目録の設定
- 目録管理者 この役職は、拡張パックを使用してMARCベースのプロファイルを編集するために必要です。コミュニティゾーンレベルで 拡張パックファイルを追加、削除、および提供するには、この 役職 に割り当てられた特別な権限が必要となります。拡張パックファイルを操作できない場合は、カスタマーサポートに連絡してこれらの権限を割り当ててください。)
- 統括システム管理者
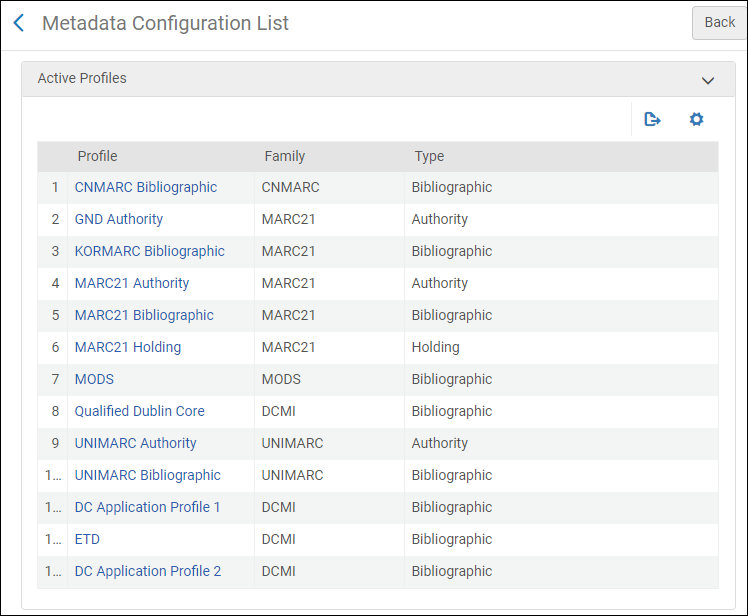
このセクションでは、メタデータ環境の設定について説明します。[メタデータ設定リスト]ページのアクティブプロファイルセクションで設定されたプロファイルは、MDエディタで作業するときに使用する目録環境を定義します。[メタデータ設定リスト]ページで設定できる書誌プロファイルは、Ex Librisによって機関に設定されたアクティブレジストリ/レジストリセットによって決定されます。以下のアクティブレジストリをAlma用に設定できます。
- MARC 21
- UNIMARC
- KORMARC
- CNMARC
- Dublin Core
- MODS
- ETD
- DC Application Profiles
- メタデータエディタに表示されるメタデータフィールドとサブフィールド、およびそれらが繰り返し可能な場合
- サブフィールドが語彙制御を使用している場合
- 正規化プロセス
- 検証プロセス
メタデータプロファイルの詳細の表示
- [一般情報](DCアプリケーションプロファイルのみ)
- [フィールド]
- [フォーム]
- [正規化プロセス]
- [検証プロセス]
- [検証例外プロファイルリスト]
- [その他の設定]
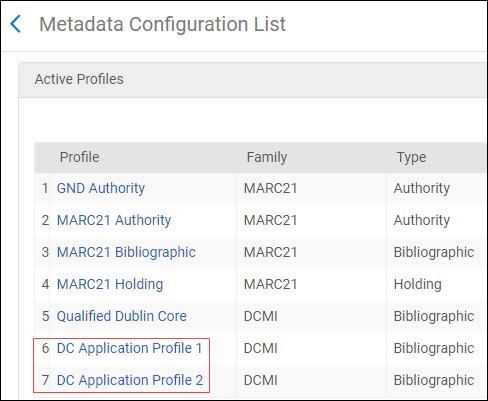
- [メタデータ設定リスト]ページ([設定メニュー > リソース > 目録 > メタデータ設定])で、表示するプロファイルのリンク(MARC 21書誌など)を選択します。[プロファイルの詳細]ページが表示されます。
 MARC 21書誌プロファイル詳細ページ
MARC 21書誌プロファイル詳細ページ - 表示するプロファイル詳細の行アクションリストで[表示] を選択します。[フィールドの詳細]ページが表示されます。
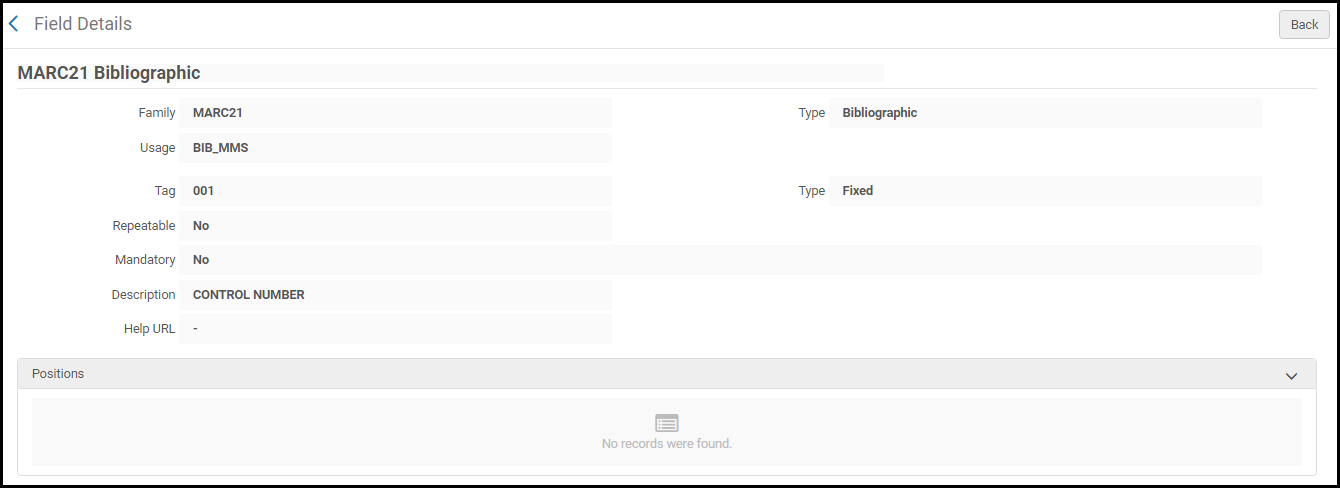 フィールド詳細ページ
フィールド詳細ページ
プロファイルの詳細を編集する
- [一般情報](DCアプリケーションプロファイルのみ) - 詳細については、DCアプリケーションプロファイル - 一般情報タブを参照してください。
- [フィールド] - フィールドの編集を参照してください。
- [フォーム] - フォームの操作を 参照してください。
- [正規化プロセス] - 正規化プロセスの操作を参照してください。
- [検証プロセス] - 検証プロセスの編集を参照してください。
- [検証例外プロファイル]リスト - 検証例外プロファイルの操作を参照してください。
- [その他の設定] - その他の設定を参照してください。
フィールドの編集
- [メタデータ設定リスト]ページ([設定メニュー > リソース > 目録 > メタデータ設定])で、編集するプロファイルのリンク(MARC 21書誌など)を選択します。[プロファイルの詳細]ページが表示されます。
- メタデータ・エディタで目録作成用のフォームが提供されている固定フィールドに対しては、フォームでの編集を強制 を有効にすることで、目録作成時にフォームの使用を必須にできます。この機能がフィールドに対して有効になっている場合、メタデータ・エディタでは自由入力による目録作成はできません。
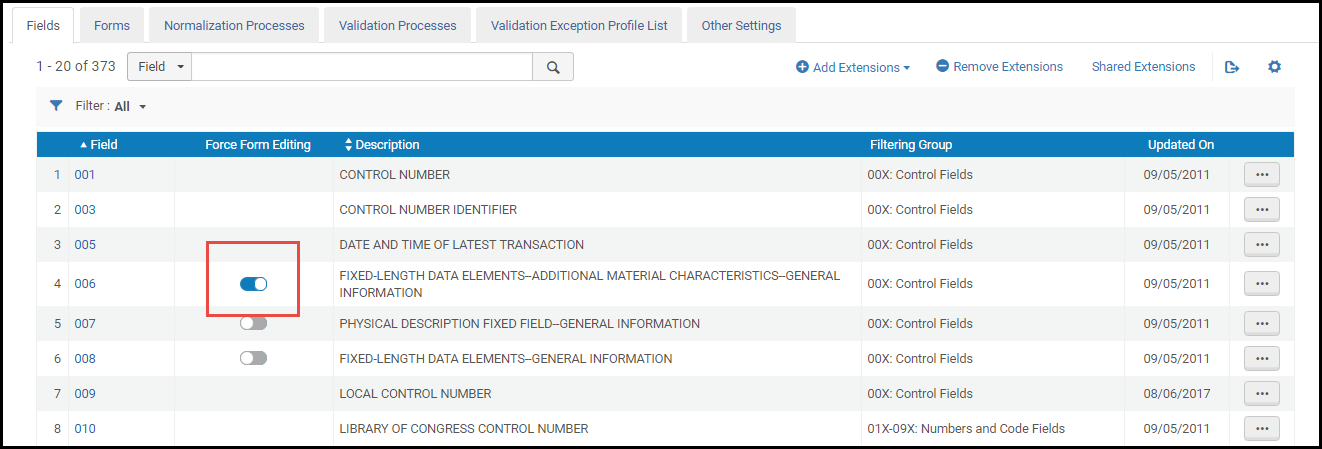 フォーム編集設定スライダーを強制するスライダーの操作については、Almaユーザーインターフェイスをご覧ください。
フォーム編集設定スライダーを強制するスライダーの操作については、Almaユーザーインターフェイスをご覧ください。 - 編集するフィールドの行アクションリストで[カスタマイズ](または[編集])を選択します。[フィールドの詳細]ページが表示されます。
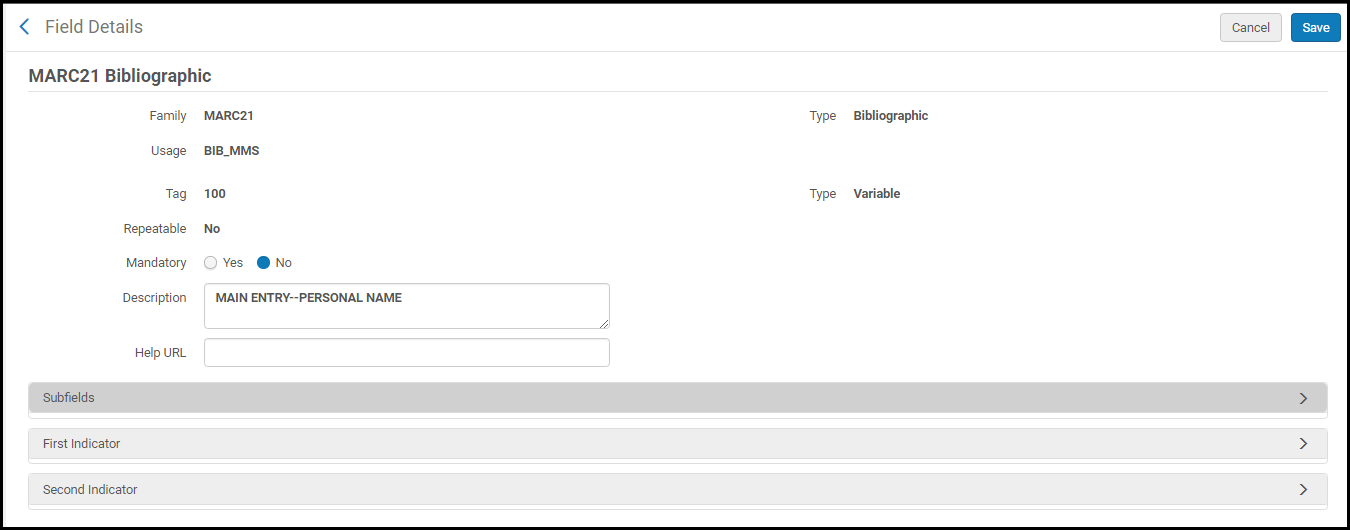 フィールドの詳細ページのカスタマイズ(編集)
フィールドの詳細ページのカスタマイズ(編集) - 要件に合わせて、次のフィールドオプション(異なる場合があります)を編集します。
- [必須] – [はい]または[いいえ]。
- [説明] - 参考用の詳細。
- [ヘルプURL] – ヘルプに使用できるURL。このURLが指すヘルプ情報は、MDエディタの[情報]タブに表示されます。このフィールドを空白のままにすると、デフォルトは米国議会図書館の目録基準情報になります。
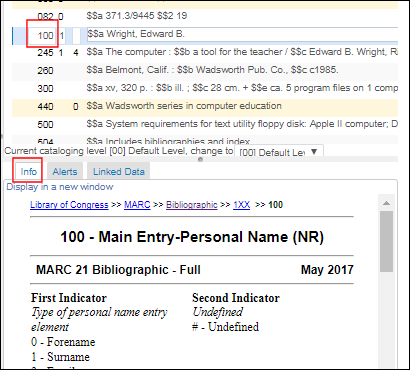 ヘルプURLオプションに関連するMDエディタ情報タブ
ヘルプURLオプションに関連するMDエディタ情報タブ - [サブフィールド] - サブフィールドごとに、[はい]または[いいえ]を選択して、サブフィールドが必須または繰り返し可能であることを示すことができます。
- 特定の語彙制御を割り当てるサブフィールドの行アクションリストで、語彙の制御の割り当てを選択します。[新規制御語彙値の作成]セクションがある[プロファイルの詳細]ページが表示されます。
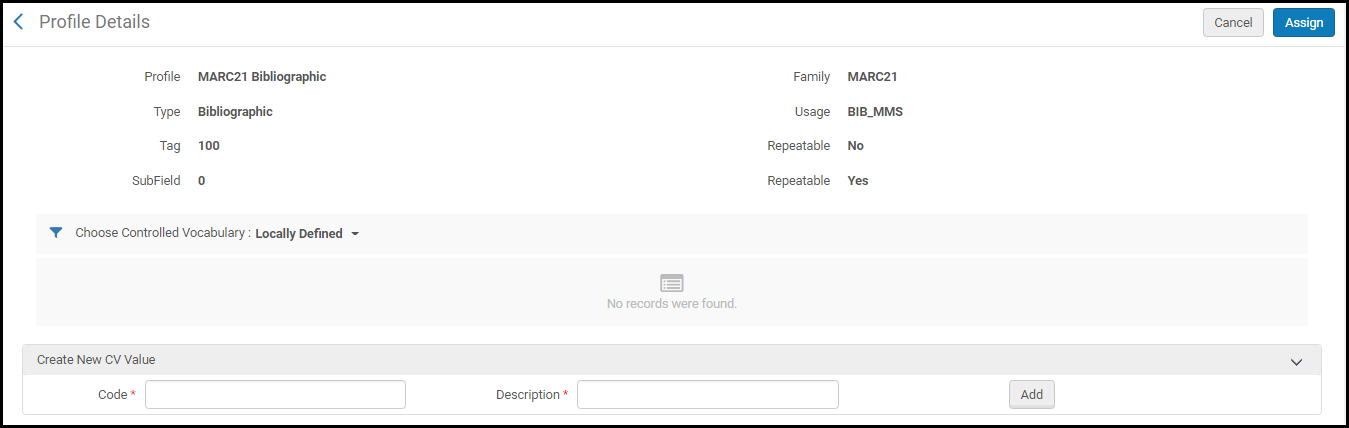
- [語彙制御(CV)の選択]ドロップダウンリストから制御する語彙を選択します。このリストのオプションは、[語彙制御レジストリの設定]で設定されます。選択した語彙制御の詳細が表示されます。この選択を保存するには[割り当て]を選択します。 便宜上、[新規語彙制御値の作成]セクションを使用して、制御する用語を追加できます。ここで追加する用語は、編集中のフィールドにのみ適用されます。これらの用語を別の/異なるフィールドで使用する場合は、[語彙制御レジストリ](語彙制御レジストリの設定を参照)を使用して、複数のフィールドで使用される語彙制御を作成します。新規語彙制御値の作成セクションで新しい語彙制御値を追加するには、コードと説明を入力して[追加]を選択します。 用語の追加が終了したら、[割り当て]を選択します。
- 特定の語彙制御を割り当てるサブフィールドの行アクションリストで、語彙の制御の割り当てを選択します。[新規制御語彙値の作成]セクションがある[プロファイルの詳細]ページが表示されます。
- 第1インジケータ - [フィールドの詳細]ページの最初のインジケータセクションで必要な変更を加えます。
- 第2インジケータ - [フィールドの詳細]ページの最初のインジケータセクションで必要な変更を加えます。
- 保存を選択します。フィールドの変更は、メタデータプロファイルに保存されます。
- [配置]を選択します。
拡張パックを使用したMARCベースのプロファイルの編集
| プロファイル要素 | LDR | コントロールフィールド/固定フィールド | データフィールド |
|---|---|---|---|
| タグ | 事前定義済みのフィールドと、プロファイルに存在するカスタマイズされたフィールドは残ります。 拡張パックの新しいフィールドが追加されます。 | 事前定義済みのフィールドと、プロファイルに存在するカスタマイズされたフィールドは残ります。 拡張パックの新しいフィールドが追加されます。 | |
| サブフィールドコード | 事前定義済みのコードと、プロファイルに存在するカスタマイズされたコードは残ります。 拡張パックの新しいコードが追加されます。 | ||
| ポジション | プロファイルに存在する事前定義済みの位置は削除されます。 プロファイルに存在するカスタムポジションは残ります。 拡張パックから新しい位置が追加されます。 | プロファイルに存在する事前定義済みの位置は削除されます。 プロファイルに存在するカスタムポジションは残ります。 拡張パックから新しい位置が追加されます。 | |
| ポジション値 | プロファイルに存在する事前定義済みの値はそのまま残ります。 プロファイルに存在するカスタム値はすべて、拡張パックの新しい値に置き換えられます。 | プロファイルに存在する事前定義済みの値はそのまま残ります。 プロファイルに存在するカスタム値はすべて、拡張パックの新しい値に置き換えられます。 | |
| インジケータ値 | プロファイルに存在する事前定義済みの値はそのまま残ります。 プロファイルに存在するカスタム値はすべて、拡張パックの新しい値に置き換えられます。 | ||
| サブフィールドの語彙制御 | プロファイルに存在する事前定義済み、およびカスタム値は、拡張パックの新しい値に置き換えられます。 |
拡張パックの管理
- .xml拡張ファイルをローカルで作成します(詳細については、拡張パックの.xmlファイルの例を参照してください)。
- [メタデータ設定リスト]ページ([設定メニュー > リソース > 目録 > メタデータ設定])から、拡張するMARCベースのプロファイルのリンクを選択します。
- [フィールド]タブから、[拡張機能の追加] メニューでオプションを選択します。
- [機関へ] このオプションを使用して、設定するプロファイルに.xml拡張パックファイルを追加します。このオプションを選択すると、コミュニティゾーンまたはローカルファイルの1つからMARCベースのプロファイルに拡張パックの.xmlファイルを追加することを選択できます。
 拡張パックの.xmlファイルをMARCベースのプロファイルに追加するコミュニティゾーンオプションを選択すると、コミュニティゾーンの共有.xmlファイルのリストが表示されます。拡張パックの.xmlファイルをローカルストレージにダウンロードするか、拡張パックの.xmlファイルをプロファイルに直接追加できます。
拡張パックの.xmlファイルをMARCベースのプロファイルに追加するコミュニティゾーンオプションを選択すると、コミュニティゾーンの共有.xmlファイルのリストが表示されます。拡張パックの.xmlファイルをローカルストレージにダウンロードするか、拡張パックの.xmlファイルをプロファイルに直接追加できます。
- [機関へ]
- [コミュニティへ] このオプションを使用して、他の機関と共有するための.xml拡張パックファイルをコミュニティゾーンに追加します。このオプションを選択すると、拡張パックの名前、説明、拡張パックの問い合わせ先、連絡先の電子メールアドレス、および.xml拡張パックファイルの詳細を提供するよう求められます。
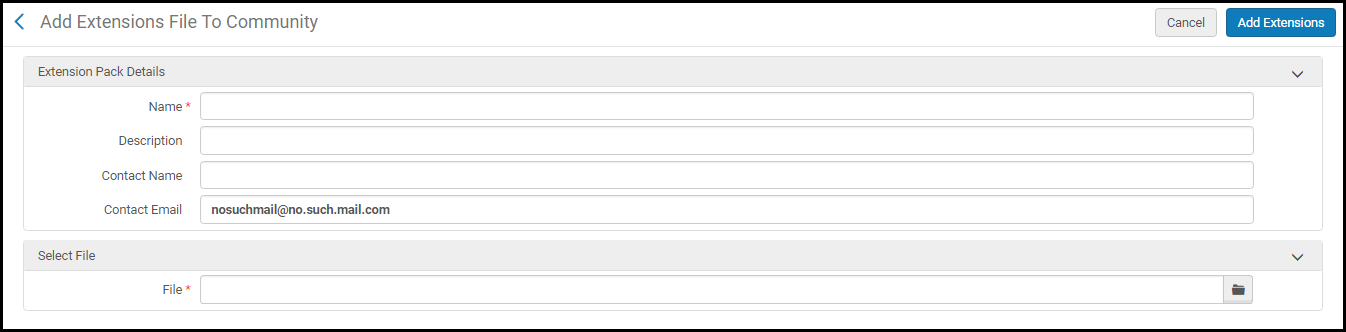 拡張パックをコミュニティゾーンに追加する
拡張パックをコミュニティゾーンに追加する - [拡張機能の追加]を選択します。 コミュニティゾーンに追加された拡張パックの.xmlファイルの場合、追加されたファイルと投稿メッセージが[共有拡張機能]ページに表示されます。
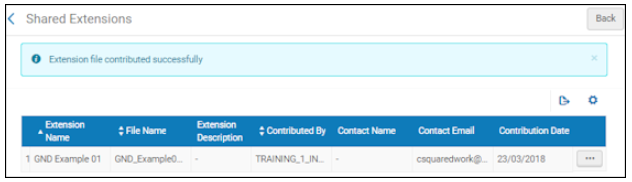 共有拡張機能ページ処理中にシステムが同じ値の複数のオカレンスを検出した場合、最初のオカレンスが適用され、他の冗長なオカレンスは無視されます。
共有拡張機能ページ処理中にシステムが同じ値の複数のオカレンスを検出した場合、最初のオカレンスが適用され、他の冗長なオカレンスは無視されます。 - 変更を確認/確認します。
- [配置]を選択します。
メンバーがIZレベルの拡張パックを持つMARCプロファイルの機関ゾーン レコードを編集する場合、ローカル拡張フィールドをカタログ化する場合のみ (機関アイコン付き
拡張パック.xsd
<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema"
elementFormDefault="qualified" targetNamespace="http://com/exlibris/repository/mdprofile/xmlbeans"
xmlns="http://com/exlibris/repository/mdprofile/xmlbeans">
<!-- marc_profile element definition -->
<xs:element name="marc_profile">
<xs:complexType>
<xs:sequence>
<xs:element ref="leader_configuration" minOccurs="1"
maxOccurs="1" />
<xs:element ref="control_fields_list" minOccurs="1"
maxOccurs="1" />
<xs:element ref="data_fields_list" minOccurs="1"
maxOccurs="1" />
</xs:sequence>
</xs:complexType>
</xs:element>
<!-- XSD element definition -->
<!-- leader element definition -->
<xs:element name="leader_configuration">
<xs:complexType>
<xs:sequence>
