
Search and Ranking in CDI
This page discusses some of the search (standard and multilingual) and ranking features available in the Ex Libris Central Discovery Index (CDI). In some paragraphs it refers to the full text field. Please note that whether this field is searched at all is dependent on your settings. By default, the search is not extended to the full text. For more information, see Full Text Indexing in CDI. For More information about the merged record (such as what data is searchable and how it is displayed), see Match and Merge in CDI.
-
For CDI the fields in the Search section in the PNX are searchable, but they are not the only fields indexed by CDI and used for search and ranking. This means that they may not be searched the same way as they were for Primo Central.
-
The DBIDs listed in the Search section may not show a true representation of the active collections in Alma/SFX. Please use your activation tool to check which collections are responsible for the appearance of a record in Primo.
Standard Search Features
CDI collections in Alma with Search Rights: Subscription require patrons to be logged on to Primo or to be on campus (within a valid IP range) to obtain search results.
Phrase Search
Enclosing multiple query terms in double quotes (“…") limits results to phrase matches. For example, a search for "computational linguistics" (in double quotes) will return phrase matches with computational linguistics, but not linguistics and computational chemistry or computational chemistry and linguistics. However, a phrase search will match other variations of a word or character in the phrase. For example, a search for “neural network” in its singular form will also match neural networks in its plural form. A search for "street facade" would match both "street facade" and "street façade". Phrase searches can be used for languages that do not use whitespace between words, such as Chinese, Japanese and Thai. For example, a search for "東京の歴史" (in double quotes) will match the exact phrase 東京の歴史 but not 東京の文化と歴史.
There are two exceptions to the phrase matching related to stop words. The first exception is the handling of stop words in the full text field. Unlike metadata, CDI does not index stop words in the full text field. As a result, matches with stop words within a phrase are not guaranteed for the full text field. For example, a search for "research for motion" can match "research in motion" since "for" and "in" are English stop words. As full text matches are ranked far lower than metadata matches, material with the exact phrase in the metadata will almost always outrank them in the result list. However, full text matches can become important if there are no or very few results with the exact phrase in the metadata, and it can lead to other relevant findings. On the downside, they contribute to a longer tail of results that may be less or not relevant to the users’ intentions. Another exception is that stop words which are placed at the end of a phrase are currently dropped from the phrase search. For example, a search for "there she was" drops the word "was" and match phrases such as "there she is" since the word "was" is defined as a stop word for English.
Phrase searching also increases the effect of the verbatim match boost feature. The verbatim match boost feature is part of CDI's relevance ranking algorithm, which boosts the relevance scores of verbatim matches – namely, the matches that do not match via character normalization, stemming or other multilingual search features. For example, searching for "heavy metals" (in double quotes) will emphasize that phrase over heavy metal to a much larger degree than the non-phrase search for heavy metals (without double quotes).
Using this property, double quotes can be used even on a single term when it is important to emphasize verbatim matches. For example, if a search for résumé (without double quotes) is returning undesirable matches for resume as top results, enclosing the search term in double quotes (for example, "résumé") will further emphasize the verbatim match over the non-verbatim matches.
Clarification about "Exact" Matching
There are a few levels of "exact" matches between a search query and indexed text.
-
Phrase matching - In this documentation, phrase matching or exact phrase matching refers to matches where the words in a phrase are in the same order between the search query and the indexed text. For example, the following is a phrase match: query = computational linguistics and indexed text = computational linguistics. But the following is not an exact phrase match: query = "computational linguistics" and indexed text = linguistics and computational chemistry.
-
Verbatim matching - In this documentation, we refer to verbatim matching as word-level matching, where words did not match via stemming, character normalization, synonym mapping, or any other processes. For example, "English book" vs. "English books" is an exact phrase match, but it is not a verbatim match.
-
Exhaustive matching (or exact title matching, exact subject matching, and so forth) - This type of matching refers to phrase matches that also completely match field values. For example, query="American history" is an exact phrase match for the title "19th Century American History", and it is not an exhaustive match.
-
Exact string matching - While all the above allow variations in casing (for example, "Book" vs. "book"), the number of spaces between words (for example, "computational linguistics" with one space vs. "computational linguistics" with two spaces), and the use of punctuation symbols (for example, "Paris, Texas" vs. "Paris Texas"), exact string matching requires exact matches at the character-level. This type of matching is typically required for Identifier fields.
CDI's phrase searching supports "exact phrase matching" for the default search fields, such as the title, author, and abstract fields.
Boolean Operators
CDI supports the following Boolean operators: AND, OR, and NOT. They must be written in all capital letters to ensure that they are interpreted as Boolean operators by the system.
-
The AND operator – This operator ensures that matching records include both search terms (such as cats AND dogs). When there is no explicit Boolean operator between two terms, the AND operator is assumed. For example, if you search for earthquake fault, you will get the same result set as if you had searched for earthquake AND fault. Note that the relevance ranking of the result sets may be different since a search without the operator applies higher relevance scores to phrase matches (such as earthquake fault).
