
Funcionalidades lingüísticas de Primo VE
Esta sección describe las distintas funcionalidades lingüísticas que admite Primo VE. Para una descripción de las características lingüísticas que utiliza el Índice de Descubrimiento Central (CDI), véase Características de búsqueda multilingüe.
Detección de idioma
Para ofrecer servicios basados en idiomas, Primo VE debe detectar primero el idioma del texto indexado y de la consulta. Actualmente, Primo VE puede detectar los siguientes idiomas:
-
Basados en latín: inglés, español, italiano, alemán, francés y danés.
-
Asiáticos: chino, japonés y coreano. Si los caracteres están en chino y la ubicación de Primo VE está en japonés o coreano, Primo utiliza la ubicación del idioma seleccionado.
-
Otros idiomas que poseen un rango de caracteres específico: hebreo, árabe, etc.
La detección de idiomas se basa en comparar las palabras del registro y la consulta con un diccionario. Si el cincuenta por ciento o más de las palabras coinciden, se identifica el idioma.
Palabras reservadas
Las palabras vacías son palabras comunes (como artículos, preposiciones y pronombres) que se filtran de las búsquedas de palabras clave para ofrecer los mejores resultados de búsqueda. Por ejemplo, si un usuario busca las aventuras de huckleberry finn, Primo VE realiza la siguiente búsqueda sin las palabras vacías las y de:
Para frases exactas (como "las aventuras de huckleberry finn"), Primo VE realiza la siguiente búsqueda para proporcionar resultados más precisos:
"las aventuras de huckleberry finn"
Para obtener una lista de las palabras vacías que Primo VE utiliza para la búsqueda y la indexación, véanse los siguientes ficheros por idioma: Danés, inglés, alemán, español, francés, italiano y chino.
Nombres de autores
Primo VE trata las palabras con apóstrofo O' como si fuera una pausa en muchos idiomas procedentes del Latín y las indexa como si fueran dos palabras separadas. Esto también sucede con autores como O'Leary, que se indexa como o y leary. Como resultado, una búsqueda de Oleary no tendrá el mismo número de resultados que una búsqueda de O'Leary. Cuando los usuarios buscan nombres que suelen incluir apóstrofos, pero no los añaden, Primo VE también buscará el nombre como si los usuarios los hubiesen incluido. Por ejemplo, si la consulta del usuario es Oleary, Primo VE modifica la consulta para buscar oleary u o leary.
Derivación
La derivación es un proceso que reduce palabras flexivas (o a veces derivadas) a su raíz, base o forma de raíz. Cuando se activa la derivación, la forma derivada del término de búsqueda se agrega a la consulta con un impulso muy bajo para mejorar los resultados de la búsqueda. Actualmente, solo los siguientes idiomas admiten esta funcionalidad: Español, italiano, inglés, francés y danés.
-
La derivación funciona independientemente del mecanismo inteligente de búsqueda y rango que aumenta las palabras de consulta adyacentes. Esto permite al sistema mejorar las versiones derivadas de los términos de búsqueda cuando no son adyacentes a otros términos de búsqueda.
-
Primo VE no deja de derivar los términos, excepto en el caso de las pluralizaciones. Si se activa la derivación, Primo VE incluirá la forma plural del término y otorgará a sus resultados un rango inferior. Por ejemplo, una búsqueda de flor silvestre se expande a silvestre Y (flor O flores^0.5).
El parámetro add_keywords_stemming_to_query en la página Ajustes de descubrimiento del cliente (Menú de configuración > Descubrimiento > Otros > Ajustes del cliente) le permite activar/desactivar el uso de la derivación.
Sinónimos
Primo VE añade los siguientes tipos de sinónimos a una consulta de búsqueda:
-
Números – Cuando la búsqueda contiene un dígito, Primo VE añade el número deletreado a la consulta. Por ejemplo, Primo VE añade la palabra noveno a la consulta de búsqueda 9°.