<xs:element name="positions_list" minOccurs="1"
maxOccurs="1" type="positionsListType" />
</xs:sequence>
</xs:complexType>
</xs:element>
<!-- control_fields_list element definition -->
<xs:element name="control_fields_list">
<xs:complexType>
<xs:sequence>
<xs:element name="control_field_configuration" minOccurs="0"
maxOccurs="unbounded">
<xs:complexType>
<xs:sequence>
<xs:element name="description" minOccurs="1"
maxOccurs="1" type="xs:string" />
<xs:element name="help_url" minOccurs="0"
maxOccurs="1" type="xs:string" />
<xs:element name="materials_type_list" minOccurs="1"
maxOccurs="1" type="materialstypeListType" />
</xs:sequence>
<xs:attribute name="tag" type="tagType" use="required" />
<xs:attribute name="repeatable" type="xs:boolean"
use="required" />
<xs:attribute name="mandatory" type="xs:boolean" use="optional" />
</xs:complexType>
</xs:element>
</xs:sequence>
</xs:complexType>
</xs:element>
<!-- data_fields_list element definition -->
<xs:element name="data_fields_list">
<xs:complexType>
<xs:sequence>
<xs:element name="data_field_configuration" minOccurs="0"
maxOccurs="unbounded">
<xs:complexType>
<xs:sequence>
<xs:element name="description" minOccurs="1"
maxOccurs="1" type="xs:string" />
<xs:element name="help_url" minOccurs="0"
maxOccurs="1" type="xs:string" />
<xs:element name="first_indicator_configuration" type="indicatorType"
minOccurs="0" maxOccurs="1" />
<xs:element name="second_indicator_configuration"
type="indicatorType" minOccurs="0" maxOccurs="1" />
<xs:element name="sub_fields_list" minOccurs="0"
maxOccurs="1" type="subfieldType">
<xs:key name="sub_field_configuration-unique">
<xs:selector xpath="sub_field_configuration" />
<xs:field xpath="@code" />
</xs:key>
</xs:element>
</xs:sequence>
<xs:attribute name="tag" type="tagType" use="required" />
<xs:attribute name="repeatable" type="xs:boolean"
use="required" />
<xs:attribute name="mandatory" type="xs:boolean" use="optional" />
</xs:complexType>
</xs:element>
</xs:sequence>
</xs:complexType>
</xs:element>
<!-- XSD complex type definition -->
<xs:complexType name="positionsListType">
<xs:sequence>
<xs:element name="position_configuration" type="positionType"
minOccurs="0" maxOccurs="unbounded" />
</xs:sequence>
</xs:complexType>
<xs:complexType name="positionType">
<xs:sequence>
<xs:element name="description" minOccurs="1" maxOccurs="1"
type="xs:string" />
<xs:element name="values" minOccurs="1" maxOccurs="1"
type="valuesType" />
</xs:sequence>
<xs:attribute name="start" type="customIntegerType" use="required" />
<xs:attribute name="end" type="customIntegerType" use="required" />
</xs:complexType>
<xs:complexType name="valuesType">
<xs:sequence>
<xs:element name="value" minOccurs="0" maxOccurs="unbounded">
<xs:complexType>
<xs:simpleContent>
<xs:extension base="xs:string">
<xs:attribute name="code" type="codeType" use="required" />
</xs:extension>
</xs:simpleContent>
</xs:complexType>
</xs:element>
</xs:sequence>
</xs:complexType>
<xs:complexType name="subfieldValuesType">
<xs:sequence>
<xs:element name="value" minOccurs="0" maxOccurs="unbounded">
<xs:complexType>
<xs:simpleContent>
<xs:extension base="xs:string">
<xs:attribute name="code" type="codeType" use="required" />
</xs:extension>
</xs:simpleContent>
</xs:complexType>
</xs:element>
</xs:sequence>
<xs:attribute name="codeTable" type="xs:string" />
</xs:complexType>
<xs:complexType name="indicatorType">
<xs:sequence>
<xs:element name="description" minOccurs="1" maxOccurs="1"
type="xs:string" />
<xs:element name="values" minOccurs="1" maxOccurs="1"
type="valuesType" />
</xs:sequence>
<xs:attribute name="mandatory" type="xs:boolean" use="optional" />
</xs:complexType>
<xs:complexType name="subfieldType">
<xs:sequence>
<xs:element name="sub_field_configuration" minOccurs="0"
maxOccurs="unbounded">
<xs:complexType>
<xs:sequence>
<xs:element name="description" minOccurs="1" maxOccurs="1"
type="xs:string" />
<xs:element name="values" minOccurs="0" maxOccurs="1"
type="subfieldValuesType" />
<xs:element name="materials_type_list" minOccurs="0"
maxOccurs="1" type="materialstypeListType" />
</xs:sequence>
<xs:attribute name="code" type="subfieldCodeType" use="required" />
<xs:attribute name="repeatable" type="xs:boolean" use="required" />
<xs:attribute name="mandatory" type="xs:boolean" use="optional" />
</xs:complexType>
</xs:element>
</xs:sequence>
</xs:complexType>
<xs:complexType name="materialstypeListType">
<xs:sequence>
<xs:element name="material_type_configuration" minOccurs="0"
maxOccurs="unbounded" type="materialtypeType">
</xs:element>
</xs:sequence>
</xs:complexType>
<xs:complexType name="materialtypeType">
<xs:sequence>
<xs:element name="positions_list" minOccurs="1" maxOccurs="1"
type="positionsListType" />
</xs:sequence>
<xs:attribute name="name" type="xs:string" use="required" />
</xs:complexType>
<!-- XSD simple type definition -->
<xs:simpleType name="tagType">
<xs:restriction base="xs:string">
<xs:pattern value="[0-9]{3}" />
</xs:restriction>
</xs:simpleType>
<xs:simpleType name="customIntegerType">
<xs:restriction base="xs:string">
<xs:pattern value="[0-9]+" />
</xs:restriction>
</xs:simpleType>
<xs:simpleType name="codeType">
<xs:restriction base="xs:string">
<xs:pattern value="[a-z#0-9|]+" />
</xs:restriction>
</xs:simpleType>
<xs:simpleType name="subfieldCodeType">
<xs:restriction base="xs:string">
<xs:pattern value="[a-z0-9]{1}" />
</xs:restriction>
</xs:simpleType>
</xs:schema>
拡張パックの.xmlファイルの例
<marc_profile xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:noNamespaceSchemaLocation="marc21_profile_configuration.xsd">
<control_fields_list>
<control_field_configuration mandatory="true" repeatable="false"
tag="003">
<description>PERSISTENT RECORD IDENTIFIER</description>
<materials_type_list />
</control_field_configuration>
</control_fields_list>
<data_fields_list>
