
Normalization of Characters in Primo
If you are working with Primo VE and not Primo, see Linguistic Features for Primo VE.
Primo normalizes characters in the following contexts:
-
Indexing and Searching
-
Alphabetic sorting of results sets (such as for author or title sort)
-
Creation of the Dedup/FRBR keys during the normalization process
The normalization mechanism is separate in each context and is described in separate sections below.
Changes to the normalization configuration files have no effect on the results returned from remote searches, Primo Central, or any other deep search adaptor.
Indexing and Searching
The search engine normalizes characters during indexing and searching. This is done to ensure that the user's query matches the indexed terms. If characters are optionally configured to be normalized in multiple variations based on language, the system will index all variations, but during search time, it will normalize the character to the most appropriate variation based on the language of the query. If the language of the query cannot be determined, the system will default to the interface language. For more information, see Support for Multiple Variations.
Primo is installed with out-of-the-box normalization of characters, which can be overridden by customer defined rules.
Out-of-the-Box Normalization
The out-of-the-box (OTB) character normalization is defined in the following tables under the /ng/jaguar/home/profile/analysis/specialCharacters/CharConversion/OTB/OTB directory:
-
For CJK:
-
cjk_unicode_kana1to1_normalization.txt
-
cjk_unicode_trad_to_simp_normalization.txt
-
cjk_unicode_punct_normalization.txt
-
-
For non-CJK scripts:
-
non_cjk_unicode_normalization.txt – Provides normalization for all character sets, but CJK. For more information on this type of normalization, see Out-of-the-Box Latin Normalization for Indexing and Searching.
-
<language_code>_non_cjk_unicode_normalization.txt – Out of the box, Primo supports some normalization variations for the following languages using the language files: Danish (dan), German (ger), Norwegian (nor), and Swedish (swe). If the default locale (which is defined as English on the Search Engine Configuration page in the Primo Back Office) is changed to one of the supported languages, the character conversions defined in the relevant language file will override the character conversions defined in the following file:non_cjk_unicode_normalization.txtFor more information on language-specific files, see Out-of-the-Box Language Variations.
-
Out of the box, no characters are normalized in multiple variations, however, this can be done locally. For more information, see Support for Multiple Variations.
The structure for all the above files contains the following columns:
-
The first column contains the original Unicode character.
-
The second column contains the normalized Unicode character.
-
If a language requires a character to be normalized into two characters, a third column must contain the second normalized Unicode character. For example, the character 00F6 (ö) is normalized to the following characters for German: 006F and 0065 (oe).
Each column must be separated by a tab, and comments must be prefixed with the number sign #.
For example:
0041 0061 # LATIN CAPITAL LETTER A ( 'A' to 'a' )
0042 0062 # LATIN CAPITAL LETTER B ( 'B' to 'b' )
0043 0063 # LATIN CAPITAL LETTER C ( 'C' to 'c' )
0044 0064 # LATIN CAPITAL LETTER D ( 'D' to 'd' )
0045 0065 # LATIN CAPITAL LETTER E ( 'E' to 'e' )
0046 0066 # LATIN CAPITAL LETTER F ( 'F' to 'f' )
0047 0067 # LATIN CAPITAL LETTER G ( 'G' to 'g' )
0048 0068 # LATIN CAPITAL LETTER H ( 'H' to 'h' )
0049 0069 # LATIN CAPITAL LETTER I ( 'I' to 'i' )
004A 006A # LATIN CAPITAL LETTER J ( 'J' to 'j' )
004B 006B # LATIN CAPITAL LETTER K ( 'K' to 'k' )
004C 006C # LATIN CAPITAL LETTER L ( 'L' to 'l' )
004D 006D # LATIN CAPITAL LETTER M ( 'M' to 'm' )
004E 006E # LATIN CAPITAL LETTER N ( 'N' to 'n' )
Normalization from one to many characters is not supported within a single file. Additional normalizations can be created in separate language directories.
Because the default character conversion files are overwritten during upgrades, it is recommended that all customizations be performed at the installation and institution levels as described in the following sections.
