
正規化ルールの操作
- 目録管理者
- 目録マネージャー
- 目録編集者
- 正規化ルールを個々のレコードに適用するには、[レコードの強化]オプション([MDエディタメニューとツールバーオプション]セクションを参照)を使用するか、 正規化ルールをプレビューするときに個々のレコードに変更を適用します( ルールの結果をプレビューを参照)。
- 正規化ルールを一連のレコードに適用するには、rcDroolNormalization、MarcXSLNormalizationまたはDcDroolNormalizationタスクを使用してプロセスを作成し(「正規化プロセスの操作」を参照)、MDエディタで作成する正規化ルールを指定する必要があります(手順「新しい正規化ルールファイルを作成する」を参照)。プロセスを作成したら、そのプロセスを使用してジョブを実行できます(定義済みセットでの手動ジョブの実行を参照)。また、MDエディタで保存をクリックした際に、 正規化ルールの適用を可能にするプロセスを作成することもできます(「正規化プロセスの操作」を参照)。
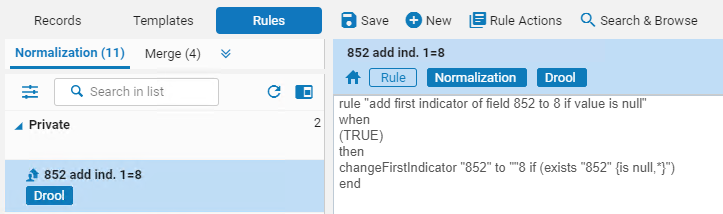
- 正規化ルールとメタデータレコードを並べて表示
- メタデータレコードで実行した場合のルールの結果のプレビュー
- ルールとプレビューの変更を切り替え
- ルールを編集してすぐにテストする
正規化ルールの作成
- MDエディタページ([リソース > 目録 > メタデータエディタを開く])で、[ルール]領域を開きます。
- MARC または Dublin Core レコードの場合、[新規] > [正規化] を選択して正規化ルールを作成します。 [正規化ルールのプロパティ (新しいルール)] というタイトルのダイアログ ボックスが表示されます。
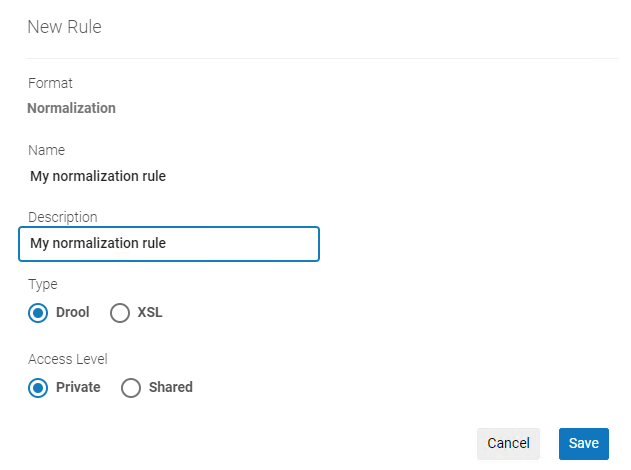 正規化ルールのプロパティダイアログボックス
正規化ルールのプロパティダイアログボックス - 正規化ルールファイルの[名前] と[説明]を入力します。 ルール名に「ルール」という単語を使用する場合は、大文字にしないでください。大文字にするとルールは機能しません。
ルール名にバックスラッシュ (\\) を使用しないでください!そうすると、 このルールは フィルター セット機能には使用できません。 - MARC レコードの正規化ルールを作成するには、[Drool]を選択します。DC(Dublin Core)レコードの 正規化ルールを作成するには、[XSL]を選択します。
- アクセスオプションを、[プライベート]または[共有]から選択します。[プライベート]を選択した場合、自分だけがルールを操作でき、ルールを正規化プロセスに含めることはできません。[共有]を選択すると、ルールは目録者間で共有されます。この場合、複数のユーザーが同時にルールを表示できます。 2人以上のユーザーが編集のためにルールを開いている場合、変更を保存しようとすると警告メッセージが表示されます。(変更を保存するか、他のユーザーが変更を行って保存できるようにするかを選択できます。)
- [保存]を選択します。 MD エディタの編集ペインが表示されます。
既存のルール構文を含めるか([編集] > [ルールの追加] > {type of rule})、ルールを定義できます(詳細については、「正規化ルールの構文」を参照)。 - 保存を選択します。ルールは、[正規化ルール]タブのルールファイルのリストに追加されます。
- [リソース] > [目録] > [メタデータ エディタを開く] メニューから [ルール] タブを選択して、MD エディタ ページの [正規化] フォルダ を展開します。
- コピーするには、コミュニティフォルダを開きます。コピーしたいルールを右クリックして重複を選択します。
重複ルールダイアログが開きます。名前と説明を指定し、プライベート(自分だけが利用可能)として、または共有ルール(組織内のすべてのユーザーが利用可能)として保存するかどうかを指定します。
ルールを CZに投稿したAlmaユーザーの名前と連絡先メールアドレスがダイアログに表示されます。質問がある場合は、このユーザーに連絡できます。 - 自分でCZに投稿するには、ルールを右クリックして[CZに投稿する]を選択します。
ルールの共有ダイアログが開きます。記述名 と説明を入力し、保存を選択してCZにルールを保存します 。