-
Ortografía de EE. UU. o británica – cuando una búsqueda contiene una palabra escrita según la ortografía de EE. UU. o la británica, Primo VE añade el sinónimo correspondiente a la consulta de búsqueda. Por ejemplo, Primo VE añade la palabra colour a una consulta de búsqueda de color.
-
Palabras con errores ortográficos comunes – en el caso de palabras con errores ortográficos comunes, Primo VE añade la palabra correcta a la consulta de búsqueda.
-
Términos de búsqueda con guion – Las búsquedas en el repositorio local que incluyen un término de búsqueda con un guion devuelven resultados adicionales al incluir la palabra compuesta del término en la búsqueda. Por ejemplo, las búsquedas del término chat-room también incluirán resultados para chat room y chatroom. Anteriormente, el sistema solo agregaba resultados para chat room. Los términos admitidos se basan en los mismos términos empleados para los resultados CDI (consulte Palabras compuestas admitidas).
Además del sinónimo, Primo VE incluye el término de búsqueda original en la consulta. Por ejemplo, Primo VE busca (quinta O 5ª) Y dimensión si la consulta es quinta dimensión.
Primo VE aplica una lista de sinónimos diferente según el reconocimiento del idioma.
El siguiente parámetro en la página Ajustes de descubrimiento del cliente (Menú de configuración > Descubrimiento > Otros > Ajustes del cliente) permite deshabilitar el uso de sinónimos:
-
disable_synonyms – Cuando se establece en verdadero, este parámetro deshabilita el uso de sinónimos en las consultas de búsqueda. Por defecto, se establece en falso.
Para obtener una lista de los sinónimos admitidos para un idioma, descargue cada fichero cliqueando en el idioma y guardándolo en un fichero: alemán, inglés, francés, hebreo y chino. Dado que esta información se actualiza a petición de los clientes, póngase en contacto con el servicio de Soporte para obtener una lista actualizada.
Quiso Decir:
Las sugerencias de Quiso Decir mejoran las consultas de búsqueda al corregir errores tipográficos y errores ortográficos comunes en los términos de búsqueda, con el fin de devolver los resultados de búsqueda esperados a los usuarios. Se proporcionan sugerencias Quiso Decir cuando la consulta original devuelve menos del umbral de 15 resultados de búsqueda, que no es configurable.
En el siguiente ejemplo, al término de búsqueda leucemia le falta un solo carácter y no devuelve ningún resultado. Los usuarios pueden seleccionar la sugerencia que aparece debajo del cuadro de búsqueda si desean ver los resultados de esa sugerencia.
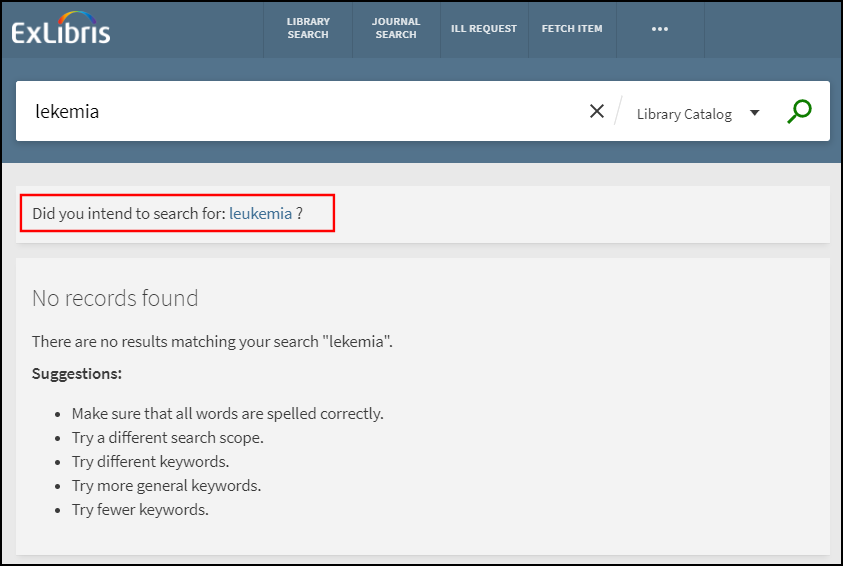
¿Cómo funciona Quiso Decir?
