
Crear contenido digital de forma masiva
Para gestionar recursos digitales se deben tener los siguientes roles:
- Operador de inventario digital
- Operador de inventario digital extendido (requerido para eliminar operaciones)
- Operador de inventario de la colección (requerido cuando se añada una nueva representación digital)
Crear contenido digital de forma masiva
El flujo de trabajo para subidas en masa en Alma se compone de los pasos siguientes:
- Configurar un perfil digital para importar que diga a Alma cómo gestionar recursos digitales cuando se lleve a cabo una subida masiva a Alma. Para más información, véase Gestionar perfiles de importación.
- Preparar un fichero de metadatos de los registros bibliográficos que el perfil para importar utilice cuando se importen los ficheros. Para más información, véase Preparar el fichero XML de metadatos y Preparar el fichero CSV de metadatos.
- Cargar los ficheros con sus metadatos a Alma utilizando el Cargador digital. Para más información, véase Cargar los ficheros a Alma.
Cargar los ficheros a Alma
Se usa el Cargador digital de Alma para llevar a cabo subidas en masa de ficheros a Alma. Los títulos (registros bibliográficos) se colocan en la colección que se selecciona cuando se suban. Par más información sobre colecciones, véase Gestión de colecciones.
Cada grupo de ficheros que prepara en Alma para subir se llama una ingesta.
Preparar la ingesta consta de cuatro pasos:
- Crear una ingesta
- Añadir ficheros a la ingesta (incluyendo ficheros MD)
- Cargar los ficheros
- Enviar la ingesta
La información de la carpeta de la ingesta se guarda en el almacenamiento local de su navegador. Por lo tanto, si se accede al Cargador desde otro navegador (o desde el mismo navegador, pero iniciando sesión como otro usuario), o si se limpia el almacenamiento local del navegador, no se podrán ver las carpetas de ingesta previamente creadas. Esto no afecta a los datos que ya se enviaron.
Para cargar y enviar ficheros a Alma:
- Abra la página del Cargador digital (Recursos > Herramientas avanzadas > Cargador digital).
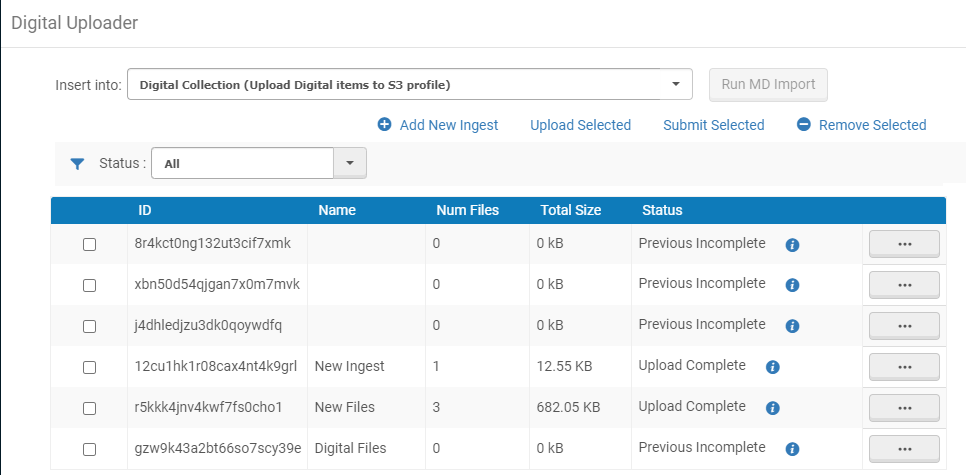
- En la lista desplegable de Agrear en, seleccionar la colección en la que colocar los ficheros y el perfil digital para importar que defina la forma en la que se van a importar los ficheros en la colección.
- Añada los ficheros para enviar a Alma mediante una de la siguientes acciones:
- Arrastrar y soltar – Añadir una ingesta arrastrando y soltando una carpeta en la Lista de ingestas y añadir los ficheros a una ingesta existente arrastrando y soltando los ficheros en una ingesta en la Lista de ingestas.