Out-of-the-Box Language Variations
Out of the box, Primo supports normalization variations for the following languages using the associated language file:
-
Danish – dan_non_cjk_unicode_normalization.txt
-
German – ger_non_cjk_unicode_normalization.txt
-
Norwegian – nor_non_cjk_unicode_normalization.txt
-
Swedish – swe_non_cjk_unicode_normalization.txt
If the Locale parameter on the Search Engine Configuration page is modified to any of the above languages, the characters defined in the relevant language file, which is stored in the following directory, will override the characters defined in the non_cjk_unicode_normalization.txt file, which are stored in the same directory:
/exlibris/primo/p<n>_<x>/ng/jaguar/home/profile/analysis/specialCharacters/CharConversion/OTB/OTB/</x></n>
If the Default Locale parameter in the Search Engine Configuration Wizard is changed to any of the above languages, the characters defined in the <language_code>_non_cjk_unicode_normalization.txt file will override the characters defined in the non_cjk_unicode_normalization.txt file.
The following figure shows the locale set to German in the Primo Back Office:
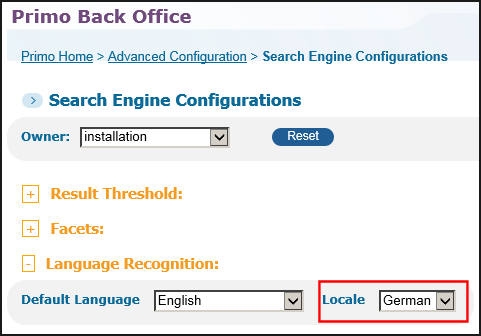
Search Engine Configuration Wizard (Locale set to German)
If you change the Locale parameter, you must re-index the database from scratch to ensure consistency between indexing and searching. For more information, refer to the Deleting and Re-indexing the Database section in the Primo System Administration Guide.
The <language_code/>_non_cjk_unicode_normalization.txt files include only the characters that need to be normalized differently. For example, see the following table, which lists per language the characters that are normalized differently from the previous version of Primo. The table lists only the lowercase form, but both uppercase and lowercase characters are normalized.
| Unicode | Lowercase | Default | German | Danish | Norwegian | Swedish |
|---|---|---|---|---|---|---|
|
00C5 00E5
|
å
|
a
|
aa
|
aa
|
aa
|
|
|
00C4 00E4
|
ä
|
a
|
ae
|
ae
|
ae
|
ae
|
|
00D8 00F8
|
ø
|
o
|
oe
|
oe
|
oe
|
|
|
00D6 00F6
|
ö
|
o
|
oe
|
oe
|
oe
|
oe
|
|
00DC 00FC
|
ü
|
u
|
ue
|
Any changes made to the locally-defined characters conversion tables (as described in the section below) will override the definitions based on the default locale.
Locally-Customized Normalizations
If you want to customize specific character conversions, create a user_defined_unicode_normalization.txt file and include your customized character conversions.
For on-premises installations, you can customize the out-of-the-box normalizations by creating entries for specific characters at the following configuration levels:
-
Installation – This level contains the customized normalization files for all institutions, which must be stored in the following directory./exlibris/primo/p<n/>_<x/>/ng/jaguar/home/profile/analysis/specialCharacters/CharConversion/CUSTOMER/CUSTOMERIf you want to customize specific character conversions, add a user_defined_unicode_normalization.txt file to the above directory and include your customized character conversions.
-
Institution (one per institution) – This level contains the customized normalization files for individual institutions in non-sharing, multi-tenant environments only, which must be stored in the following directories:/exlibris/primo/p<n/>_<x/>/ng/jaguar/home/profile/analysis/specialCharacters/CharConversion/CUSTOMER/<institution>If you want to customize specific character conversions, add a user_defined_unicode_normalization.txt file to the above directory and include your customized character conversions.
Any characters defined in the user_defined_unicode_normalization.txt file will override the character conversions defined at a higher level, including characters defined in the <language_code>_non_cjk_unicode_normalization.txt files if the default locale is set to one of the out-of-the-box language variations.
In addition, the system allows you to index multiple variations of Latin characters per Latin language at the installation and institution levels (see Support for Multiple Variations).
For cloud installations, contact Ex Libris Support for assistance to add your customizations to the server.
-
If you add local customizations, you will need deploy the Search Engine option on the Deploy All page and then re-index from scratch. To re-index from scratch, follow the instructions in the Performing System Cleanup - Clean Database Scripts section in the Primo System Administration Guide.
-
Character conversions at the institution level have precedence over customizations at the installation level, and customizations at the installation level have precedence over character conversions defined in the default character conversion files at the OTB level.
-
For customers who do not have access to the server, contact Ex Libris Support for assistance.