-
The OR operator – This operator allows users to search for multiple terms, but only one search term has to match the record. Example: cats OR felines
-
The NOT operator – This operator is always applied to the term or Boolean expression that is immediately following the operator. The NOT operator is normally used with another term or expression to exclude certain matches. It can be used in the following ways:
dogs NOT cats
dogs NOT (cats)
dogs AND NOT cats
dogs AND NOT (cats)
-
Defining precedence of Boolean expressions – Parentheses are used to group Boolean expressions, defining the precedence of Boolean expressions. A general rule of thumb is always to use parentheses when a Boolean expression is ambiguous. Examples: cats AND (dogs OR raccoons), (cats AND dogs) OR raccoons.
-
Boolean searches in German language UI – Conforming to a standard practice in German-language search engines, when the German UI selected, Boolean operator words UND, ODER, and NICHT act as alternatives to AND, OR, and NOT. The English operators will continue to work in the German UI.
-
Boolean search and CDI relevance ranking algorithm – Boolean queries get processed by the same relevance ranking algorithm as any other query.
-
Hyphen – If a word or phrase follows a hyphen and there is no white space between the hyphen and the following word, the hyphen is treated as an AND NOT operator and thus any results that match the search terms following the hyphen are excluded. For example, if the search query is “Outside the square”-midwifery consultancy, a title with the same name would not be returned in the results since there was no space between the hyphen and the word midwifery.
-
One-word searches generally produce an unusually high number of results (usually millions), which can potentially cause problems (such as performance problems and timeouts). To prevent these issues, one-word searches (for example, art, business, case, law, market, project, report, review, and science) return a limited number of results and will not omit the highest ranked records.
-
Comparing searches with/without Boolean operators will not work as expected for a limited set of one word searches. For example, comparing the number of results for for the query science may find less results than searching for the query science AND neurology, but the expectation would be that the first query returned more results. This occurs because one-word searches generate an unusually high number of results (usually millions), which can potentially cause issues (such as performance problems and timeouts). To prevent these issues, the system identifies these searches and automatically limits their results (for example, by not searching in the full text and by reducing hits to the metadata). These one-word searches are gathered from our search logs and added to a list of about 500 words that is regularly updated. For example, the following words are included in the list: art, business, case, law, market, project, report, review, and science. Please note that this behavior affects the long tail of the results set and will not remove the highest ranked results.
Wildcards
You can use the following characters as a wildcard to search for alternate spellings and variations of a root word:
-
Question mark (?) – matches a only a single character. For example, it can be used to find Olsen or Olson by searching for Ols?n, but it will not find Olsson because there are two characters between the letters s and the n in that name.
To avoid confusion when a question mark is used as a punctuation character, the question mark wildcard (?) is not permitted at the end of a word. For example, the question mark in a search for who's afraid of virginia woolf? (with or without double quotes) is interpreted as a punctuation mark (not as a wildcard) and matches woolf as most users would expect. -
The asterisk wildcard (*) – matches zero or more characters within a word or at the end of a word. When used in the middle of a term, a search for Ch*ter will match Charter, Character, and Chapter. When used at the end, a search for temp* will match temptation, temple, and temporary.
-
Wildcards should not be used on their own or as the first character of a query.
-
The use of wildcards within a phrase search is not supported.
-
A wildcard search does not necessarily return more results than the same search without the wildcard. This is because CDI’s multilingual search features (such as stemming/lemmatization, synonym mapping and spelling normalization) are not applied to wildcard searches. For example, a keyword search for archaeology may return more results than the wildcard search for archaeolog* because the former matches both archaeology and archeology using CDI's English spelling normalization feature, but the latter matches only archaeology and not archeology.
-
Wildcard searches do not work with compound words such as sweatshop and healthcare. This is because compound words are tokenized differently from regular words. For example, sweatshop is tokenized separately as sweat and shop. This allows users to search for the terms sweat shop, sweatshop, or sweat-shop and match any of these variations. However, when a user searches for sweatshop*, the system looks for tokens that start with the string sweatshop and cannot match the tokens sweat and shop.
-
The use of a wildcard does not necessarily improve relevance ranking. In some cases, it could hurt relevance ranking as some relevance factors, such as the phrase match boosting and term weighting, do not apply to wildcard searches.
-
We recommend using wildcard searches only when regular searches, which benefit from various language-specific search features, do not return desired results.
Query Expansion (Based on Control Vocabulary)
CDI's Query Expansion feature assists patrons to find relevant literature, by adding preferred terms from controlled vocabularies to patrons’ queries. For example, if a patron issues a search for heart attack, the query expansion feature will expand the search query to heart attack OR myocardial infarction, because myocardial infarction is the preferred term for heart attack in some of the controlled vocabularies, such as LCSH (Library of Congress Subject Headings) and MeSH (Medical Subject Headings).
-
The Query Expansion feature will not expand phrase searches (in double quotes).
-
The Query Expansion feature will not expand terms that are very commonly used. For example, it will not expand AIDS to acquired immunodeficiency syndrome since the term AIDS is commonly used in literature.
-
The Query Expansion feature will not expand terms in long queries.
