
Overview of the Index and Search Process
This information is not applicable to Primo VE environments. For more details on Primo VE configuration, see Primo VE.
All new data must be indexed once it has been processed by the Publishing Process. This indexed data is accessed when the system performs a search.
Each Search Engine machine consists of one or more slices, which is the atomic entity of the Search Engine. Primo implements the following types of slices:
-
RAM-based slices match relatively small document collections (backward compatible with PrimoVersion 1.x).
-
File system-based slices match large document collections and have lower memory consumption.
The type of slice defines the search, the indexing technique, and the hot swap behavior.
Indexing in Primo
The following figure is an example of how Primo indexes data.
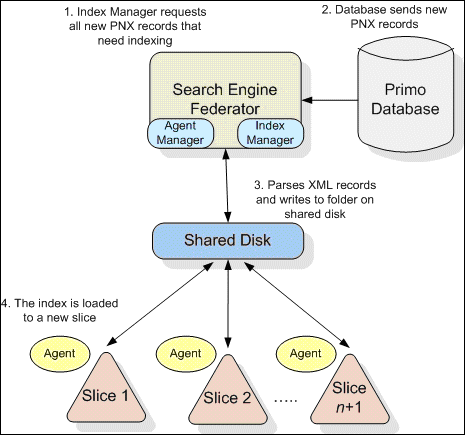
Indexing in Primo
The indexing process in Primo consists of the following main phases:
-
Indexing—The Index Manager takes the XML records and parses them. It then writes them to a temporary folder (<path/>.mir) and indexes them. During the indexing, the PNX tokens are normalized (conversion to lowercase characters, removal of punctuation, and so forth).
-
Optimization—The system optimizes the records into a single file for performance purposes.
-
Mirroring—The indexed records are copied to a directory from which the slice loads.
-
Swap—This phase replaces the old indexes with the new indexes with no downtime. Hot swap is done on the redundant machine for the N+1 Agent topology and the slice machine for the N+1 Slice topology.
Indexing on RAM Slice
The following indexing phases run sequentially: Indexing, Optimization, Mirroring, and Swap. After indexing completes, a redundant slice is loaded to RAM and facet cache is prepared. Once the new slice is ready, search functionality is moved to the new slice and the old slice is shut down. If the process fails during the Indexing or Optimization phases, the mirror directory is restored from the main directory.
Indexing on File System Slice
This indexing method is intended for large document collections that create large indexing files. The indexing phases operate as follows: The index directories are placed in an NFS file. The indexer places a copy of the mirror directory in the local path (direct-attached storage). After indexing is performed in a mirror directory, the new index is copied to the main directory, where optimization is performed on both the main and mirror folders. When new indexes are ready, a redundant slice is warmed up, using high frequency terms from the index to provide better search performance. Once the new slice is ready, search functionality is moved to the new slice.
The topology type of the Search Engine determines where the indexing and hot swap operations will take place.
Method 1: All In One
When Primo needs to create a new index, the Front End (FE) activates the Agent manager to prepare the index. Once the index is ready, the FE activates the agent to start up a new slice—that is, to load a new index. Once the new slice is running, the FE will use the new slice and the Search engine will shut down the old slice.
Method 2: 2-Tier/3-Tier
When Primo needs to create a new index, the FE activates the Agent manager on the Back Office to prepare the index. Once index is ready, the Front End will activate an additional Agent residing on the Search engine and instructs it to start up the new slice, that is, to load a new index. Once the new slice is running, the FE will start to use the new slice and the Search engine will shutdown the old slice.
Searching in Primo
Primo uses the following types of searches to enhance search performance:
-
RAM slice searches use the Lucene RAMDirectoy, which loads the index into RAM, so that search operations are performed directly from RAM. This provides higher search performance; however, operation of this mode requires the available RAM to be at least 2.4 times the index size.
-
File system slice searches utilizes OS in memory disk cache to achieve performance levels similar to that of the RAM slice search. This depends on the underlying implementation of buffering in the operating system. Because of NFS cache limitations, it is highly recommended to use direct attached storage for the Search engine servers. The servers will copy the slice from the NFS to their local disk.