Quiso Decir se activa cuando la consulta de búsqueda original devuelve menos de 15 resultados. Si se activa, el algoritmo Quiso Decir realiza lo siguiente:
-
Por cada término de búsqueda en la consulta original:
-
Se verifican las siguientes fuentes para una coincidencia:
-
Índice Quiso Decir: este índice se crea aplicando la distancia de Levenshtein, que es la distancia entre dos palabras usando un número mínimo de ediciones de un solo carácter (como inserciones, eliminaciones o sustituciones) al índice de títulos regulares. Para Quiso Decir, el índice limita las ediciones a un solo carácter.
Por ejemplo, si la palabra leucemia se indexa en el índice del título normal, los siguientes términos podrían devolver una sugerencia para leucemia:
-
lecemia: falta la letra u.
-
leecemia: la letra u ha sido reemplazada por la segunda e.
-
aleucemia: la letra a se ha agregado al comienzo del término.
-
-
Diccionario: el diccionario contiene palabras comúnmente mal escritas para verificar.
-
-
Por cada coincidencia encontrada, se crea una consulta candidata reemplazando el término en la consulta original con su coincidencia.
-
-
Cada consulta candidata se prueba y, para la sugerencia, se utiliza la candidata de mayor ranking que devuelve suficientes resultados.
Normalización de Caracteres Especiales
En función del idioma de indexación configurado, Primo VE normaliza caracteres especiales y caracteres con signos diacríticos en el índice de búsqueda. Primo VE admite los siguientes idiomas de indexación: alemán (de), islandés (is), lituano (it), noruego/danés (no), sueco (sv), español (es), polaco (po), coreano (ko), chino (zh) y japonés (ja).
Específicamente para Hong Kong, su biblioteca puede decidir usar chino o TSVCC para la conversión de caracteres.
Si desea cambiar su idioma de indexación a uno de los idiomas admitidos, abra una solicitud de soporte en Salesforce. Tengo en cuenta que esto requerirá indexar de nuevo sus datos. Después de completar la reindexación, las búsquedas utilizarán las conversiones de caracteres específicas del idioma descritas a continuación, con independencia del idioma seleccionado en la IU.
Árabe y farsi
| Carácter | Conversión |
|---|---|
| 0627 (آ) | 0622 (ا) |
| 0623 (إ) | 0622 (ا) |
| 0625 (أ) | 0622 (ا) |
| 0649 (ئ) | 0626 (ى) |
| 064A (ي) | 0626 (ى) |
| 0647 (ۀ) | 06C0 (ه) |
| 0629 (ة) | 06C0 (ه) |
| 0642 (ڨ) | 06A8 (ق) |
| 0648 (ؤ) | 0624 (و) |
| 062C (چ) | 0686 (ج) |
| 0628 (پ) | 067E (ب) |
| 0643 (گ) | 06AF (ك) |
| 0632 (ژ) | 0698 (ز) |
| 0641 (ڤ) | 06A4 (ف) |
Danés
| Carácter | Conversión |
|---|---|
| 00E4 (ä) | 0061 0065 (ae) |
| 00C4 (Ä) | 0061 0065 (ae) |
| 00E5 (å) | 0061 0061 (aa) |
| 00C5 (Å) | 0061 0061 (aa) |
| 00D8 (Ø) | 006F 0065 (oe) |
| 00F8 (ø) | 006F 0065 (oe) |
| 00D6 (Ö) | 006F 0065 (oe) |
| 00F6 (ö) | 006F 0065 (oe) |
| 00E6 (æ) | 0061 0065 (ae) |
| 00E6 (Æ) | 0061 0065 (ae) |
-
Para la búsqueda, la conversión no es bidireccional. Por ejemplo, las búsquedas del término Edgar Allan Poe devolverán resultados para Edgar Allan Pö, pero las búsquedas del término Edgar Allan Pö no devolverán resultados para Edgar Allan Poe.