Field Truncations
CDI provides protection against very large field values that could cause various search and display issues. Such large field values may be due to accidental bad metadata mapping. For example, if a Table of Contents field is accidentally mapped to the Title field in a record, it could cause slow response times, display issues, and ranking issues. Large field values are truncated, either by the number of entries or the number of characters, or both, depending on the field. For example, the title and subtitle fields have a limit of 500 characters. The reference field, which contains the academic publication's list of references, has a limit of 1,000 entries. The author and editor fields have a limit of 100 entries. We periodically review the limits and will adjust them as needed.
Handling Long and Citation Searches
CDI uses a specialized process to improve results for queries that include citations that users may copy and paste from a webpage or a list of references into a Primo search box to find a known item. Citations typically contain many different metadata elements and vary in terms of format and completeness. The following example shows the APA citation style:
Boies, K., Fiset, J., & Gill, H. (2015). Communication and trust are key: Unlocking the relationship between leadership and team performance and creativity. The Leadership Quarterly, 26(6), 1080–1094
By rule, CDI returns only records that contain all keywords (or keyword variations) included in the search. For long searches (nine words or more), CDI matching is modified to allow matches on the first five to seven terms in the title or author field. This functionality does not apply to queries with Boolean operators (AND, OR, NOT) and may vary based on some predefined variables (such as punctuation marks, 1-letter terms, stop words and so on) that are included in the search. CDI first identifies the most significant terms, taking into account these variables. Then, CDI adds a custom sub-query that includes at least the first five significant terms to be found in the title or author field.
In this specialized process, CDI uses an Open Source AI tool called Grobid to parse the search query and identify the different metadata elements in the search query, including author, publication title, chapter/article title and enumeration (date, volume and issue). This enables the CDI search engine to find and return cited items in search results.
The chapter or article title and/or author information, as well as publication title and enumeration (date, title, volume and issue) are in most cases required in order for CDI to find the CDI records, if they exist in the index. If the citation metadata is incomplete, CDI may find the cited item in some cases, while in other cases it may not. This depends on a number of factors, including the format and completeness of the metadata in the CDI record, the search query format, the Grobid metadata identification, and the CDI search algorithm.
Multilingual Search Features
The Ex Libris Central Discovery Index (CDI) uses the Unicode standard, and allows searching in various languages whose writing systems are supported by the Unicode standard. In addition, it provides enhanced language-specific search features in many languages, including the following languages:
- Arabic
- Chinese (Simplified and Traditional)
- Danish
- Dutch
- English
- French
- German
- Hebrew
- Italian
- Japanese
- Korean
- Malay
- Norwegian
- Portuguese
- Romanian
- Spanish
- Swedish
- Thai
- Turkish
CDI uses several techniques to provide enhanced search capabilities in these languages. Some of the most important processes are listed below. These processes are applied to search results based on the language of each CDI record. For example, English search features (tokenization, stemming, and so forth) are applied to English records and German search features are applied to German records.
- Tokenization
- Decompounding
- Stemming/Lemmatization
- Character Normalization
- Transliteration
- Elision handling
- Synonym Mapping and Spelling Normalization
- Stop Words
These techniques are described in detail in the following sections. In addition, the following section describes how these features play a role in CDI’s relevance ranking algorithm.
- Verbatim Match Boost (all languages)
Multilingual Search Architecture
CDI indexes the "analyzed" or "normalized" forms of words instead of the "surface" forms of the words. For example, the word books is indexed as its dictionary form book, instead of its surface form books. At search time, books used in a search query is also normalized as book. This makes the two forms book and books cross-searchable. Please note that the analyzed/normalized forms are internal data representations, and not what users see in the UI display. Users still see the original field values -- in this example, books—in the UI display.
For example, book vs. books:
-
Index Time:
-
books → book (normalized according to the language of the record)
-
book → book (normalized according to the language of the record)
-
-
Search Time:
-
books → book (normalized according to the language of the record)
-
book → book (normalized according to the language of the record)
-
This approach has several advantages:
- It is suitable for supporting morphologically rich languages, such as French, German, Japanese, Arabic and Hebrew, and languages with extensive writing systems, such as Chinese, Korean, and Japanese. For example, each Chinese character may have several variations and that can be easily supported by this approach.
- It allows for true multilingual search capabilities. Search queries are normalized according to the language of each record, and every query is compared against all records using their language-specific search features. For example, the word "kind" in a search query can match "kinds" in English documents and "Kinder" (children) in German documents. This benefits bilingual or multilingual users regardless of the primary language or location of the library.
- It is scalable, and it allows for the addition of support for new languages without affecting the relevance ranking of records in the languages that CDI already supports.
CDI is a dynamic index (i.e., updated frequently), and that allows the Ex Libris development team to update the text analysis (normalization) algorithms for both index time and search time to improve CDI's search and ranking features.
Tokenization
Tokenization is the process of breaking a stream of letters or text into words, phrases, or meaningful elements. Tokenization is part of CDI's language-specific text analysis, which is performed at both index time and search time, and resulting tokens constitute the smallest searchable unit in CDI.
In most languages, words are separated by white space or punctuation, so tokenization is a simple process for those languages. However, in languages such as Chinese, Japanese and Thai, words are not separated by white space. For these languages, CDI's text analysis uses sophisticated techniques to identify word boundaries, and use that information to perform tokenization.
