
Arbeiten mit Titeldatensätzen
- Katalogisierer
- Katalogisierer, erweitert
- Katalog-Administrator
- Katalog-Manager
Erstellen von Titeldatensätzen
Erstellen eines MARC 21-Titelsatzes
- Öffnen Sie den Metadaten-Editor (Ressourcen > Katalogisierung > Metadaten-Editor öffnen).
- Klicken Sie auf Neu > MARC 21 Titeldaten-Felder und wählen Sie anschließend die Standardvorlage für die Eingabe eines Titelsatzes aus.
Der Metadaten-Editor öffnet diese Vorlage.
- Geben Sie die Daten für Ihren Titelsatz ein. Siehe den Abschnitt Menü- und Werkzeugleisten-Optionen des Metadaten-Editors020Navigieren auf der Seite MD-Editor#MD_Editor_Menu_and_Toolbar_Options für zusätzliche Informationen zur Arbeit mit dem Metadaten-Editor.
Für Informationen zur Eingabe von Datensatz-Inhalten in Hebräisch siehe Richtungszeichen anzeigen und Richtungszeichen einfügen.
Für weitere Informationen zur Katalogisierung in Hebräisch siehe Spezialthemen zur Hebräischen Katalogisierung.Wenn Sie die Felder 010 oder 035 katalogisieren, geben Sie ein Raute-Zeichen (#) für jedes Leerzeichen ein, das Sie für dieses Feld speichern wollen. Der Inhalt wird von der Alma-Datenbank als Leerzeichen (für jedes eingegebene Raute-Zeichen) gespeichert, erscheint im Metadaten-Editor jedoch als Raute-Zeichen, um die exakte Anzahl an Leerzeichen in den Feldern erkennbar zu machen.In den folgenden Feldern bietet das System Popup-Unterstützung, nachdem Sie die ersten drei Zeichen eingegeben haben (siehe Abbildung unten).:- 260 $$a, b, e, f
- 264 $$a, b
- 505 $$r, t
- 561$a
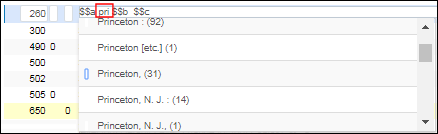 Beispiel einer Pop-Up-Unterstützung (nicht empfohlene Überschriften)Bei der Eingabe von Sonderzeichen wurde die Popup-Unterstützung mit einer Kundenparametereinstellung folgendermaßen implementiert:
Beispiel einer Pop-Up-Unterstützung (nicht empfohlene Überschriften)Bei der Eingabe von Sonderzeichen wurde die Popup-Unterstützung mit einer Kundenparametereinstellung folgendermaßen implementiert:- Wenn Sie einen Datensatzinhalt eingeben und der Metadaten-Editor Vorschläge liefert (nachdem Sie die ersten Zeichen eingegeben haben) und das Eszett-Zeichen oder ss anstelle des Eszett-Zeichens verwenden, sind die Vorschläge spezifisch für Ihre Eingabe. Wenn Sie also Werte mit ß eingeben, z. B. Großbritannien, werden nur Ergebnisse angezeigt, die ß enthalten, und wenn Sie Werte mit ss eingeben, z. B. Grossbritannien, werden nur Ergebnisse angezeigt, die ss enthalten.
- Wenn Sie einen Datensatzinhalt eingeben und der Metadaten-Editor Vorschläge liefert (nachdem Sie die ersten Zeichen eingegeben haben) und das Umlaut-Zeichen oder den Buchstaben ohne Umlaut verwenden, sind die Vorschläge spezifisch für Ihre Eingabe. Wenn Sie also Müller eingeben, erhalten Sie Vorschläge mit dem ü; und wenn Sie Muller eingeben, erhalten Sie Vorschläge ohne ü.