Support for Multiple Variations
Primo allows you to index the same character in several possible ways. During indexing, all defined variations are created per language, but only the variation that matches the detected language of the query is used. If a language is not detected, the system will use the language of the UI. By selecting only one variation based on language, unwanted results (for example, to retrieve results with u when the query is for ü) are minimized during searching.
For each language, add only the characters that require language-specific normalizations to the following files:
non_cjk_unicode_normalization.txt
For cloud installations, contact Ex Libris Support for assistance to add your customizations to the server.
Language-specific customizations should be added to the appropriate language directory at the following configuration levels as needed:
-
Installation (overrides OTB level for all institutions) – /exlibris/primo/p<n/>_<x/>/ng/jaguar/home/profile/analysis/specialCharacters/CharConversion/CUSTOMER/CUSTOMER
-
Institution (overrides installation and OTB levels for specified institution) – /exlibris/primo/p<n>_<x>/ng/jaguar/home/profile/analysis/specialCharacters/CharConversion/CUSTOMER/<institution>
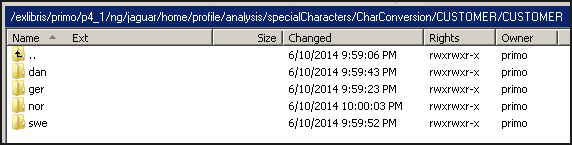
Language-Specific Directories for Character Conversion
Each language directory must be a 3-character ISO Latin 639.2-B code that contains the following file, which should include only the characters that require language-specific normalizations:
non_cjk_unicode_normalization.txt
To be certain that the language-specific directory is used to normalize search queries, the equivalent UI language must be enabled in the Languages code table (which defines 4-character codes that the system converts to the equivalent 3-character codes).
Out of the box, no multiple variations are defined per language.
Normalizing Decomposed Unicode to Composed Unicode
In addition to the out-of-the-box normalizations, the SE can normalize decomposed Unicode characters to the composed form. The system performs this type of normalization first, utilizing the 221_punctuation_char_normalization_range_unicode.txt file, which is populated via the SE 221 Char conversion mapping table in the Front End subsystem. This normalization file is stored under the following directory on the Primo server:
/ng/jaguar/home/profile/analysis/specialCharacters/221_punctuation_char_normalization_range_unicode.txt
Out of the box, the SE 221 Char conversion mapping table is empty. To add an entry to the above file, you must add a mapping row containing the following fields in the SE 221 Char conversion mapping table:
-
From – Original decomposed Unicode characters
-
To – Normalized composed Unicode character
For example, to normalize A and a Diaeresis to A with a Diaeresis as a single character, enter the following:
0041-0308 00C4
After making a change to the mapping table, it is necessary to deploy the Search Engine Configuration option. It is also necessary to clear the index and then re-index.
The Normalization Flow for Indexing and Searching
The system creates a single active mapping from the various files described above using the following flow:
-
The SE normalizes decomposed Unicode to composed Unicode, as defined in the 221 Char conversion mapping table in the Front End subsystem.
-
The SE normalizes characters based on the tables in the /ng/jaguar/home/profile/analysis/specialCharacters/CharConversion directory using the following hierarchy:
-
/exlibris/primo/p<n/>_<x/>/ng/jaguar/home/profile/analysis/specialCharacters/CharConversion/CUSTOMER/<institution/> – Uses the institution of the active view. This is applicable in non-sharing, multi-tenant environments only.
-
/exlibris/primo/p<n/>_<x/>/ng/jaguar/home/profile/analysis/specialCharacters/CharConversion/CUSTOMER/CUSTOMER
-
/exlibris/primo/p<n/>_<x/>/ng/jaguar/home/profile/analysis/specialCharacters/CharConversion/OTB/OTB
-
The following figure shows the hierarchy of the conversion files and how each type of conversion file is used to create the default and language-specific conversion mappings. The right side of the figure shows the default conversion mapping flow used for all users regardless of the detected language. The left side shows the conversion mapping flow for characters that require an additional conversion from the default mapping, which is based on the detected language of the query or the language setting of the UI (if a language cannot be detected in the query).