Examples of Tokenization:
- black cat => black + cat (English)
- 梵文基础读本 => 梵文+基础+读本 (Chinese)
- 東京タワー => 東京 + タワー (Japanese)
“Black cat” becomes the two searchable units “black” and “cat”; “梵文基础读本” becomes the three searchable units “梵文”, “基础” and “读本”; and “東京タワー” becomes the two searchable units “東京” and “タワー”.
Decompounding
Compound words are words that consist of multiple components that can stand as individual words on their own. In languages such as German, Swedish, and Danish, compound words are spelled without white space, and as a result, they can be very long.
Decompounding is the process of finding constituent parts in a compound word. CDI performs this process for languages such as German, Swedish, Danish and Korean. This process allows the patron to search for those constituent parts and get matches on the compound word.
Example:
Searching for German words abwasser anlagen (which is wastewater plant in English) returns results matching the compound word abwasserbehandlungsanlage (which is wastewater treatment plant in English)
Stemming/Lemmatization
Stemming is the process of reducing inflected (or sometimes derived) words to their stems, or the root forms. Lemmatization is the process of converting various forms of a word to its dictionary form. Despite the slight differences, these processes have the same goals, and these terms are often used interchangeably. CDI performs language-specific stemming or lemmatization to allow the patron to search for any form of a word (with or without inflections) and get matches on other forms of the same word.
Examples:
- books vs. book (English)
- ponies vs. pony (English)
- theses vs. thesis (English)
- maisons vs. maison (French)
- grandes vs. grande (French)
- Kinder vs. Kind (German)
In the first example above, searches for the word book will return results for both book and books. Searches for grande maison will return results for both grande maison and grandes maisons in French records.
For each language, the CDI stemming will be handled differently.
English Rules
Stemming for the English language uses the following rules:
-
If a word ends with the letters ies, replace them with a y.
-
Otherwise, If a word ends with the letters es and they are preceded by ch, sh, ss, x, or zz, remove the letters es.
-
Otherwise, if a word ends with the letter s, remove the letter s.
Some words do not follow the above rules and should not be stemmed.
Examples:
-
The singular form of the word movies is movie, and should not be changed to movy as suggested in rule #1.
-
Since the word news is already in singular form, it should not be stemmed to the word new as suggested in rule #3.
The following words are exempt from the above stemming rules:
- analyses -> analysis
- andes -> andes
- angus -> angus
- aries -> aries
- arius -> arius
- arkansas -> arkansas
- athens -> athens
- atlas -> atlas
- aussies -> aussie
- axes -> axis
- bias -> bias
- bonuses -> bonus
- children -> child
- cosmos -> cosmos
- feet -> foot
- geese -> goose
- headaches -> headache
- men -> man
- movies -> movie
- news -> news
- oxen -> ox
- teeth -> tooth
- ties -> tie
- viruses -> virus
- women -> woman
Character Normalization
Character normalization is the process of normalizing variants of a character to its basic version. Characters with diacritics are, for example, normalized to the characters without diacritics. CDI also provides character normalization for variants of Chinese characters.
Character normalization allows the patron to search for a word containing a diacritic and get results on the word without the diacritic, and vice versa. Similarly, it allows the patron to search for a Chinese word using the traditional characters, and get hits on the word spelled with the simplified characters, and vice versa. The character normalization mappings are mostly the same across all languages, but in some cases, language specific character normalization mappings are defined.
Examples:
- 大学 vs. 大學 (Chinese)
- México vs. Mexico (Spanish)
The Chinese search for 大學 will return results for 大学, and the Spanish search for Mexico will return results for México.
In some cases, CDI allows for multiple ways to represent a character with a diacritic. For example, the German umlauts ä, ö, and ü can be spelled without the diacritic as ae, oe and ue, or a, o, and u. CDI allows both variations. This allows the patron to search for schoen or schon and get results matching on schön. Another example is the Spanish ñ, which can be searched for by using ñ, n, or ni. This allows the query terms Espanol and Espaniol to return results matching on Español.
Transliteration
Transliteration is a conversion of one script to another. This process allows for searching in one script and get hits on the same words written in another script.
CDI currently provides transliteration search features for Chinese (Hanzi-Pinyin), Japanese (Kanji/Katakana-Hiragana) and Korean (Hanja-Hangul) for titles and author names. Chinese Pinyin transliterations can be written with spaces between words (for example, beijing daxue), or with spaces at the Hanzi-character boundaries or syllable boundaries (for example, bei jing da xue).
Examples:
The Chinese query beijingdaxue ("Peking University" in Pinyin transliteration) would return results containing the string 北京大学 ("Peking University" in Hanzi script).
The same Chinese query written as beijing daxue or bei jing da xue (use double quotes for better results) would also return results containing the string 北京大学 ("Peking University" in Hanzi script).
The Japanese query なつめそうせき ("Natsume Souseki" in Hiragana script) would return results containing the string 夏目漱石 ("Natsume Souseki" in Kanji script).
The Korean query 경제 (“economy" in Hangul script) would return results containing the string 經濟 (“economy" in Hanja script).
If a search is performed using transliteration, then transliterated search results are not necessarily the first results to display.