When a user performs a search in the Primo Front End, the Search Engine sends a query to all registered slices (not via the agent on the slice machine). The slice searches its index in RAM and returns the top 200 IDs, their scores, and statuses to the Federator. At the same time, the slice begins calculating facets, using another thread. The Search Manager merges the results from all of the slices and does the following:
-
Adds synonyms of each word being searched for to the query. The system searches for the synonyms as well as the words specified in the query by the user.
-
Takes the top ten values (according to scores) and requests the full records from the PNX. It receives the records and stores these records to be displayed to the user in the Front End user interface.
-
When the search results in either no or very few records, Primo searches again using stemming in order to retrieve additional records.
-
Merges all records and retrieves the top 200 merged results. It then sends the facets of these records to the appropriate slices. The slices calculate how many times these records appear in the entire result set and return this information to the Search Manager.
-
Searches for specific static facets in addition to the 200 facets searched for based on the search query.
-
Retrieves an accurate count of facet values. It then sends the full PNX records and the facet information for the top ten values to the Front End user interface.
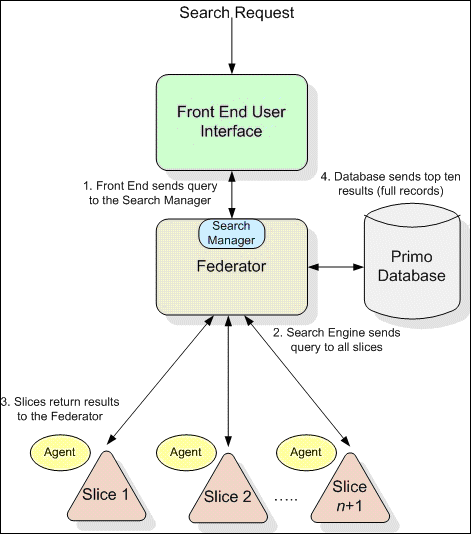
Search Process
The Federator uses the host machine and port information in search_schema.xml when it performs a search (refer to search_schema.xml).
Agents are run separately. When an agent begins running, it registers to the Search Engine. Each slice is assigned a unique ID within the system. The path is the location of the directory from which the slice is loading.
The Primo N+1 topology provides a failover capability in search servers to ensure continuous availability of search operations. When a system failure is detected on one of the search servers, the indexer will automatically copy the failed slice and start up a replacement Search engine, which may take a few minutes. Until the new Search server starts, the exisiting servers will continue to process Primo searches, but the results will not be 100 percent complete. Once the replacement indexer is up and running, the searches will resume full accuracy.
-
For N+1 topologies that have a single slice (N=1), Primo searches will not be processed until the indexer starts up the failed slice.
-
Until a replacement of the failed server is up and running, the system will not be able to run indexing or swapping.
In all other topologies, the monitor automatically tries to restart the slice and sends an e-mail notification to the System Administrator when a earch engine failure occurs.
Filters are used as constraints that are added to the search and are used for quick matches (this is the same as using the Deploy button in the Back Office interface).
Linguistic Issues
Primo linguistically supports English, German, French, and Danish languages by creating dictionaries per language (if available) for the following: recognition, stop word lists, special stemming algorithm (English and German only), misspelled words (English, Hebrew, and German only), synonyms (not French), pluralization algorithm, and phonetic algorithm for “did you mean” suggestions.
Primo creates indexes for stop words to allow end users to search phrases that contain stop words.
Primo defines a synonym collection per language. Administrators can extend this collection by updating the user_synonym file.
Did You Mean
If the configured result threshold is not met, the “did you mean” functionality is activated for the search. The “did you mean” is made up of the following:
-
Metaphone and double metaphone algorithms take words and encode them.
-
N-gram encoding (for example, people - peple, pople, and so forth). Using N gram encoding, the system checks how close the word being searched for is to the candidate.
-
Text files of commonly misspelled words and homonyms (currently available in English only).
-
The metaphone and N-Gram repositories are based on the regular index and are extended with phrases/typographical/grammatical mistakes that are learned from the search statistics.