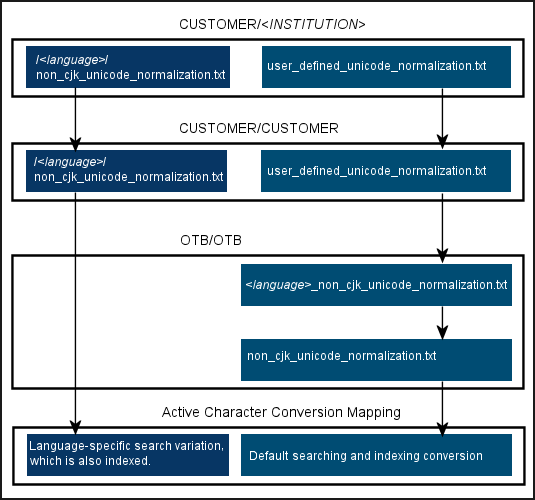
Character Conversion Flow
The relevant language-specific mapping file (which is defined under the
.../OTB/OTB directory) is also included in the default conversion mapping if the Locale parameter is set to Danish, German, Norwegian, or Swedish in the Search Engine Configuration Wizard. For more information, see Out-of-the-Box Language Variations.
.../OTB/OTB directory) is also included in the default conversion mapping if the Locale parameter is set to Danish, German, Norwegian, or Swedish in the Search Engine Configuration Wizard. For more information, see Out-of-the-Box Language Variations.
The language-specific directories, which are created locally, allow you to create multiple variations for a character. For more information, see Locally-Customized Normalizations.
Character Conversion Examples
Each of the scenarios in this section is based on the conversion of the following characters:
-
00E5 (å)
-
00F6 (ö)
Scenario 1:
In this scenario, the following normalization files have been defined:
-
/OTB/OTB/non_cjk_unicode_normalization.txt
Character Conversion 00E5 (å)0061 (a)00F6 (ö)006F (o) -
/OTB/OTB/ger_cjk_unicode_normalization.txt
Character Conversion 00F6 (ö)006F 0065 (oe) -
/OTB/OTB/swe_cjk_unicode_normalization.txt
Character Conversion 00E5 (å)0061 0061 (aa) -
/CUSTOMER – Nothing is defined in this directory.
Result 1a:
If the customer did not change the default locale setting, the system will use the following character conversions (which are defined in the
/OTB/OTB/non_cjk_unicode_normalization.txt file) for both indexing and searching:
/OTB/OTB/non_cjk_unicode_normalization.txt file) for both indexing and searching:
| Character | Conversion |
|---|---|
|
00E5 (å)
|
0061 (a)
|
|
00F6 (ö)
|
006F (o)
|
Result 1b:
If the customer changes the default locale setting to German, the system will use the character conversion mapping that is defined for ö in the
/OTB/OTB/ger_non_cjk_unicode_normalization.txt file for both indexing and searching:
/OTB/OTB/ger_non_cjk_unicode_normalization.txt file for both indexing and searching:
| Character | Conversion |
|---|---|
|
00E5 (å)
|
0061 (a)
|
|
00F6 (ö)
|
006F 0065 (oe)
|
Scenario 2:
In this scenario, the out-of-the-box definitions are the same as in Scenario 1, the default locale has been set to Swedish, and the /CUSTOMER/CUSTOMER/user_defined_unicode_normalization.txt file has been added to override the Swedish conversion for å:
| Character | Conversion |
|---|---|
|
00E5 (å)
|
0061 (a)
|
In addition, the customer added the /CUSTOMER/CUSTOMER/ger/non_cjk_unicode_normalization.txt file to define the following variations for German:
| Character | Conversion |
|---|---|
|
00F6 (ö)
|
006F 0065 (oe)
|
The following table lists the character conversion mapping created from all of the files:
| Character | Default Conversion | German
Conversion
|
|---|---|---|
|
00E5 (å)
|
0061 (a)
|
|
|
00F6 (ö)
|
006F (o)
|
006F 0065 (oe)
|
This indicates that å will be both indexed and searched as an “a” even though the default Locale parameter was set to Swedish in the Search Engine Configuration Wizard.
This also means that ö will be indexed as both o and oe. Although, if Primo detects that a search query is in German or the locale of the UI is German, ö will be converted to oe.
Alphabetical Sorting
Normalization of characters for alphabetic sorting of the results set in the Front End is done in two stages: Indexing and Run-time.
Indexing
The sort keys created from the fields in the Sort section of the PNX are normalized during indexing via the following mapping tables:
-
SE 221 Char conversion – Normalizes decomposed characters to composed characters. There are no out-of-the-box values in this table. For more information, see Normalizing Decomposed Unicode to Composed Unicode.
-
SE Char conversion – Normalizes composed characters and punctuation. After changes to this table have been saved and deployed, the system saves the definitions to the following file:/ng/jaguar/home/profile/analysis/specialCharacters/ punctuation_char_normalization_range_unicode.txtThe SE Char conversion table comes with the following out-of-the-box definitions:
-
Delete initial and trailing blanks.
