
Linguistic Features for Primo VE
This section describes the various linguistic features that Primo VE supports. For a description of the linguistic features that Central Discovery Index (CDI) uses, see Multilingual Search Features.
Language Detection
In order to offer language-based services, Primo VE must first detect the language of the indexed text and the query. Currently, Primo VE can detect the following languages:
-
Latin-based: English, Spanish, Italian, German, French, and Danish.
-
Asian: Chinese, Japanese, and Korean. If the character is Chinese and the locale of Primo VE is Japanese or Korean, Primo VE uses the locale of the selected language.
-
Other languages that have a specific character range: Hebrew, Arabic, and so forth.
Language detection is based on comparing the words of the record and the query with a dictionary. If fifty percent or more of the words match, the language is identified.
Search behavior may vary depending on the language context used for indexing and searching. In some cases, special characters or punctuation in a search term may be handled differently when the record language and the UI/search language are not the same. If expected results are not retrieved, try searching in the relevant UI language for the record’s language context.
Stop Words
Stop words are common words (such as articles, prepositions, and pronouns) that are filtered from keyword searches to provide the best search results. For example, if a user searches for the adventures of huckleberry finn, Primo VE performs the following search without the stop words the and of:
For exact phrases (such as "the adventures of huckleberry finn"), Primo VE performs the following search to provide more precise results:
"the adventures of huckleberry finn"
For a list of stop words that Primo VE uses for searching and indexing, see the following files per language: Danish, English, German, Spanish, French, Italian, and Chinese.
Author Names
Primo VE treats words with O' apostrophe as a stop word in many Latin languages and indexes them as two separate words. This happens also for authors such as O'Leary, which is indexed as o and leary. As a result, a search for Oleary does not retrieve the same number of results as O'Leary. When users search for names that typically include apostrophes but do not include the apostrophe, Primo VE also searches for the name as if the users had included the apostrophe. For example, if the user's query is Oleary, Primo VE changes the query to search for oleary or o leary.
Stemming
Stemming is a process that reduces inflected (or sometimes derived) words to their stem, base, or root form. When stemming is activated, the stemmed form of the search term is added to the query with a very low boost to improve the search results. Currently, only the following languages support this functionality: German, Spanish, Italian, English, French, and Danish.
-
Stemming works independently of the smart search and ranking mechanism that boosts adjacent query words. This enables the system to boost stemmed versions of search terms when they are not adjacent to other search terms.
-
Primo VE does not unstem terms with the exception of pluralizations. If stemming is activated, Primo VE includes the plural form of the term and gives its results lower ranking. For example, a search for wild flower expands to wild AND (flower OR flowers^0.5).
The add_keywords_stemming_to_query parameter on the Discovery Customer Settings page (Configuration Menu > Discovery > Other > Customer Settings) enables you to activate/deactivate the use of stemming.
Synonyms
Primo VE adds the following types of synonyms to a search query:
-
Numbers – when a search contains a digit, Primo VE adds the spelled-out number to the query. For example, Primo VE adds the word ninth to a search query for 9th.
-
US or British spelling – when a search contains a word spelled according to US or British spelling, Primo VE adds the corresponding synonym to the search query. For example, Primo VE adds the word colour to a search query for color.
-
Commonly misspelled words – for commonly misspelled words, Primo VE adds the word spelled correctly to the search query.
-
Hyphenated search terms – Local repository searches that include a search term with a hyphen return additional results by including the term's compound word in the search. For example, searches for the term chat-room also includes results for chat room and chatroom. Previously, the system only added results for chat room. The supported terms are based on the same terms used for CDI results (see Supported Compound Words)
Primo VE includes the original search term in the query in addition to the synonym. For example, Primo VE searches for (fifth OR 5th) AND dimension if the query is fifth dimension.
Primo VE applies a different synonym list based on language recognition.
The following parameter on the Discovery Customer Settings page (Configuration Menu > Discovery > Other > Customer Settings) enables you to disable the use of synonyms:
-
disable_synonyms – When set to true, this parameter disables using synonyms in search queries. By default, it is set to false.
For a list of the supported synonyms for a language, download each file by clicking the language and saving it to a file: German, English, French, Hebrew, and Chinese. Since this information is updated per customer requests, contact support for an updated list.
Linguistic Query Expansions and Query Length Handling
Primo enhances user search queries through various linguistic expansions to improve recall and relevance. These include inflectional variants, stemming, synonyms, author name variants, and locale-specific language processing. As a result, the underlying Solr query is often significantly expanded beyond the original keywords entered by the user.
In some cases—particularly with long or complex queries—this expanded query may exceed Solr’s technical limits. When this occurs, the system will dynamically reduce or disable certain linguistic expansions in order to ensure the query can still be processed and results can be returned. This fallback behavior ensures that the user receives relevant results based on their core query terms, rather than encountering a "no results" outcome due to technical limitations.
