
CDI中的匹配和合并
简介
CDI中的内容来自多个来源,包括出版商、内容集成者、开放获取仓储、机构知识库等等。 我们总共获取了超过2000个来源,因此有时对于一个引文可能会有多个记录。 单独显示所有这些记录可能会对用户造成困惑,并使得用户更难在结果中找到需要的内容。
但是,我们也在努力尽可能呈现最高质量,最详细,最完整的可用元数据,与此同时向用户提供最可行的方法访问内容。 为了尽可能的使可用的元数据达到要求,并减少重复和模糊的信息,我们使用匹配&合并进程。
匹配&合并是一组标准用于控制记录(“纸本记录”)是否可以合并为综合的记录(“逻辑记录”)。 在这些逻辑记录中,来自纸本记录的可用元数据综合为一个可以对终端用户显示更完善内容的记录。 下图显示该进程的简要表现。

匹配&合并:规则
匹配&合并基于多种标识符: 如果多个记录共享相同的标识符,根据标识符判断它们也满足其他标准后可以合并。 大多数内容类型都可用匹配&合并,尽管有一些在特定情况下除外,还有一些完全除外(见匹配&合并过滤器)。
请注意,“模糊题名匹配”比较两个记录的DocumentTitle和DocumentSubtitle字段,忽略大小写、空格、表点、变音符号和其他特殊字符。
外部标识符:
- DOI - 也需要模糊题名匹配,不适用于期刊/电子期刊
- PMID - 也需要模糊题名匹配,不适用于期刊/电子期刊
- ISBN/EISBN - 也需要模糊题名匹配,出版年份的区别必须不超过一年
- ISSN/EISSN - 出版地或出版年份必须匹配,仅适用于期刊/电子期刊
- LCCN - 对于期刊/电子期刊,出版地或出版年份必须匹配;对于图书、电子书、毕业论文和政府文件,需要模糊题名匹配,以及出版年份必须匹配
- OCLC - 和LCCN的额外标准一致
内部标识符:
有ISBN、EISSN、ISBN或EISBN的记录分配与相关题名对应的Ex Libris内部标识符。 匹配&合并在不同情况下使用该标识符,题名层级和出版层级的记录的进程处理不同。
- 出版层级: 适用于报纸、杂志、期刊、电子期刊、图书和电子书。 只需要题名层级的标识符匹配。
- 文章层级:适用于期刊文章、杂志文章、报纸文章、贸易出版物文章、书评和会议录。 除了题名层级标识符,文件题名、出版年份、卷、期和起始页面都需要匹配。
其他情况:
- 参考咨询记录可以仅根据模糊题名匹配合并
- 毕业论文记录可以仅根据URI(直接链接)匹配合并
匹配&合并过滤器
过滤器就是规则的反面: 它们指示哪些情况下不能合并记录。 请注意,在过滤器和规则都适用时,适用过滤器。
不匹配的元数据: 如果任何以下的数据节点不匹配,记录将不会合并。
- DOI
- PMID
- URI(如果记录来自相同的内容提供者的相同内容结果集)
- 语言(可被记录来源元数据中的语言指示影响,或您的系统检测到的记录元数据的语言)
除外的内容类型:
- 归档资料
- 图像
- 缩微
- 音乐录音
- 专利
- 报告
- 技术报告
- 标准
- 录像
其他过滤器:
- 识别为来自机构知识库的记录不会合并
- 内容类别为报纸文章且出版日期早于2000年1月1日的记录不会合并
- 记录除外标记: 可以标记特定记录从匹配&合并进程除外,这通常根据内容提供者或上传客户的要求进行
- 请注意:以下内容提供者已要求对它们的全部记录标记除外:
-
Artstor
-
CABI Direct content
-
CAIRN International Journals
-
- 请注意:以下内容提供者已要求对它们的全部记录标记除外:
-
“糟糕的题名”:我们维护一份含有不希望合并以避免产生错误的简短且常见的题名内部列表
-
过多匹配:索引中有超过4000个记录含有同一题名的记录不会合并
传递性合并
“传递性合并”是在三个或多个记录合并时,至少两个记录无法合并的情况。 例如,下表中,记录A可以与B合并,记录B可以与C合并,但是A无法与C合并。 但是因为A和C与B的共性,所有三个记录可以合并到相同的逻辑记录。
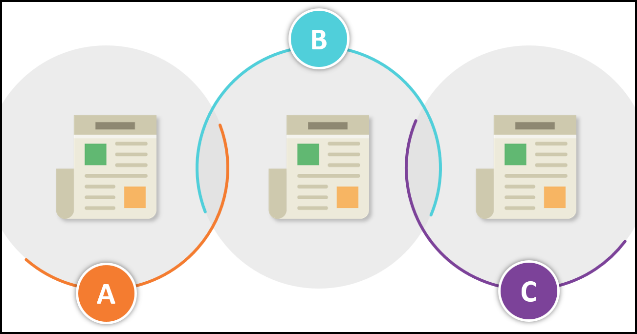
匹配&合并:如何影响用户的CDI检索体验
匹配&合并多方面地提高CDI的检索能力。
更好的可发现性
与单独检索纸本记录相比,使用由匹配&合并创建的逻辑记录提高单册的可发现性 这是因为逻辑记录继承参与记录的所有字段值。 例如,如果特定字段值有变体,比如题名和著者名字,除了参与的纸本记录,它们也包含在逻辑记录中。 类似地,如果只有部分参与纸本记录提供全文、参考、标识符或其他元数据,它们都会包含在逻辑记录中用于发现,不管图书馆的来源启用状态如何。