If the word exists in the dictionary, the Did you mean link is not displayed in the Front End.
In addition to searching in the local PNX database, Primo searches on remote repositories using MetaLib.
The actual data to be searched is split into manageable slices. These slices are prepared by the Indexer. Each slice is searched by a dedicated thread, but multiple slices can reside on the same machine so that all CPUs are utilized. In addition, multiple machines may be used so that the search process is not limited to the memory of one machine.
The Federator manages the dispersal of the search to all slices and the federation of the results into a unified result set, which is returned to the Front End and displayed to the user.
search_schema.xml
The search_schema.xml defines the number and location of each slice.
To view the file:
Enter the following commands to view the search_schema.xml file:
se_conf
vi search_schema.xml
The following is a sample search_schema.xml file:
http://www.exlibrisgroup.com/xsd/jaguar/search_schema">
<federator/>
<facet_count>250</facet_count>
<min_res_for_stemming>25</min_res_for_stemming>
<max_facets_to_sumup>50000</max_facets_to_sumup>
<max_results_stemming>25</max_results_stemming>
<enable_warmup>true</enable_warmup>
<warmup_queries_number>500</warmup_queries_number>
<cache_results>true</cache_results>
<didymean_threshold/>
<res_threshold>50</res_threshold>
<score_threshold>0.75</score_threshold>
<synonyms/>
<levels/>
<level desc="very high">0.8</level>
<level desc="high">0.1</level>
<level desc="normal">0.01</level>
<level desc="low">0.005</level>
<level desc="very low">0</level>
<threshold>normal</threshold>
<didymean/>
<preferred_result>sx</preferred_result> <!-- sx/ngram --></preferred_result>
<sx_threshold>0.975</sx_threshold>
<ngram_threshold>0.65</ngram_threshold>
<freq_threshold>5</freq_threshold>
<candidates_to_examine>20</candidates_to_examine>
<field>title</field>
<dictionary_languages>eng</dictionary_languages>
<advanced_merge_factor>500</advanced_merge_factor>
<advanced_merge_docs>500</advanced_merge_docs>
<validate_didymean>true</validate_didymean>
<add_search_statistics>true</add_search_statistics>
<search_statistics_fetch_param>all</search_statistics_fetch_param>
<filters/>
<filter>scope:(north)</filter>
<filter>scope:("kings")</filter>
<filter>facet_frbrtype:(7 OR 6)</filter>
<repository active="true"/>
<path>/exlibris/primo/indexes</path>
<agents desc="collections of all search instances to be searched by jaguar" auto_deploy="active" swapping_type="agents"/>
<agent port="9501" host="il-primo06.corp.exlibrisgroup.com" connection_type="remote" active="true"/>
http://www.exlibrisgroup.com/xsd/jaguar/search_schema">
<slice/>
<path>/exlibris_primo/inst_1_index</path>
<load2ram>false</load2ram>
<slice/>
<path>/exlibris_primo/inst_2_index</path>
<load2ram>false</load2ram>
<agent port="9501" host="il-primo04.corp.exlibrisgroup.com" connection_type="local" active="true"/>
http://www.exlibrisgroup.com/xsd/jaguar/search_schema"/>
<multiple_front_ends/>
<mfe_master>il-primo04.corp.exlibrisgroup.com:2701</mfe_master>
<mfe_slaves>il-primo04.corp.exlibrisgroup.com:2701</mfe_slaves>
<mfe_config>none</mfe_config>
Metasearch Functionality
Primo uses MetaLib as a metaSearch Engine, via the MetaLib X-Server. Primo sends MetaLib a list of resources and a query and receives a list of results as MARC records. Each result includes an OpenURL. Primo then converts the metasearch MARC records to PNX records using the on-the-fly MetaLib pipe. When relevant, the metasearch results are added to the local results and the merged list is then deduplicated and ranked, and facets are calculated.
Third Node Functionality
In addition to local and remote search, Primo supports plug-in capabilities of third-party search functions within the Primo application. This feature allows end users to utilize the strength of the Primo tool set (look and feel, caching, faceting highlighting, statistics, e-shelf, tagging, and reviews) with their search methods or special resources.