- [MD エディタ] ページ ([リソース] > [目録] > [メタデータ エディターを開く]) で[ルール] タブを選択し、 [正規化] フォルダーを展開して、保存されているルールを表示します。
- 使用するルールを選択し、次のオプションのいずれかから選択します。
- [編集] - ルール構文が含まれるテキストボックスを開き、この構文を変更できるようにします(詳細については、正規化ルールの構文を参照してください)。
- [削除] - はいを選択して、ルールファイルの削除を確認します。
- [重複] - 選択したルールファイルを複製し、元のファイルに影響を与えずに新しいルールとして変更して保存できるようにします。
- [プロパティ] - 正規化ルールのプロパティダイアログボックスを開き、ルールファイルのプロパティを変更できます。
- ルールの名前を変更するには、 ルールを複製し、その重複に目的の名前を付けてから、古いルールを削除します。
- 作業したい書誌レコードを見つけ([リポジトリ検索]を使用するか、MDエディタの[レコード]タブ内にて)、MDエディタで開きます。
- (F6) を押して、スプリット エディタ アイコンを選択します。
- 左側のペインで [ルール] タブを選択し、 [正規化ルール]フォルダーを展開します。
- プレビューまたはテストするルールを( [コミュニティ]フォルダーではなく) [プライベート] フォルダまたは [共有] フォルダで右選択し、[編集]を選択します。
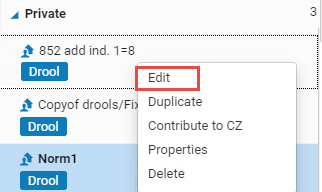
ルールはMDエディタの右ペインに表示されます。
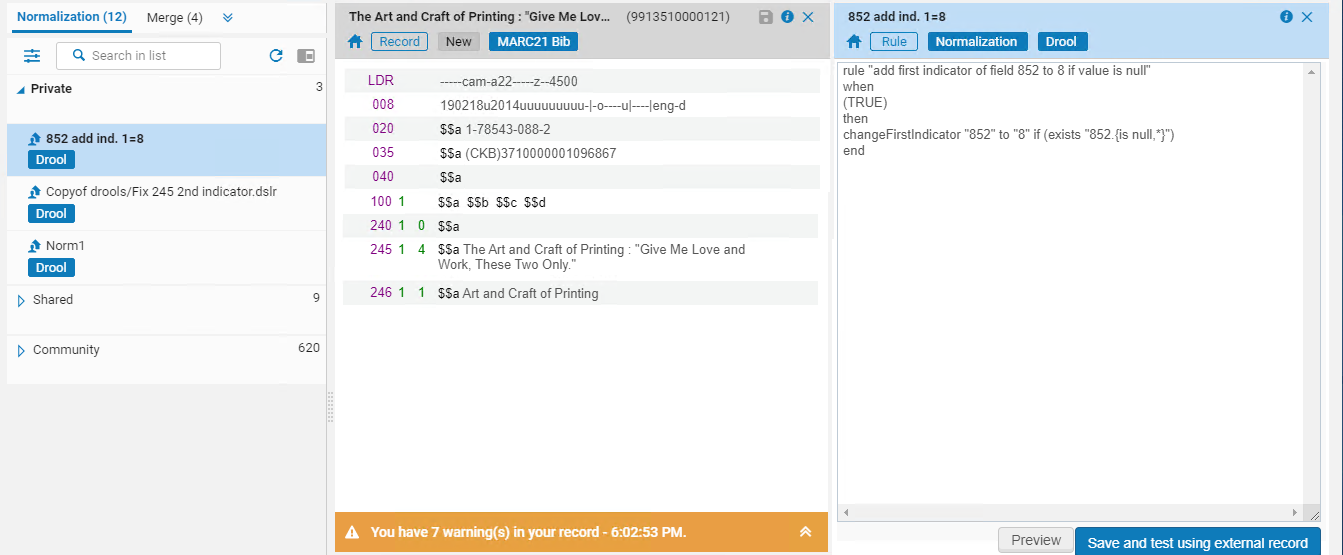
- [プレビュー]を選択します。ルール がレコードに適用され、結果が表示されます。
ネットワーク レコードを更新するには、正規化は(メンバーではなく)ネットワーク機関によって実行される必要があります。機関はネットワーク レコードを更新できないため、正規化は ローカルフィールド(メンバーのローカル拡張)にのみ適用されます。ネットワークレコードのルールをプレビューすると、次のメッセージが表示されます: 正規化プロセスの実行時に、ルールはローカルフィールドにのみ適用されることに注意してください。
- [変更の適用]を選択して変更をレコードに保存するか、さらに編集を行いたい場合は[正規化ルールに戻る] を選択します。
- 正規化ルールに最終的な変更を加えたら、[保存して外部レコードを使用してテストする] を選択し、正規化ルールの最終バージョンを保存します。詳細については、 外部データソースの正規化ルールのテストを参照してください。
Dublin CoreとMODSレコードの正規化ルール
メタデータエディタには、Dublin CoreとMODSに関連する次のタイプのルールがあります。
- XSL表示ルール
- XSL 正規化ルール
XSL 正規化 ルールはDiscovery:localに対応していません。
Dublin Core正規化ルールは、通常の正規化ルール形式での記述はできず、 XSL形式でのみの記述が可能です。つまり、 メタデータエディタで直接XSLを作成するか(上記で説明)、 メモ帳 (または任意の外部アプリケーション)で作成し 、それをメタデータエディターにコピーすることができます。
メタデータエディタのコミュニティゾーンでは、 Dublin CoreのXSL正規化ルールの以下の例を表示できます。
- EXL – dc:language値「en」を「English」に変更
- EXL – Dublin Coreレコードの文字列を置き換える一般的なルール
- EXL_Add_field_accessRights
- 選択した外部アプリケーションでXSLを記述します。
- [メタデータ エディタ] > [ルール] セクションを開きます。
- メタデータエディター でXSLをコピーして貼り付け、ルールを保存します。
Primo VEの正規化ルールプロセス構成
Almaの正規化ルールに加えて、Primo VEの正規化ルールと Esploroの正規化ルールを作成できます。これらのルールを作成するには、 [新規]から 、次の項目を選択してください。
-
正規化 (検出) – このオプションは、 Primo VEがシステムで定義されている場合にのみ表示されます。Primo VEに ロードされ、 Almaで管理されていない 書誌レコードのDCまたはXML正規化ルールを作成する場合は、このオプションを選択します。 これらのルールの構文については、「DCおよびXML形式の正規化ルールの構文」を参照してください。