-
Para ordenar y navegar, Primo VE usa el siguiente orden para el alfabeto danés:
-
a/A-z/Z (con Ü/ü ordenada como Y/y)
-
æ/Æ ; ä/Ä
-
ø/Ø ; ö/Ö
-
å/Å ; aa/Aa
-
Alemán
| Carácter | Conversión |
|---|---|
| 00DC (Ü) | 0075 0065 (ue) |
| 00FC (ü) | 0075 0065 (ue) |
| 00C4 (Ä) | 0061 0065 (ae) |
| 00E4 (ä) | 0061 0065 (ae) |
| 00D6 (Ö) | 006F 0065 (oe) |
| 00F6 (ö) | 006F 0065 (oe) |
Noruego
| Carácter | Conversión |
|---|---|
| 00E4 (ä) | 0061 0065 (ae) |
| 00C4 (Ä) | 0061 0065 (ae) |
| 00E5 (å) | 0061 0061 (aa) |
| 00C5 (Å) | 0061 0061 (aa) |
| 00D8 (Ø) | 006F 0065 (oe) |
| 00F8 (ø) | 006F 0065 (oe) |
| 00D6 (Ö) | 006F 0065 (oe) |
| 00F6 (ö) | 006F 0065 (oe) |
| 00E6 (æ) | 0061 0065 (ae) |
| 00E6 (Æ) | 0061 0065 (ae) |
-
Para la búsqueda, la conversión no es bidireccional excepto para los caracteres especiales Å y å. Por ejemplo, las búsquedas del término Edgar Allan Poe devolverán resultados para Edgar Allan Pö, pero las búsquedas del término Edgar Allan Pö no devolverán resultados para Edgar Allan Poe.
-
Para ordenar y navegar, Primo VE usa el siguiente orden para el alfabeto noruego:
-
a/A-z/Z (con Ü/ü ordenada como Y/y)
-
æ/Æ ; ä/Ä
-
ø/Ø ; ö/Ö
-
å/Å ; aa/Aa
-
Islandés
En islandés, las tildes para algunos caracteres no solo indican una pronunciación distinta, sino que también tienen un significado diferente.
Conversiones de carácter
La siguiente tabla enumera los caracteres que requieren de conversión especial. Todos los demás caracteres especiales con tildes y diéresis, como ä, ë, ü, û, è, se convierten a su valor “por defecto” (a, e, u, y así sucesivamente).
| Carácter | Conversión |
|---|---|
| 00C5 (Å) | 0041 0041 (AA) |
| 00E5 (å) | 0061 0061 (aa) |
| 00D8 (Ø) | 00D6 (Ö) |
| 00F8 (ø) | 00F6 (ö) |
Orden de clasificación
La siguiente tabla enumera el orden de clasificación de los caracteres en islandés. Los caracteres destacados en amarillo no se convierten y se ordenan según se indica, lo que significa que las búsquedas de estas letras especiales islandesas deben devolver coincidencias para esa letra especial. No se debe incluir el carácter 'regular'. Ejemplos:
-
Cuando se busca "sál", no se debe devolver la palabra "sal".
-
Cuando se busca «skola» , no se debe devolver la palabra «skóla».
| Carácter mayúscula | Carácter minúscula |
|---|---|
| A (0041) | a (0061) |
| Á (00C1) | (00E1) |
| B (0042) | b (0062) |
| C (0043) | c (0063) |
| D (0044) | d (0064) |
| Ð (00D0) | ð (00F0) |
| E (0045) | e (0065) |
| É (00C9) | é (00E9) |
| F (0046) | f (0066) |
| G (0047) | g (0067) |
| H (0048) | h (0068) |
| I (0049) | i (0069) |
| Í (00CD) | í (00ED) |
| J (004A) | j (006A) |
| K (004B) | k (006B) |
| L (004C) | l (006C) |
| M (004D) | m (006D) |
| N (004E) | n (006E) |
| O (004F) | o (006F) |
| Ó (00D3) | ó (00F3) |
| Ø (00D8) | ø (00F8) |
| P (0050) | p (0070) |
| Q (0051) | q (0071) |
| R (0052) | r (0072) |
| S (0053) | s (0073) |
| T (0054) | t (0074) |
| U (0055) | u (0075) |
| Ú (00DA) | ú (00FA) |
| V (0056) | v (0076) |
| W (0057) | w (0077) |
| X (0058) | x (0078) |
| Y (0059) | y (0079) |
| Ý (00DD) | ý (00FD) |
| Z (005A) | z (007A) |
| Þ (00DE) | þ (00FE) |
| Æ (00C6) | æ (00E6) |
| Ö (00D6) | ö (00F6) |
-
Los resultados de búsqueda se ordenan en el orden de clasificación alfabético islandés anterior.
