
Components
This information is not applicable to Primo VE environments. For more details on Primo VE configuration, see Primo VE.
Primo consists of the following components:
-
Publishing Platform
-
Indexer
-
Back Office
-
Search Federator
-
Search Agents
-
Search Engine
-
Front End
-
Database
The following figure illustrates the logical view of Primo, including its various components. Each of its components is described in the following sections.
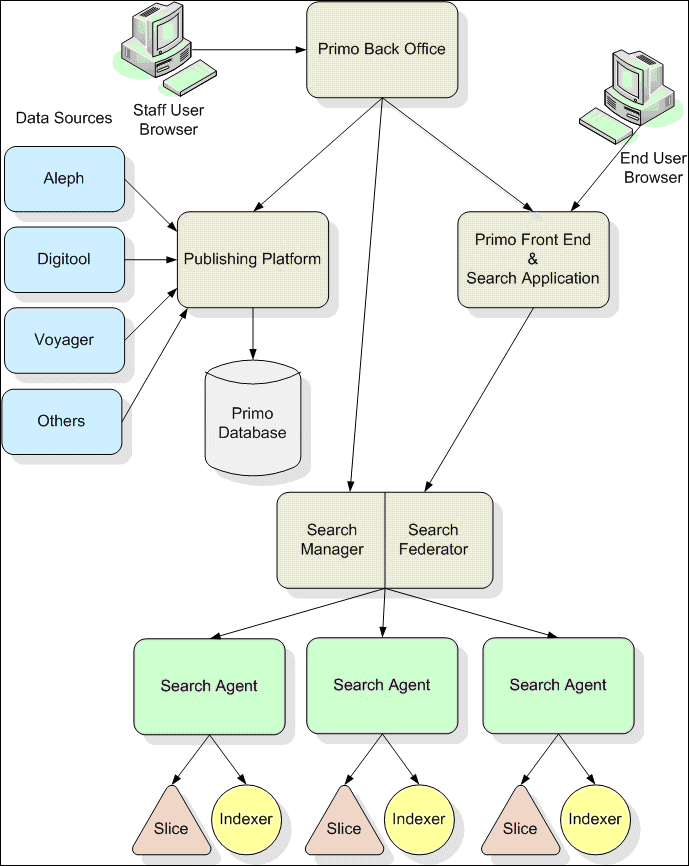
Logical View of Primo System
Publishing Platform
The Publishing Platform enables the institution to consolidate the full range of institutional resources, including print collections, digital repositories, and electronic resources. The Publishing Platform manages the harvesting of this raw data from various data sources and its transformation into high quality, indexed information that can be quickly and efficiently searched by the Primo Search Engine. This data is stored in the Primo Normalized XML (PNX) format.
Primo can harvest and normalize any data in standard XML format. Standard formats—for example, MARC, MAB and Dublin Core—have built-in template mappings. Templates can be customized during the implementation process. The processing of each data source is performed by pipes that recognize various source formats.
The Publishing Platform performs:
-
Intelligent harvesting of data via FTP, file copy, or OAI
-
Normalization of the data to the PNX format, which is stored in the Primo database
-
Enrichment based on algorithms and external information
-
De-duplication based on algorithms
-
FRBRization
The Normalization Mappings and Enrichments are configurable using the Primo Back Office. For additional information about the Primo Back Office, refer to the Primo Back Office Guide.
The Publishing Platform supports scheduled and unattended harvesting and processing of different data formats, while enabling interactive monitoring and control over the entire set of activities.
Indexer
The Indexer is part of the Search Engine and is used to create slices. The Search Engine supports multiple slices of search data. Slices are an efficient way to allocate groups of equal-sized chunks of memory.
The Indexer automatically swaps itself with search machines so that slices can be made available without downtime.
The Indexer splits the actual data into manageable slices, which are loaded into memory. Each slice is searched by a dedicated thread; however, multiple slices can reside on the same machine so that all CPUs are utilized. Multiple machines may be used so that the system is not limited to the memory of one machine.
The following figure illustrates the indexing process in the Primo system.