<data_field_configuration repeatable="true" mandatory="false" tag="020" xmlns="http://com/exlibris/repository/mdprofile/xmlbeans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<sub_fields_list>
<sub_field_configuration code="9" mandatory="false" repeatable="true">
<description>Former ISBN
</description>
</sub_field_configuration>
</sub_fields_list>
</data_field_configuration>
<data_field_configuration repeatable="true" mandatory="false" tag="024" xmlns="http://com/exlibris/repository/mdprofile/xmlbeans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<sub_fields_list>
<sub_field_configuration code="9" mandatory="false" repeatable="true">
<description>Former ISSN
</description>
</sub_field_configuration>
</sub_fields_list>
</data_field_configuration>
<data_field_configuration repeatable="false" mandatory="false" tag="689" xmlns="http://com/exlibris/repository/mdprofile/xmlbeans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<description>SUBJECT HEADING CHAIN</description>
<help_url>http://www.google.com</help_url>
<first_indicator_configuration>
<description>Type of subject heading chain</description>
<values>
<value code="0">Simple chain</value>
<value code="1">Complex chain</value>
</values>
</first_indicator_configuration>
<second_indicator_configuration>
<description>Undefined</description>
<values>
<value code="#">Undefined</value>
</values>
</second_indicator_configuration>
<sub_fields_list>
<sub_field_configuration code="a" mandatory="true" repeatable="false">
<description>Heading chain first element
</description>
</sub_field_configuration>
<sub_field_configuration code="b" mandatory="false" repeatable="true">
<description>Heading chain second element</description>
</sub_field_configuration>
<sub_field_configuration code="c" mandatory="true" repeatable="true">
<description>Type of chain</description>
<values>
<value code="0">GND chain</value>
<value code="1">DNB chain</value>
</values>
</sub_field_configuration>
</sub_fields_list>
</data_field_configuration>
</data_fields_list>
</marc_profile>
フォームの使用
MARCフィールドを、フォームの作成に使用するラベルにマッピングできます。MARCスリム設定を参照してください。
- フォームタブを選択して、Qualified Dublin Core、MARC Bibliographic、 または MODS プロファイルを設定します。
- [フォームの追加]を選択し、次のいずれかを選択します。 以下が表示されます。
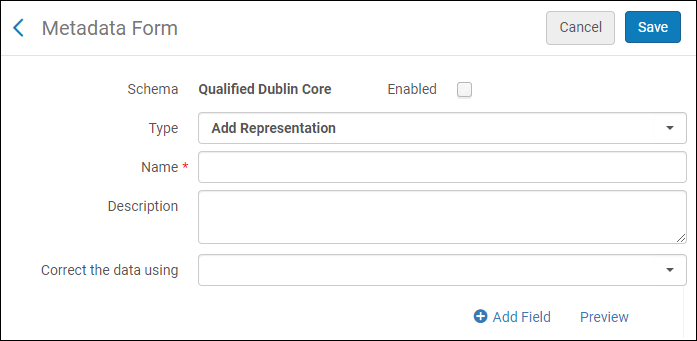 メタデータフォーム
メタデータフォーム - フォームのフィールドに入力し、[フィールドの追加]を選択します。フィールドタイプのリストが表示されます。
- チェックボックス – 選択またはクリアできる単一のチェックボックス
- コンボボックスの複数選択 – チェックボックスのドロップダウンリスト。複数のチェックボックスを選択できます。
- コンボボックスの単一選択 – オプションのドロップダウンリスト。選択できるのは1つだけです。
- 日付 – 日付ピッカー
- 隠された – 所定のフィールドと値をメタデータレコードに自動的に追加するために使用される隠しフィールド 。
- ラジオボタン - 複数のラジオボタンが表示されます。選択できるのは1つだけです。
- テキスト領域 – 複数行のテキストボックス
- テキストボックス – 1行のテキストボックス
- ルックアップ – 入力するとオプションが表示されます。または、このアイコンを選択してオプションのページを開きます。 選択できるのは 1 つだけです。 フォームにルックアップフィールドを追加は、表現およびスタッフ仲介によるデポジットの場合 のみ 可能になります。
- フィールドタイプを選択します。選択したフィールドタイプのフィールドが表示されます。例:
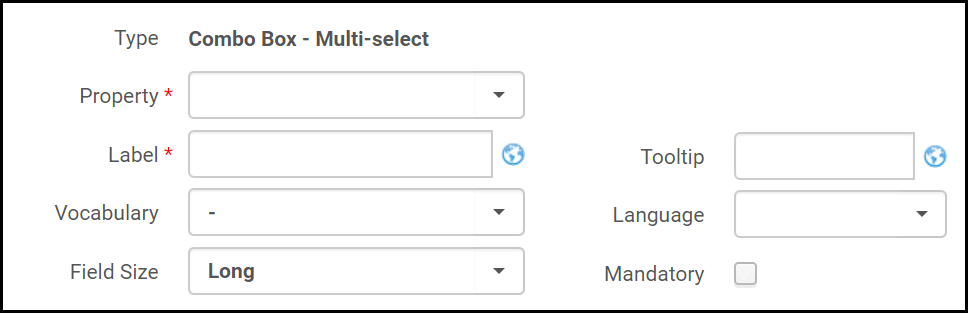 フォームフィールド(Dublin Coreフォーム)
フォームフィールド(Dublin Coreフォーム) - 次のようにフィールドに入力します。
- プロパティまたはフィールド – (Dublin Coreの場合)フォームに追加するプロパティ、または(MARC 21の場合)フォームに追加するフィールド。
- 属性名 –(MODS のみ)選択したフィールドの属性名を選択します。
- 属性値 –(MODS のみ)選択した属性の値を入力します。
- [ラベル] – プロパティのラベル。
- 語彙 – 語彙を選択して、このフィールドがユーザーに表示されるオプションを決定します。詳細については、語彙の制御レジストリ - フォームを参照してください。
- [フィールドサイズ] – フィールドを短くするか長くするかを選択します。
- ツールチップ – 表示するツールチップメッセージ。
- 言語 – 機関が学位論文または学術論文の言語として受け入れる言語。
- [デフォルト値] - フォームに表示するデフォルト値を選択します。
- 必須 – フォームを必須にする場合は、このオプションを選択します。
- 繰り返し可能 – このオプションを選択すると、ユーザーはフィールドの複数のインスタンスを追加できるようになります。
- [リストに保存]を選択します。プロパティがフォームに追加されます。
- フォームにフィールドを追加するための手順を繰り返します。[プレビュー]を選択して、フォームのプレビューを表示します。
- フォームへのフィールドの追加が終了したら、[保存]を選択します。
正規化プロセスの使用
- カスタマイズされた正規化プロセスを作成します。以下の 目録の設定 を参照してください。
- 正規化プロセスの編集 - 行アクションリストから[編集]を選択します。既存の正規化プロセスの設定は、次のタブに表示されます。
- 一般情報
- タスクリスト
- タスクパラメータ
- 正規化プロセスを複製して複製コピーを変更します。 行アクションのリストから、コピーを選択します。
- 正規化プロセスを無効にする - 正規化プロセスが現在必要ではないが、将来必要になる可能性がある場合は、有効 列で無効化(有効化)できます。
- 正規化プロセスの削除-行アクションリストから[削除]を選択します。
正規化プロセスの作成
- [プロファイルの詳細]ページの[正規化プロセス]タブで[プロセスの追加]を選択します( [設定メニュー] > [リソース] > [目録]> [メタデータ構成] > プロファイルリンクを選択)。または、[プロセスリスト]ページ( [設定メニュー] > [リソース] > [一般] > [プロセス] )からプロセスを作成することもできます。 既存のプロセスのコピーを作成するには、行アクションリストから[コピー]を選択します。プロセスをコピーしたら、必要に応じて編集できます。
- [一般情報]セクションで
- プロセスの名前と説明を入力します。これらの値は、プロセスリストページでユーザーに表示されます。
- [ステータス]フィールドで、プロセスが有効([有効])かどうかを選択します。無効になっているプロセスは、実行せずにシステムに保存および編集できます。いつでも有効にできます。
- [次へ]を選択し、[タスクの追加]を選択します。
- 必要なタスクを選択し、[追加して閉じる]を選択します。
このページには、プロセス(またはタスクチェーン)に含めることができるタスクの定義済みリストが含まれています。タスクの説明については、「タスク リストのオプション」を参照してください。
追加のタスクを定義することはできず、これらのタスクのほとんどには固定パラメーターがあります。 編集しているメタデータ構成によって、タスクは異なります。
「MarcDroolNormalization」(「DcDroolNormalizationまたはMarc XSL Normalization) )タスクを選択して、次のステップにおいてMDエディタで作成した正規化ルール( 「正規化ルールの操作」を参照)を選択できるようにします。 - 上矢印と下矢印を使用して、タスクを実行する順序を調整します。
- [次へ]を選択します。ウィザードの次のページが表示されます。
表示されるパラメータは、選択したタスクによって異なります。 - 保存を選択します。
タスクリストオプション
| プロセス名 | 説明 |
|---|---|
| 852フィールドの正規化 | 書誌レコードから管理番号を取得して、所蔵レコードの正しいサブフィールドに配置するタスクを実行します。 詳細については、 MARC 21所蔵プロファイルの操作を参照してください。 |
| addBibToCollectionNormalizationTask | MARCレコードの787フィールドの値に従って、インポートされたデジタルタイトルをコレクションに割り当てます。詳細については、インポートプロファイルの管理を参照してください。 |
| ハングル翻字に韓文漢字を追加 | 以下に示すようにソースフィールドとターゲットフィールドを設定することにより、タイトルなどのコンテンツを韓文漢字からハングル文字に変換します。詳細については、目録におけるCJK翻字の使用を参照してください。この翻字プロセスは、MARC 21書誌およびMARC 21典拠の設定に加えて、KORMARC、UNIMARC、CNMARCなどのさまざまなMARC設定に使用できます。 |
| ハングルCK翻字に韓文漢字を追加 | 以下に示すようにソースフィールドとターゲットフィールドを設定することにより、タイトルなどのコンテンツを韓文漢字からハングルCKに変換します。詳細については、目録におけるCJK翻字の使用を参照してください。この翻字プロセスは、MARC 21書誌およびMARC 21典拠の設定に加えて、KORMARC、UNIMARC、CNMARCなどのさまざまなMARC設定に使用できます。 |
| ハングルMOE翻字に韓文漢字を追加 | 以下に示すようにソースフィールドとターゲットフィールドを設定することにより、タイトルなどのコンテンツを韓文漢字からハングルMOEに変換します。詳細については、目録におけるCJK翻字の使用を参照してください。この翻字プロセスは、MARC 21書誌およびMARC 21典拠の設定に加えて、KORMARC、UNIMARC、CNMARCなどのさまざまなMARC設定に使用できます。 |
| ピンイン翻字に韓文漢字を追加 | 以下に示すようにソースフィールドとターゲットフィールドを設定することにより、タイトルなどのコンテンツを韓文漢字からピンインに変換します。詳細については、目録におけるCJK翻字の使用を参照してください。この翻字プロセスは、MARC 21書誌およびMARC 21典拠の設定に加えて、KORMARC、UNIMARC、CNMARCなどのさまざまなMARC設定に使用できます。 |