Arrastrar y soltar la carpeta actualmente es solo compatible con Chrome. Se pueden arrastrar y soltar ficheros usando los navegadores compatibles.
- Con la casilla de Añadir ingesta nueva:
- en la página del Cargador digital, seleccionar Añadir ingesta nueva. Aparecerá lo siguiente:
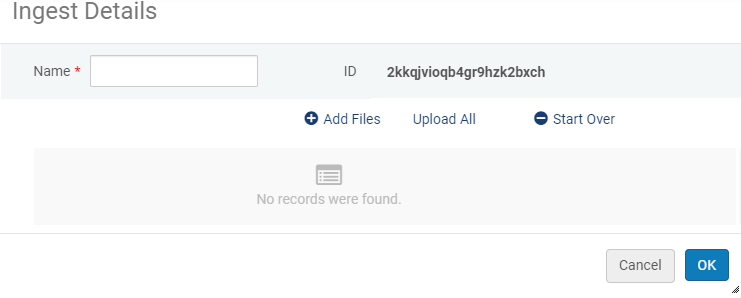 Añadir ingesta nueva
Añadir ingesta nueva - Introducir un nombre para la ingesta.
- Seleccionar Añadir ficheros y seleccionar los ficheros que desean subir. El nombre del fichero, el tamaño, y si es posible una miniatura auto-generada para los siguientes formatos de ficheros, aparecerán en la casilla de diálogo de la Ingesta.
- jpg
- png
- mp4
- wav
- m4v
- doc
- ppt
- docx
- pptx
- jpeg2000
- Cada fichero puede tener un máximo de 1 GB.
- Se puede incluir un máximo de 1.000 ficheros en una sola ingesta.
- Para las ingestas por encima de estos límites, puede cargar directamente en el almacenamiento S3. Para más información, consulte la Red de Desarrolladores.
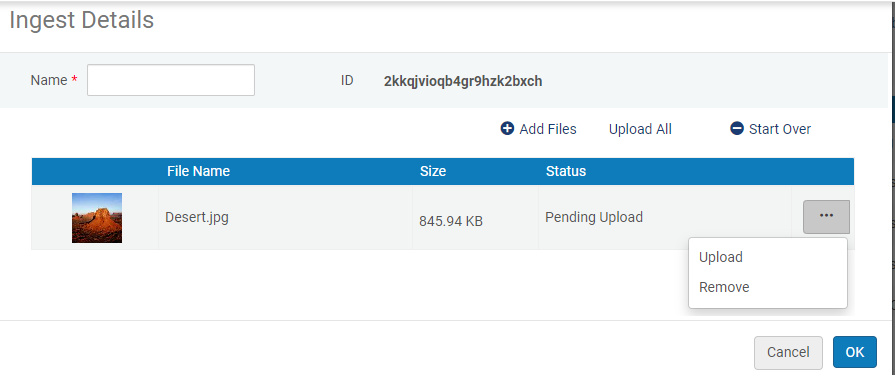 Comenzar la ingesta
Comenzar la ingesta- Puede incluir un fichero en miniatura en la ingesta, que aparecerá en los resultados de búsqueda del repositorio y en el Visor digital, por ejemplo: Para más información, véase Añadir un fichero en miniatura a la ingesta.
- Puede incluir un fichero de subtítulos en formato .vtt con el mismo nombre que el fichero de vídeo en la ingesta para mostrar los subtítulos cuando al reproducir el vídeo. Para obtener más información, consulte El nuevo Visor digital.
- Añadir uno o más ficheros de metadatos para la ingesta (ver Preparar el fichero XML de metadatos o Preparar el fichero CSV de metadatos).
Si no se añade un fichero de metadatos a la ingesta, aparecerá un
 icono de advertencia en la lista de ingestas.
icono de advertencia en la lista de ingestas. - Para cargar un fichero en la ingesta, seleccionar Cargar. Para cargar todos los ficheros en la ingesta a la vez, seleccione Cargar todo. Para quitar los ficheros y comenzar de nuevo, haga clic en Comenzar de nuevo.