- Wenn Sie einen Datensatzinhalt eingeben und der Metadaten-Editor Vorschläge liefert (nachdem Sie die ersten Zeichen eingegeben haben) und Sie einen Bindestrich eingeben, werden nur Ergebnisse angezeigt, die einen Bindestrich enthalten, z. B. Baden-Baden. Wenn Sie beispielsweise Baden Baden ohne Bindestrich eingeben, werden nur Ergebnisse angezeigt, die keinen Bindestrich enthalten.
Wenden Sie sich an den Support, um die Kundenparameter für Unterfeldvorschläge so festzulegen, dass Vorschläge des Metadaten-Editors auf die von Ihnen bevorzugte Weise verarbeitet werden.Die Pop-Up-Unterstützung für diese Felder ist keine Empfehlung für Normdatei oder bibliografische Überschriften. Diese Pop-up-Hilfe wird durch die Beschreibungen bestimmt, die Sie im Vorgegebener Wortschatz - Register erstellen und speichern (siehe Konfiguration eines vorgegebenen Wortschatz-Registers) und identifizieren Sie sie anschließend in Ihrer Metadatenkonfiguration mit Vorgegebenen Wortschatz auswählen (siehe Felder bearbeiten), um die Liste Vorgegebener Wortschatz - Register mit Beschreibungen auszuwählen, die Sie zuvor erstellt haben.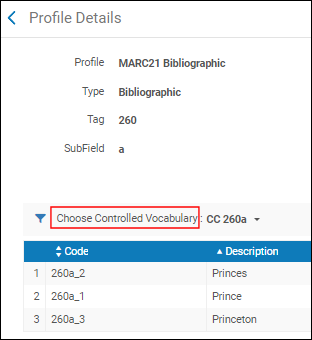 Vorgegebenen Wortschatz auswählen:Zum Zugriff auf empfohlene Normdateien und bibliografische Überschriften drücken Sie F3 von dem Feld aus, das Sie eingeben/überprüfen. Das System öffnet eine Liste an Optionen, aus welchen Sie auswählen können (beachten Sie, dass die Unterfelder in der Reihenfolge ihrer ursprünglichen Katalogisierung extrahiert werden). Wenn keine Überschriften-Empfehlungen verfügbar sind, zeigt Alma Keine übereinstimmenden Überschriften gefunden an. Für weitere Informationen siehe Verwenden von F3.
Vorgegebenen Wortschatz auswählen:Zum Zugriff auf empfohlene Normdateien und bibliografische Überschriften drücken Sie F3 von dem Feld aus, das Sie eingeben/überprüfen. Das System öffnet eine Liste an Optionen, aus welchen Sie auswählen können (beachten Sie, dass die Unterfelder in der Reihenfolge ihrer ursprünglichen Katalogisierung extrahiert werden). Wenn keine Überschriften-Empfehlungen verfügbar sind, zeigt Alma Keine übereinstimmenden Überschriften gefunden an. Für weitere Informationen siehe Verwenden von F3.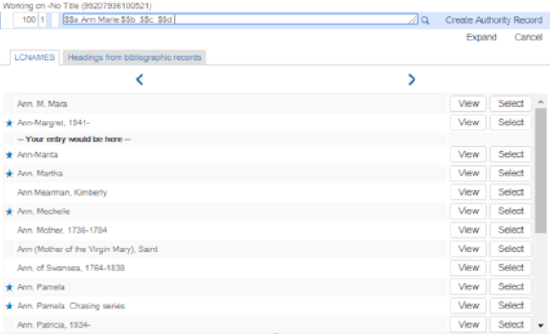 F3 Beispiel - Empfohlene Normdatei und Bibliographische ÜberschriftenWenn Sie im IE arbeiten und auf F3 drücken, achten Sie darauf, dass Sie auf Enter drücken, während der Fokus am Text ist. Andernfalls wird die Indexeintrag-Liste eventuell nicht korrekt angezeigt.Wenn für mehrere Normdatei-Wortschätze Prioritäten definiert wurden, überprüft das System Übereinstimmungen in der Reihenfolge der Priorität und zeigt die Ergebnisse in separaten Registerkarten an (wie GND und LCSH), in der Reihenfolge der Priorität von links nach rechts, wenn F3 verwendet wird. Siehe Normdatei-Prioritäten für weitere Informationen.