| ピンイン翻字に漢字を追加 | 中国語のコンテンツをピンインに変換します。 設定 このプロセスの設定では、ソースとターゲットのフィールド/サブフィールドを漢字からピンインに指定する必要があります。 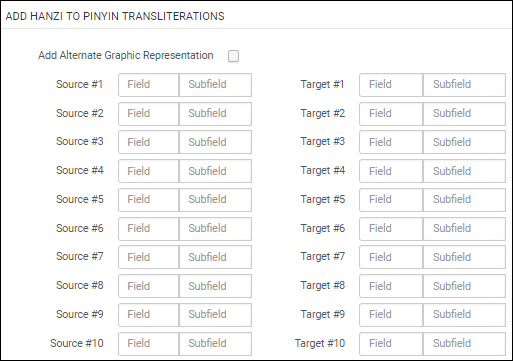 漢字からピンインへのタスク設定 正規化が処理されると、ターゲットフィールドの第1と第2インジケーターは、ソースフィールドのインジケーターと同じになります。 翻字された単語はターゲットフィールド/サブフィールドに配置され、複数の翻字がある単語のみがターゲットフィールド/サブフィールドの山括弧< >に配置されます。その後、目録者は正しいものを選択し、その他を削除できます。 香港中国語検索言語用に設定された機関では、漢字からピンインへの翻字プロセスを、山括弧ですべての可能な翻字オプションを提供する代わりに、最も一般的に使用される単語の翻字をレコードに追加する ことに注意してください。 ターゲットサブフィールドにコンテンツが存在する場合、正規化プロセスはそれを上書きします。 サブフィールドの削除は、この正規化プロセスの一部として処理されません。サブフィールドを削除するには、そのタスク専用の正規化プロセスを選択します。 [代替グラフィック表記の追加]オプションを選択して、880フィールドを漢字からピンインへの翻字のターゲットとして識別します。このオプションを使用する場合、ソースフィールドのみを指定する必要があります。ソースフィールドのすべてのサブフィールドは、880フィールドに字訳されます。 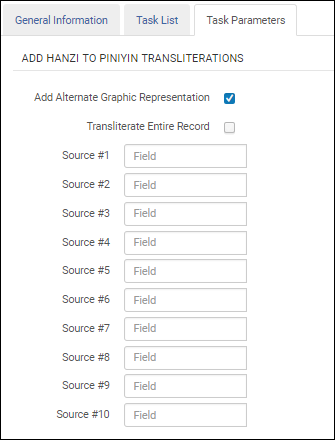 代替グラフィック表記を追加 レコード内のすべてのフィールドを漢字からピンインに翻字するには、[レコード全体を翻字]オプションを選択します。このオプションは、[代替グラフィック表記の追加]オプションを選択した後に表示されます。すべてのフィールドが翻字されるので(中国語のないフィールドを除く)、タスク設定でソースフィールドを指定する必要はありません。 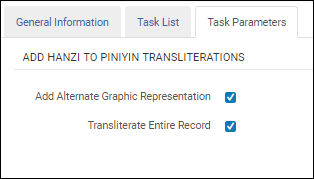 レコード全体を翻字する 大文字 漢字で始まり、翻字されるすべてのMARC 21フィールドでは、最初の翻字された文字は大文字になります。 個人名 漢字をピンイン翻字に追加する正規化タスクを使用し、Ex Librisが機関を香港の検索言語設定している場合、100、600、700、800フィールドの$aにある個人名は次の方法で処理されます。
中国語の翻字と比較した香港の翻字については、以下の例を参照してください。 香港 毛澤東 => Mao, Zedong 中国語 毛澤東 => mao ze dong 詳細については、目録におけるCJK翻字の使用を参照してください。この翻字プロセスは、MARC 21書誌およびCNMARCプロファイルに使用できます。 |
| ハングル翻字にカナを追加 | 以下に示すようにソースフィールドとターゲットフィールドを設定することにより、タイトルなどのコンテンツをカナからハングルに変換します。詳細については、目録におけるCJK翻字の使用を参照してください。この翻字プロセスは、MARC 21書誌およびMARC 21典拠の設定に加えて、KORMARC、UNIMARC、CNMARCなどのさまざまなMARC設定に使用できます。 |
| ローマ字カナ翻字にカナを追加 | 以下に示すようにソースフィールドとターゲットフィールドを設定することにより、タイトルなどのコンテンツをカナからローマ字カナに変換します。詳細については、目録におけるCJK翻字の使用を参照してください。この翻字プロセスは、MARC 21書誌およびMARC 21典拠の設定に加えて、KORMARC、UNIMARC、CNMARCなどのさまざまなMARC設定に使用できます。 |
| addMmsIdToDcIdentifier | DCレコードのdc:identifierフィールドにMMSIDを追加します。 |
| AuthorityGenerateControlNumberSequence | 典拠レコードの制御番号シーケンスを生成するタスクを実行します。 |
| BibGenerateControlNumberSequence | 書誌レコードの管理番号シーケンスを生成するタスクを実行します。 |
| BibGenerateLocalControlNumberSequence | 例えば、編集 > レコードの拡張がMDエディタでレコードを編集する際に選択されている場合、035フィールドに保存されているローカル 請求番号を生成するタスクを(MARC21で)実行します。 新しいプロセスを追加する場合、タスクを追加するを選択し、ローカル請求番号を生成するを選択し、追加して閉じるを選択し、タスクパラメータを設定するために次へを選択します。 「書誌ターゲットフィールド」 は単一のオプションをリストすることに注意してください:「035サブフィールドa」。 |
| BibGenerateHandle | |
| CnmarcBibAdd005Task | 005フィールドは、MDエディタで保存する場合にのみ追加されます。 |
| CnmarcBibClearEmptyFieldsTask | このプロセスは、空の書誌フィールドを削除するタスクを実行します。 |
| CnmarcBibReSequenceTask | このプロセスは、001、100、200などの適切な順序に従って書誌フィールドを再配列するタスクを実行します。 500から899までのフィールドはソートされません(または百の位でのみソートされます)。 |
| CnmarcBibTag100OpenDateTask | 100フィールドが存在する場合、現在の日付は、YYYYMMDD形式を使用して、00〜07の位置の100 $aの先頭に配置されます。 |
| CnmarcBibTag100Task | Almaは、CNMARC 210$dに入力された日付(および4桁の連続した数字が含まれている場合は210 $h)に従って、CNMARC 100フィールドの09~12および13~16の位置に日付を自動的に挿入または修正します。さらに、210 $dが標準化されています。198?や19?のような日付の場合、たとえば、Almaは疑問符とスペースを「-」(ハイフン)に置き換えます。 |
| Create210BasedOn010 | この正規化プロセスタスクは、MARC 210 $aをレコードに追加し、MARC 010 $aのISBNとAlma内で管理されるテーブルに基づいて、中国の出版社を210に配置します。このタスクを選択した状態で正規化プロセスを作成して保存したら、MDエディタの[編集 > レコードの拡張]オプションを使用して、目録化しているレコードを更新できます。 |
| DcBibClearEmptyFieldsTask | 空のDublin Coreフィールドを削除するタスクを実行します。 |
| DcBibResequenceTask | 適切な順序に従ってDublin Coreフィールドを再配列するタスクを実行します。 |
| DcDroolNormalization | 実行する正規化ルールを選択します。詳細については、「MARC Droolの正規化」 を参照してください。 MDエディタで共有ルールとして作成された正規化ルールのみを選択できます。 詳細については、「正規化プロセスの操作」を参照してください。 |
| 簡易レベルの識別 | レコードの簡易レベルを計算するタスクを実行します。 |
| 中国人著者の請求番号を生成する | MDエディタでレコードを編集しているときに、たとえば[編集 > レコードの拡張]を選択すると、905フィールドに保存される中国人の著者の請求番号を生成するタスク(CNMARC)を実行します。 新しいプロセスを追加するときは、[タスクの追加]を選択し、[中国人著者の請求番号を生成する]を選択し、[追加して閉じる]を選択し、[次へ]を選択して、[著者番号生成ルーチンの選択]ドロップダウンリストから著者番号生成ルーチンにアクセスして選択します。 次の著者番号生成ルーチンオプションのいずれかを選択します。
これは、ルーチン2を使用して090フィールドに著者番号を生成する一般中国著者番号テーブルに基づくCNMARC書誌レコードの請求番号生成ルーチンです。
これは、ルーチン3を使用して090フィールドに著者番号を生成する一般中国著者番号テーブルに基づくCNMARC書誌レコードの請求番号生成ルーチンです。
次のシーケンスは、905フィールドに生成されます。 このルーチンは、バッチ処理ではなく、レコードを手動で編集する場合にのみ使用してください。
この保守手順は、書誌レコードの905フィールドからシーケンスをAlmaに保存します。これは新しいシーケンスを生成しませんが、代わりに、書誌レコードから既存のシーケンスを保存します。これは、移行後やMDインポート後などのバッチ更新後に使用できます。これは、Almaシーケンスと書誌レコードに保存されているものを同じにするために使用されます。 MDエディタ(F4)パラメーターで著者番号を生成するときに[使用]を選択すると、MDエディタで、[著者番号生成ルーチンを選択]パラメーターで選択した著者番号生成のタイプを有効にします。 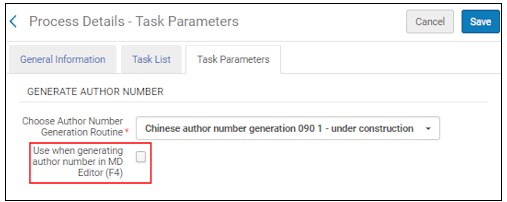 MDエディタ(F4)パラメーターで著者番号を生成するときに使用します 正規化のためにこのオプションを選択すると、MDエディタでF4を押すと、システムは通常の著者番号生成の代わりにこのプロファイルで識別される著者番号生成ルーチンを使用します。 |
| MARC21作成者の請求番号を生成 | MDエディタでレコードを編集中に[編集 > レコードの拡張]が選択された場合など、905フィールドに保存されている中国人著者の請求番号を生成するタスク(MARC 21)を実行します。これは、[中国人著者の請求番号を生成]プロセスのMARC 21バージョンです。 新しいプロセスを追加するときは、[タスクの追加]を選択し、[中国人著者の請求番号を生成する]を選択し、[追加して閉じる]を選択し、[次へ]を選択して、[著者番号生成ルーチンの選択]ドロップダウンリストから著者番号生成ルーチンにアクセスして選択します。
これは、ルーチン3を使用して090フィールドに著者番号を生成する一般中国著者番号テーブルに基づくMARC 21書誌レコードの請求番号生成ルーチンです。
これは、ルーチン4を使用して090フィールドに著者番号を生成する一般中国著者番号テーブルに基づくMARC 21書誌レコードの請求番号生成ルーチンです。
これは、ルーチン1を使用して905フィールドに著者番号を生成する一般中国著者番号テーブルに基づくMARC 21書誌レコードの請求番号生成ルーチンです。
次のシーケンスは、905フィールドに生成されます。 このルーチンは、バッチ処理ではなく、レコードを手動で編集する場合にのみ使用してください。
この保守手順は、書誌レコードの905フィールドからシーケンスをAlmaに保存します。これは新しいシーケンスを生成しませんが、代わりに、書誌レコードから既存のシーケンスを保存します。これは、移行後やMDインポート後などのバッチ更新後に使用できます。これは、Almaシーケンスと書誌レコードに保存されているものを同じにするために使用されます。 MDエディタ(F4)パラメーターで著者番号を生成するときに[使用]を選択すると、MDエディタで、[著者番号生成ルーチンを選択]パラメーターで選択した著者番号生成のタイプを有効にします。 正規化のためにこのオプションを選択すると、MDエディタでF4を押すと、システムは通常の著者番号生成の代わりにこのプロファイルで識別される著者番号生成ルーチンを使用します。 |
| MARC正規化ルール | [タスクパラメーター]タブでパラメーターとして選択された正規化ルールを実行します。 |
| 863/4/5タスクによるMARC21所蔵展開 | 863/864/865 要約報告所蔵フィールドを追加するタスクを実行します。 詳細については、 MARC 21所蔵プロファイルの操作を参照してください。 |
| 866/7/8タスクによるMARC21所蔵展開 | 866/867/868テキスト所蔵フィールドに説明を追加するタスクを実行します。 詳細については、 MARC 21所蔵プロファイルの操作を参照してください。 |
| Marc21AuthClearEmptyFieldsTask | 空の典拠フィールドを削除するタスクを実行します。 |
| Marc21AuthResequenceTask | 適切な順序に従って典拠レコードフィールドを再配列するタスクを実行します。 |
| Marc21BibClearEmptyFieldsTask | 空の書誌フィールドを削除するタスクを実行します。 空のフィールドを持つレコードは保存できないため、このタスクをすぐに使用できるプロセスから削除することはできません。 |
| Marc21BibResequenceTask | 適切な順序(001、100、200など)に従って書誌フィールドを再配列するタスクを実行します。 500から899までのフィールドはソートされません(または百の位でのみソートされます)。689フィールド(ドイツ市場のみに関連)は、そのインジケーターでソートされます。 |
| Marc21createControlNumber | 書誌レコードの001および003フィールドから新しい管理番号を作成し、035フィールドに配置するタスクを実行します。 |