-
正規化(リサーチ) – このオプションは、 Esploroがシステムで定義されている場合にのみ表示されます。詳細については、 「アセット正規化ルールの管理」 (Esploro)を参照してください。
正規化ルールの構文
(<conditions on MARC record>) then
Action
End
- “When” が最初の行の唯一の単語である必要があります。条件は別の行に配置する必要があります。
- “When”という条件のみで、レコード全体に複数の条件を使うことができます。 すべて のルールには 1 つのアクションのみが必要です (“Then”ラインの後)。後に複数のアクションを使用したい場合 は“Then”ライン、これをいくつかのルールに分割し、それぞれが単一のアクションを持ちます。
- ルールに複数のブール演算子を含めることはできますが、多数のブール演算子を選択すると、パフォーマンスが低下する可能性があります。したがって、ブール演算子は各ルールあたり200個以下に収める必要があります。
- 指定しない場合、条件はレコードレベルで機能します。各MARC21フィールドに個別に条件を適用したい場合は、フィールドごとに条件を指定する必要があります。たとえば、同じタグを持つMARC21フィールドが複数ある場合などです。
- \b
- \t
- \n
- \f
- \r
- \"
- \'
- \\
- \\\を \\ に置換
- \.を . に置換
- \を ¥¥ に置換
- ¥(を ( に置換
- \)を ) に置換
- \\\|を \\| に置換
レコード要素
| 表現 | 意味 |
|---|---|
| "<tag>"、"<new tag>" | 001、245などのフィールドタグを表しています。 |
| "<oldCode>", "<newCode>" | a、b、cなどのサブフィールドコードを表しています。 |
| "<element>" データフィールドの場合 | データフィールドに指定できる値は次のとおりです
|
| "<element>" (コントロールフィールド) | 以下は、コントロールフィールドに使用できる値です
|
| "<element>"固定位置フィールドの場合 | 以下は、固定位置に使用できる値です UNIMARC/CNMARC 1XXフィールド:
UNIMARC/CNMARC 1XXフィールドにのみ関連します。 |
| CONDITION(レコードレベル) | 可能な条件オプションは次のとおりです。重要な情報については、次のセクション(条件)を参照してください。
以下は、UNIMARC/CNMARC 1XXフィールドにのみ関連する条件オプションです。
|
条件
- WHEN句 – ルールがレコードに適用されるかどうかを判断するために、レコード全体で満たされる必要がある条件です
- IF(アクション内) – 特定のアクションがそのフィールドで実行されるかどうかを判断するためにフィールド単体に適用される条件です
- containsScript – この条件を使用して、特定の言語を検出します。 containsScript 条件では、次のチェック可能な言語の固定リストが使用されます。アラビア語、アルメニア語、ベンガル語、注音符号、点字、ブヒッド文字、カナダ先住民文字、チェロキー語、キリル文字、デーバナーガリー語、エチオピア語、グルジア語、ギリシャ語、グジャラート語、グルムキー語、ハン語、ハングル語、 ハヌヌー、ヘブライ語、ひらがな、インヘリタンス、カンナダ語、 カタカナ、 クメール語、 ラオス語、 ラテン語、 リンブ語、マラヤーラム語、モンゴル語、ミャンマー語、オガム文字、オリヤー語、ルーン語、シンハラ語、シリア語、タガログ語、タグバンワ語、テール、 タミル語、 テルグ語、 ターナ語、 タイ語、 チベット語、イー語。次の構文例を参照してくださいルール「典拠にCJK」
when
containsScript "Han" "1**"
then
set indication."true"
end - exists <element> – 少なくとも1つの一致が見つかりました
- exists <element> – データフィールドに適用されます。IF句で使用する場合、アクション要素と条件によってテストされる要素の両方が同じ(データ)フィールドでなければなりません。