Elision Handling
Elision in this case refers to the omission of a final vowel of a word when the following word begins with a vowel, and is observed in languages such as French and Italian.
For example, in French, the word sequence le + arbre becomes l'arbre. In Italian, lo + amico becomes l’amico.
CDI’s elision handling allows the patron to search for amico and get hits on l’amico.
Synonym Mapping and Spelling Normalization
CDI provides language-specific simple synonym mappings and spelling normalization. For example, in English, the words theater and theatre are two spellings of the same word. These are normalized during CDI's English text analysis, and as a result, the patron can search using one of these spellings and get hits on both spellings. Language-specific synonyms are also defined for cases where two words have the same meaning.
Examples:
- theater vs. theatre (English)
- accessorize vs. accessorise (English)
- analog vs. analogue (English)
- ordenador vs. computadora (Spanish)
In addition, the ampersand (&) is equated with the appropriate word for the word and in each language.
CDI's search engine has two mechanisms to handle synonyms and spelling variations for English. One is the query expansion feature that is based on a controlled vocabulary, which expands search queries to include matches with synonyms (for example, heart attack is expanded to include matches to myocardial infarction). This mechanism penalizes matches with the synonyms by 50 percent. The other mechanism is mainly for handling spelling variations of the same words, such as counseling/counselling and theatre/theater. The words that matched using this mechanism get a 90 percent weight of the original search term.
However, it’s not easy to predict how these penalties change the relevance ranking of search results because many other factors (such as the publication dates, citation counts and content types) influence the ranking. If search results have similar relevance scores to start, these penalties may greatly change the ranking of those results. If search results have very different relevance scores to start, these penalties may not change the ranking of the results.
Local search engine configurations apply only to Primo local indexes, and they have no effect on CDI.
Handling of Ampersand ("&") Character
The ampersand character ("&") is a synonym of and, et, und, or other equivalent words in CDI's supported languages. This allows the cross-searching of cats and dogs and cats & dogs—for example, in English documents.
The synonym mapping is performed according to the language of each record. For example, & is mapped to and in English records, and & is mapped to et in French records. As a result, the number of results between the search queries cats and dogs and cats & dogs may not be the same because cats and dogs may appear in non-English records. Similarly, the number of results between chats et chiens and chats & chiens may not be the same because chats et chiens may appear in non-French records.
Currently, these mappings apply in all fields except the author field.
Stop Words
A stop word is a word that acts as a function (such as a definite/indefinite article, preposition, pronoun, conjunction, and auxiliary verb), occurs very frequently in CDI and does not have a common secondary meaning as a word that contains content.
CDI maintains language-specific lists of stop words, which are filtered out in the execution of searches except when they are part of formal phrase searches as described below. Stop words are chosen according to the following basic criteria.
CDI's current English stop words include a, an, the, and, but, or, it, of, on, with, in, is, and are, but it does not include the word will since it has a common secondary meaning as a noun.
In general, CDI ignores stop words in queries in order to improve the accuracy and efficiency of the search. However, in a phrase search (with search terms in double quotes), all stop words become required words, except those appearing at the end of the phrase. For example, the query man of the year includes two English stop words of and the. If this query is issued without double quotes (i.e., man of the year), it returns results containing the words man and year, and CDI's relevance algorithm boosts the ranking of results that contain the phrase man of the year.
If the query is issued as a phrase search with double quotes (for example, "man of the year"), CDI returns results containing the exact phrase and does not exclude the stop words. However, there are some limitations for phrase matches in the full text field, and phrases that end with stop words. For more details, see Phrase Search.
Stop words are applied according to the language of a record for CDI, not the language of the search query. For example, CDI uses the French stop words list for French records and the English stop words list for English records. If French records are incorrectly labeled as English records, users may get unexpected results since the French stop words (such as la) will not be ignored when searching these records.
Verbatim Match Boost
This is one of the most important features of CDI's native language search support. Many of the features described in this document allow the patron to get results when the query terms and the indexed terms are equivalent, but not exactly the same word for word (verbatim). These features have an effect of increasing the number of results, or in other words, increasing the search recall. While these features will provide a better user experience to the patrons, there is a risk of including less relevant or non-relevant results, and reducing the search precision.
The Verbatim Match Boost feature addresses this concern by boosting the relevance score of a result when the matching of the query terms and the indexed terms is verbatim or near verbatim.
Example:
For the English search query theatres, the results for theatres get higher relevance scores (and are ranked higher) than the results for theaters or theatre if all other factors that contribute to the relevance scoring calculation are equal.
The Verbatim Match Boost feature is applied to almost all processes mentioned in this support document. The actual implementation of this feature works by penalizing non-verbatim matches, thus effectively boosting the verbatim matches. Penalties are computed for each term/token, and the penalty amount is defined for each process in each language, such that major differences, such as synonyms, are penalized more than minor differences, such as spelling differences and singular vs. plural forms of nouns.
For more information, see Synonym Mapping and Spelling Normalization.
Relevance Ranking
When a patron issues a search query in Primo backed by the Ex Libris Central Discovery Index (CDI), the query is issued to both the local index and CDI. Search results from each of these indexes are ranked according to their relevance ranking algorithms, and they are blended to form the final search results presented to the patron. This document discusses the relevance ranking algorithm used by CDI.
