
The Import PNX Extensions Tool
This functionality is not relevant to to Primo VE.
The Import PNX Extensions tool allows users to load enrichment content (such as tables of contents, abstracts, tags, and reviews) to enhance Primo records. This program has been developed as an API plug-in to enable you to add a wide variety of enrich-indexing data from multiple sources by writing your own import programs.
Primo provides import functionality for the following sources:
-
Syndetics (Table of Contents, Summaries (abstracts), and Fiction Profiles)
-
LibraryThing (Tags and Reviews)
-
Baker and Taylor (Table of Contents)
-
You must be an installation-level staff user to create and execute this tool.
-
Because the import tag process may require intensive database activity and time, Primo Technical Support recommends that you run the import on weekends or during off-peak hours.
-
The Import PNX Extensions tool is intended for updates from the data source for existing PNX records.
-
Do not add enrichment content during the initial load because the system will not update the necessary flag to indicate that the data needs to be indexed (this function is switched off during the initial load to save on time). Following the initial load of the records, you can run the Create XRef and Import PNX Extensions tools.
Importing PNX Extensions
The import tool performs the following operations:
-
Harvests enrichment content (using FTP, SFTP, or copy) from source.
-
Converts the source format to a generic Primo XML format.
-
Loads to the ENRICHMENTS table, which stores the data that can be used potentially to enrich the Primo indexes.
-
Finds matching PNX records using the P_PNX_XREF table.
-
Uses the PNX_EXTENSIONS_MAPPINGS mapping table to add enrich-indexing data to the P_PNX_EXTENSION table for matched PNX records, and flags the PNX for indexing.
To add enrichment content for new records that are processed by ongoing pipes, an additional stage has been added to the pipe. This additional stage is activated for any data sources for which the creation of the P_PNX_XREF table has been enabled. This process works as follows:
-
Once the records have been loaded and the dedup and FRBR processes have completed, cross-references are created (if relevant) for the records, and the PNX records are checked for matching enrich-indexing content in the ENRICHMENTS table.
-
If a match is found, the enrichment content is added to the P_PNX_EXTENSION table, and the PNX is flagged for indexing.
To import enrichment content:
-
On the Tools Monitoring page, select Import PNX Extensions in the Create a Tool drop-down list.The Import PNX Extensions page opens.
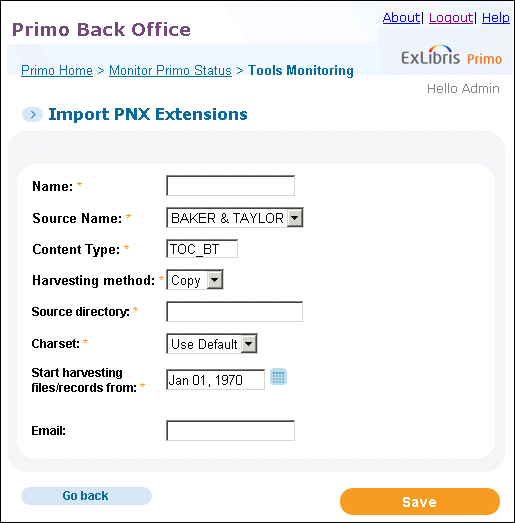 Import PNX Extensions Page
Import PNX Extensions Page -
Enter the fields as described in Import Enrich-Indexing Content Details. Required fields are indicated by an asterisk.
Import Enrich-Indexing Content Details Field name Description Name*This field identifies the tool job, which you can execute and monitor in the Tool Monitoring list.Source Name*Indicates the source of the content. Currently, Primo supports the import of Syndetics and LibraryThing content.Additional sources and content types can be imported by creating import plug-ins and then adding the new sources to the PNX Extension Sources and PNX_EXTENSIONS_MAPPINGS mapping tables. For more information, see EL Commons - Primo documentation.Content Type*Contains the type of content to add to the PNX Extension table for indexing. The following types of content are supported:-
For Syndetics:
-
ABSTRACT
-
FICTION_PROFILE
-
TOC – Table of Contents (for searching only)
-
TOC_DISPLAY – Table of Contents (for display and searching). When imported, this option displays a Table of Contents link in the brief display of the search results and also a Table of Contents tab in the Details tab. To modify the labels for each, use the following code tables, respectively: Results Tile and Details Tab.
-
-
For LibraryThing:
-
TAG
-
REVIEW
-
-
For BAKER & TAYLOR:
-
TOC_BT
-
To include multiple content types or remove a content type, select a content type while pressing the Ctrl key.Harvesting Method*The method used to harvest the source information. The following methods can be selected: FTP, Copy, or SFTP.If Copy is selected, the user must have read permission for the directory.Source Directory*The location of the import files.Character Set*This field indicates the character set of the data. The valid values are Use Default, UTF-8, and MARC-8.To keep the character set used with the program, select Use Default.If you want to enable additional character sets, use the Character Set code table under the Publishing subsystem.Start harvesting files/records from*Indicates the date of the source file to harvest. Enter a date or click to select a date with the calendar tool.This date is updated with the date of the latest harvested file.Server*The IP of the site (used only for FTP and SFTP harvest methods).Username*The user name used to access the FTP/SFTP site.Password*The password used to access the FTP/SFTP site.EmailThe e-mail address to which the completion status of the build is sent.Configure Server LocaleWhen this field is selected, this page displays the Server Locale field (FTP only).Server LocaleSelect a locale from the drop-down list (FTP only).
to select a date with the calendar tool.This date is updated with the date of the latest harvested file.Server*The IP of the site (used only for FTP and SFTP harvest methods).Username*The user name used to access the FTP/SFTP site.Password*The password used to access the FTP/SFTP site.EmailThe e-mail address to which the completion status of the build is sent.Configure Server LocaleWhen this field is selected, this page displays the Server Locale field (FTP only).Server LocaleSelect a locale from the drop-down list (FTP only). -
-
Execute the tool when needed. For information on monitoring tools, see Tools Monitoring.