
Overview of the Publishing Process
This information is not applicable to Primo VE environments. For more details on Primo VE configuration, see Primo VE.
The Publishing Process is the process that Primo uses to retrieve and process data from external library systems. This process involves a number of steps, which are outlined in the following figure.
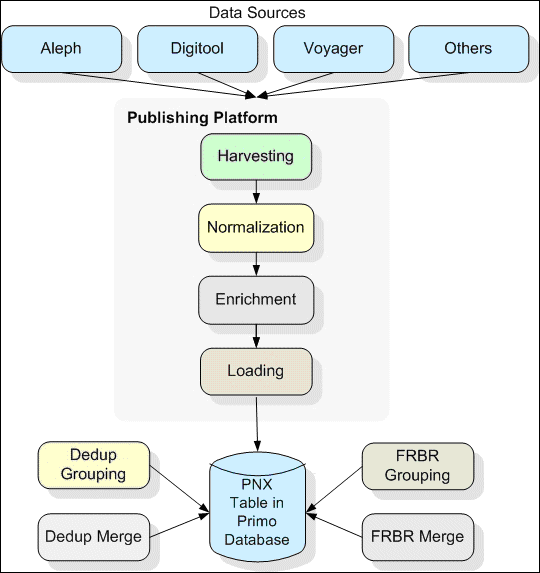
Publishing Process
Each of the steps in the publishing process is discussed in detail in the following sections.
Preparing the Source Data
Before Primo begins harvesting data, the source system must prepare the following:
-
The complete data source for the initial harvesting of the data.
-
A delta of the data, including only changed records (new, updated, and deleted), for the ongoing update of the database.
All the information to be contained in the PNX database table should be included in a single record that can be identified by a unique and persistent ID. This means that any information that is related to the main record (for example, holdings information related to the bibliographic record) must be added to the extracted record.
The structure of the record must conform to one of the following formats:
-
MARCXML (http://www.loc.gov/standards/marcxml/).
-
Dublin Core XML (http://dublincore.org/documents/dc-xml-guidelines/).
The record can include non-standard MARC or Dublin Core fields, including non-numeric codes for MARC.
Harvesting Data
A single source system can contain several data sources, such as the following systems:
-
For SFX, Primo may harvest a single SFX instance, but a single SFX installation may include several data sources (that is, instances).
-
For Aleph and Voyager, every bibliographic database is a separate data source, but a single installation of Aleph or Voyager may include several bibliographic databases that are harvested by Primo.
The harvesting stage is the first step in the publishing pipe. Primo supports several harvesting methods, including:
-
FTP/SFTP Harvesting - Primo can harvest files from a remote server. To perform FTP harvesting, Primo must be able to access the server using the server IP, the directory name, user name, and password. For ongoing harvesting, Primo retains the date and time of the last harvest.The Publishing Platform harvests all files with a server timestamp greater than the last harvesting date. File names must be unique. Optionally, the file can be deleted once it was successfully harvested.
-
Copy Harvesting—Primo can harvest files by copying files from any mounted drive. To perform copy harvesting, Primo must have READ permission for the directory.
-
OAI Harvesting—Primo can harvest records from an OAI server by sending an OAI-PMH request and processing the records that are sent in response to the request. To perform OAI harvesting, Primo needs the OAI server IP address and port number, as well as the OAI set to harvest. For ongoing harvesting, Primo retains the data and time of the last request.
Normalizing the Harvested Data
Before beginning the normalization stage, records are classified as follows:
-
Normal records include new and updated records from the data source that need to be normalized and enriched before being loaded to the persistence layer.
-
Deleted records are records that were deleted in the data source and need to be deleted from the persistence layer. These records are deleted directly from the persistence layer and do not go through the normalization and enrichment stages.
Records are divided into groups called bulks. The default bulk size is up to 1,000 records. Bulks are zipped in order to reduce the file count and the written data sizes, as well as improve performance.
In the normalization process, the source records are converted to the PNX format using the normalization mapping set of the pipe. For more information about the PNX format, refer to the Primo Technical Guide.
Enriching the Data
Once the records are normalized, they may be enriched with additional data. Every publishing pipe can be assigned an enrichment set, which includes one or more enrichment routines.
Loading Data into the Primo Database
Once records have been normalized and enriched, they are loaded into the PNX table in the Primo database. The PNX table is an Oracle database table in which the PNX records are stored before they are retrieved and loaded to the Search Engine. The duplicate record detection process is also handled in the Primo database. The Primo database has a number of tables, which store various types of data used in Primo.
Processing Duplicate Records (Dedup)
During the duplicate record detection process (Dedup), the publishing platform locates duplicate records and assigns them the same matchID. This is performed by using the Dedup vector of the PNX record. For more information about the Dedup process and the matching algorithms, refer to the Duplicate Detection Process section in the Primo Technical Guide.
Dedup Process
The persistence layer duplication detection database stores the Dedup vector. Once the vector is stored in the database, it is removed from the normalized record. Part of the vector is indexed in order to locate candidates for a match.
When a record is matched against the database, the system first attempts to find a match based on the RecordID. If a match is not found, the record is new and the system tries to find a matching record based on the vector. If a match is found, the record is assigned the MatchID of the record with which it is matched. Once a match is found, the matching process stops. If a match is not found, the record is assigned a new MatchID.
If there is a match on the RecordID, the system compares the vector in the incoming record with its vector in the database. If the vector is the same, the record is assigned its present MatchID. If it is not the same, the record is treated as a new record (the MatchID is removed) and the system tries to find it a matching record.
It is important to distinguish between the initial and ongoing Dedup process. During the initial publishing stage, all data sources are first loaded to the persistence layer, and only when all records have been loaded, will the duplicate detection process start. In the ongoing publishing stage, the duplicate detection process is run as part of every pipe. The difference is due to the fact that in the initial publishing stage, the Dedup is run in multi-processing mode to save time, while in ongoing publishing stage, every record is Deduped sequentially.
Merging Duplicate Records (Dedup)
Once all matching records are located in the Dedup process, the system creates a merged record.
Processing Records (FRBR)
The grouping process (FRBR) is based on creating a vector for every record. The vector includes one or more keys that identify the work it represents. Records that have a matching key (Primo attempts to match all keys in the record) are added to a group and are assigned the ID of the group (frbrID). Each record can belong to only one group. In other words, once a record is matched with an existing group, Primo terminates the grouping process for that record.
Primo creates a merged record for the FRBR group. Unlike the Deduped merged record, the Search Engine retrieves and indexes both the merged FRBR record and the individual records in the FRBR group.