
Arbeiten mit CJK-Transliterationen in der Katalogisierung
Um Metadaten zu konfigurieren, müssen Sie eine der folgenden Rollen innehaben:
- Katalogisierer
- Katalog-Manager
- Katalog-Administrator
Für Institutionen, die CJK-Sprachen verwenden, wurden für die Katalogisierung von CJK-Datensätzen CJK-Transkriptionsfunktionen im Alma MD-Editor umgesetzt. Die Implementierung der CJK-Transkriptionsfunktion richtet sich insbesondere an:
- Hanja zu Hangul
- Hanja zu Hangul CK
- Hanja zu Hangul MOE
- Hanja zu Pinyin
- Hanja zu Pinyin
- Kana zu Hangul
- Kana zu romanisiertem Kana
- Voller und halbe Breite, Kana zu romanisiertem Kana (in einer kombinierten Transliteration)
Dies gilt für die Katalogisierung von Titelsätzen und Normdatensätzen und geschieht über die Verwendung von Normalisierungsprozessen, die Sie Ihren Bedürfnissen anpassen.
Für Informationen zur Konfiguration von Katalogisierungs-Normalisierungsprozessen für die CJK-Transkription siehe Arbeiten mit Normalisierungsprozessen.
Um Datensätze mithilfe der CJK-Transkription zu katalogisieren:
- Öffnen Sie den Titelsatz, den Sie transkribieren wollen, im MD-Editor.
- Erweitern Sie den Datensatz (Bearbeitungsaktionen > Datensatz erweitern). Das Dialogfenster Datensatz erweitern erscheint.
- Wählen Sie den Normalisierungsprozess, den Sie für die Transkription erstellt haben, aus der Dropdown-Liste und klicken Sie auf OK.
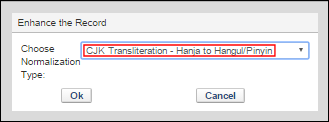 Auswahl des Normalisierungsprozesses zur Erweiterung des DatensatzesDer Datensatz wird geändert und zeigt die Transkription an. Der CJK-Text wird konvertiert und der lateinische Text bleibt in den neuen, transkribierten Datensätzen unverändert. Das System fügt auch automatisch Unterfeld 9 ($$9) zu den transkribierten Datensätzen hinzu, mit einem Hinweis auf die Art der Transkription, die durchgeführt wurde.
Auswahl des Normalisierungsprozesses zur Erweiterung des DatensatzesDer Datensatz wird geändert und zeigt die Transkription an. Der CJK-Text wird konvertiert und der lateinische Text bleibt in den neuen, transkribierten Datensätzen unverändert. Das System fügt auch automatisch Unterfeld 9 ($$9) zu den transkribierten Datensätzen hinzu, mit einem Hinweis auf die Art der Transkription, die durchgeführt wurde.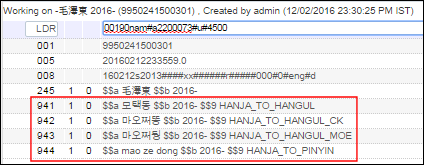 Transkription vollständig
Transkription vollständig - Speichern Sie den Datensatz.