| Marc21HoldingClearEmptyFieldsTask | 空の所蔵フィールドを削除するタスクを実行します。 詳細については、 MARC 21所蔵プロファイルの操作を参照してください。 |
| Marc21HoldingResequenceTask | 適切な順序に従って所蔵フィールドを再配列するタスクを実行します。 フィールド5XXと8XXはソートされません。 詳細については、 MARC 21所蔵プロファイルの操作を参照してください。 |
| 001フィールドを所蔵レコードに書き込みます。 詳細については、MARC 21所蔵プロファイルの操作を参照してください。 | |
| MarcDroolNormalization | 実行する正規化ルールを選択します。正規化プロセスでは、メタデータエディターで すでに定義され保存されている共有正規化ルールを構成要素として使用します (「正規化ルールの操作」を参照)。 プライベート正規化ルールは、 正規化プロセス に使用することはできません。 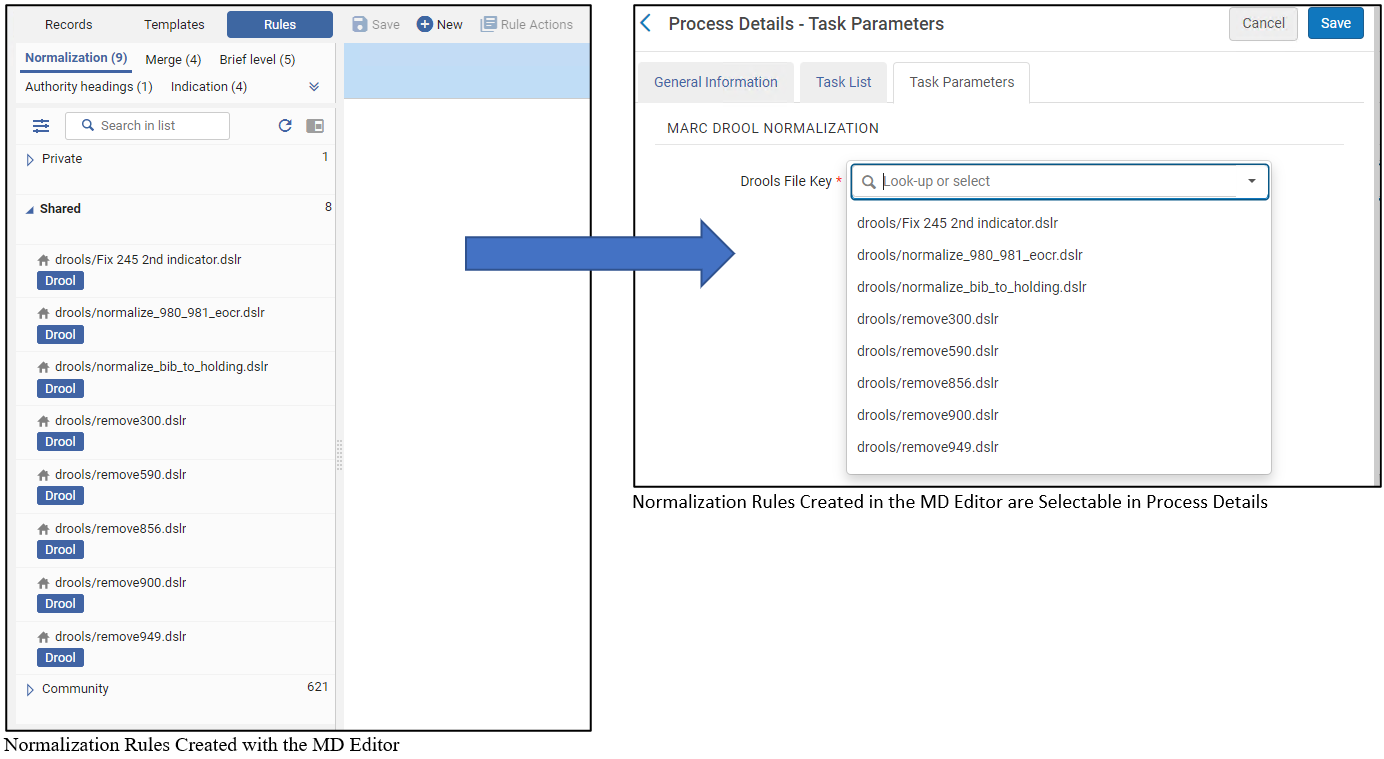 正規化ルールの作成に関する詳細については、正規化ルールの操作を参照してください。 |
| MarcXSLNormalization | 実行する正規化ルールを選択します。 正規化プロセスは、共有済の すでに定義されかつメタデータエディタ保存された正規化ルール を構成要素として使用します(「正規化ルールの操作」を参照)。 プライベート正規化ルールは、 正規化プロセス に使用することはできません。  正規化ルールの作成に関する詳細については、正規化ルールの操作を参照してください。 |
| MmsTagSuppressed | 選択した値TrueまたはFalse(Primoへの公開を抑制するレコードの場合はTrue、Primoへのレコードの公開を許可する場合はFalse)に従って、書誌レコードをディスカバリーから非公開/公開するタスクを実行します。 |
| MmsTagSyncExternal | 以下の選択された値のいずれかに従って、外部目録との書誌レコードの同期ポリシーを設定するタスクを実行します。
|
| MmsTagSyncNationalCatalog | 以下の選択された値のいずれかに従って、全国目録と書誌レコードの同期ポリシーを設定するタスクを実行します。
|
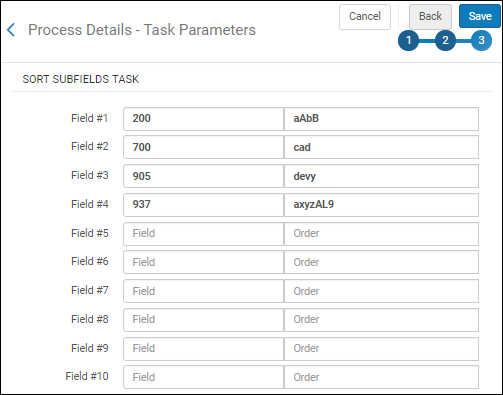
| 正規化中に特定のフィールドのサブフィールドの順序をソートするには、このタスク を選択します。このタスクを[プロセスの詳細] - [タスクの追加]ページに追加し、[次へ]を選択すると、サブフィールドの並べ替えタスクセクションが表示され、特定のフィールドのサブフィールドの順序を最大10種類までカスタマイズできます。
サブフィールドの並べ替えタスク ソート順で指定されていないフィールドに他のサブフィールドがある場合、それらは元の順序でソートされたサブフィールドの後に追加されます。ソート用にカスタマイズされていないフィールドは、 元のサブフィールドの順序を維持します。並べ替えのカスタマイズでは大文字と小文字が区別されます。小文字と大文字は別々に扱われます。 | |
| UnimarcBibAdd005Task | 005フィールドは、MDエディタで保存する場合にのみ追加されます。 SBNを使用する機関については、 SBNまたはUNIMARCのタスクUnimarcBibAdd005Taskの設定を参照してください。 |
| UnimarcBibClearEmptyFieldsTask | このプロセスは、空の書誌フィールドを削除するタスクを実行します。 |
| UnimarcBibReSequenceTask | このプロセスは、001、100、200などの適切な順序に従って書誌フィールドを再配列するタスクを実行します。 500から899までのフィールドはソートされません(または百の位でのみソートされます)。 |
| UnimarcBibTag100OpenDateTask | 100フィールドが存在する場合、現在の日付は、YYYYMMDD形式を使用して、00〜07の位置の100 $aの先頭に配置されます。 |
| UnimarcBibTag100Task | Almaは、UNIMARC 210$dに入力された日付(および4桁の連続した数字が含まれている場合は210 $h)に従って、UNIMARC 100フィールドの09~12および13~16の位置に日付を自動的に挿入または修正します。さらに、210 $dが標準化されています。198?や19?のような日付の場合、たとえば、Almaは疑問符とスペースを「-」(ハイフン)に置き換えます。 |
| 発信元システム情報を更新する | このオプションを使用して、[一致時上書き]オプションまたは[統合]オプションでレコードをインポートするときにバージョン防止に使用される発信元システムバージョンを設定し、[発信元システムを検討]または[発信元システムを無視]オプションを選択します。2015年9月リリースより前にシステムに保存されたレコードには、発信元システムバージョン情報がありません。Almaは、プロセス自動化ジョブを使用して、プロセスリストプールから選択された発信元システム情報を更新することで、この情報を設定する機能を提供します。2015年9月リリース後にインポートされたレコードの場合、発信元システムと発信元システムバージョンが自動的に追加されます。 2015年9月リリースより前のこれら既存のレコードを処理する場合、正規化タスクでコミュニティゾーンにリンクされたレコードは変更されないことに注意してください。 発信元システム情報と発信元システムバージョン情報を管理するための正規化を設定するには、[発信元システム情報の更新]を使用してプロセスをセットアップする方法に関する手順を参照してください |
発信元システムを管理するための正規化の設定
- [プロセスリスト]ページ([設定メニュー > リソース > 全般 > プロセス])で、[プロセスの追加]を選択します。
- 以下で識別されるパラメーターに対して以下のオプションを選択し、[次へ]を選択します。
- ビジネスエンティティ – 書誌タイトル
- タイプ - MARC 21書誌正規化(または環境に応じて他のオプションタイプ)
- [一般情報]セクションに入力して、[次へ]を選択します。
- [タスクの追加]を選択し、[元のシステム情報の更新]を選択します。
- [追加して閉じる]を選択し、[次へ]を選択します。
- 要件に応じて、次のパラメーターのいずれかを選択します。 選択したパラメーターについては、関連するパラメーターも指定する必要があります(存在する場合)。
- 発信元システムの更新-インポートされたレコードのメタデータで特定する発信元システム。
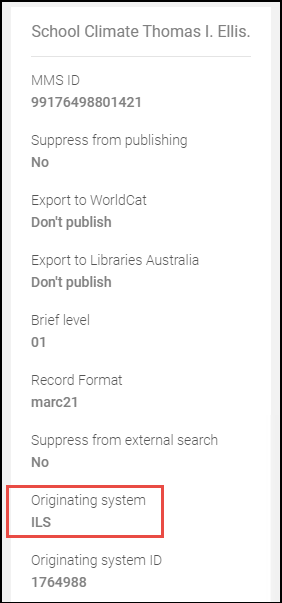 発信元システム
発信元システム - 発信元システムバージョンの更新 - レコードのメタデータに保存する日付。この日付は、レコードの一致を処理するためにインポートプロファイルで 上書き/統合防止オプションを選択するときに使用されます(インポートプロファイルの作成/編集:プロファイルの一致を参照)。この日付パラメーターの形式はMM/DD/YYYYです。発信元システムバージョンの形式はYYYYMMDDhhmmss.fです(hhmmss.fは時間、分、秒、および秒の小数部であり、24時間制が使用されます)。このパラメーターを指定して正規化が行われると、AlmaはYYYYMMDD000000.0を入力します。発信元システムバージョンのhhmmss.f部分にゼロが入力されます。 メタデータインポートを使用する場合、Almaは、発信元システムバージョンフィールドのインポートされたレコードの005コントロールフィールドから日付と時刻(YYYYMMDDhhmmss.fとしてフォーマットされています)を取得します。005コントロールフィールドと日付/時刻形式の例については、次の図を参照してください。
 正規化プロセスは、[発信元システムバージョン]パラメーターでカレンダーから入力または選択された日付に従って、発信元システムバージョンフィールドを更新します。たとえば、[元のシステムバージョン]パラメーターに選択された日付で正規化プロセスを使用するMARC 21書誌正規化ジョブを実行すると、指定した日付は、ジョブに選択したセット内のすべてのレコードに適用されます。
正規化プロセスは、[発信元システムバージョン]パラメーターでカレンダーから入力または選択された日付に従って、発信元システムバージョンフィールドを更新します。たとえば、[元のシステムバージョン]パラメーターに選択された日付で正規化プロセスを使用するMARC 21書誌正規化ジョブを実行すると、指定した日付は、ジョブに選択したセット内のすべてのレコードに適用されます。 - [既存の発信元システムバージョン値の更新]-選択した発信元システムバージョン(上記)が既存のバージョンを上書きするかどうか。選択しない場合、既存のバージョンはそのまま残ります。
- 発信元システムの更新-インポートされたレコードのメタデータで特定する発信元システム。
- [保存]を選択します。 作成したプロセスを実行して、一連のレコードの発信元システムバージョン情報を更新するには、定義済みセットでの手動ジョブの実行ページの手順に従います。必要に応じて、ジョブを実行するときに、[元のシステム]または[元のシステムバージョン]パラメータを変更/上書きできます。
検証プロセスの編集
- MARC 21書誌一致検証 – インポートプロセス中またはMDエディタで書誌レコードの一致が実行された場合の検証の処理方法を定義します。
- 保存時のMARC 21書誌検証 – インポートプロファイルを使用してMARCレコードをインポートし、外部リソース(WorldCatやLoCなど)を介して目録をコピーし、MDエディタで書誌レコードを保存するときの検証の処理方法を定義します。
- MARC 21権限一致検証 – インポートプロセス中またはMDエディタで権限レコードの一致が実行された場合の検証の処理方法を定義します
- 保存時のMARC 21権限検証 – インポートプロファイルを使用してMARCレコードをインポートし、外部リソースを介して目録をコピーし、MDエディタで書誌レコードを保存する場合の検証の処理方法を定義します。
- プロファイルの詳細ページの[検証プロセス]タブで、編集する検証プロセスの行の[編集]アクションを選択します([設定メニュー > リソース > 目録 > メタデータ設定]プロファイルリンクを選択します)。
 検証プロセスタブ検証プロセスの一般情報タブにプロセスの詳細ページが開きます。
検証プロセスタブ検証プロセスの一般情報タブにプロセスの詳細ページが開きます。 検証プロセスの一般情報タブ
検証プロセスの一般情報タブ - [検証プロセス]のタブ(一般情報、タスクリスト、タスクパラメーター)を選択して、必要に応じて検証の詳細を編集し、変更する情報にアクセスします。タスクリストタブでは、次の表で説明する検証タスクを次のように指定できます。
- [タスクの追加]リンクを使用して追加
- 行の[削除]アクションを使用して、既存のタスクリストから削除されました
- 上/下矢印を使用して行の順序を変更することにより、既存のタスクリストで優先順位を変更しました
MARC21書誌メタデータ設定検証タスクの概要および MARC21権限メタデータ設定検証タスクの概要の表で説明されている検証タスクは、 Marc21書誌一致検証、保存時のMarc21書誌検証 、Marc21権限 一致検証、および保存時のMarc21 権限 検証 の検証プロセスでそれぞれ利用可能です。MARC21書誌メタデータ設定検証タスクの概要 検証タスク 説明 MARC21認識フィールド検証 すべてのフィールドがプロファイルによって認識されることを検証します。 MARC21必須検証 必須フィールドの存在を検証します。 MARC21繰り返し可能検証 繰り返し可能なフィールドを検証します。 MARC21固定フィールド位置検証 コントロールフィールドの正当なデータを検証します。 MARC21変数フィールド検証 インジケータの正当なデータを検証します。 サブフィールドの認識検証MARC21 すべてのサブフィールドがプロファイルによって認識されることを検証します。 MARC21必須サブフィールド検証 必須サブフィールドの存在を検証します。 MARC21繰り返し可能サブフィールド検証 繰り返し可能なサブフィールドを検証します。 Marc21BibFindMatchesValidationTask Marc21Bibは、一致する検証があるかどうかを確認します。 MARC21サブフィールド単語データ検証 単語データを検証します。 代替グラフィック表記の検証 代替グラフィック表記を検証します。 Bib_Headingの典拠形を検証する 書誌の標目が許可されているかどうかを検証します。 このタスクを使用して、ローカル請求番号がリポジトリ内のすべての書誌レコードで一意であることを確認します。
このタスクでは、([タスクパラメーター]タブから)次のタスクパラメーター、090、091、092、093、094、095、096、097、098、 099、および905を指定できます。
 ローカル請求記号の一意性を検証する
ローカル請求記号の一意性を検証するデフォルトでは、すべての09Xフィールドが指定されます。リストに905を追加することも選択できます(905の$sを検証します)。