-
Convert the following characters to blank: hyphen (2010), back slash (005C), underline (005F), hyphen-minus (002D), slash (002F), Figure dash (2012), En dash (2013), EM dash (2014).
-
Delete the following non alpha-numeric characters:
-
ASCII punctuation (http://unicode.org/charts/PDF/U0000.pdf) – 0021-002E, 005B-005E, 007B-007E(does not delete characters that should be changed to a blank)
-
Latin 1 punctuation (http://unicode.org/charts/PDF/U0080.pdf) - 00A1-00B8, 00BA-00BB, 00BF(does not delete superscripts and fractions – 00B2-00B3, 00B9, 00BC-00BE)
-
Combining Diacritical marks (floating diacritics) (http://unicode.org/charts/PDF/U0300.pdf) – 0300-036F
-
Compresses multiple blanks to a single blank.
-
Any change to this table requires a deploy of the Search Engine configuration and re-indexing from scratch.
Run-Time
During run-time the actual order of the characters is determined by files on the server. Primo supplies out-of-the-box files, but you can use locally-defined files to override them.
The following out-of-the-box character set files are located in the
/exlibris/primo/p3_1/ng/jaguar/home/profile/analysis/sort/system directory:
/exlibris/primo/p3_1/ng/jaguar/home/profile/analysis/sort/system directory:
-
latin_rules_ootb.txt – contains the default Latin sort rules
-
cjk_pinyin_rules_ootb.txt – contains the default CJK PINYIN sort rules
-
cjk_brushs_rules_ootb.txt – contains the default CJK Brush sort rules
-
other_rules_ootb.txt – contains the default Hebrew sort rules
To override the out-of-the-box character set files:
-
Select the Custom option next to the character set definitions (Latin, CJK, and Additional) that you want to override in the Advanced Configuration > Search Engine Configurations > Sorting section.
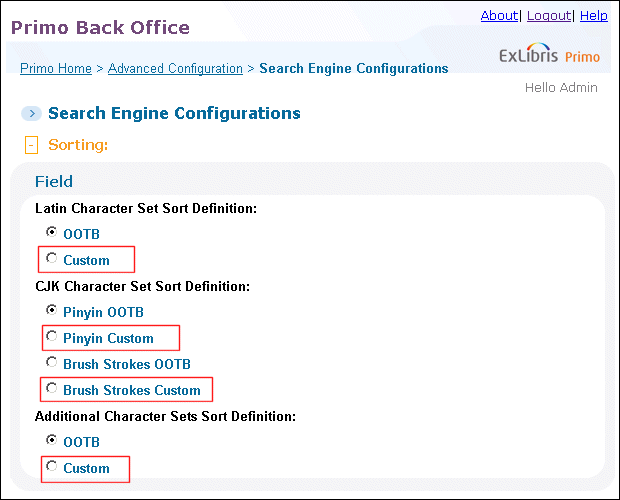 Character Sets Sort Definitions
Character Sets Sort Definitions -
Create the following customized files and place them in the /exlibris/primo/p3_1/ng/jaguar/home/profile/analysis/sort/user_defined directory on your server:
-
latin_rules_custom.txt – contains the custom Latin sort rules
-
cjk_pinyin_rules_custom.txt – contains the custom CJK PINYIN sort rules
-
cjk_brushs_rules_custom.txt – contains the custom CJK Brush sort rules
-
other_rules_custom.txt – contains custom Hebrew sort rules
-
-
Deploy the Search Engine configuration.
-
Re-index from scratch.
Dedup and PNX Keys
Characters are normalized in the Dedup and FRBR keys for matching purposes. The system uses the following transformation routines for FRBR and Dedup keys:
-
Character conversion – This transformation is used in the out of the box rules. It normalizes Latin characters. For more information, see Character Conversion Transformation - Normalization Table.
-
NormalizeDiacritics – This transformation normalizes characters based on the DiacritcsConversion mapping table in the Normalization subsystem.
The DiacriticsConversion mapping table contains the following columns:
-
Source UniCode – the Unicode character from which to normalize.
-
Target UniCode – the Unicode character to which to normalize. It is possible to normalize a single character to two characters by entering a hyphen between them. For example, enter 0064-0068.
