
Overview of the Primo Back Office
It is important to understand the main purposes of Primo’s Back Office (see Back Office figure), the Back Office components, and how these components relate to each other.
It is not recommended for staff users to perform Back Office configurations from multiple windows and tabs.
The basic purpose of the Back Office is to provide for the following:
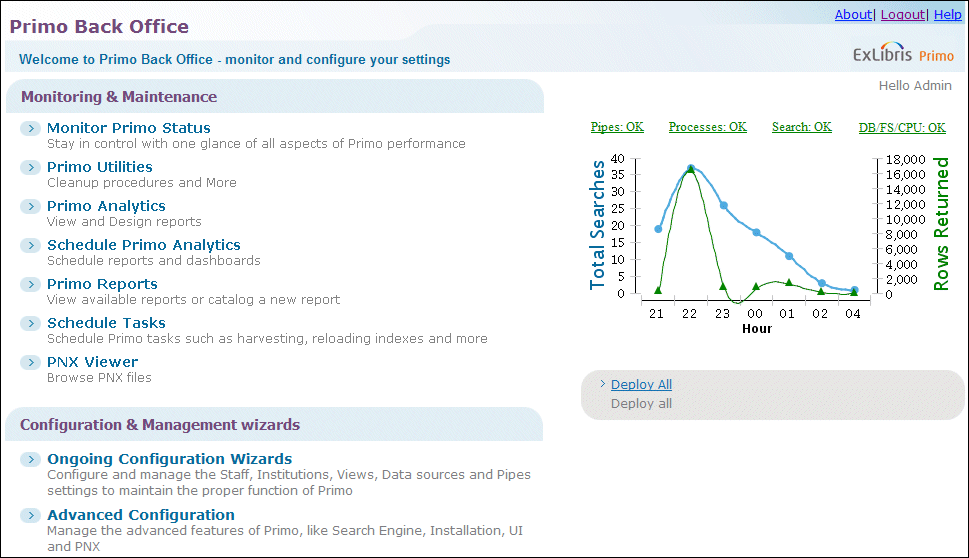
Primo Back Office Home Page
The Dashboard displays only for Local (on-premises) Primo customers.
Configuring Primo's Front End
Through the Back Office, Primo administrators can configure the settings and functions of Primo's Front End user interface. Although the system's out-of-the-box settings can be used, it is necessary to perform a minimal amount of customization to your system.
The Primo Front End user interface is made up of views, which are the sole means of user interaction with Primo. Each institution can have its own fully customized view, which must be configured through the Back Office.
Every view can have one or more tabs. Defining tabs enables you to divide the Primo repository and records from remote resources into resource groups or types. For example, the search box in the following figure has a tab for local searches and another tab for remote searches.

Primo Front End Search Box
Within each tab, one or more search scopes can be defined. A search scope groups records so that a search can be restricted to only those records.
After discovery, Primo indicates the availability of the resource in the source system. Primo interacts with the source system to provide more information about the resource or to deliver the resource.
Configuring the Publishing Platform Pipe Flow
The Back Office is used to configure and control the applications that manage the publishing platform. The publishing platform is software that enables a Primo site to consolidate its full range of resources, regardless of the resource’s media type. The Publishing Platform harvests and then normalizes the source records of the various resources to a standard and enriched format. The new record format is called the PNX (Primo Normalized XML).
The Primo publishing platform also enables the user to schedule unattended harvesting and processing of the data sources, while letting the user monitor and control the entire process of the pipe run. The publishing platform is capable of working with various data sources and data formats. To differentiate between the Publishing Platform processes, pipes are defined for every data source.
Stages
The publishing pipe consists of the following stages:
Once the records are loaded into the Primo database, they go through the following additional stages (see Dedup and FRBR)
- Duplicate Record Detection (Dedup)
- FRBR
Harvesting
The first stage in a Primo pipe is harvesting, which is basically copying the source data to the Primo system. Primo supports several harvesting methods including FTP, Copy, and OAI. These harvesting methods can copy the files from a remote server, any mounted drive, or a server that stores metadata in Dublin Core and supports OAI-PMH harvesting.