- Seleccionar Aceptar para volver a la página del Cargador digital. Véase Cargador digital.
- en la página del Cargador digital, seleccionar Añadir ingesta nueva. Aparecerá lo siguiente:
- El ID de la ingesta
- El nombre de la ingesta
- El número de ficheros en la ingesta
- El tamaño total de la ingesta
- El estado de la ingesta. Los siguientes son los posibles estados:
- Nuevo – La ingesta no contiene ningún fichero.
- Pendiente de cargar - La ingesta no se ha cargado.
- Carga completada – La ingesta no se ha enviado.
- Enviado – La ingesta se ha enviado.
- Para eliminar un fichero de una ingesta, seleccione el botón de la acción de la lista de acciones desplegables para la ingesta y después seleccione Borrar.
- Para quitar una ingesta, seleccione la ingesta y Eliminar seleccionado.
- Arrastrar y soltar – Añadir una ingesta arrastrando y soltando una carpeta en la Lista de ingestas y añadir los ficheros a una ingesta existente arrastrando y soltando los ficheros en una ingesta en la Lista de ingestas.
- Para cargar ingestas, seleccionar las ingestas y seleccionar Cargar.
- Para enviar ingestas para procesar, seleccionar las ingestas que se desea enviar y seleccionar Enviar selección.
- Se necesita el paso de enviar para que se puedan continuar añadiendo de forma segura ficheros a su ingesta, lo cual no está procesado hasta que se seleccione Enviar.
- El campo Nombre del Fichero de Metadatos en el perfil de importación asociado con la ingesta debe contener la ruta y el nombre del fichero correctos del fichero de metadatos para que la ingesta sea enviada.
- Por lo general, la tarea de Importar MD está programada para que se lleve a cabo. Para ejecutar la tarea de importar MD manualmente, seleccionar Ejecutar tarea de importación.
La tarea de Importar MD se ejecuta y la ingesta se procesa.
Los ficheros con más de 30 días (con la excepción de ficheros bloqueados) se eliminan con la tarea de mantenimiento semanal.
Preparar el fichero XML de metadatos
Para que el Cargador digital para lleve a cabo una carga masiva de ficheros, se puede preparar un fichero XML ya sea en formato MARC o DC con metadatos para los registros bibliográficos. Cada fichero de metadatos puede contener información para múltiples registros bibliográficos. Alma crea los registros bibliográficos y representaciones para los ficheros con la información en dicho fichero de metadatos.
Los elementos de registro en el fichero deberían introducirse en un único elemento de colección.
El tipo de información que se necesita en el fichero de metadatos depende de cómo se configure el perfil para importar. Por ejemplo, si se configuró el fichero para importar para buscar el nombre del fichero en el campo MARC 856 subcampo u, el fichero de metadatos debe contener esta información en este campo.
Si el registro bibliográfico contiene información de la colección, el registro se asignará a la colección indicada en el registro. De lo contrario, el registro se asignará a la colección seleccionada como la Asignación de colección por defecto en el perfil de importación digital.
Asignación de Colección MARC XML
Para registros MARC, si se activa un proceso de normalización que contiene la addBibToCollectionNormalizationTask, la importación asigna el registro a una colección según la siguiente prioridad de reglas:
- Si MARC 787$w contiene una ID de colección válida de Alma, el registro se asigna a esta colección.
- Si MARC 787$o contiene los valores del sistema externo y los campos de ID externos, como se ha configurado en una colección que ya existe en Alma, el registro se asigna a esta colección. El campo debe contener el sistema y el ID en el siguiente formato: ({system}){ID}, por ejemplo: (Rosetta)123454321 (similar a la estructura del campo 035).
- Si MARC 787$t contiene el nombre de una colección de alto nivel de Alma, el registro se asigna a esta colección.
- Si nada de lo anterior es relevante, el registro se asigna a la colección de Alma definida como por defecto en el perfil de importación.