This adjustment is performed automatically and transparently, with the goal of maintaining the best possible user experience while respecting system constraints.
Did You Mean
Did You Mean (DYM) suggestions improve search queries by correcting typographical errors and common misspellings in search terms to return expected search results to users. DYM suggestions are provided when the original query returns less than the threshold of 15 search results, which is not configurable.
In the following example, the search term leukemia is missing a single character and returns no results. Users can select the suggestion that appears below the search box if they want to see results for that suggestion.
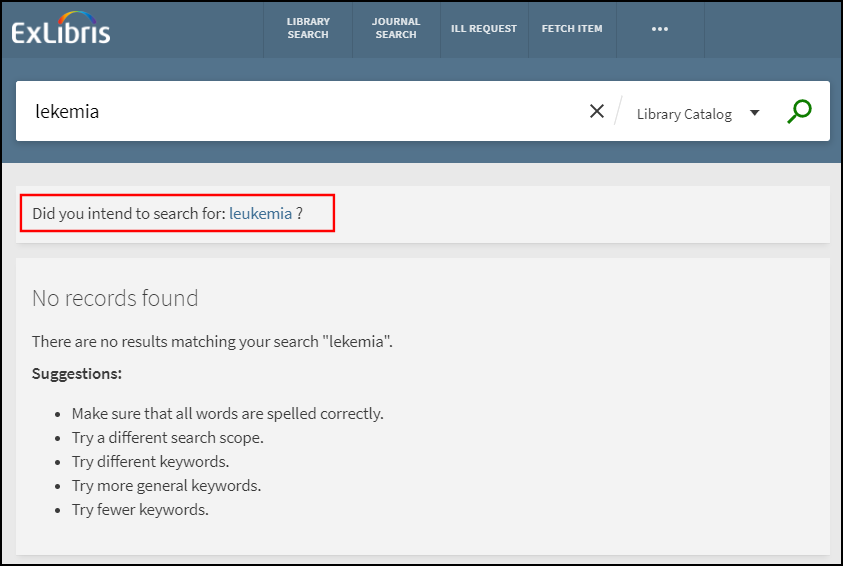
How Does DYM Work?
DYM is invoked when the original search query returns less than 15 results. If invoked, the DYM algorithm performs the following:
-
For each search term in the original query:
-
The following sources are checked for a match:
-
DYM index – This index is created by applying the Levenshtein distance, which is the distance between two words using a minimum number of single-character edits (such as insertions, deletions, or substitutions) to the regular titles index. For DYM, the index limits edits to a single character.
For example, if the word leukemia is indexed in the regular title index, the following terms could return a suggestion for leukemia:
-
lekemia - The letter u is missing.
-
leekemia - The letter u has been replaced with the second e.
-
aleukemia - The letter a has been added to the beginning of the term.
-
-
Dictionary – The dictionary contains commonly misspelled words from which to check.
-
-
For each match found, a candidate query is created by replacing the term in the original query with its match.
When the candidate query is created by dividing an apparently non-existent word into two existing words, the two words appear in the candidate query in parentheses.Note that the parentheses themselves may affect the ranking of the candidate queries described in the next step.
-
-
Each candidate query is tested, and the highest-ranking candidate that returns enough results is used for the suggestion.
Configuration Options
This functionality is enabled out-of-the-box, and it is not configurable. If you want to hide this functionality, add the following stanza to your CSS:
#mainResults > div.margin-bottom-medium > md-card {
visibility:hidden;
}
Normalization of Special Characters
Based on the configured indexing language, Primo VE normalizes special characters and characters with diacritics in the search index. Primo VE supports the following indexing languages: Arabic (ar), Croatian (hr), Farsi (fa), German (de), Icelandic (is), Lithuanian (it), Norwegian/Danish (no), Swedish (sv), Spanish (es), Polish (po), Korean (ko), Chinese (zh), and Japanese (ja).
Specifically for Hong Kong, your library can decide to use either Chinese or TSVCC for the character conversion.
If you want to change your indexing language to one of the supported languages, open a Salesforce support ticket. Note that this will require your data to be re-indexed. After re-indexing is complete, searches use the language-specific character conversions described below, regardless of the selected UI language.