ドロップダウンリスト全体を表示するときに、値を選択してチェックマークを削除または追加し、一意性を検証する09Xフィールドを示します。
すべての09Xフィールドが選択されているわけではない場合、一意性チェックは他の書誌レコードの同じ09Xフィールドに対して行われます。したがって、たとえば、請求番号検証リストの書誌フィールドで093フィールドを選択すると、検証チェックはリポジトリ内の他のすべての書誌093フィールドを比較して、重複した請求番号があるかどうかを判断します。
すべての09Xフィールドが選択されている場合、一意性チェックは他の書誌レコードの09Xフィールドに対して行われます。したがって、たとえば、書誌レコードの093フィールドにローカル請求番号が格納されている場合、検証チェックはリポジトリ内の他のすべての書誌09Xフィールド(093フィールドだけでなく)の比較を行い、重複する請求番号があるかどうかを判断します。
ショートカットとして、09Xフィールドの横にあるxを選択して、リストから削除できます。
詳細については、 メタデータエディタ(.docxファイル)でレコードを保存するときに090請求番号の一意性を確認する方法 を参照してください。
「その他の標準番号」チェックディジットを検証する
MARC21書誌プロファイルを設定する際に、 この検証タスクを選択して、フィールド024の次の その他の標準番号IDを検証します。
- UPC (第1インジケーター= 1)
- ISMN (第1インジケーター= 2)
- IAN (第1インジケーター= 3)
「その他の標準番号」検証チェックディジット 検証タスクを[タスクリスト]タブのタスクリストに追加した後、[タスクパラメータ]タブを選択し、024フィールドで検証するサブフィールドを特定します。複数のサブフィールドを指定する場合は、コンマで区切り、スペースを入れずにサブフィールドを入力してください。
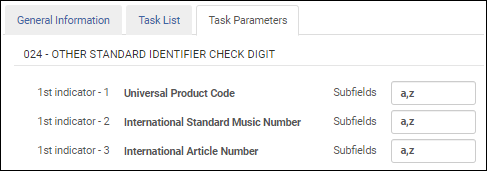 その他の標準番号検証タスクパラメータ-MARC 21 / KORMARC
その他の標準番号検証タスクパラメータ-MARC 21 / KORMARCISBNチェックディジットを検証する
この検証タスクを選択して、国際標準図書番号(ISBN)を検証します。
ISBN 検証チェックディジット 検証タスクを[タスクリスト]タブのタスクリストに追加したら、[タスクパラメータ]タブを 選択し、フィールドとサブフィールド に追加を選択して、検証するフィールド/サブフィールドを識別します。複数のサブフィールドを指定する場合は、コンマで区切り、スペースを入れずにサブフィールドを入力してください。
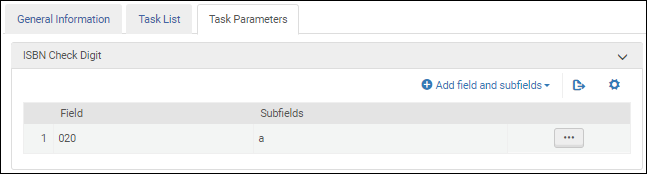 ISBN検証タスクのパラメーター-MARC 21 / KORMARC
ISBN検証タスクのパラメーター-MARC 21 / KORMARC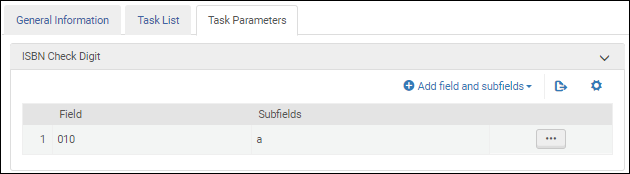 ISBN検証タスクのパラメーター-UNIMARC / CNMARC
ISBN検証タスクのパラメーター-UNIMARC / CNMARC新しいMARC21書誌の空のフィールドを検証する (これは、KORMARC、UNIMARC、およびCNMARCの書誌メタデータ設定プロファイルでも使用可能です。)
新しいMARC21書誌の空のフィールドを検証タスクを検証タスクリストに追加したら、[タスクパラメーター]タブを選択し、検証する空のフィールドを特定します。 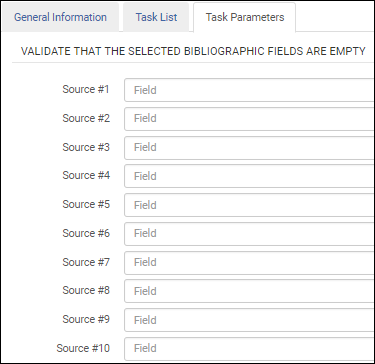 空として検証するフィールド
空として検証するフィールドこの検証チェックに特別なエラーまたは警告メッセージを設定するには、検証例外プロファイルを作成する必要があります。詳細については、検証例外プロファイルの操作を参照してください。
この検証チェックは、更新中の既存のレコードではなく、新しいレコード専用です。
検証プロセスを使用する各機能(MDエディタ、API、インポート、注文明細、クイック目録)に対して、検証により[タスクパラメーター]タブで指定されたフィールドが空でないことが識別されると、エラーまたは警告メッセージが表示されます。たとえば、MDエディタでは、[タスクパラメーター]タブで確認するフィールドとして009が設定されている場合、メッセージは次のように表示されます。
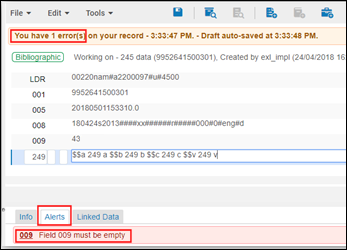 空でないフィールドの検証メッセージ
空でないフィールドの検証メッセージMARC21資料の検証フォーム
006フィールド(位置0)の資料のフォームがリーダー(LDR)の資料タイプと一致することを検証します。
ISSNチェックディジットを検証する
この検証タスクを選択して、国際標準シリアル 番号(ISBN)を検証します。
ISSN 検証チェックディジット 検証タスクを[タスクリスト]タブのタスクリストに追加したら、[タスクパラメーター]タブを選択し、 [フィールドとサブフィールドの追加] を選択して、検証するフィールド/サブフィールドを特定します。複数のサブフィールドを指定する場合は、コンマで区切り、スペースを入れずにサブフィールドを入力してください。
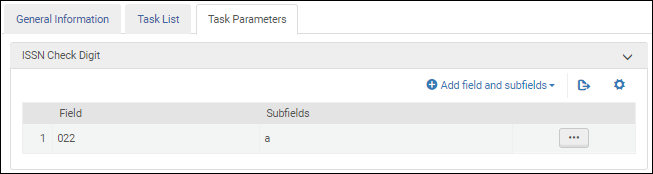 ISSN検証タスクパラメータ-MARC 21 / KORMARC
ISSN検証タスクパラメータ-MARC 21 / KORMARC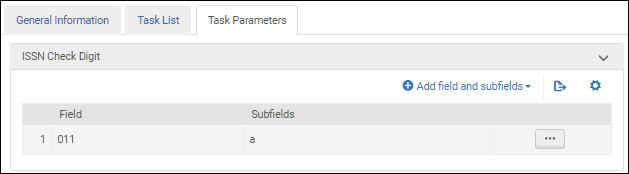 ISSN検証タスクのパラメーター - UNIMARC / CNMARC
ISSN検証タスクのパラメーター - UNIMARC / CNMARCUPCチェックデジットを検証する
UNIMARC 書誌プロファイルを設定する場合、 この検証タスクを選択して、ユニバーサル製品コード(UPC)を検証します。
UPCチェックディジット検証 検証タスクを[タスクリスト]タブのタスクリストに追加したら、[タスクパラメーター]タブを 選択し、[フィールドとサブフィールドの追加] を選択して、検証するフィールド/サブフィールド を特定します。複数のサブフィールドを指定する場合は、コンマで区切り、スペースを入れずにサブフィールドを入力してください。
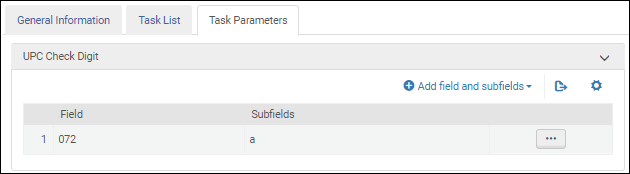 ユニバーサル製品コード検証タスクのパラメーター - UNIMARC / CNMARC
ユニバーサル製品コード検証タスクのパラメーター - UNIMARC / CNMARCISMNチェックディジットを検証する
UNIMARC書誌プロファイルを設定している場合、 この検証タスクを選択して、国際標準音楽番号 (ISMN)を検証します。
ISMNチェックディジットの検証 検証タスクを[タスクリスト]タブのタスクリストに追加したら、[タスクパラメーター]タブを 選択し、[フィールドとサブフィールドの追加] を選択して、検証するフィールド/サブフィールド を特定します。複数のサブフィールドを指定する場合は、コンマで区切り、スペースを入れずにサブフィールドを入力してください。
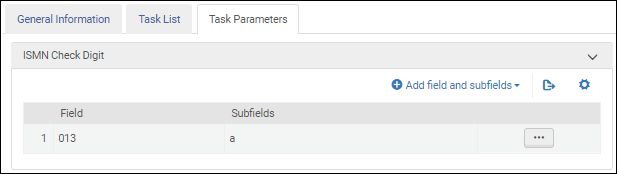 国際標準音楽番号検証タスクのパラメーター-UNIMARC / CNMARC
国際標準音楽番号検証タスクのパラメーター-UNIMARC / CNMARCIANチェックディジットの検証 検証タスクを[タスクリスト]タブのタスクリストに追加したら、[タスクパラメーター]タブを選択し、[フィールドとサブフィールドの追加] を選択して、検証するフィールド/サブフィールド を特定します。複数のサブフィールドを指定する場合は、コンマで区切り、スペースを入れずにサブフィールドを入力してください。
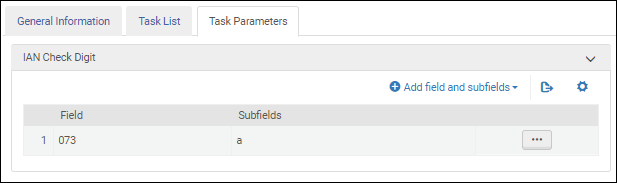 国際記事番号検証タスクのパラメーター - UNIMARC / CNMARC
国際記事番号検証タスクのパラメーター - UNIMARC / CNMARC - [一般情報]タブ、[タスクリスト]タブ、および[タスクパラメータ] タブでプロセスの詳細の変更が終了したら、[保存]を選択します。
検証例外プロファイルの使用
- MARC XML書誌インポート - この例外プロファイルを選択して、インポート中の無効なデータを処理することをお勧めします。
- 保存時にMARC XML書誌メタデータを編] - この例外プロファイルは、外部リソース(WorldCatやLoCなど)を介して目録をコピーするとき、およびメタデータエディタで書誌レコードを保存するときに使用されます。
検証プロファイル(検証プロセスの編集を参照)とは異なり、デフォルトの動作を定義し、 その動作の例外を定義することもできます。ページの上部セクションでは、デフォルトの重大度を指定します。 これは、レコードで見つかったすべての 検証問題のデフォルトの重大度です。下部のセクションでは、そのデフォルトの 例外を指定できます。これらは、 デフォルトとは逆の方法で処理するルールです。以下のスクリーンショットでは、デフォルトが「警告」に設定されているため、例外リストのすべてがエラーとして扱われます。これは、デフォルトの例外であるためです。
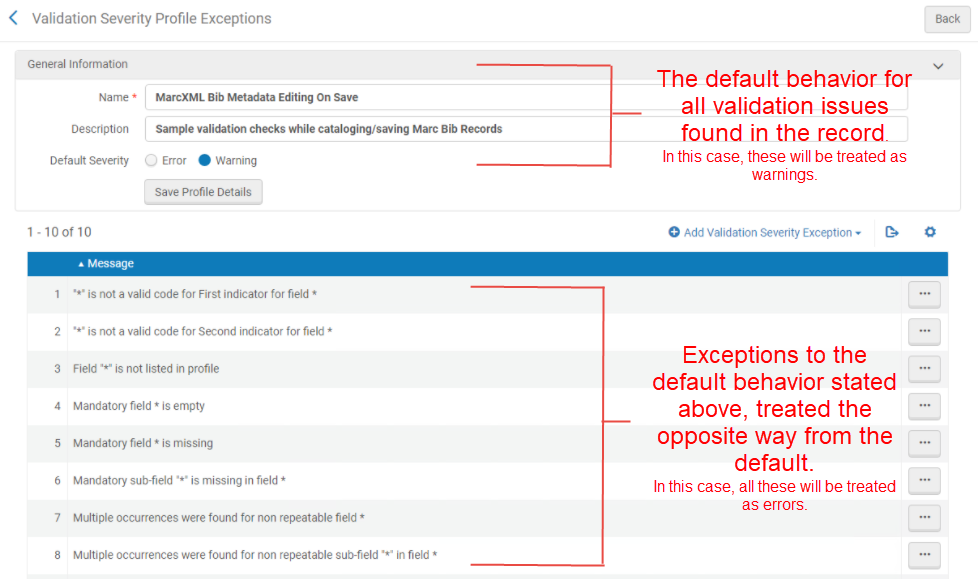
このページでは、既存のプロファイルを編集またはコピーすることもできます。作成したプロファイルは削除できます。
検証例外プロファイルの追加
- [プロファイルの詳細]ページ([設定メニュー > リソース > 目録 > メタデータ設定]でプロファイルリンクを選択)で、[検証例外プロファイルリスト]タブを選択します。 [検証重大度プロファイルの追加]を選択します。
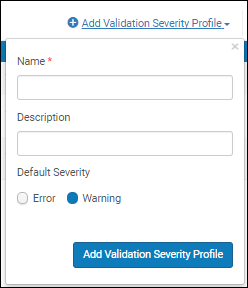 既存の検証例外プロファイルをコピーして変更し、 新しいプロファイルを作成するには、行の [コピー]アクションを選択し、要件に一致するように重複 プロファイルを変更します(検証例外プロファイルの編集を参照)。
既存の検証例外プロファイルをコピーして変更し、 新しいプロファイルを作成するには、行の [コピー]アクションを選択し、要件に一致するように重複 プロファイルを変更します(検証例外プロファイルの編集を参照)。 - 検証例外プロファイルに次を入力します。
- 追加する重大度検証プロファイルの名前(必須)と説明
- [エラー]または[警告]を選択して、デフォルトの重大度を示します。デフォルトの重大度は、[フィールド]タブで定義されたフィールドレベルパラメーターの違反(必須、繰り返し不可など)を警告(オーバーライド可能)またはエラー(解決する必要がある)として扱うかどうかを決定します。
- [検証重大度プロファイルの追加]を選択します。プロファイルは、検証例外プロファイルのリストに追加されます。検証例外プロファイルへのメッセージの追加については、検証例外プロファイルの編集を参照してください。
検証例外プロファイルの編集
- プロファイルの詳細ページの[検証例外プロファイルリスト]タブ([設定メニュー > リソース > 目録 > メタデータ設定]からプロファイルリンクを選択)で、更新する検証例外プロファイルの行の[編集]アクションを選択します。
- [一般情報]領域で、必要に応じて名前、説明、またはデフォルトの重大度を変更します。
- メッセージ領域で、行の[削除]アクションを選択して、不要なメッセージを削除します。
- [検証の重大度の例外を追加]を選択し、[メッセージ]ドロップダウンリストから検証の例外メッセージを選択します。
[メッセージ]ドロップダウンリストのメッセージの構文は設定できません。 - [検証の重大度の例外を追加]を選択します。
- [プロファイルの詳細を保存]を選択し、[戻る]を選択します。
その他の設定
- [簡易レベルルール]を選択します(メタデータ設定でブリーフレベルルールのデフォルトを設定するを参照)
- レコードを保存するときに特定の方法で特定のフィールドを処理するパラメーターを選択します(他の設定パラメーターの設定を参照)。
その他の設定パラメーターの設定
- 003削除を無効にする - レコードを保存するときに003フィールドの内容を維持するには、このパラメーターを選択します。このパラメーターが選択されていない場合、レコードが保存される際にデフォルトで、内容を001フィールドのMMS IDと連結して003フィールドを削除し、035フィールドに配置される(OCoLC)35397863のようなIDを作成します。
- MMS IDに基づいて035の生成を除外する - レコードを保存するときに、035フィールドの自動生成をオフにし、003フィールドの内容と001フィールドのMMS IDを連結しないようにするには、このオプションを選択します。
- 001からのみ035を生成 - (UNIMARC書誌および典拠メタデータ設定プロファイルのみ)レコードを保存するときに、001フィールド(MMS ID)の内容から035フィールドを作成するには、このオプションを選択します。
 UNIMARCのメタデータ設定のその他の設定タブ