F3 Beispiel - Empfohlene Normdatei und Bibliographische ÜberschriftenWenn Sie im IE arbeiten und auf F3 drücken, achten Sie darauf, dass Sie auf Enter drücken, während der Fokus am Text ist. Andernfalls wird die Indexeintrag-Liste eventuell nicht korrekt angezeigt.Wenn für mehrere Normdatei-Wortschätze Prioritäten definiert wurden, überprüft das System Übereinstimmungen in der Reihenfolge der Priorität und zeigt die Ergebnisse in separaten Registerkarten an (wie GND und LCSH), in der Reihenfolge der Priorität von links nach rechts, wenn F3 verwendet wird. Siehe Normdatei-Prioritäten für weitere Informationen.- Lokale Normdateien werden mit dem Wort (lokal) in Klammern gekennzeichnet.
- Bevorzugte Begriffe werden mit einem Stern gekennzeichnet. Nicht-bevorzugte Begriffe sind links frei (fehlender Stern).
- Klicken Sie auf Ansicht, um den gesamten Normdatensatz anzuzeigen.
- Klicken Sie auf Auswählen, um den Inhalt dem Datensatz, an welchem Sie arbeiten, einzufügen.
- Wählen Sie die Registerkarte Indexeinträge aus Titelsätzen, um die vorgeschlagenen Titelsätze anzuzeigen.
- Für zusätzliche Informationen siehe Arbeiten mit Normdatensätzen.
- Klicken Sie auf das Symbol Speichern. Für zusätzliche Informationen zum Speichern von Datensätzen siehe Speichern von Datensätzen im Metadaten-Editor020Navigieren auf der Seite MD-Editor#Saving_Records_in_the_MD_Editor.
Arbeiten mit Einheitstitel-Indexeinträgen für GND-Datensätze
- 075 $b u
- Feld 130 und 500, 510 oder 511 mit $9, das eines der Folgenden enthält:
- 4:auta
- 4:koma
- 4:regi
- 4:kuen
Erstellen von Normdatei-Indexeinträgen mit Einheitstiteln, die mit $t beginnen
Arbeiten mit dem Feld 240 und Einheitstitel-Indexeinträgen
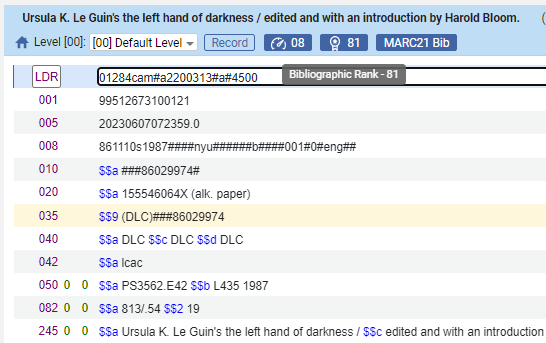
Bibliografischer Rang im Metadaten-Editor
Alma bewertet die Vollständigkeit und den Umfang von MARC 21-Titelsätzen anhand von Informationen, die Kennungen, Namen, Themen, informative LDR- und 008-Felder, Veröffentlichungsdetails usw. umfassen. Dies spiegelt sich im bibliografischen Rang wider, der Bibliotheken ein hilfreiches Werkzeug zur Identifizierung von Datensätzen, die möglicherweise Aufmerksamkeit erfordern, bieten soll. Der neue bibliografische Rang wird in der Datensatzansicht und im Metadaten-Editor angezeigt.
Weitere Informationen zum bibliografischen Rang finden Sie unter Bibliographischer Rang-Algorithmus.
Bibliographischer Rang in Gemeinschaftszonen-Sammlungen
Diese Informationen werden auf Sammlungsebene angezeigt: Sammlungssuchergebnisse für alle Verwaltungsbezeichnungen (Verwaltet von Ex Libris, Von der Gemeinschaft verwaltet, Beigetragen, Nicht gewartet, Noch ausstehende Löschung).