Arabic and Farsi
| Character | Conversion |
|---|---|
| 0627 (آ) | 0622 (ا) |
| 0623 (إ) | 0622 (ا) |
| 0625 (أ) | 0622 (ا) |
| 0649 (ئ) | 0626 (ى) |
| 064A (ي) | 0626 (ى) |
| 0647 (ۀ) | 06C0 (ه) |
| 0629 (ة) | 06C0 (ه) |
| 0642 (ڨ) | 06A8 (ق) |
| 0648 (ؤ) | 0624 (و) |
| 062C (چ) | 0686 (ج) |
| 0628 (پ) | 067E (ب) |
| 0643 (گ) | 06AF (ك) |
| 0632 (ژ) | 0698 (ز) |
| 0641 (ڤ) | 06A4 (ف) |
Croatian
Searching
For searching, Primo VE supports Croatian and foreign (non-Croatian) diacritics chars, as follows:
- Croatian diacritics characters Č, Ć, Đ, Š, Ž are kept as is – they are not converted.
- Foreign (non-Croatian) diacritics characters are converted to their base letters. For example:
- Émile ( É -> E )
- Müller ( ü -> u )
- García ( í -> i )
- Łukasz ( Ł -> L )
- Zoë ( ë -> e )
Sorting and Browsing
For sorting and browsing, Primo VE supports Croatian diacritics and special digraphs, with the following sort order:
A, B, C, Č, Ć, D, DŽ, Đ, E, F, G, H, I, J, K, L, LJ, M, N, NJ, O, P, Q, R, S, Š, T, U, V, W, X, Y, Z, Ž
Foreign (non-Croatian) diacritics characters are sorted as their base letter.
Danish
| Character | Conversion |
|---|---|
| 00E4 (ä) | 0061 0065 (ae) |
| 00C4 (Ä) | 0061 0065 (ae) |
| 00E5 (å) | 0061 0061 (aa) |
| 00C5 (Å) | 0061 0061 (aa) |
| 00D8 (Ø) | 006F 0065 (oe) |
| 00F8 (ø) | 006F 0065 (oe) |
| 00D6 (Ö) | 006F 0065 (oe) |
| 00F6 (ö) | 006F 0065 (oe) |
| 00E6 (æ) | 0061 0065 (ae) |
| 00E6 (Æ) | 0061 0065 (ae) |
-
For search, the conversion is not bi-directional. For example, searches for the term Edgar Allan Poe returns results for Edgar Allan Pö, but searches for the term Edgar Allan Pö does not return results for Edgar Allan Poe.
-
For sort and browse, Primo VE uses the following order for the Danish alphabet:
-
a/A-z/Z (with Ü/ü sorted as Y/y)
-
æ/Æ ; ä/Ä
-
ø/Ø ; ö/Ö
-
å/Å ; aa/Aa
-
German
| Character | Conversion |
|---|---|
| 00DC (Ü) | 0075 0065 (ue) |
| 00FC (ü) | 0075 0065 (ue) |
| 00C4 (Ä) | 0061 0065 (ae) |
| 00E4 (ä) | 0061 0065 (ae) |
| 00D6 (Ö) | 006F 0065 (oe) |
| 00F6 (ö) | 006F 0065 (oe) |
Norwegian
| Character | Conversion |
|---|---|
| 00E4 (ä) | 0061 0065 (ae) |
| 00C4 (Ä) | 0061 0065 (ae) |
| 00E5 (å) | 0061 0061 (aa) |
| 00C5 (Å) | 0061 0061 (aa) |
| 00D8 (Ø) | 006F 0065 (oe) |
| 00F8 (ø) | 006F 0065 (oe) |
| 00D6 (Ö) | 006F 0065 (oe) |
| 00F6 (ö) | 006F 0065 (oe) |
| 00E6 (æ) | 0061 0065 (ae) |
| 00E6 (Æ) | 0061 0065 (ae) |
-
For search, the conversion is not bi-directional except for the special characters Å and å. For example, searches for the term Edgar Allan Poe does return results for Edgar Allan Pö, but searches for the term Edgar Allan Pö does not return results for Edgar Allan Poe.
-
For sort and browse, Primo VE uses the following order for the Norwegian alphabet:
-
a/A-z/Z (with Ü/ü sorted as Y/y)
-
æ/Æ ; ä/Ä
-
ø/Ø ; ö/Ö
-
å/Å ; aa/Aa
-
Icelandic
In Icelandic, the accents for some characters not only signify different pronunciation, but also signify a different meaning.
Character Conversions
The following table lists the characters that require special conversion. All other special characters with accents and umlauts, such as ä, ë, ü, û, è, are converted to their “default” value (a, e, u, and so forth).
| Character | Conversion |
|---|---|
| 00C5 (Å) | 0041 0041 (AA) |
| 00E5 (å) | 0061 0061 (aa) |
| 00D8 (Ø) | 00D6 (Ö) |
| 00F8 (ø) | 00F6 (ö) |
Sort Order
The following table lists the sort order of characters in Icelandic. The characters highlighted in yellow are not converted and are sorted as indicated, which means that searches for these special Icelandic letters should return matches for that special letter. The 'regular' character should not be included. Examples:
-
When searching for “sál”, the word “sal" should not be returned.