Relevance ranking in CDI is determined according to a continuously tuned, proprietary algorithm, and is built on a foundation of two building blocks: the Dynamic Rank and the Static Rank. The Dynamic Rank is a collection of relevance factors that represent how well a search query matches each record, and the Static Rank is a collection of relevance factors that represent the value or importance of each record. Both of these are important in determining the ranking, and top results need to have good scores from both Dynamic Rank and Static Rank.
Dynamic Rank
The Dynamic Rank represents how well the user's query matches each record. Dynamic Rank factors include the following:
-
Field weighting – When a query term or phrase matches in a field of a record, a score is generated according to the importance of the field. For example, Title, Subtitle and Subject are the highest weighted fields. The Creator and Abstract fields are weighted lower than these, but higher than other metadata fields. The Full Text field is weighted the lowest.
-
Term weighting – Matches on rare terms are weighted higher than matches on common terms. For example, if a given query is yoruba books, the less common term "yoruba" has a higher influence than the common term “book".
-
Term frequency and field length – The number of a matching term repeated within a field is also considered. For example, if a given query is nanobiotechnology, an abstract that contains five occurrences of the term would score higher than an abstract of the same length that contains the term only once. Similarly, the length of the field where a match occurs is considered in determining the weight of the match.
-
Verbatim match boost – A given query term could match an indexed term via multilingual search features, such as stemming, synonym mapping, and character normalization. Such non-verbatim matches are weighted less than verbatim matches where the query term is exactly the same as the indexed term. For example, if a given query is cliché, matches on cliché are scored higher than matches on cliches.
-
Phrase and proximity match boost – If a given query contains multiple terms and double quotes are not used, matches on the exact phrases (phrase match) and close phrase matches (proximity matches) are given a boost in the score. For example, if a given query is American history (without double quotes), the exact phrase match "American history" scores higher than the non-exact phrase match (proximity match) "American automobile history”, which in turn scores higher than a match on "American" and "history" appearing in different fields.
-
Exact title and title+subtitle match boost – The exact title match boost feature boosts scores for cases where a given query matches the title or title+subtitle. This helps known item searches consisting of a title or title+subtitle.
-
Known item search boost – In addition to the exact title match boost feature above, the known item search boost feature emphasizes matches where a given query contains a combination of common elements of known item searches, such as title, subtitle, author, and publication title. For example, a query an inconvenient truth global warming al gore (without double quotes) boosts matches on the books titled "An Inconvenient Truth: The Planetary Emergency of Global Warming and What We Can Do About It" and "An Inconvenient Truth: The Crisis of Global Warming" authored by Al Gore.
Static Rank
The Static Rank represents the value of each item, and does not pertain to the user's query terms. Static Rank factors include the following:
-
Resource type – Items are weighted according to their resource types. For example, books are weighted higher than book reviews; articles (journal articles) are weighted higher than newspaper articles, and so on.
-
Publication date – Recent items are weighted higher than older items. CDI uses carefully designed mathematical functions specific to each content type to maximize the effectiveness of this factor. For example, the penalty for having an old publication date is higher for articles than for books.
-
Scholarly/Peer review – Articles from "scholarly" or "peer reviewed" journals are boosted.
-
Citation counts – Citation counts are used to reward publications with high citation counts.
-
Journal rank – Journal scores in academic journal rankings are also considered, and articles published in highly respected academic journals are boosted according to their journal scores.
-
Anonymous author – Anonymous author items are demoted. Anonymous items may include editor's notes, letters to the editor, obituaries, and other non-primary articles in journals.
Each record's Static Rank score is determined as a combination of scores calculated from these factors, using carefully designed mathematical functions. For example, a journal article published 5 years ago with 100 citations would probably have a higher Static Rank score than a journal article published 6 months ago with 0 citations. In this case, the benefit of the high citation counts of the first record outweighs the benefit of the recency of the second record.
The scores from Dynamic Rank and Static Rank are then combined to determine the relevance score of each record for the given query. The ranking of a search result set is determined by the final relevance scores of the records in the result set.
CDI's relevance ranking algorithm is tuned to provide best search experience for both known item searching and other types of searching (for example, subject searching, exploratory searching, topical searching, existence searching, unknown item searching, and so forth). Additionally, there are aspects of CDI relevance that assist the user community comprised of the novice researcher, the professional researcher and all user types in-between. For example, short and general topical queries (for example, linguistics, global warming) tend to return more books, eBooks, references and journals among the top results, and long and specific topical queries (for example, linguistics universal grammar, global warming Kyoto protocol) tend to return more articles among the top results.
CDI overlays this foundation with a regimen of judgments to ensure that relevance as a whole remains strong as individual pieces of the system are improved. The relevance ranking system in CDI is shared by all customers, and is not customizable for individual institutions.
Advanced Search, Title and Author Searching
When using the Advanced search, CDI includes the following fields for Title and Author/Creator searches:
-
Title searches include the title of the record (including article or book chapter titles) and the title of the publication (journal or book) the record is part of. They also include series titles and uniform and alternate titles for these publications to increase the match between the search term and the records in the CDI index, especially in the case of title variants.