Splitting Records
During the second stage, the records are split into two groups. The first group is a bulk of normal records, which are sent through the publishing pipe to the Normalization and Enrichment stages. These normalized records include new and updated records received during the Harvesting stage. The second group of records is deleted records. These records were deleted from the data sources, and thus do not need to be normalized or enriched, but the records still need to be deleted from the Primo index.
Normalization
Every pipe also works with a set of normalization rules. Normalization rules can be shared by different pipes. The normalization process converts the group of normal records to the PNX format, using the normalization rules set of the pipe.
Enrichment
Once the records are normalized, they may be enriched with additional data. Every publishing pipe can be assigned an enrichment set, which includes one or more enrichment routines.
Load to Primo Database
The normalized and enriched data is loaded into the Primo database. The Primo database stores the PNX records (in the P_PNX table) so that they can be retrieved and loaded into the search engine. In addition, the pipe stores the original source records in the database (in the P_SOURCE_RECORD table). After the records are loaded into the Primo database, the Duplicate Record Detection and FRBRization processes are performed.
Dedup and FRBR
During the Duplicate Record Detection (Dedup) process, the publishing platform locates duplicate records and groups them together based on predefined algorithms.
The FRBRization process groups records that represent the same intellectual work based on the principles published by IFLA in Functional Requirements for Bibliographic Records: Final Report and IFLA Study Group on the Functional Requirements for Bibliographic Records. For more information on the Dedup and FRBR processes, refer to the Primo Technical Guide.
Once the Publishing process is complete, the search engine can retrieve the PNX records from the Primo database.
The above process describes the standard flow of a “regular” pipe. There are additional types of pipes which include variations. For more information on pipe types, refer to Defining a Pipe.
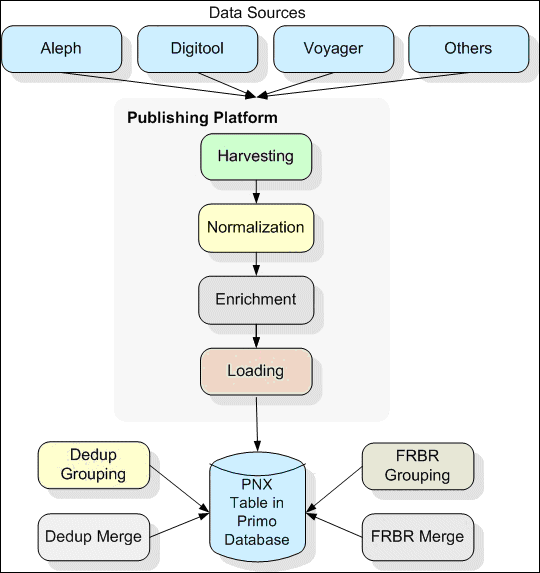
Primo Publishing Platform Pipe Flow
Monitoring Primo Status
For on-premises customers only, the Back Office displays a dashboard that you can use to monitor the system's performance, including the status of the system's pipes, processes, and search engines. Monitoring the Primo status enables you to ensure your environment system is running properly. The links at the top of the dashboard indicate the status using text and color indication to let you know right away whether the different parts of the system are functioning properly or not. These system parts include Primo's pipes, processes, and search engines.
Beneath the status links is a graph of search statistics. The graph displays the total amount of searches that were performed within the last six hours and the average amount of records returned for these searches.
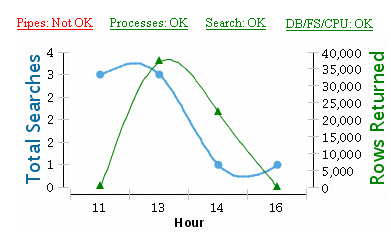
Dashboard Monitor in Back Office - On-Premises Customers Only
For all customer installations, you can monitor the pipes and processes used by your system (Primo Home > Monitor Primo Status). Monitoring the pipes and processes helps determine which pipes and processes need to be executed, cleaned, or edited. You can also monitor the slices within the Primo search engine to ensure that the search engine is functioning properly.
For cloud installations, the SEs and many of the processes are monitored but can be maintained only by Ex Libris.