Cuando se carga un fichero de metadatos con un registro único no se necesita ningún campo 856. El registro creado incluye todos los ficheros que están en la carpeta de ingesta.
Lo siguiente es un ejemplo de un fichero XML de metadatos:
<?xml version="1.0" encoding="UTF-8" ?>
<collection>
<record>
<leader>01139cam a2200277 a 4500</leader>
<controlfield tag="001">ocm27832725113 </controlfield>
<controlfield tag="003">OCoLC</controlfield>
<controlfield tag="005">20131108731707.4</controlfield>
<controlfield tag="008">970910r19451931pk b 000 0 eng </controlfield>
<datafield tag="035" ind1=" " ind2=" ">
<subfield code="a">(OCoLC)27832725113</subfield>
</datafield>
<datafield tag="100" ind1="1" ind2=" ">
<subfield code="a">Representation of rec 1</subfield>
<subfield code="b">jpg files</subfield>
</datafield>
<datafield tag="245" ind1="1" ind2="2">
<subfield code="a">Record 1 - Civil war</subfield>
</datafield>
<datafield tag="856" ind1=" " ind2=" ">
<subfield code="a">Soldier on a Horse</subfield>
<subfield code="u">civil war.jpg</subfield>
</datafield>
<datafield tag="856" ind1=" " ind2=" ">
<subfield code="a">North and South</subfield>
<subfield code="u">civil2.jpg</subfield>
</datafield>
<datafield tag="650" ind1=" " ind2="0">
<subfield code="a">Digital items loaded to Amazon</subfield>
</datafield>
</record>
</collection>
<collection>
<record>
<leader>01139cam a2200277 a 4500</leader>
<controlfield tag="001">ocm27832725113 </controlfield>
<controlfield tag="003">OCoLC</controlfield>
<controlfield tag="005">20131108731707.4</controlfield>
<controlfield tag="008">970910r19451931pk b 000 0 eng </controlfield>
<datafield tag="035" ind1=" " ind2=" ">
<subfield code="a">(OCoLC)27832725113</subfield>
</datafield>
<datafield tag="100" ind1="1" ind2=" ">
<subfield code="a">Representation of rec 1</subfield>
<subfield code="b">jpg files</subfield>
</datafield>
<datafield tag="245" ind1="1" ind2="2">
<subfield code="a">Record 1 - Civil war</subfield>
</datafield>
<datafield tag="856" ind1=" " ind2=" ">
<subfield code="a">Soldier on a Horse</subfield>
<subfield code="u">civil war.jpg</subfield>
</datafield>
<datafield tag="856" ind1=" " ind2=" ">
<subfield code="a">North and South</subfield>
<subfield code="u">civil2.jpg</subfield>
</datafield>
<datafield tag="650" ind1=" " ind2="0">
<subfield code="a">Digital items loaded to Amazon</subfield>
</datafield>
</record>
</collection>
Los siguientes son ejemplos de cómo usar el campo MARC 787 para asignar un registro a una colección:
- El siguiente registro:
<datafield tag="245" ind1="1" ind2="4">
<subfield code="a">The politics of our lives :</subfield>
<subfield code="b">the Raising Her Voice in Pakistan experience /</subfield>
<subfield code="c">Jacky Repila.</subfield>
</datafield>
<datafield tag="787" ind1=" " ind2=" ">
<subfield code="w">8131549940000121</subfield>
</datafield>Se añadirá a esta colección: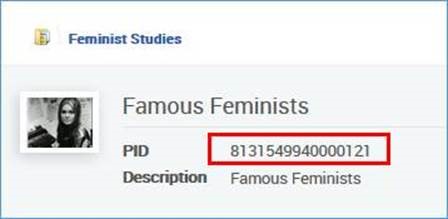 Ejemplo 1
Ejemplo 1 - El siguiente registro:
<datafield tag="245" ind1="0" ind2="0"><subfield code="a">Nuevos feminismos de Asia del sur :</subfield><subfield code="b">paradojas y posibilidades /</subfield><subfield code="c">editado por Srila Roy.</subfield></datafield><datafield tag="787" ind1=" " ind2=" "><subfield code="w">8131549960000121</subfield></datafield>Se añadirá a esta colección:
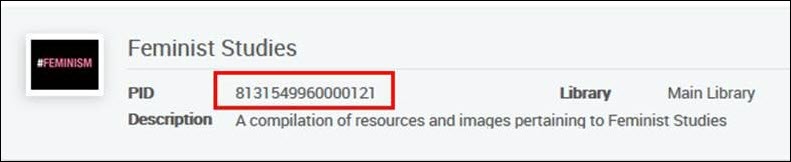 Ejemplo 2
Ejemplo 2
Asignación de colección DC XML
Para DC, si se activa un proceso de normalización que contiene la addBibtoCollectionNormalizationTask, Alma verifica los campos dc:relation y dcterms:isPartOf. Alma verifica cada uno de estos campos en el siguiente orden y asigna los registros importados a esa colección.