Because the alternative titles are not shown in the Primo/VE record display, returned records may not completely match the title's search terms.
-
Creator/Contributor searches – include personal and corporate authors, editors, and other contributors.
For more information about Advanced Search, see the following documents: Performing Advanced Searches (Primo) and Performing Advanced Searches (Primo VE).
The "Equals exact phrase" Option in CDI
The Equals exact phrase option in Advanced Searches returns results only when the phrase matches the data in the specified Author, Title, or Subject field exactly. For example, a title search for "customer success" returns records that contain only customer success in the Title field.
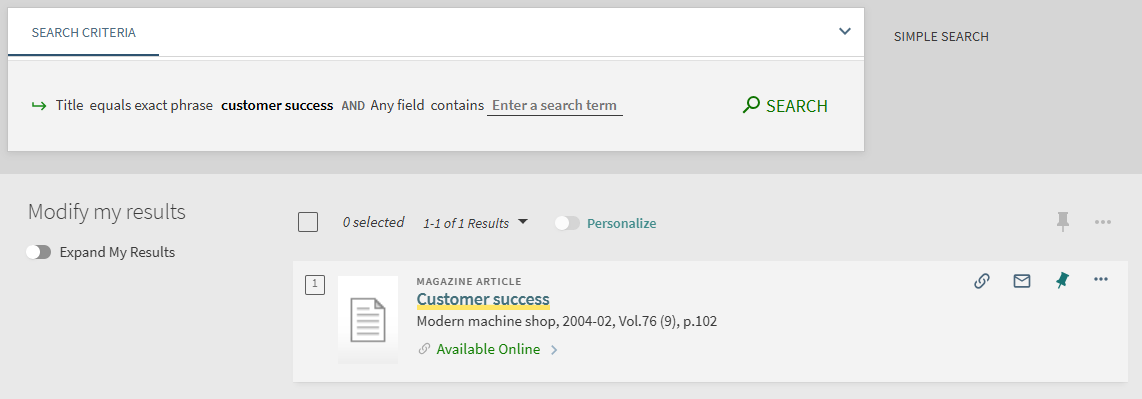
For title matching, results are restricted as follows:
-
Verbatim matching (for example, a search for "cat" does not match "cats")
-
Complete matching (for example, a search for "linguistics" does not match "computational linguistics")
Searches will ignore definite and indefinite articles in multiple languages as defined in https://www.loc.gov/marc/bibliographic/bdapndxf.html_
For example, when searching for I am a book, the letter i is a definite article in Italian, the word am is a definite article in Scottish Gaelic, and the letter a is an indefinite article in English. As a result, the definite articles are omitted, and the results will match the title Book.
The "Contains exact phrase" Option in CDI
CDI's Verbatim Search feature disables all cross-searching variations (except for Casing Normalization) when the phrase search syntax (with double quotes) is used. In addition, this functionality supports queries that include a single word in double quotes.
Examples:
-
A search for "raccoon" returns matches with the word raccoon, but not with its plural version.
-
A search for "raccoons" returns matches with the word raccoons, but not with its singular version.
-
A search for "sea otter" returns matches with the exact phrase sea otter, but not with the plural version of the phrase sea otters.
-
A search for "sea otters" returns matches with the exact phrase sea otters, but not with the singular version of the phrase sea otter.
CDI does not support phrase searching when phrases end with stop words. For example, when searching for the exact phrase cats in may, the words in and may are stop words. As a result, the search matches the word cats and ignores the words in and may.
This functionality is enabled by default and is applied when using the Contains exact phrase search option or when phrases are enclosed in double quotes. To disable this functionality, please open a Support ticket.
In the following example, the exact phrase is matched verbatim and does not match any other variations of the words in the phrase.

The "Starts with" Option in CDI
CDI's "starts with" or "begins with" option enables users to search for titles starting with specific phrases. This feature ignores leading definite and indefinite articles in various languages, as outlined in this MARC documentation.
CDI handles leading definite and indefinite articles slightly differently than the Primo local index. For instance, search queries like Oxford Handbook and The Oxford Handbook will match both variations in CDI, but not in Primo's local index. To ensure consistent results across both CDI and Primo's local index, it is recommended to omit leading articles in your search queries.
Facet Search Behavior and Display
Facets are links in the Tweak My Results section on the Brief Results page that allow users to filter their search results by a specific category (such as Resource type, Subject and Language). It is possible to select one or multiple facet values (with both include/exclude options) to filter the results. CDI returns the following facets as part of the search results:
-
Top-level facets (displayed at the top - in the Availability section):
-
Full Text Online - All CDI records are displayed
-
Peer-reviewed Journals – CDI records display if the display/lds50 field is peer_reviewed.
-
Open Access – CDI records display if the display/oa field is free_for_read. For additional information, see Open Access Content in CDI.
When selecting multiple top level facets, a Boolean AND is applied. This means records returned must include all selected top-level facet filters.
-
-
Other facets:
-
Resource Type – For information regarding CDI resource types, see Resource Types in CDI.