- existsControl <element> - コントロールフィールドに適用されます。IF句で使用する場合、アクション要素と条件によってテストされる要素の両方が同じ(コントロール)フィールドでなければなりません。
- existsMoreThanOnce <element> – 複数の一致が見つかりました。データフィールドに適用されます。IF句で使用する場合、アクション要素と条件によってテストされる要素の両方が同じ(データ)フィールドでなければなりません。
- not exists <element> – 一致するものは見つかりませんでした
- not exists <element> – データフィールドに適用されます。IF句で使用する場合、アクション要素と条件によってテストされる要素の両方が同じ(データ)フィールドでなければなりません。
- not existsControl <element> – コントロールフィールドに適用されます。IF句で使用する場合、アクション要素と条件によってテストされる要素の両方が同じ(コントロール)フィールドでなければなりません。
- recordHasDuplicateSubfields(表示ルールの場合、表示ルールの操作を参照) – フィールド、サブフィールド、および無視する文字 (charsToIgnore)として渡された文字列に従って、現在のレコードで重複するサブフィールド(サブフィールドとその内容)が見つかった場合、 次の形式のパラメーターでtrueを返しますrecordHasDuplicateSubfields "<tag>" "<code>" "<charsToIgnore>"コンマで区切られた複数のタグ(フィールド)を指定することができます。複数のコード(サブフィールド)をスペースなしで指定して、それらを区切ることができます。 空白を含まない1つ以上の文字(英数字または句読点)を、重複の評価対象のサブフィールドのコンテンツの最後で無視する文字として指定できます。詳細については、例6を 参照してください。recordHasDuplicateSubfields 条件を満たすレコード(trueを返す)の場合、 レコードのセットが作成されます。
- 特定の条件がtrueでない場合に適用されます。例:addControlField "{element}" if(not exists "{condition}")
- 特定の条件がtrueの場合に適用されます。例:addControlField "{element}" if(exists "{condition}")
- 無条件に適用されます。例:addControlField "{element}"
アクションリスト
| アクション | フォーマット/例 | コメント |
|---|---|---|
| フィールドとサブフィールドを他のフィールドとサブフィールドに置換 | changeControlField "<tag>" to "<new tag>" 例: changeControlField "007" to "008" | コントロールフィールドのタグ識別子を変更します。内容を変更しません。 |
| changeField "<tag>" to "<new tag>" 例: changeField "245" to "246" | タグ識別子を変更します。この時、インジケータまたはサブフィールドは変更しません。 | |
| changeSubField "<tag>.<code>" to "<new code>" changeSubFieldOnlyFirst "<tag>.<code>" to "<new code>" changeSubFieldExceptFirst "<tag>.<code>" to "<new code>" 例: changeSubField "035.b" to "a" | サブフィールド(最初のサブフィールドのみ、もしくは最初のサブフィールド以外のすべて)の"<code>"を、フィールド"<tag>"のサブフィールド"<new code>"に変更します。 | |
| changeFirstIndicator "<tag>" to "<value>" changeSecondIndicator "<tag>" to "<value>" 例: changeFirstIndicator "245" to "3" | タグ<tag>の指定されたインジケーターの値を設定します。 | |