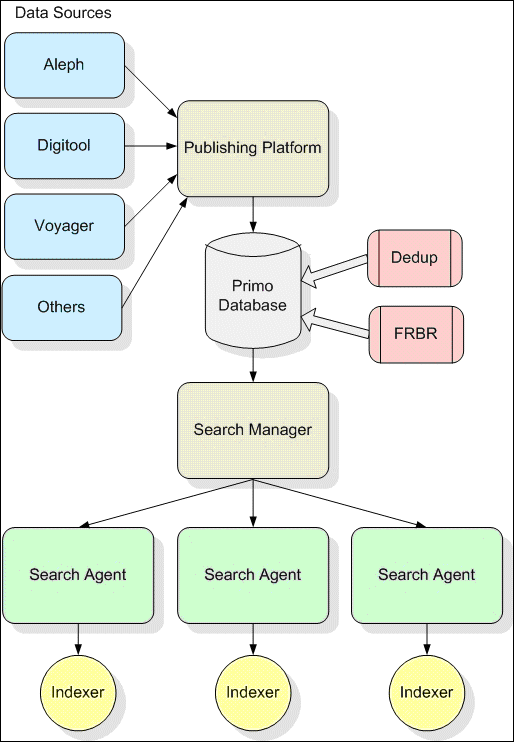
Logical View of Primo System Indexing
For more information about the indexing process and swapping, refer to Overview of the Index and Search Process.
Back Office
The Primo Back Office enables configuration and monitoring of all Primo components in an easy-to-use graphical interface.
The configuration of Primo in the Back Office is organized by the lifecycle of Primo, and includes:
-
Initial configuration
-
Ongoing maintenance
In addition, you can configure elements of the system individually by accessing them through the appropriate wizard. A site map is provided for direct access to the individual tasks for the advanced user. For additional information about the Primo Back Office, refer to the Primo Back Office Guide.
Search Federator
The Search Federator coordinates the search, utilizing all slices, and combines the search results into a unified result set.
Search Agents
Search agents are located on remote machines. These agents stop and start the search instance and the indexing process. When an agent starts, it sends a registration request to the Federator. The agent and the Federator communicate using the Java RMI protocol.
Search Engine
The Primo Search Engine retrieves library metadata from the local PNX database table and transforms it into useful information. The Search Engine extends Lucene functionality and supports multiple slices for very large data sets. These slices are prepared by the Indexer. Each slice is searched by a dedicated thread; however, multiple slices can reside on the same machine, so that all CPUs are utilized. Multiple machines may be used so that you are not limited to the memory of one machine.
Search functionality includes faceted navigation, “did you mean” suggestions, paging, and sorting.
Front End
The Primo Front End user interface is responsible for all interactions with the end user. It is a search tool that is both powerful and easy to use. Each institution can have its own fully customized view. Every view can have one or more tabs. Tabs enable a site to divide the Primo repository and records from remote resources into resource groups or types. Within a tab, several search scopes can be defined. Search scopes group records so they can be searched together.
Using the Front End user interface, the end user searches the PNX database table for relevant items. After discovery, Primo indicates the availability of the resource in the source system and interacts with the source system to provide more information about the resource or delivers the resource to the end user. The Front End generates the actual HTML pages viewed by the end user.
The following figure illustrates the querying process in the Primo system.
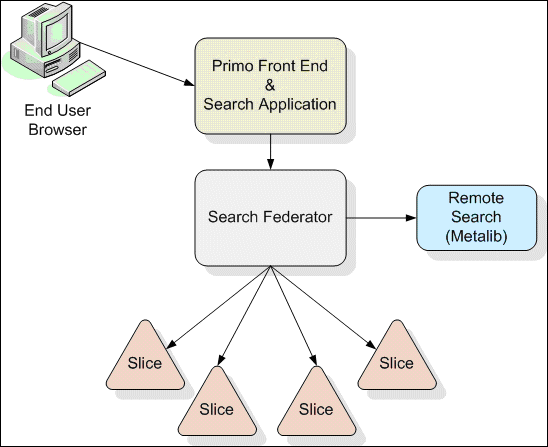
Logical View of Primo System Queries
Primo Database
The Primo database is based on Oracle 11g R2 RDBMS. The Oracle database contains the following primary types of content:
-
Primo PNX records and user-contributed information (such as reviews and tags).
-
Monitoring information, including statistics, detailed information on searches, and so forth.
-
Primo configuration information.