提高的检索效率
使用逻辑记录也会提高检索效率。 首先时因为逻辑记录的数量远少于参与记录,其次是因为无需在检索时将相同单册的记录集合在一起。 这样的话,检索响应时间就会更快,检索系统可以处理更多的检索。 对于大型索引,例如CDI这种大小不断增加的索引,该方法可以提供快速且持续的检索体验。
快速更新
因为匹配&合并在CDI主索引每次更新时发生,对纸本记录的完善会快速反映在逻辑记录中。 这提高了所有与更新的逻辑记录关联的纸本记录的可发现性。 这使得CDI成为一个动态的索引。
分面
分面检索(根据分面过滤检索结果)使用逻辑记录。 例如,当用户在内容类型分面中点击“文章”时,CDI根据逻辑记录的内容类型过滤检索结果。 分面计数(例如 ,与分面值相关的计数)根据逻辑记录中的值计算。
记录显示
记录显示,例如显示在检索结果视图中的题名、著者和片段,以及显示在详情视图中的元数据字段,都是基于图书馆有访问权限的记录(例如,来自图书馆已启用的来源或本身免费可用的记录)。 来自图书馆没有访问权限的参与记录的逻辑记录的字段值不会显示。 此外,CDI应用逻辑从可显示的参与记录的所有字段值中选择最合适的字段值显示。 我们区别单个来源字段和多个来源字段。 单个来源字段为只含有唯一值,例如题名、计数级别、日期、DOI以及可以有多个值的字段(例如著者字段)。 对于有多个值的字段,所有内容都取自同一来源以保证一致性。
对于有唯一值的字段,例如题名,CDI会返回最高优先级的来源类型的参与者的值,首选主出版商数据而不是聚合数据。 开放获取和机构知识库以及其他非特定来源的优先级最低。 如果相同来源类型的参与者有多个不同的值(例如,相同题名的每个参与者的版本有轻微不同),CDI选择出现次数最多的值。 对于可以有多个值的字段,CDI根据来源类型选择。 多来源字段,例如主题字段、ISBN和ISSN,返回图书馆有访问权限的所有参与者的所有可用的值(去重)。
通过使用该逻辑,会显示最合适的元数据,充分考虑客户需求。 但是,因此也有一些匹配检索词可能不会显示在记录的详情视图中,因为对一个参与记录匹配时逻辑记录可能显示轻微不同的元数据。 这会,例如,导致主题由于来自没有权限的参与者而不显示。 它仍可被检索并能在记录中找到。 而且,请注意,对特定文档ID的检索只会访问来自该参与记录的元数据。 您可以会在某些有差异的元数据字段链接到一个记录,这取决于是根据检索文档ID还是检索关键词找到的记录。
匹配&合并FAQ
-
我的本地记录是否参与匹配和合并进程?
本地Primo索引中的本地记录不会与来自CDI的记录匹配和合并。 但是由客户上传到CDI的记录可以合并。
-
匹配和合并是否会对某些提供者提供优先级?
不会。匹配和合并保持供应商中立。
-
来自组成逻辑记录的多个纸本记录的特定字段的相同值是否会合并(去重)显示、检索等?
会。例如,相同的主题会去重,这样您只会在一个记录中看到一个主题一次,而不是多次。
-
不同内容类型的记录能否合并?
能,但是有以下限制: 达到至少一条规则标准,且没有被任何过滤器限制的记录可以合并。 有些规则仅用于特定内容类型,其他规则应用于全部内容类型,除特定除外之外;见匹配&合并: 规则和匹配&合并:过滤器部分。
-
如何可以提交改善匹配和合并进程的建议?
请提交有关更改规则、新规则或其他变更的建议到Idea Exchange。 如果想要报告记录没有正确合并的问题,请提交支持工单。
-
为什么我的检索词没有显示在返回的记录中?
如果检索结果的记录详情视图没有显示匹配检索词,有以下几种可能:
-
它们与由匹配&合并创建的逻辑记录中的元数据字段匹配,但是匹配的值没有包含在来自图书馆有访问权限的参与纸本记录的显示字段中。 有关详情,见匹配与合并: 如何影响用户的CDI检索体验。
-
它们在全文字段中匹配但是没有从全文创建片段。 来自全文的片段为全文的前1,000个字符,因此如果检索词没有出现在全文的开头,不会生成片段。 此外,某些来源的来自全文的片段创建由于内容提供商的合同协议屏蔽。 如果题名为记录的文献列表的一部分且文献列表被索引,此类匹配也适用于整个题名。 此类匹配在结果列表中出现的机率远小于题名或主题匹配(另见字段权重)。
-
-
为什么我用于过滤的分面值没有在返回记录中显示?
与常规检索一样,分面过滤使用由匹配&合并创建的逻辑记录。 由于记录显示基于图书馆的访问权限,用于分面过滤的字段值可能不会显示在详情记录显示中。 有关详情,见匹配与合并: 如何影响用户的CDI检索体验。