| combineFields "<tag>" excluding "<comma-separated subfield list>" 例: combineFields "852" excluding "a,b" | 指定した番号のすべてのフィールドを統合します。名前付きサブフィールドを除く、2行目以降のすべてのサブフィールドを最初の行にコピーします。除外されたサブフィールドの最初の出現のみがコピーされ、それらが最初の行にまだ存在しない場合のみ適用できます。 | |
| フィールドとサブフィールドの追加 | addField "<tag>.<code>.<value>" addField "<tag>.{<ind1>,<ind2>}.<code>.<value>" 例: addField "999.a.RESTRICTED" | MARCレコードにフィールドを追加します。サブフィールドの値を指定された値に設定します。 |
| addControlField "<tag>.<value>" 例: addControlField "008.820305s1991####nyu###########001#0#eng##" | MARCレコードにコントロールフィールドを追加します。 | |
| addSubField "<tag>.<code>.<value>" addSubField "<tag>.{<ind1>,<ind2>}.<code>.<value>" 例: addSubField "245.h.[Journal]" | 値<value>を持つサブフィールド<code>をフィールド<tag>に追加します。フィールドが存在しない場合、何も行われません。 | |
| addSystemNumber "<element>" from "<tag>" prefixed by "<prefix tag>" 例: addSystemNumber "035.a" from "001" prefixed by "003" | データフィールド<element>を、括弧内の2番目のコントロールフィールド<prefix tag>の内容と等しくし、その後に最初のコントロールフィールド<tag>の内容を続けます。 たとえば、001の値が9945110100121で、003の値がDAVである場合、左側の例の条件は値が‡(DAV)9945110100121の035を生成します。 | |
| フィールドをコピー | copyField "<tag>" to "<new tag>" copyField "<tag>.<code>" to "<new tag>.<new code>" copyField "<tag>" to "<new tag>.{<ind1>,<ind2>}" 例: copyField "971.a" to "100.u" | フィールドを別のフィールドにコピーします。最初のバージョンでは、サブフィールドは指定されておらず(<code>および<new code>)、新しいフィールドには古いフィールドと同じサブフィールドが含まれています。2番目のバージョンでは、<new code>が指定されていない場合、新しいサブフィールドは<code>で指定されたサブフィールドと同じです。 copyFieldは、既存のフィールドに追加するのではなく、個別のフィールドを作成します。新しいフィールドを既存のフィールドと組み合わせることもできます(combinedFieldsを参照)。 |
| フィールドとサブフィールドを削除 | removeControlField "<tag>" 例: removeControlField "009" | コントロールフィールドのすべての出現を削除します。 コントロールフィールド008を削除し再作成しない場合、Almaはすぐに再作成することに注意してください。フィールドを削除した後に再度追加することを検討してください。例: ルール「008を削除」 when (TRUE) then removeControlField "008" addControlField "008.######s2013####xx######r#####000#0#eng#d" end |
| removeField "<tag>" 例: removeField "880" | フィールドのすべての出現を削除します<tag>. | |
| removeSubField "<tag>.<code>" 例: removeSubField "245.h" | 指定されたフィールドからサブフィールド<code>のすべての出現を削除します。 | |
