
Using Duplicate Title Analysis
To work with Duplicate Title Analysis, you must have the following role:
- Repository Manager
The Duplicate Title Analysis job creates a report that identifies duplicate bibliographic records. Records are considered duplicates if they have the same data in one of the following parameters:
- System Control Number (035 field) with or without a prefix such as (OCLC)
- Other Standard Identifier (024 field)
- ISSN
- ISBN
Note: The ISBN match here is not identical to the ISBN match method in the MD import. This ISBN match compares the values of SYSTEM_CONTROL_NUMBER, VALID_ISBN, VALID_ISSN, and VALID_STANDARD_IDENTIFIER, while considering the job's parameters.
After the Duplicate Title Analysis job runs, its results can be viewed from the History tab on the Monitor Jobs page (Admin > Manage Jobs and Sets > Monitor Jobs). The History tab can also be accessed by selecting Job History on the Duplicate Title Analysis page.
The output file from the Duplicate Title Analysis job can be used in two ways:
- For the institution to independently analyze the duplicate records.
- As an input file for the Merge Records and Combine Inventory job.
For more information, see the Duplicate Title Analysis video (1:00 min.).
The Duplicate Title Analysis job runs on the institution level only. If there is a Network Zone, the job will need to be run at the Network Zone and Institution Zone separately.
Running Duplicate Title Analysis
To run the Duplicate Title Analysis job:
- Open the Duplicate Title Analysis page (Resources > Advanced Tools > Duplicate Title Analysis).
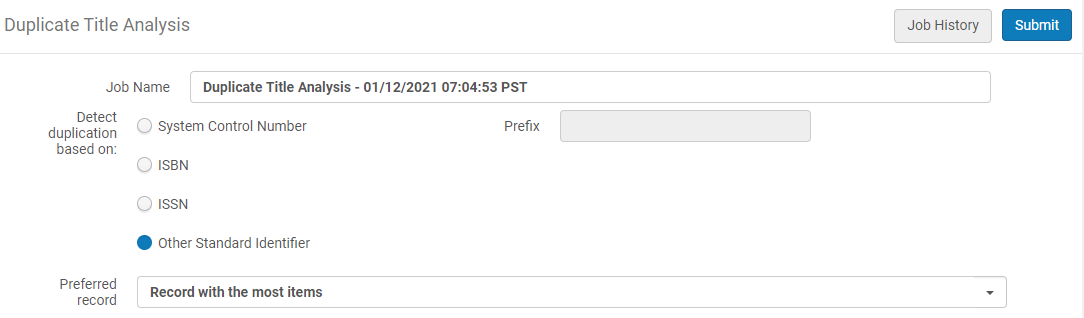
- In the "Detect duplication based on" parameter, select one of the following options for matching duplicate bibliographic records:
- System Control Number / Prefix: The System Control Number parameter uses the MARC 21 035 field for determining a match. In addition, a prefix such as (OCoLC) contained in the 035 field can be specified to narrow the criteria used for matching on the 035 field. The Prefix field is optional.
- ISBN
- ISSN
- Other Standard Identifier: The Other Standard Identifier parameter uses the MARC 21 024 field for determining a match
- In the "Preferred record" parameter, select which record will be treated by the system as the preferred record (the record into which the other records are merged):
- Do not calculate – the report does not include the preferred record.
- Record with the most inventory – the preferred record is the one with the highest number of items/portfolios/collections/digital representation in the group. If there are multiple records with the same highest number of entities, the record with the highest brief level is taken as preferred (out of the ones with the most entities).
The Network Zone does not hold physical inventory. It is better to use different criteria for selecting the preferred record. - Record with highest brief level – the preferred record is the one with the highest brief level (10 is higher than 1). If there are multiple records with the same highest brief level, the record with the most entities is taken as the preferred.
- If preferred record cannot be determined (there are multiple records with the same "preferred" characteristics) – the record with the lowest MMS ID is taken as the preferred.
- Select Submit. The Running tab opens on the Monitor Jobs page showing the job status of Running (or Pending, depending on the activity in the jobs queue).
- Select the History tab to view the job results when the job has completed running.
- For the Duplicate Title Analysis job that you ran, select Report from the list of row actions to open the Job Report page.
- In the Counters section, select the link to download/open the Duplicate Titles Report in Excel .csv format.
Duplicate Title Analysis Report
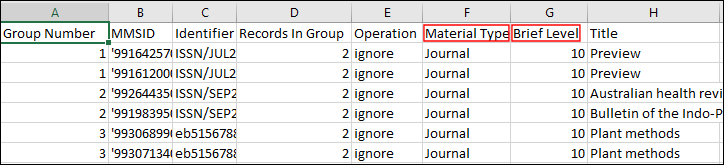
Duplicate Title Analysis Report in Excel .csv Format
The report displays duplicate records in groups, and provides the following information:
- Group Number – Matching bibliographic records are identified by the same group number in the Group Number column.
- MMS ID
- Identifier – The value upon which the system found a match from the field that was selected for Detect duplication based on in your Duplicate Title Analysis job.
- Records in Group – The total number of records in the same group.
- Operation - Indicates which is the preferred record, as calculated by the system:
- Preferred – for the preferred record
- Merge – for the non-preferred records. Non preferred records in the group are merged into the preferred record according to the selected merge routine. The inventory associated with the non-preferred records is combined with the inventory of the preferred record.
- Ignore – for record in a group that has records that do not belong to the institution. For example, if the process is activated in a Network Zone member and a group contains records from the NZ, the group is not handled.
- Not Merged - When it is not possible to merge one of the records in a group, the whole group is not handled and reported as "Not Merged".
- Material Type
- Brief Level
- Title
- Resource Type – This column displays the resource type information as described in The Resource Type Field section.
- Held By – A semicolon-delimited list of the member institutions that have inventory for the record. This only appears in reports when the Duplicate Title Analysis job is run in the Network Zone.
- If the Duplicate Title Analysis job is run before the Build Record Relations job (a system job), deleted records are included in this report as well.
- If the Duplicate Title Analysis job is run after the Build Record Relations job, deleted records are not included in this report.