les champs avec des virgules doivent être entourés par des guillemets :
Guerre et Paix, "Tolstoï, Leo", 1862, ...
Tous les caractères supportés dans MARC XML sont supportés dans csv.
Pour avoir un exemple de fichier CSV, voir Exemple CSV.
Conversion CSV vers Dublin Core
Lorsque vous sélectionnez CSV comme format source physique et Dublin Core comme format cible, Alma convertit les informations dans la notice CSV vers le format Dublin Core. La conversion est surtout intuitive, par exemple : contributeur est converti en dc:contributor. Veuillez cependant noter ce qui suit :
- MMS_ID doit être utilisé uniquement pour une correspondance avec un MMS ID Alma existant. La syntaxe est : alma:{INST_CODE}/bibs/{MMS_ID}. Ce champ n'est pas stocké comme partie de la notice importée.
- ISBN et ISSN sont convertis en <dc:identifier xsi:type="dcterms:URI"> avec le préfixe urn.
- Originating_system_id est converti en dc:identifier.
- Pour les collections, collection_id est converti à dc:relation dans le format suivant : <Inst-code>/bibs/collections/<collection id>
- Tous les champs sont répétables et aucun n'est obligatoire.
- Le type de vocabulaire DCMI est recommandé pour le champ type (à l'exception de collection, qui ne doit pas être utilisé).
- La conversion de plusieurs représentations pour une seule notice bibliographique est prise en charge en attribuant aux représentations le même group_id.
- Les schémas d'encodage et les langues sont supportés. Le format ISO 639-1 est nécessaire pour un code de langue à 2 lettres et le format ISO 639-2/3 pour un code de langue à 3 lettres.
La syntaxe est la suivante :
- encodage uniquement – property.schema (par exemple, dc:subject.dcterms:LCSH)
- langues uniquement – property lang=\{code à 2 ou 3 lettres} (par exemple, dc:subject lang=en)
- encodage et langues – property.schema lang=\{code à 2 ou 3 lettres} (par exemple, dc:subject.dcterms:LCSH lang=en)
Préparer le fichier de métadonnées Excel
Pour plus d'informations sur la préparation du fichier de métadonnées Excel, voir Importer des notices avec des fichiers CSV ou Excel.
Ajouter un fichier de vignette à l'apport
Vous pouvez ajouter un fichier de vignette à l'apport (aux formats jpg, png, gif seulement) avec le même nom que le fichier numérique et avec l'extension .thumb. Par exemple :
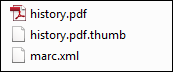
Fichier de vignette
Cela permet à Alma de stocker l'image .thumb comme une vignette pour le fichier en question. La vignette apparaîtra dans les résultats de recherche dans le répertoire, dans la visionneuse numérique et dans Primo.
Ajouter un fichier de texte intégral à l'apport
Vous pouvez ajouter un fichier de texte intégral à l'apport soit en format simple soit en format ALTO en utilisant le même nom que celui du fichier numérique et l'extension .text.plain ou text.alto. Cela vous permet d'effectuer des recherches de texte pour l'image dans le visionneur Lecteur de livre.