- Por ID de colección interna:
<dc:relation>alma:{INST_CODE}/bibs/collections/{COLLECTION_ID}</dc:relation>
- Por ID de colección externa:
<dc:relation>any text</dc:relation>
- Por nombre de colección (solo nivel superior):
<dc:relation>any text</dc:relation>
- Por colección por defecto (solo si 1-3 no coinciden con una colección existente).
Asignación de la colección MODS XML
Crear la regla de normalización Añadir bib a la colección para MODS. Esto funciona como en el caso de DC, permite la asignación según el ID de la colección, el ID externo de la colección y el Nombre de la colección:
- <relatedItem@type="host"><identifier>alma:{INST_CODE}/bibs/collections/{COLLECTION_ID}</identifier></relatedItem>
- <relatedItem@type="host"><identifier>{external_id}</identifier></relatedItem>
- <relatedItem@type="host"><identifier>{collection_name - top level only}</identifier></relatedItem>
Preparar el fichero XML de metadatos
Para usar el Cargador digital a fin de realizar una carga masiva de ficheros, se puede preparar un fichero CSV con metadatos para los registros bibliográficos. El fichero CSV está basado en inventario, lo que significa que cada fila representa una representación. Cada fila puede tener toda la información bibliográfica (que genera un nuevo registro bibliográfico) o puede hacer referencia a un registro bibliográfico existente, coincidiendo por reglas de coincidencia y añadir inventario digital al registro bibliográfico de referencia. El contenido a nivel de fichero está incluido en la misma fila, que contiene toda la ruta del fichero (relativa a la carpeta de ingesta) y una etiqueta (opcional). Son compatibles múltiples ficheros por representación. Múltiples representaciones por registro bibliográfico están representadas por dos columnas que contienen todo el registro bibliográfico (con reglas para prevenir la creación de múltiples registros). En este caso, asigne a las representaciones el mismo group_id para que Alma sepa que las representaciones forman parte del mismo registro bibliográfico.
El fichero CSV debe tener la codificación UTF-8 (no UTF-8-BOM).
Cuando se importen metadatos, se pueden proporcionar los registros CSV con un sistema externo y una ID para asignarlos a una colección, en la columna de collection_external (con el mismo formato que con los registros MARC). El campo es repetible.
El CSV puede contener cuatro tipos de campos:
- Colección – reservada para asignación de colección. Contiene el nombre o ID de una colección (collection_name solo es colección de nivel superior) para el registro bibliográfico al que se ha asignado. Este campo es opcional. (Si los campos de la colección no existen, el registro bibliográfico se asigna a la colección por defecto definida en el perfil MD de importación). Repetible.
Si el formato del objetivo se configura a MARC en el fichero de importación, los nombres de encabezado de CSV se mapean a los campos MARC de la siguiente forma:
- collection_name – 787 t
- collection_id – 787 w
- collection_external – 787 o
Si el formato de destino se configura como Dublin Core en el perfil de configuración, los nombres de encabezado del CSV se mapean en el campo dc:relation.Se debe configurar la regla de normalización Añadir BIB a la colección en el fichero de importación para que la tarea de importación asigne la colección de acuerdo con estos campos. De lo contrario se usará la colección por defecto. - Campor de nivel-registro bibliográfico – Existen dos subtipos:
- mms_id y originating_system_id – usados para registros de coincidencias para registros existentes. Ambos campos pueden existir, si se desea que coincidan con mms_id y añadir un originating_system_id (esto se gestiona con reglas). mms_id no es repetible.