UNIMARCのメタデータ設定のその他の設定タブ - 代替グラフィック表記スクリプトコードの追加 - このパラメーターを使用して、880の作成時に$6のリンク先スクリプト言語指示を追加または省略します。このパラメータを選択すると、880フィールドの$6にスクリプト言語インジケータが追加されます。詳細については、書誌レコード内のリンクされた880フィールドの操作を参照してください。
UNIMARCフィールド、正規化、検証の操作
- [メタデータ設定リスト]ページ([設定メニュー > リソース > 目録 > メタデータ設定])で[UNIMARC書誌リンク]を選択します。[プロファイルの詳細]ページが表示されます。
- [正規化プロセス]タブを選択します。次のデフォルトの正規化プロセスが[正規化プロセス]タブに表示されます。
- UNIMARC書誌の初期正規化
- 保存時のUNIMARC書誌正規化
- UNIMARC書誌の再シーケンス
- UNIMARC書誌の再シーケンスおよび空白フィールドのクリア
- 正規化プロセスのいずれかの行アクションリストから[編集]選択し、[タスクリスト]タブを選択して、提供されているUNIMARCタスクを表示します。詳細については SBNまたはUNIMARCのタスクUnimarcBibAdd005Taskの設定を参照してください。
- 終了したら、[保存]を選択してください。
- [メタデータ設定リスト]ページ([設定メニュー > リソース > 目録 > メタデータ設定])で[UNIMARC書誌リンク]を選択します。[フィールド]タブで[プロファイルの詳細]ページが開きます。
- 9XXフィールドの1つを見つけます。
- 行アクションリストから[カスタマイズ]を選択して、カスタマイズに使用可能なサブフィールドとインジケータを表示します。
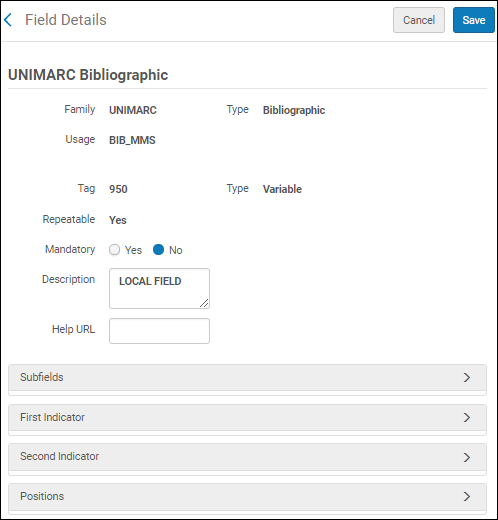 UNIMARCフィールドの詳細
UNIMARCフィールドの詳細 - サブフィールド、ファーストインジケータ、およびセカンドインジケーターセクションを展開して、カスタマイズ可能なオプションを表示します。
- [メタデータ設定リスト]ページ([設定メニュー > リソース > 目録 > メタデータ設定])で[UNIMARC書誌リンク]を選択します。[フィールド]タブで[プロファイルの詳細]ページが開きます。
- [1XX:コード化情報ブロック]オプションを選択して、[フィールド]タブでフィルタします。
- フィールド100の場合、行アクションリストから[表示]を選択します。[フィールドの詳細]ページが表示されます。
- [位置]セクションを展開して、検証されている位置を表示します。 次の位置検証がUNIMARCに追加されました。
- ファイルに入力された日付
- 発行日の種類
- 発行日1
- 発行日2
- 終了したら、[メタデータ設定リスト]ページに戻るまで[戻る]を選択してください。
UNIMARCローカル典拠レコードの管理
- [メタデータの設定リスト]ページ([設定メニュー > リソース > 目録 > メタデータの設定])内の[ローカル典拠を追加]を選択します。[ローカル典拠の追加]ポップアップウィンドウが表示されます。
- UNIMARCローカル典拠プロファイルに必要なパラメータを完了します。
- [名前] – プロファイルのローカル典拠レジストリページに表示する単語名を入力します。
- [コード] - たとえば、インポートプロファイルを設定するときに表示する単語コード名を入力します。
- [ファミリー] – ドロップダウンリストからUNIMARCを選択します。
- [タイプ] – ドロップダウンリストから次のタイプのいずれかを選択します。
- [件名]
- [著者]
- [著者と件名]
- [分類]
- [ダイレクトIDプレフィックス] – IDプレフィックスを使用する場合は入力します。
- [多言語] – ドロップダウンリストから[はい]または[いいえ]を選択します。
- [追加して閉じる]を選択します。作成したローカル認証レジストリは、[ローカル認証レジストリ]ページのリストに表示されます。
- [保存]を選択してください。[メタデータ設定リスト]ページのリストにローカル認証プロファイルが表示されます。
- [UNIMARC典拠]リンクを選択して、詳細プロファイルページを開き、MARC 21と同様のフィールド、正規化、検証を設定します。
- プロファイルの詳細情報を変更する完了したら[配置]を選択します。
KORMARCフィールド、正規化、および検証の操作
- [メタデータ設定リスト]ページを開きます([設定メニュー > リソース > 目録 > メタデータ設定])。
- [KORMARC書誌]リンクを選択します。[プロファイルの詳細]ページが表示されます。
- [正規化プロセス]タブを選択します。次のデフォルトの正規化プロセスが[正規化プロセス]タブに表示されます。
- 保存時にKORMARC書誌を正規化
- KORMARC書誌の再シーケンス
- KORMARC書誌の再シーケンスおよび空白フィールドのクリア
- 正規化プロセスのいずれかの行アクションリストから[編集]を選択し、[タスクリスト]タブを選択して、提供されているKORMARCタスクを表示します。
- 終了したら、[保存]を選択してください。
CNMARCフィールド、正規化、および検証の操作
- [メタデータ設定リスト]ページを開きます([設定メニュー > リソース > 目録 > メタデータ設定])。
- [CNMARC書誌]リンクを選択します。[プロファイルの詳細]ページが表示されます。
- [正規化プロセス]タブを選択します。次のデフォルトの正規化プロセスが[正規化プロセス]タブに表示されます。
- CNMARC書誌の初期正規化
- 保存時にCNMARC書誌を正規化
- Z39.50/SRU検索におけるCNMARC書誌の正規化
- CNMARC書誌の再シーケンス
- CNMARC書誌の再シーケンスおよび空白フィールドのクリア
- 正規化プロセスのいずれかの行アクションリストから[編集]を選択し、[タスクリスト]タブを選択して、提供されているCNMARCタスクを表示します。正規化タスクの説明については、タスクリストオプションの表を参照してください。
- 終了したら、[保存]を選択してください。
MODSフィールド、正規化、および検証の操作
- [メタデータ設定リスト]ページを開きます([設定メニュー > リソース > 目録 > メタデータ設定])。
- MODSリンクを選択します。[プロファイルの詳細]ページが表示されます。
- [正規化プロセス]タブを選択します。次のデフォルトの正規化プロセスが[正規化プロセス]タブに表示されます。
- 書誌をコレクションに追加する
- 保存時のMODS書誌正規化
- ディスカバリMODSから書誌レコードを抑制する
- 正規化プロセスのいずれかの行アクションリストから[編集]を選択し、[タスクリスト]タブを選択して、提供されているMODSタスクを表示します。
- プロセスにタスクを追加するには、「タスクの追加」を選択します。次の表に、使用可能なMODSタスクを示します:
タスク 説明 ModsDroolNormalization タスクパラメータタブから実行する正規化ルールを選択します。 addBibToCollectionNormalizationTask 書誌レコードをコレクションに追加する MmsTagSuppressed MMS MODSの抑制フラグを設定します 移行タスクを処理する 書誌Bレコードのメタデータからハンドルをレコードのハンドル識別子フィールドにコピーします。 MMS IDを使用してレコード識別子を更新する MMS IDを使用してレコード識別子を更新します。 recordIdentifier要素のレコード変更チェックボックス を選択して、 recordIdentifier 要素の recordinfoNote 要素の変更を記録します。 - 追加するタスクを選択します。
- 完了したら、追加して閉じる選択して保存を選択します。
Dublin Coreフィールド、正規化、および検証の操作
- [メタデータ設定リスト]ページを開きます([設定メニュー > リソース > 目録 > メタデータ設定])。
- [認定Dublin Core]リンクを選択します。[プロファイルの詳細]ページが表示されます。
- [正規化プロセス]タブを選択します。次のデフォルトの正規化プロセスが[正規化プロセス]タブに表示されます。
- 書誌をコレクションに追加する
- 保存時の認定DC書誌の正規化
- Z39.50/SRU検索における認定Dublin Core書誌の正規化
- 正規化プロセスのいずれかの行アクションリストから[編集]を選択し、[タスクリスト]タブを選択して、提供されているDublin Coreタスクを表示します。
- 終了したら、[保存]を選択してください。
DCアプリケーションプロファイルの操作
- MDエディタで、Dublin Coreレコードにフィールドを追加するとき([リソース > メタデータエディタを開く])。
- [レコード形式]フィールドで、[レコード形式]フィールドに表記を追加する場合([リソース > デジタル表記を追加])。
- [レコード形式]フィールドで、新しいコレクションを追加するとき([リソース > コレクションの管理])。
- インポートプロファイルを設定するときの[ターゲット形式]フィールド([リソース > インポートプロファイルの管理])。
- [フィールドを含める書誌レコード形式]で、デジタルタイトルのエクスポートジョブを実行する場合([管理 > ジョブの実行])。
- Almaに表示されるメタデータを設定するエリア
- 検索インデックスで、Almaリポジトリで検索可能なフィールドを設定します( [設定 > リソース > 検索設定 > 検索索引])。
- [配信プロファイルメタデータ]で、デジタルビューアでデジタルコンテンツを表示するときに表示されるメタデータフィールドを設定します(設定 > フルフィルメント > 配信プロファイルメタデータ)。
DCアプリケーションプロファイル - 一般情報タブ
DCアプリケーションプロファイルへのフィールドの追加
- [標準] – 標準の認定DCフィールドを追加します。以下が表示されます。
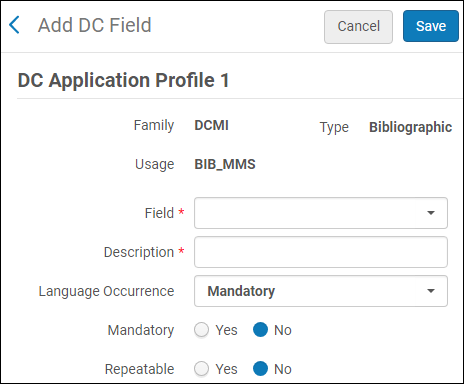 標準フィールドを追加
標準フィールドを追加- [フィールド]ドロップダウンリストから、認定DCフィールドを選択します。
- フィールドの説明を入力します。
- 言語オカレンスを選択します。
- フィールドを必須にする場合は、[はい/いいえ]を選択します。
- フィールドを繰り返し可能にする場合は、[はい/いいえ]を選択します。
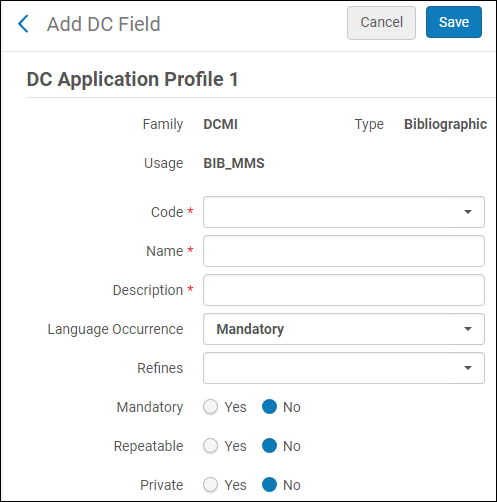
- ローカル - ローカルDCフィールドを追加します。以下が表示されます。
 ローカルフィールドを追加
ローカルフィールドを追加- [コード]フィールドから、ローカルDCフィールドのコードを選択します。
- ローカルDCフィールドの名前を入力します。
- ローカルDCフィールドの説明を入力します。
- 言語オカレンスを選択します。
- [絞り込み]フィールドから、エクスポート時にローカルフィールドの値を含む単純なDCフィールドを選択できます。
- フィールドを必須にする場合は、[はい/いいえ]を選択します。
- フィールドを繰り返し可能にする場合は、[はい/いいえ]を選択します。
- フィールドをプライベートにする場合は、[はい/いいえ]を選択します。[はい]を選択すると、フィールドはエクスポートされません。(ただし、索引は作成されます)
- ローカルフィールドを構成できるすべてのプロファイル(DCAP1、DCAP2、ETD)全体で、合計50個のローカルフィールドを追加できます。
- 各ローカルフィールドは、すべてのプロファイルにわたって1回だけ構成します。つまり、複数のプロファイルで同じローカルフィールドコードを繰り返さないでください。
GND典拠プロファイルの使用
- GNDレコードを見つけやすくする検索インデックス(GND典拠検索索引マッピングセクションを参照)
- 目録化をサポートするフィールド/サブフィールドの定義
- 必須の定義を含む、定義済みのすべてのGNDフィールド
- GND語彙制御が配置済み
- 特定の正規化ルール
MARC 21所蔵プロファイルの操作
- [フィールド]
- [正規化プロセス]
- [検証プロセス]
- [検証例外プロファイルリスト]
MDエディタ内のグローバル典拠の表示とアクセスの管理
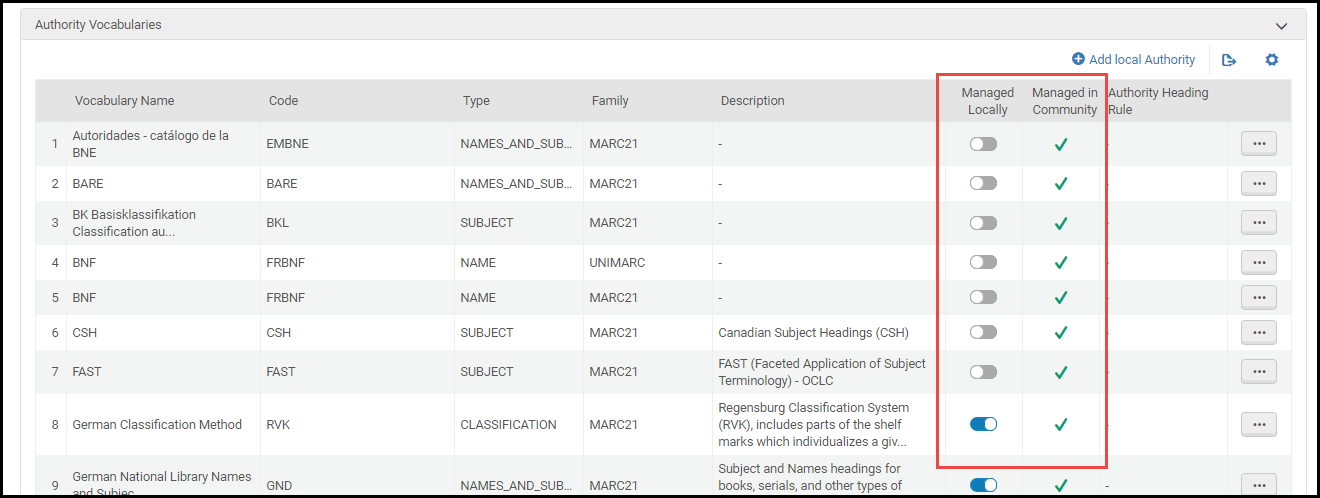
- ローカルで管理 [ローカルで管理]列を使用すると、MDエディタに表示する典拠単語を特定できます。これを行うには、この列の単語を有効化または無効化します。
- コミュニティで管理 [コミュニティで管理]列は、コミュニティゾーンで維持されている単語を識別します。この列は情報提供のみを目的としています。この列の単語行を有効化または無効化するオプションはありません。
- MDエディタの[テンプレート]タブと[レコード]タブ
- MDエディタの[ファイル > 新規]レコードオプション
- [インポートプロファイルの詳細]ページのオプションの[単語コード]パラメータのドロップダウンリスト
- [メタデータ設定リスト]ページを開きます([設定メニュー > リソース > 目録セクション > メタデータ設定])。[メタデータ設定リスト]ページが表示されます。< MDエディタの[ファイル>新規]オプションリストには、メタデータ設定で[ローカルで管理]として識別された単語オプションが表示されます。
