
Useful Custom Formulas for Esploro Analytics
- Product: Esploro
Background
Esploro Analytics (aka Oracle Business Intelligence, or OBI) is a general purpose reporting and business intelligence tool, which does not automatically "understand" data structures common in the academic world (such as ISBN/ISSNs).
The custom formulas below have helped users manipulate data available in Analytics that was not originally formatted in a way that was useful for their reporting needs. These formulas can be easily changed to work for other types of fields or data.
Two of the most commonly used functions are regexp_substr and regexp_replace. One thing to note about regexp_substr, regexp_replace and other Evaluate functions is that sometimes you must use two single quote characters instead of a double quote to avoid "syntax errors" in OBI.
Instructions
To add or edit a formula in an Analytics report:
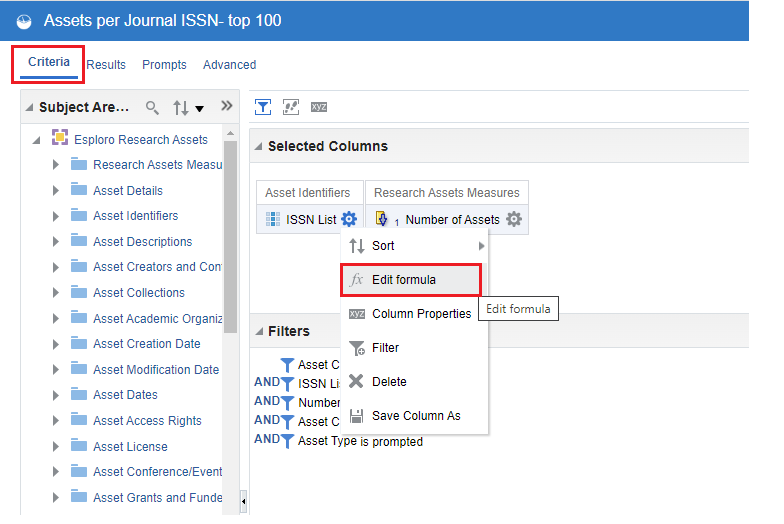
1. Open the 'Criteria' tab of your report. Select the configuration menu of the field you would like to change, select 'Edit Formula'.
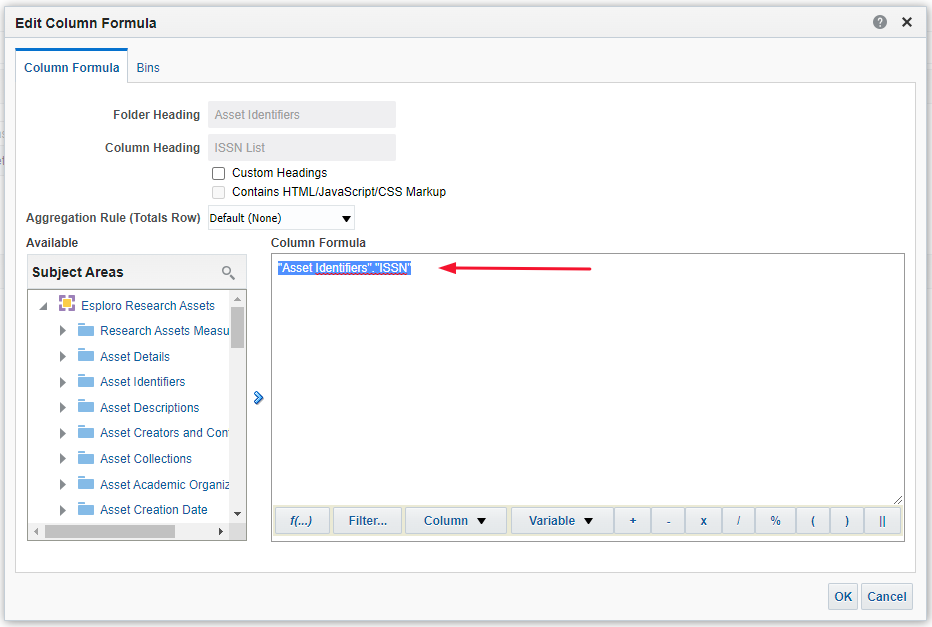
2. In the 'Column Formula' text box, replace the current formula with your custom formula and click 'OK'.
Example formulas
Count the occurrences of a pattern (in this case the number of semicolons, which can be used to confirm how many values appear in a multi-value row):
Evaluate('regexp_count(%1,''\;'')',"Researcher Details"."Honors")
Retrieve the first occurrence of a string (change the last 1 to 2, 3, etc. for the second, third, etc. occurrence):
Evaluate('regexp_substr( %1, ''[^\;]+'', 1,1)', "Researcher Details"."Honors")
Retrieve the second occurrence of a string (change the last 1 to 2, 3, etc. for the second, third, etc. occurrence):
Evaluate('regexp_substr( %1, ''[^\;]+'', 1,2)', "Researcher Details"."Honors")
Retrieve the last occurrence of a string (in this example the delimiter is ; , the ‘$’ character in regexp means the end of the string, the ‘^’ is beginning ):
Evaluate('regexp_substr( %1, ''[^\;]+$'', 1,1)', "Researcher Details"."Honors")
Remove duplicate ISSNs from the ISSN field:
ifnull(evaluate( 'regexp_replace( %1, ''([^\;]+)(\;[ ]*\1)+'')',"Asset Identifiers"."ISSN"), Evaluate('regexp_substr( %1, ''[^\;]+'', 1,1)', "Asset Identifiers"."ISSN"))
Combine two fields into a single field using a delimiter (in this example - ):
"Researcher Details"."Researcher Name" || ' - ' || "Researcher Details"."Current Internal Organization Affiliations Names List"
- Article last edited: 20-Apr-2020