| フィールドまたはサブフィールドのテキストを置換 | replaceControlContents "<tag>.{<position>,<length>}. <value>" with "<new value>" 例: replaceControlContents "LDR.{7,1}.s" with "m" | 開始位置<position>の<value> with "<new value>"をコントロールフィールド<tag>の<position>+<length>に置き換えます。<value>に一致するテキストのみを置き換えます。 |
| replaceContents "<tag>.<code>.<value>" with "<new value>" replaceContentsOnlyFirst "<tag>.<code>.<value>" with "<new value>" replaceContentsExceptFirst "<tag>.<code>.<value>" with "<new value>" 例: replaceContents"245.h.[Journal]" with "[Book]" | フィールド"<tag>"のサブフィールド<code>内の<value>と一致する文字列(もしくは最初が一致するサブフィールドの一致する文字列の全インスタンス、または最初が一致するサブフィールドを除いた、全一致するサブフィールドの全一致する文字列)を"<new value>"に置き換えます。<value>と一致しない文字列または文字列の一部は変更されません。 | |
| replaceSubFieldContents "<tag>.<code>" with "<tag>.<code>" 例:replaceSubFieldContents "245.b" with "100.a" | サブフィールドの内容を別のサブフィールドの内容に置き換えます。 | |
| replaceFixedContents "<tag>.{<1_ind>,<2_ind>}.<code>.{<position>,<length>}.<value>" with "<new value>" 例: replaceFixedContents "100.{1,2}.a.{0,8}.20150226" with "20220724" | UNIMARCおよびCNMARC 1XX固定位置フィールドの <value> with <new value> を置き換えます。 UNIMARC/CNMARC 1XXフィールドにのみ関連します。 | |
| サブフィールドにテキストを追加する | prefix "<tag>.<code>" with "<value>" 例: prefix "035.b" with "(OCoLC)" | フィールド "<tag>"のサブフィールド "<code>" の値に接頭語を追加します。 新しい値<value>の後に、古い値が続きます。 |
| prefixSubField "<tag>.<code>" with "<source tag>.<source code>" 例: prefixSubField "910.a" with "906.a" | フィールド"<source tag>"のサブフィールド"<source code>"の値を、サブフィールド"<code>"の接頭語としてフィールド"<tag>"に追加します。 新しい値は、フィールド"<source tag>"のサブフィールド"<source code>"の値と続き、その後に古い値が続きます。 | |
| suffix "<tag>.<code>" with "<value>" 例: suffix "035.b" with "(OCoLC)" | フィールド"<tag>"のサブフィールド"<code>" の値に接尾語を追加します。 新しい値<value>の後に、古い値が続きます。 | |
| suffixSubField "<tag>.<code>" with "<source tag>.<source code>" 例: suffixSubField "910.a" with "907.c" | フィールド"<source tag>"のサブフィールド"<source code>"の値を、フィールド "<tag>"のサブフィールド "<code>"の接尾語として追加します。 新しい値は、フィールド"<source tag>"のサブフィールド"<source code>"の値と続き、その後に古い値が続きます。 | |