-
When searching for “skola”, the word “skóla" should not be returned.
| Capital Character | Small Character |
|---|---|
| A (0041) | a (0061) |
| Á (00C1) | (00E1) |
| B (0042) | b (0062) |
| C (0043) | c (0063) |
| D (0044) | d (0064) |
| Ð (00D0) | ð (00F0) |
| E (0045) | e (0065) |
| É (00C9) | é (00E9) |
| F (0046) | f (0066) |
| G (0047) | g (0067) |
| H (0048) | h (0068) |
| I (0049) | i (0069) |
| Í (00CD) | í (00ED) |
| J (004A) | j (006A) |
| K (004B) | k (006B) |
| L (004C) | l (006C) |
| M (004D) | m (006D) |
| N (004E) | n (006E) |
| O (004F) | o (006F) |
| Ó (00D3) | ó (00F3) |
| Ø (00D8) | ø (00F8) |
| P (0050) | p (0070) |
| Q (0051) | q (0071) |
| R (0052) | r (0072) |
| S (0053) | s (0073) |
| T (0054) | t (0074) |
| U (0055) | u (0075) |
| Ú (00DA) | ú (00FA) |
| V (0056) | v (0076) |
| W (0057) | w (0077) |
| X (0058) | x (0078) |
| Y (0059) | y (0079) |
| Ý (00DD) | ý (00FD) |
| Z (005A) | z (007A) |
| Þ (00DE) | þ (00FE) |
| Æ (00C6) | æ (00E6) |
| Ö (00D6) | ö (00F6) |
-
The search results are sorted using the Icelandic alphabetical sort order above.
-
The filing values for browsing will not normalize the diacritics of the highlighted special characters so that the browsing corresponds to the Icelandic alphabetical sort order.
-
Data that contains characters or diacritics that are not listed above will behave according to the default English language settings.
Lithuanian
The Lithuanian language contains 18 special letters that are indexed as themselves : ą, č, ę, ė, į, š, ų, ū, ž, Ą, Č, Ę, Ė, Į, Š, Ų, Ū, and Ž.
Polish
| Character | Conversion |
|---|---|
| 0104 (Ą) | 0061 0061 (aa) |
| 0105 (ą) | 0061 0061 (aa) |
| 0106 (Ć) | 0063 0063 (cc) |
| 0107 (ć) | 0063 0063 (cc) |
| 0118 (Ę) | 0065 0065 (ee) |
| 0119 (ę) | 0065 0065 (ee) |
| 0141 (Ł) | 006C 006C (ll) |
| 0142 (ł) | 006C 006C (ll) |
| 0143 (Ń) | 006E 006E (nn) |
| 0144 (ń) | 006E 006E (nn) |
| 00D3 (Ó) | 006F 006F (oo) |
| 00F3 (ó) | 006F 006F (oo) |
| 015A (Ś) | 0073 0073 (ss) |
| 015B (ś) | 0073 0073 (ss) |
| 0179 (Ź) | 007A 007A (zz) |
| 017A (ź) | 007A 007A (zz) |
| 017B (Ż) | 007A 0065 (ze) |
| 017C (ż) | 007A 0065 (ze) |
Spanish
| Character | Conversion |
|---|---|
| 00D1 (Ñ) | 00F1 (ñ) |
| 00F1 (ñ) | 00F1 (ñ) |
| 00C7 (Ç) | 00E7 (ç) |
| 00E7 (ç) | 00E7 (ç) |
| 0140 (ŀ) | 0140 (ŀ) |
| 013F (Ŀ) | 0140 (ŀ) |
Swedish
| Character | Conversion |
|---|---|
| 00E4 (ä) | 0061 0065 (ae) |
| 00C4 (Ä) | 0061 0065 (ae) |
| 00E5 (å) | 0061 0061 (aa) |
| 00C5 (Å) | 0061 0061 (aa) |
| 00D8 (Ø) | 006F 0065 (oe) |
| 00F8 (ø) | 006F 0065 (oe) |
| 00D6 (Ö) | 006F 0065 (oe) |
| 00F6 (ö) | 006F 0065 (oe) |
| 00E6 (æ) | 0061 0065 (ae) |
| 00E6 (Æ) | 0061 0065 (ae) |
-
For search, the conversion is not bi-directional. For example, searches for the term Edgar Allan Poe does return results for Edgar Allan Pö, but searches for the term Edgar Allan Pö does not return results for Edgar Allan Poe.
-
For sort and browse, Primo VE uses the following order for the Swedish alphabet:
-
a/A-z/Z (with æ/Æ sorted as ae/Ae; Ü/ü is sorted as Y/y)
-
å/Å
-
ä/Ä
-
ö/Ö ; ø/Ø
-