- Otros campos de registros bibliográficos – Mapear en el formato MD de destino de acuerdo con la tabla en la red del desarrollador (https://developers.exlibrisgroup.com/alma/integrations/digital/almadigital/ingest. Ver la tabla para ver los detalles de repetibilidad. (Los campos no repetibles están marcados como NR).
- Campos de nivel-representación – mapea las propiedades de la representación. Campos reservados que no son repetibles (excepto rep_note).
- Campos de nivel-fichero. Repetible.
El contenido CSV se debería crear y gestionar de acuerdo con el análisis de Excel. Por ejemplo: los campos con comas se deben de poner entre comillas:
Guerra y Paz,“Tolstoy, Leo”,1862,...
Todos los carácteres compatibles con MARC XML son compatibles con csv.
Para ver un ejemplo de un fichero CSV, ver Ejemplo CSV.
Mapeo de CSV a Dublin Core
Cuando se seleccione CSV como el formato de fuente física y Dublin Core como formato objetivo, Alma convierte la información en el registro CSV al formato Dublin Core. La mayoría de las coincidencias son intuitivas, por ejemplo: colaborador mapea a dc:contributor. De todas formas, téngase en cuenta lo siguiente:
- MMS_ID solo se debe utilizar para hacer coincidir un MMS ID de Alma existente. La sintaxis es: alma:{INST_CODE}/bibs/{MMS_ID}. Este campo no se almacena como parte del registro importado.
- ISBN y ISSN mapeado a <dc:identifier xsi:type="dcterms:URI"> con el prefijo urn.
- Originating_system_id mapea a dc:identifier.
- Para colecciones, colección_id se mapea a dc:relation en el siguiente formato: <Inst-code>/bibs/collections/<collection id>
- Todos los campos son repetibles y ninguno es obligatorio.
- Se recomienda vocabulario tipo DCMI para tipo (con la excepción de la colección, que no debería de usarse).
- Es compatible mapear múltiples representaciones para un solo registro bibliográfico asignando a las representaciones el mismo group_id.
- Son compatibles la codificación de esquemas e idiomas. Se requiere el formato ISO 639-1 para un código de idioma de dos letras, y el ISO 639-2/3 para un código de idioma de tres letras.
La sintaxis es la siguiente:
- solo codificar – property.schema (por ejemplo: dc:subject.dcterms:LCSH)
- solo idiomas – property lang=\{2 or 3 letter code} (por ejemplo: dc:subject lang=en)
- tanto codificación como idiomas – property.schema lang=\{2 or 3 letter code} (por ejemplo: dc:subject.dcterms:LCSH lang=en)
Preparar el fichero de metadatos de Excel
Para información sobre cómo preparar el fichero de metadatos de Excel, véase Importar registros con ficheros CSV o Excel.
Añadir un fichero de miniatura a la ingesta
Se puede añadir un fichero de miniatura a la ingesta (solo formatos jpg, png, gif) con el mismo nombre que el fichero digital con la extensión .thumb. Por ejemplo:
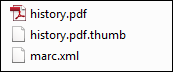
Fichero de miniatura
Esto permite a Alma almacenar la imagen .thumb como miniatura para el respectivo fichero. La miniatura aparecerá en los resultados de búsqueda deL repositorio, en el Visor Digital y en Primo.
Añadir un fichero de texto completo en la ingesta
Puede añadir a la ingesta un fichero de texto completo en formato de texto plano o en formato ALTO, con el mismo nombre que el fichero digital y con una extensión .text.plain o .text.alto. Esto permite realizar búsquedas de texto para la imagen en el Visor del lector de libros.