| 書誌および典拠レコードにおける機関情報の維持 たとえば、この構文は、保存時にネットワークゾーンの書誌レコードを正規化するために、[MARC 21書誌メタデータ設定タスクリスト]で選択される正規化ルールで使用できます。 この機能は現在作業中です。この構文を有効にするには、Ex Librisサポートにお問い合わせください。 | addCreatingAgency "<tag>.<code>" 例: addCreatingAgency "040.a" | 作成機関のISILコードを、フィールド"<tag>"のサブフィールド"<code>"に追加します。 |
| addModifyingAgency "<tag>.<code>" 例: addModifyingAgency "040.d" | フィールド "<tag>"のサブフィールド"<code>"に変更する機関ISILコードを追加します。"<tag>.<code>"に既に変更する機関がある場合、これによって別の機関ISILコードが追加されます。 | |
| replaceModifyingAgency "<tag>.<code>" 例:replaceModifyingAgency "040.d" | フィールド "<tag>"のサブフィールド"<code>"に変更する機関ISILコードを追加します。"<tag>.<code>"に変更する機関が既に存在する場合、すべて置き換えられます。 | |
| サブフィールドの分割 | splitSubField "<tag>.{ind1,ind2}.<code>.<delimiter>" to "<tag>.{<ind1>,<ind2>}.<code>" addSeq "<code>" 例1: splitSubField "866.a.;" to "555.{0,0}.a" addSeq "8" 例2: splitSubField "555.a.– " to "859.{0,0}.a" addSeq "8" 例3:splitSubField "859.a.\\\\." 例4: splitSubField "999.a.;" to "555.a" addSeq "8" | このタグは必須です。 インジケータは任意です。 分割はサブフィールドレベルで行われるため、コードは必須です。 区切り文字には任意の文字列を使用することができます。区切り文字が存在しない場合、完全なサブフィールドが最初の(そして唯一の)発生セグメントとしてコピーされ、シーケンスが追加されます。 toコンポーネントは任意です。指定されている場合、to tag.codeが複数発生し、それぞれに区切り文字までのデータが含まれます。例1および例2を参照してください。toコンポーネントが指定されていない場合、サブフィールドは例3に示されるように、同じフィールド内の同じ内容の追加のサブフィールドとして分割されます。 addSeqコンポーネントは任意です。toコンポーネントが指定されていない場合は関係ありません。addSeqを指定すると、例1のように、シーケンスを持つサブフィールドが追加されます。また、サブフィールドが元のフィールドに既に存在する場合、例2のように、シーケンス(ピリオドが前に付く)がそのフィールドに追加されます。 |
| correctDuplicateSubfields "<tag>" "<code>" 例: フィールド610および630から重複するサブフィールドx、y、およびzを削除します。 | パラメーターとして渡されたフィールドとサブフィールドに従って、最初の出現を保持し、現在のレコード から 他のサブフィールドを削除することにより、重複したサブフィールド(同じコードおよび同じ値のサブフィールドなど)を修正します。 recordHasDuplicateSubfieldsを使用して、correctDuplicateSubfieldsを使用する正規化ルールに提供するセットを作成できます。 詳細は、例6を 参照してください。 異なる値を持つサブフィールドの重複排除については、以下を参照してください。 | |
