
重複タイトル分析の使用
重複タイトル分析を使用するには、次の役職が必要です。
- リポジトリマネージャー
重複タイトル分析ジョブ は重複する書誌レコードを識別するレポートを作成します。 次のパラメータのいずれかに 同じデータがある場合、レコードは重複していると見なされます:
- (OCLC)などの接頭語付きまたは接頭語なしのシステム制御番号(035フィールド)
- その他の標準識別子 (024フィールド)
- ISSN
- ISBN
注: ここでのISBN一致は、MDインポートのISBN一致方法と同じものではありません。このISBNの一致は、ジョブのパラメーターを考慮しながら、SYSTEM_CONTROL_NUMBER、VALID_ISBN、VALID_ISSN、およびVALID_STANDARD_IDENTIFIERの値を比較します。
重複タイトル分析 ジョブの実行後、その結果は、[ジョブの監視]ページの[履歴]タブから表示できます([管理] > [ジョブとセットの管理] > [ジョブの監視])。[履歴]タブは、重複タイトル分析ページで[ジョブ履歴]を選択することでアクセスすることもできます。
重複タイトル分析ジョブからの出力ファイルは、次の2つの方法で使用できます。
- 機関が重複レコードを独自に分析する。
- 入力ファイルとしてレコードを結合して在庫を統合する。
詳細については、重複タイトル分析の動画 (1分) を参照してください。
「重複タイトル分析」ジョブは、機関レベルでのみ実行されます。ネットワークゾーンがある場合、ジョブはネットワークゾーンと機関ゾーンで 別々に実行する必要があります。
重複タイトル分析を実行する
重複タイトル分析ジョブを実行するには:
- [重複タイトル分析]ページを開きます([リソース] > [アドバンスツール] > [重複タイトル分析ページ])。
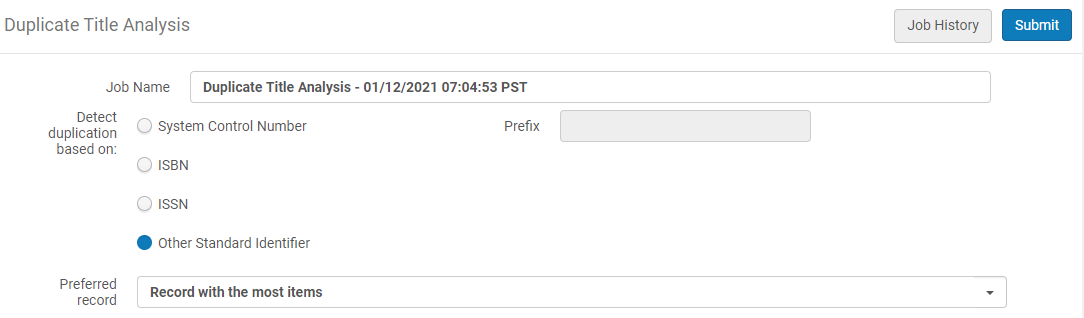
- [重複を検出する]パラメータで、重複する書誌レコードを照合するための次のオプションのいずれかを選択します。
- システムコントロール番号/接頭語:システムコントロール番号パラメーターは、一致を判別するためにMARC 21 035フィールドを使用します。さらに、035フィールドに含まれる(OCoLC)などの接頭語を指定して、035フィールドでの照合に使用される基準を絞り込むことができます。接頭語フィールドはオプションです。
- ISBN
- ISSN
- その他の標準識別子:その他の標準識別子パラメーターは、一致の判別にMARC 21 024フィールドを使用します
- 「優先レコード」 パラメーターで、システムによって優先レコード(他のレコードが統合されるレコード)として扱われるレコードを選択します。
- 計算しない – レポートには優先レコードが含まれていません。
- 目録が最も多いレコード – 優先レコードは、グループ内でアイテム/ポートフォリオ/コレクション/デジタル表現の数が最も多いレコードです。エンティティの数が同じであるレコードが複数ある場合は、簡易レベルが最も高いレコードが優先されます(エンティティの数が最も多いレコードから)。
ネットワークゾーンは物理的な目録を保持しません。優先レコードを選択するには、別の基準を使用することをお勧めします。 - 簡易レベルが最も高いレコード – 優先レコードは簡易レベルが最も高いレコードです(10は1よりも高くなります)。同様の最も高いの簡易レベルを持つレコードが複数ある場合は、エンティティが最も多いレコードが優先されます。
- 優先レコードを決定できない場合 (同じ「優先」特性を持つ複数のレコードがあります)– MMS IDが最小のレコードが優先として使用されます。
- 送信を選択します。[作業の監視]ページに実行中タブが開き、[実行中](またはジョブ列内のアクティビティに応じて[保留中]) のジョブステータスが表示されます。
- ジョブの実行が完了したら、[履歴]タブを選択してジョブの結果を表示します。
- 実行した重複タイトル分析ジョブの場合、行アクションのリストから[リポート]を選択して、[ジョブリポート]ページを開きます。
- カウンタセクションで、Excel.csvフォーマットの重複タイトルリポートをダウンロード/開くリンクを選択します。
タイトル分析リポートを重複する
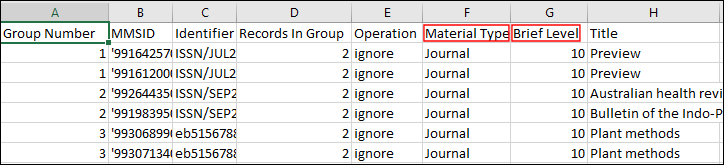
Excel.csvフォーマットの重複タイトル分析リポート
リポートには、重複レコードがグループで表示され、次の 情報が提供されます。
- [グループ番号] - 一致する書誌レコードは、グループ番号列の同じグループ番号によって識別されます。
- MMS ID
- [識別子] – 重複タイトル分析ジョブに基づいて重複を検出するに選択されたフィールドから、システムが一致を検出した値。
- [グループ内のレコード] – この列は、同じグループ内のレコードの総数を示します。
- 操作 - システムによって計算された優先レコードがどれであるかを示します。
- 優先 – 優先レコードの場合。
- 統合 - 非優先レコードの場合。グループ内の非優先レコードは 選択した統合ルーチンに従って、優先レコードに統合されます。非優先レコードに関連付けられている目録は、優先レコードの目録と結合されます。
- 無視 - 機関に属していないレコードがあるグループのレコードの場合。たとえば、プロセスがネットワークゾーンのメンバーでアクティブ化され、グループにNZからのレコードが含まれている場合、 グループは処理されません。
- 統合されていません - グループ内のレコードの1つが統合できない場合、グループ全体は 処理されず、「統合されていません」として報告されます。
- 資料タイプ
- 簡易レベル
- タイトル
- リソースタイプ - この列には、「リソースタイプフィールド」セクションで説明されているリソースタイプ情報が表示されます。
- 所有 - レコードの目録があるメンバー機関のセミコロン区切りのリスト。これは、重複タイトル分析ジョブが ネットワークゾーンで実行されている場合にのみレポートに表示されます。
- レコード関係の構築ジョブ (システムジョブ) の前に重複タイトル分析のジョブを実行すると、削除されたレコードもこのリポートに含まれます。
- レコード関係の構築ジョブの後に重複タイトル分析ジョブを実行した場合、削除されたレコードはこのリポートに含まれません。