-
Subject – For additional information, see Using Normalized Subject Headings from CDI.
-
Publication Date – The initial start and end dates displayed in the results list date facet boxes are based on the earliest and most recent publication in the results set. The date is normalized to four digits (YYYY).
Publication dates are normalized into date ranges as follows for each PNX record:
- Dates before 1899 are normalized as their century. For example, 1826 is normalized to 1801.
- Dates from 1900 are normalized by decade. For example, 1945 is normalized to 1941.
The earliest and most recent normalized dates in the result set are displayed in the Start and End date boxes.
In some cases, you will notice that the search results do not completely match the date range selected. This is because records with different publication dates are sometimes allowed to merge during the Match and Merge process. As a result, such a logical record in CDI has multiple values. All dates are searchable but only one date is selected for display, so in such cases there may be discrepancy between the record display date and the facet applied. To reduce this discrepancy, CDI will, for records of type article (including journal articles, newspaper articles, magazine articles), use rules to prefer the date provided by the majority of data sources and use a single date for faceting, display and rights calculation. In cases where there is no majority for one date, CDI will use the latest date. These rules are not applied for monograph type of records, where multiple dates do exist more commonly, for example in case of different editions.
-
Collection – For information regarding the types of collections that are included in the Collection facet, see CDI Tips and Tricks.
-
Journal Title – This facet contains the publication title for records included in the search results that have one of the following resource types: Journal, Journal article, Magazine, Magazine article, Newspaper, or Newspaper article.
-
Language – The language of the resource. In some cases, you will notice that the search results do not completely match the language selected. This is because records with different language values are sometimes allowed to merge during the Match and Merge process. As a result, such a logical record in CDI has multiple values. All languages are searchable, but for display purposes, CDI selects the language information from one record that the institution is entitled to view. In such cases, there may be a discrepancy between the record's display language and the facet applied. To reduce this discrepancy, CDI uses rules to remove 'outlier' language values (provided by less than 25% of the data sources) for both faceting and display. Multiple values are still allowed for the language field to accommodate for multi-language publications.
-
Within the same facet, you can select multiple facet values and then apply them to the results at the same time. This results in a Boolean OR being applied. For example, if you select the Subject facet values Agriculture and Botany, the system returns results that include all records that contain either Agriculture or Botany subjects. If you had selected these facet values separately (for example, you first select the topic Botany and afterwards, you select the Agriculture facet value on the filtered list, the filter applies a Boolean AND, requiring the matching records to contain both facet values.
-
For merged records, facet filtering uses logical records created by Match and Merge in CDI. For example, when a user clicks “articles” in the resource type facet, CDI filters the search results based on the logical records' resource types. In some cases, you will notice that the search results do not completely match the facet selected. This is because records with different metadata (for example, resource type, date, or language) are sometimes allowed to merge. As a result, such a logical record in CDI has multiple values. For more information about these cases, see Match & Merge FAQ.
-
Selection of Facet Values
When selecting facet values from different facets, a Boolean AND is applied during filtering for these facet values. For example, if you select Subject facet values Agriculture and Botany and Resource Type facet values Book and Other, the system returns results that include all records that match the following criteria:
-
The records must contain either Agriculture or Botany subjects.
-
And the records must be either Book or Other resource types.
For each facet, a maximum of 20 facet value are presented for results returned from CDI and all records in the results participate in facet count calculation for the top 20 values displayed.
Capitalization in CDI Facets
In Subject facets, CDI Subject facet values are normalized by capitalizing the first letter of each word. This is essential because providers indexed in CDI have many different rules for capitalization. This normalization ensures that no duplicates (with different case) appear in the facet list.
The normalization is also applied to acronyms when included in the Subject facet. Only the first letter of the acronym is capitalized.
In the Journal title facet, the titles are taken as is from the provider. This is also the case for Title information in the CDI records (for example, Article and Book titles). These are taken 'as is' from the provider.
Large Search Queries
CDI imposes limits on the length of search queries. Exceeding these limits prevents CDI from returning search results.
-
Max number of characters: 1,000.
-
Max number of tokens (words and boolean operators combined): 75.
Search Term Highlighting
Highlighting refers to a visual indication of words in search results, helping users understand how their search query matches specific terms in each record. CDI provides an advanced multilingual highlighting feature that identifies parts of CDI records that match the user’s search terms. These highlights can appear in fields such as title, creator, subject, description, and identifier.
Highlighting matched words in search results, however, is not always straightforward. For example, if a query includes the word cat, users typically expect both the singular cat and the plural cats to be highlighted. This behavior can also vary by language. For example, when the query contains the French word cheval, users would expect both cheval and its plural form chevaux to be highlighted.
CDI applies language-specific text analyzers to selected fields within matched records to perform highlighting. This process can be resource-intensive, particularly for large fields or records with numerous field values, potentially impacting search response times. To balance performance and usability, CDI's highlighter is designed to optimize the user experience while minimizing processing time.
- While CDI's highlighting feature strives to highlight all matching words, it cannot always guarantee that every match will be highlighted.
- Partial matches within a phrase query can also be highlighted. For example, if a user searches for the phrase computational linguistics, CDI may highlight the partial match linguistics as well.