| moveSubfieldsToEndOfField "<tag>" "<code>" 例: サブフィールド9および2をフィールド650の末尾に移動します。 | 各サブフィールドの最初の出現をフィールドの末尾に移動させ、他に出現する同じサブフィールドをすべて削除します。 複数のサブフィールドが指定されている場合、ルールで識別されているのと同じ順序で最後に配置されます。この例では、サブフィールド9が末尾に配置され、その後にサブフィールド2が続いています。 ifステートメントはmoveSubfieldsToEndOfField アクションではサポートされていないことに注意してください。 | |
| 現在のレコードの重複するフィールドを修正する | correctDuplicateFields "{fields}" 例: correctDuplicateFields "610,630,650" | このアクションが取り入れるパラメーターは、610,630,650などのコンマ区切りのフィールド値を含むフィールドのみです。 このアクションは、パラメーターとして渡されたフィールドに従って、現在のレコードの重複したフィールドを修正します。 このアクションは、同じフィールドの複数のインスタンス間で見つかった重複データを識別して修正するためにのみ使用できます。 |
| 重複したフィールドを見つける (表示ルールについては表示ルールの操作を参照) | recordHasDuplicateFields "{fields}" 例: recordHasDuplicateFields "610,630,650" | このアクションが取り入れるパラメーターは、610,630,650などのコンマ区切りのフィールド値を含むフィールドのみです。 このアクションの結果は、trueまたはfalseのいずれかです。パラメーターとして渡されたフィールドに従って、現在のレコードに重複したフィールドが見つかった場合、trueを返します。 このアクションは、同じフィールドの複数のインスタンス間で見つかった重複データを識別して修正するためにのみ使用できます。 |
ワイルドカードと特殊文字
when
(TRUE)
then
replaceContents "300.a.1 v\\\\." with "Leaves"
end
when
(exists '245.{*, }.c.\"')
then
replaceControlContents "008.{7,4}" with "2016"
end
when
((exists '260.{*, }.c.תשע\\"ו') OR (exists '264.{*, }.c.תשע\\"ו'))
then
replaceControlContents "008.{7,4}" with "2016"
end
- ワイルドカードは、条件または値の最初の文字として使用することはできません。
- リテラルバックスラッシュ(\)使用するには、別のバックスラッシュ\\ でエスケープします。
- ピリオドが文字列の最後の文字である場合、4つのバックスラッシュ (\\\\)を使用してエスケープします。ピリオドの直後に別の文字が続く場合、4つのバックスラッシュは必要ありません(次の例のようにaddField "907.a.F.L.T\\\\.")。ただし、一貫性のある望ましい結果を確保するには、正規化ルールで常に4つのバックスラッシュを使用することをお勧めします。次の例を参照してください。
- 上記のように、二重引用符が単一引用符を使用してエスケープする条件(でのみ)使用される場合や、単一引用符を使用してエスケープする条件で単一引用符を使用する場合、二重引用符または引用符をダブルバックスラッシュでさらにエスケープする必要があります。
- パイプ記号が条件の一部である場合は、4つのバックスラッシュを使用してエスケープします。例: removeField "866" if (exists "866.8.0\\\\|99")。これは、条件でパイプ記号を使用する場合にのみ必要です。
例:replaceContentsを使用した正規化ルールでのピリオドの使用
when
(TRUE)
then
replaceContents "245.a.\\\\." with ""
replaceContents "246.a.\\\\." with ""
end
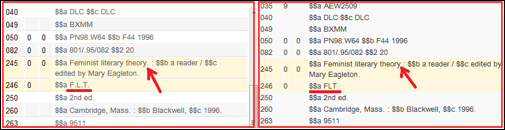
例:addFieldを使用した正規化ルールでのピリオドの使用
salience 100
when
TRUE
then
addField "906.a.Architecture\\\\."
addField "907.a.F\\\\.L\\\\.T\\\\."
end