-
Los valores de ficheros para navegar no normalizan los diacríticos de los caracteres especiales destacados, de forma que la navegación corresponderá al orden de clasificación alfabético islandés.
-
Los datos que contienen caracteres o diacríticos que no se enumeran arriba se comportarán según los ajustes por defecto para el idioma inglés.
Lituano
El idioma lituano contiene 18 letras especiales que son indexadas tal como son: ą, č, ę, ė, į, š, ų, ū, ž, Ą, Č, Ę, Ė, Į, Š, Ų, Ū y Ž.
Polaco
| Carácter | Conversión |
|---|---|
| 0104 (Ą) | 0061 0061 (aa) |
| 0105 (ą) | 0061 0061 (aa) |
| 0106 (Ć) | 0063 0063 (cc) |
| 0107 (ć) | 0063 0063 (cc) |
| 0118 (Ę) | 0065 0065 (ee) |
| 0119 (ę) | 0065 0065 (ee) |
| 0141 (Ł) | 006C 006C (ll) |
| 0142 (ł) | 006C 006C (ll) |
| 0143 (Ń) | 006E 006E (nn) |
| 0144 (ń) | 006E 006E (nn) |
| 00D3 (Ó) | 006F 006F (oo) |
| 00F3 (ó) | 006F 006F (oo) |
| 015A (Ś) | 0073 0073 (ss) |
| 015B (ś) | 0073 0073 (ss) |
| 0179 (Ź) | 007A 007A (zz) |
| 017A (ź) | 007A 007A (zz) |
| 017B (Ż) | 007A 0065 (ze) |
| 017C (ż) | 007A 0065 (ze) |
Español
| Carácter | Conversión |
|---|---|
| 00D1 (Ñ) | 00F1 (ñ) |
| 00F1 (ñ) | 00F1 (ñ) |
| 00C7 (Ç) | 00E7 (ç) |
| 00E7 (ç) | 00E7 (ç) |
| 0140 (ŀ) | 0140 (ŀ) |
| 013F (Ŀ) | 0140 (ŀ) |
Sueco
| Carácter | Conversión |
|---|---|
| 00E4 (ä) | 0061 0065 (ae) |
| 00C4 (Ä) | 0061 0065 (ae) |
| 00E5 (å) | 0061 0061 (aa) |
| 00C5 (Å) | 0061 0061 (aa) |
| 00D8 (Ø) | 006F 0065 (oe) |
| 00F8 (ø) | 006F 0065 (oe) |
| 00D6 (Ö) | 006F 0065 (oe) |
| 00F6 (ö) | 006F 0065 (oe) |
| 00E6 (æ) | 0061 0065 (ae) |
| 00E6 (Æ) | 0061 0065 (ae) |
-
Para la búsqueda, la conversión no es bidireccional. Por ejemplo, las búsquedas del término Edgar Allan Poe devolverán resultados para Edgar Allan Pö, pero las búsquedas del término Edgar Allan Pö no devolverán resultados para Edgar Allan Poe.
-
Para ordenar y navegar, Primo VE usa el siguiente orden para el alfabeto sueco:
-
a/A-z/Z (con æ/Æ ordenada como ae/Ae; Ü/ü se ordena como Y/y)
-
å/Å
-
ä/Ä
-
ö/Ö ; ø/Ø
-