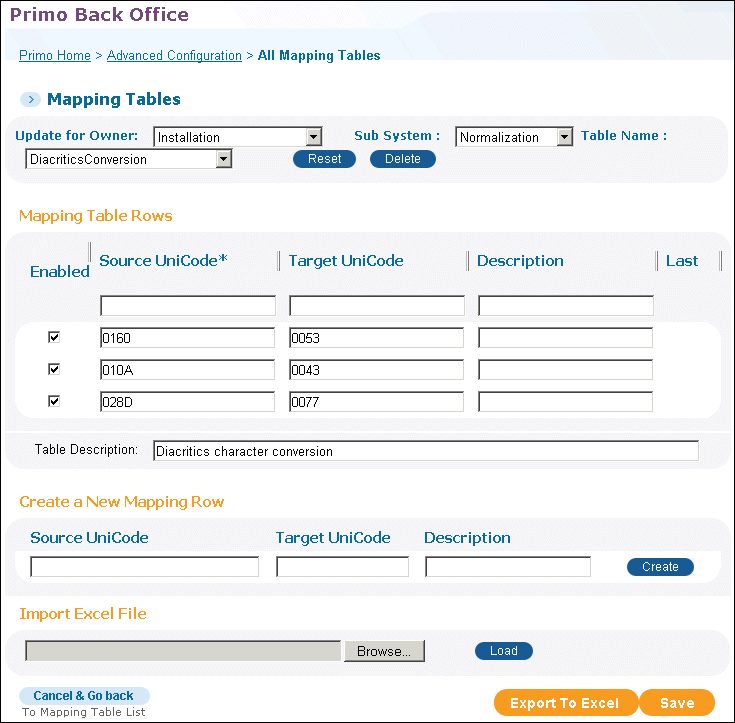
DiacriticsConversion Mapping Table
The following example converts a Latin O with stroke to uppercase O:
| Source UniCode | Target UniCode |
|---|---|
|
0OD8
|
OO4F
|
Normalization of Punctuation and Special Characters
During normalization, the tokenizer uses the rules in the following table to determine which punctuation and special characters should be included in search indexes. Character conversion files can be used to process any punctuation or special characters that are not handled by the following rules. Any remaining punctuation and special characters are replaced with spaces and treated as word separators. For example, a*b or a$b are treated as two separate words (a and b) by the tokenizer.
| Format/Description | Examples | Notes |
|---|---|---|
|
One or more alphanumeric characters followed by one or more of the following symbols:
+ # /
|
13/A
c++ c# i/o a+ ab+ |
|
|
Two words separated by an apostrophe: <word><apostrophe><word>
|
Al-Haqa'iq
al-Bah?th ?an U¯rubba¯ |
An apostrophe may be one of the following characters, which is converted to 0027:
2018, 2019, 201B, 0060, 00B4, 02BB, 02BC, 02BD, 02BE, 02BF
|
|
Two words separated by a hyphen: <word><hyphen><word>
|
standards-based performance
|
A hyphen may be represented by any of the following characters:
\u002d, \u2010, \u2011, or \u05be
|
|
When included with special combinations of numbers and alphanumeric characters (such as IP addresses or special volume, issue, or supplement indications in citations), the following characters are not removed:
_ - / . ,
|
a.1
1.a a-1-a |
|
|
& and @ symbols that separate words (such as in company names) are not removed.
|
AT&T Excite@Home
|
|
|
Periods that are part of acronyms are not removed: <letter>(.<letter>.)+
|
I.E.E.E.
U.N. |
|
|
Combining marks, which include the following characters are not removed: \uFE20 - \uFE2F, \u1DC0 - \u1DFF, \u0300 - \u036F, \u20D0 - \u20FF
|
||
|
Modifiers, which include the following characters are not removed: \u02B0 - \u02FF, \uA700 - \uA71F
|
This excludes the Hebrew hyphen (05BE) so that words with this character are recognized as follows: <word><hyphen><word>
|
|
|
For backward compatibility with V2.1 of the tokenizer, the following characters are not removed: \u0100 - \u05BD, \u05BF - \u1FFF
|
||
|
For backward compatibility with V2.2 of the tokenizer, the following characters are not removed: \uFFA0 - \uFFDC
|
||
|
Unless a digit follows a single underscore, Primo will replace underscores with a space.
If a query contains more than one underscore in succession (including underscores that precede a digit), Primo will replace them with a single space.
|
abc_3_220 will be searched and indexed as abc_3_220.
abc__3_220 will be searched and indexed as abc 3_220.
|