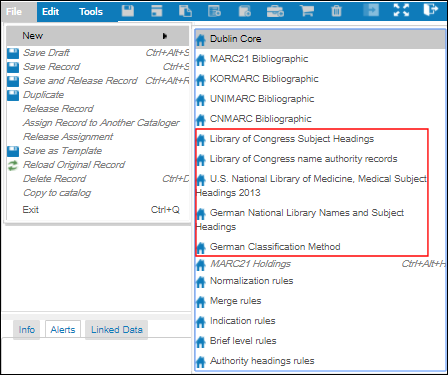 MDエディタの典拠単語オプション
MDエディタの典拠単語オプション - [ローカルで管理]列の単語を有効化して、MDエディタ(およびインポートプロファイル)に表示する単語を特定します。
語彙の制御レジストリの設定
- 目録管理者
- 統括システム管理者
- 語彙制御を作成します。
- 語彙制御を特定のMARC21サブフィールドに割り当てます。
- 語彙制御の詳細を表示する(行のアクションリストから[表示]を選択します)
- 語彙制御の追加(語彙制御の追加/編集を参照)
- 語彙制御コード値の追加または削除(語彙制御の追加/編集を参照)
- 事前定義済みの語彙制御を復元します(行アクションリストから[復元]を選択します)
- 追加した語彙制御を削除します(行アクションリストから[削除]を選択します)
語彙制御を追加/編集します
- [語彙制御レジストリ]ページで([設定メニュー > リソース > 目録 > 語彙制御レジストリ])、[語彙制御を追加]を選択します。[語彙制御詳細]ページが開きます。
- 名称と説明を入力します。 この名前と説明は、メタデータ設定プロファイルのMARC 21サブフィールドに語彙制御を割り当てると、[語彙制御レジストリ]ページと[語彙制御の選択]のオプションのドロップダウンリストに表示されます。上記のフィールドの編集のステップ4を参照してください。語彙制御をMARC 21サブフィールドに割り当てた後でのみ、以下のステップ4に示すように、この単語をMDエディタで使用できることに注意してください。
- 語彙制御名を少なくとも1つ追加したら、[保存]を選択して、説明への変更を保存します。
- [新しい値の追加]領域で、コードと説明を入力します。コードにはスペースまたは特殊文字を含めることができますが、サブフィールドの区切り文字を含めることはできません。 入力するコードは、MDエディタでレコードを入力するときに、検証またはオプションとして提供される用語です。
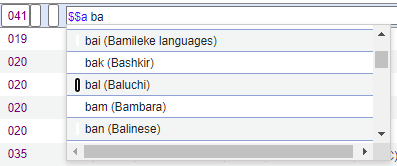 制御語彙例上記の例では、入力したコードは各行の最初に表示され、説明は各コードの右側の括弧内に表示されます。CVレジストリに入力するコードの説明は、入力した用語に関する追加情報を提供できます。
制御語彙例上記の例では、入力したコードは各行の最初に表示され、説明は各コードの右側の括弧内に表示されます。CVレジストリに入力するコードの説明は、入力した用語に関する追加情報を提供できます。 - [追加]を選択します。 コード値は、語彙制御レジストリのリストに追加されます。
- ステップ3と4を繰り返して、追加のコード値(用語)を追加します。
- コードを削除する場合は、コード値の横にある[削除]を選択します。事前定義済みの語彙に元々含まれていたコード値を削除しようとすると、警告が表示されます。
- [キャンセル]を選択して、[語彙制御レジストリ]ページに戻ります。
- [語彙制御レジストリ]ページ([設定メニュー > リソース > 目録 > 語彙制御レジストリ])で、[アクション > 設定]または[アクション > 編集]を選択します。[語彙制御詳細]ページが開きます。
- 上記の手順3から開始して、説明されている手順を続行します。
語彙の制御レジストリの設定 - フォーム
- 目録管理者
- 統括システム管理者
- [語彙の制御レジストリ - フォーム]ページで([設定メニュー] > [リソース] > [目録] > [語彙の制御レジストリ - フォーム])、[語彙の制御を追加する]を選択します。[語彙制御詳細]ページが開きます。
- 名前と説明を入力します。この名前と説明は、フォームを設定する際の語彙のための[語彙の制御レジストリ - フォーム]ページおよびオプションのドロップダウンリストに表示されます。
- 語彙の制御レジストリ - フォーム ページから、語彙を選択します。
- 行を追加を選択します。
- コードと説明を入力し、必要に応じてデフォルト値を選択します。 この コードは、フィールドでユーザーにオプションとして提供される用語です。
- [行を追加する]を選択します。
- 追加の行を追加して追加の値を 語彙に追加します。
著者番号リストの設定
- 目録管理者
- 統括システム管理者
標準著者番号リストの設定
- cutting_three_figure_cn.txt
- cutting_three_figure_kor.txt
- lee_jai_chul_1.txt
- lee_jai_chul_2.txt
- lee_jai_chul_3.txt
- lee_jai_chul_4.txt
- lee_jai_chul_5.txt
- lee_jai_chul_6.txt
- lee_jai_chul_7.txt
- lee_jai_chul_8.txt
- 著者番号リストマッピング表([設定メニュー > リソース > 目録 > 著者番号リスト])で、使用する著者番号マッピング表を含む行で、[カスタマイズ]アクションを選択します。マッピングテーブルの詳細については、マッピングテーブルを参照してください。
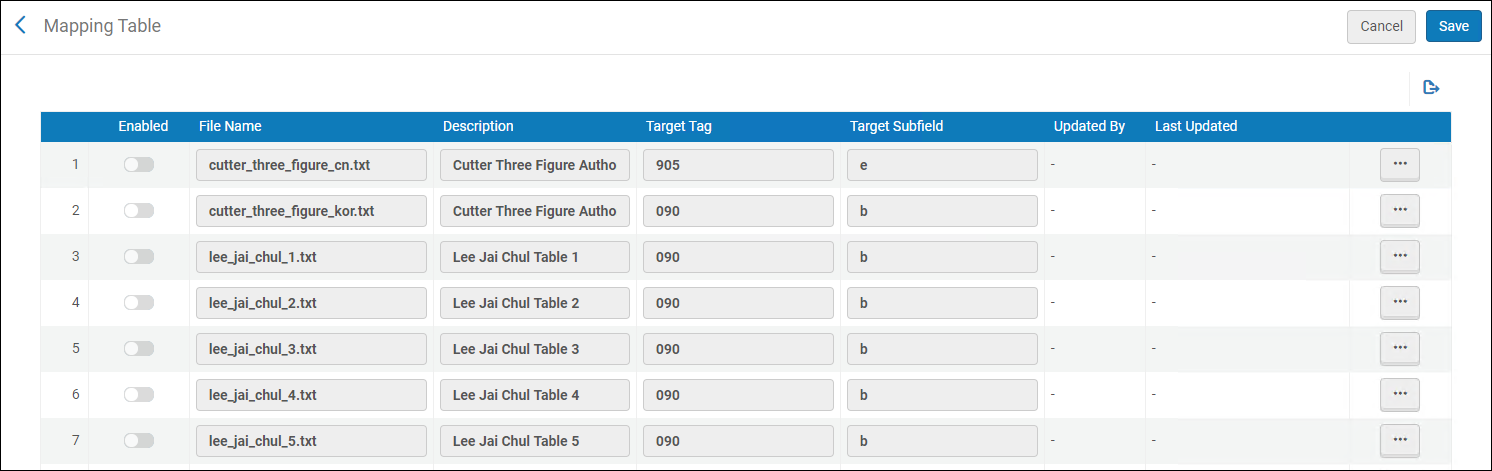 著者番号リストマッピング表ページ
著者番号リストマッピング表ページ - ターゲットタグとターゲットサブフィールドオプションが要件に合わせてカスタマイズされていることを確認します。必要に応じて変更を加えます。
- [保存]を選択してください。
Lee Jai Chul メソッドロジック
Lee Jai Chulメソッドは、次のロジックを使用してAlmaで実装されています。
- 韓国語の著者名は、カーソルが置かれているフィールドに存在すると想定されます。このフィールドに名前が見つからない場合、著者番号は生成されません。
- 著者名の最初のハングル文字が保存され、ハングルの子音と母音のテーブルを使用して、著者名の2番目のハングル文字がハングル・ジャモ文字に分解されます(도 > ㄷ ㅗなど、ハングルごとに2つまたは3つのジャモ文字)。著者名の最初の文字が最も人気のある姓の1つである場合、最初のJamo(子音)と2番目のJamo(母音)のマッピング表のコードが連結されます。それ以外の場合、コードは最初のJamoのマッピング表から取得されます。
- 生成された著者番号は、前の箇条書きで説明した最初と2番目のハングル文字の操作の結果である文字列です。この文字列は、[著者番号リスト]設定で識別されるフィールド/サブフィールドに配置されます。
- 著者番号は、生成後に目録者によって変更される場合があります。
- (著者の姓の) Lee Jai Chulメソッド に対してEx Librisによって設定されたパラメーターにアスタリスク(*)が含まれている場合、すべての名前が 最も人気があると見なされます。
このロジックには次の例外があります。
- Lee Jai Chulメソッドの5番目、6番目、または8番目の表が使用され、最初のJamoがㄱである場合、2番目のJamoは、最初の文字が最も人気のある姓の1つであってもコーディングされます。たとえば、5番目のテーブルを使用する場合、추경석>추14(「추1」ではありません)。
- 最初のJamoの数値コードが2桁の場合、2番目のコードにコードを割り当てる必要はありません。たとえば、2番目のテーブルを使用する場合、정필모 > 정84。
- 著者名がコンマで区切られている場合、コンマとその後のスペースは生成された著者番号にコピーされます。たとえば、5番目のテーブルを使用する場合、맨、마가레트 > 맨、3。
- 保存プロセスの検証でユーザー定義の請求番号区別タスクが設定されている場合(保存時のMARC 21所蔵の検証を参照)、リポジトリ全体で同一の著者番号に対して重複チェックが実行されます。重複が見つかった場合、システムは目録者にメッセージを表示します。
- 一部のテーブルには、依存関係があり、考慮に入れられます。たとえば、3番目のテーブルを使用する場合
- 3 vㅏ-ㄱㄷㅊ1 つまり、最初のJamoの値がㄱ、ㄷ、またはㅊでない場合、2番目のJamoㅏのコードは1になります。
- 3 vㅓㄱㄷ3 つまり、最初のJamoの値がㄱまたはㄷの場合、2番目のJamoㅏのコードは3になります。
- 3 vㅏ-ㄱㄷㅊ1
著者番号リスト生成のための翻字のカスタマイズ設定
- ハングル(16進コードポイント)
- ローマ字ハングル
- 文字の説明
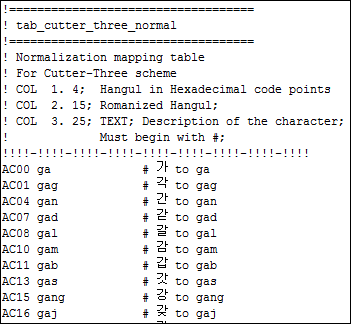
- [著者番号生成]の[ローカル翻字表設定オプション]を選択します([設定メニュー > リソース > 目録 > 著者番号生成のローカル翻字表])。local_transliteration_author_number.txtページが表示されます。
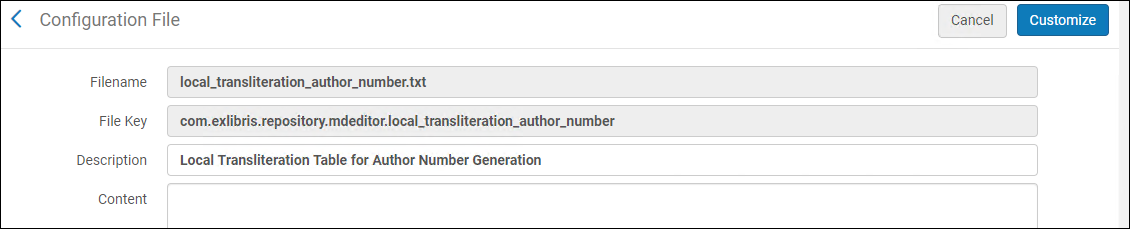 local_transliteration_author_number.txtページ
local_transliteration_author_number.txtページ - [コンテンツ]用に用意されたスペースにカスタム翻字変換ファイルをコピーして貼り付けます。
- [保存]を選択してください。
メタデータのインポートによって作成された新しいレコードに適用されるデフォルトの目録レベル
入力ファイルから新しいレコードが作成されるときは常に 、このレコードの目録レベルがデフォルトの目録レベル、またはデフォルトが定義されていない場合は「00」レベルになります。
「目録者権限レベル」設定でデフォルト値を設定することをお勧めします。詳細については、目録権限を参照してください。
外部管理典拠への投稿のための目録レベルの設定
- 目録者レベルから単語コードへのマッピング表([設定メニュー > リソース] > [目録] > [外部権限に対する目録レベルマッピング])で、[行の追加]を選択して、Alma目録レベルを外部システムの目録レベルにマッピングします。
- Alma目録レベルのいずれかを選択します。目録レベルは、目録者のアクセス許可レベルの設定によって決まります。詳細については、目録権限を参照してください。
- 外部システムの目録レベルのいずれかを入力して、選択したAlma目録レベルにマッピングします。
- TrueまたはFalseを選択して、レベルに対して作成しているマッピングがデフォルトであるかどうかを示します。 マッピングテーブルでは多対多の関係を指定できるため、 どちらがデフォルトのマッピングであるかを示す必要があります。
- 関連する単語を選択します。 現在のオプションは、GND、BARE、および NLIです。
- [行の追加]を選択します。
マッピングを変更する必要がある場合は、変更するマッピングの[削除]アクションを選択し、新しいマッピングを作成します。 - 設定の変更が完了したら、[保存]または[保存して配分]を選択します。ネットワーク管理の停止の説明など、詳細については、設定表の一元管理を参照してください。
CNMARC 6XXフィールドに対する複数のアクセスポイントの設定
- [リソース管理]設定の[目録]セクションで[複数のCNMARC 6XX標目の設定]を選択します([設定メニュー > リソース > 目録 > 複数のCNMARC 6XX標目の設定])。CNMARC 6XXカテゴリマッピング表が表示されます。マッピングテーブルの詳細については、マッピングテーブルを参照してください。
- [行の追加]を選択して、6XXフィールドとその説明を入力し、セグメント化する6XXフィールドの[行の追加]を選択します。
 CNMARC 6XXフィールドが追加されました
CNMARC 6XXフィールドが追加されました - CNMARC 6XXカテゴリマッピング表に追加するすべての6XXフィールドについて、手順2を繰り返します。
- 6XXフィールドの追加が終了したら、[カスタマイズ]を選択します。
UNIMARCに対する複数のアクセスポイントの設定
- [リソース管理]設定の目録セクションで[複数のUNIMARC典拠ID設定]を選択します([設定メニュー > リソース > 目録 > 複数のUNIMARC典拠ID設定])。複数の典拠レコードによって制御されるUNIMARC 6XXフィールドのリストが表示されます。マッピングテーブルの詳細については、マッピングテーブルを参照してください。
 UNIMARC 6XXフィールド
UNIMARC 6XXフィールド - 複数の典拠の識別に使用する6XXフィールドを有効化または無効化し、好みに合わせて説明フィールドを変更します。
- 終了したら、[カスタマイズ]を選択します。
MARCスリム設定
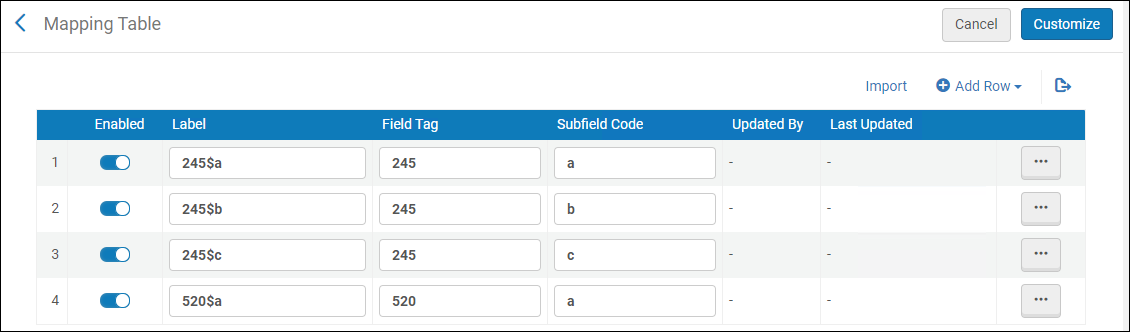
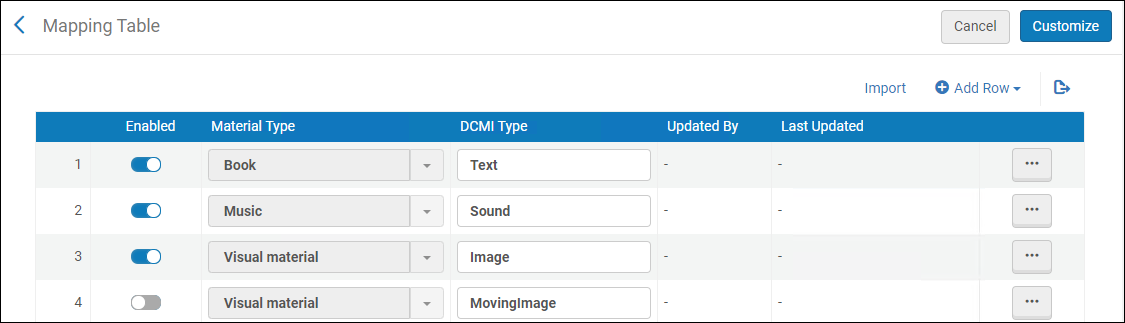
DCMI資料タイプマッピング
dc:typeおよびdcterms:typeフィールドで、Alma資料タイプをDCMIタイプにマップできます。これを行うには、[設定メニュー] > [リソース] > [目録] > [DCMI資料タイプマッピング]でDCMI資料タイプマッピング表を開きます。 マッピングテーブルの詳細については、マッピングテーブルを参照してください。