Das Feld Bibliografischer Rang ist in den Gemeinschaftszonen-Sammlungen sichtbar. Dieses Feld stellt den durchschnittlichen Rang der Titelsätze innerhalb der Sammlung dar und funktioniert auf drei verschiedenen Ebenen:
- Niedrig - 0-39
- Mittel 40-79
- Hoch 80-150
Der bibliografische Rangbereich liegt zwischen 1 und 150. Im Allgemeinen gelten Datensätze mit einem Rang über 75 als gute Datensätze.
Die drei oben genannten Qualitätskategorien basieren auf der Verteilung innerhalb der Sammlung des bibliografischen Rankings der Titelsätze. Die Logik der bibliografischen Ränge besteht darin, auf der Sammlungsebene den Durchschnitt der bibliografischen Ränge aller zugehörigen Titelsätze anzuzeigen, damit Benutzer wissen, welche Sammlung besser aktiviert werden sollte und welche Qualität sie von der Sammlung erwarten können, bevor sie sie aktivieren.
Durch die Einbeziehung von Qualitätsdaten der Gemeinschaftszonen-Sammlung, wie z. B. dem durchschnittlichen bibliografischen Rang, können Benutzer Anfragen zur Qualität von MARC-Datensätzen innerhalb einer bestimmten Gemeinschaftszonen-Sammlung beantworten.
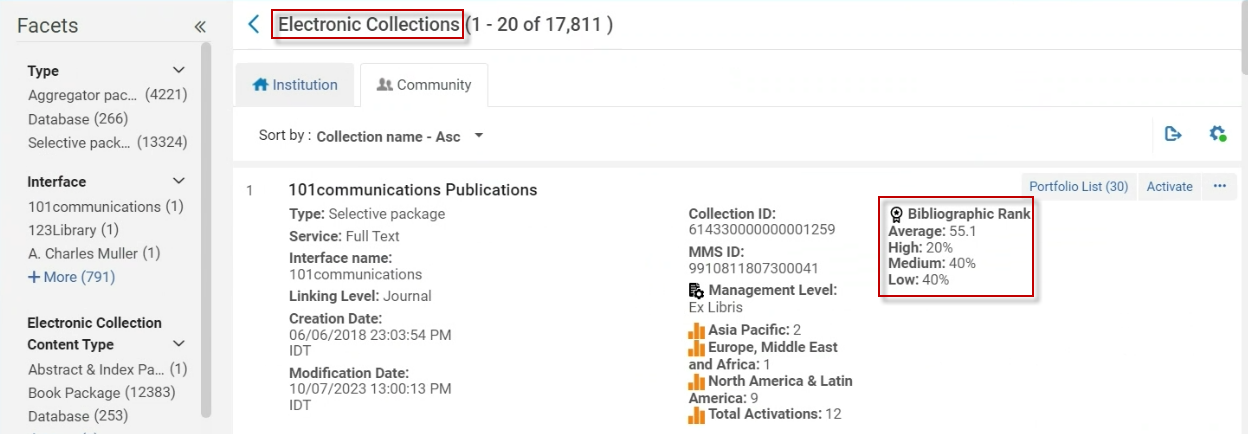
Benutzern werden die folgenden zusätzlichen Informationen zur Ebene der Gemeinschaftszonen-Sammlungen angezeigt:
| Bibliographischer Rang | Beschreibung |
|---|---|
| Durchschnitt | Die Summe aller einzelnen bibliografischen Rangs, dividiert durch die Gesamtzahl der Datensätze. |
| Hoch | % der Datensätze mit der bibliografischen Rangfolge „Hoch“ (berechnet anhand der oben genannten drei unterschiedlichen Ebenen – 80–150). |
| Medium | % der Datensätze mit der bibliografischen Rangfolge „Mittel“ (berechnet anhand der oben genannten drei unterschiedlichen Ebenen – 40–79). |
| Niedrig | % der Datensätze mit der bibliografischen Rangfolge „Niedrig“ (berechnet anhand der oben genannten drei unterschiedlichen Ebenen – bis 39). |
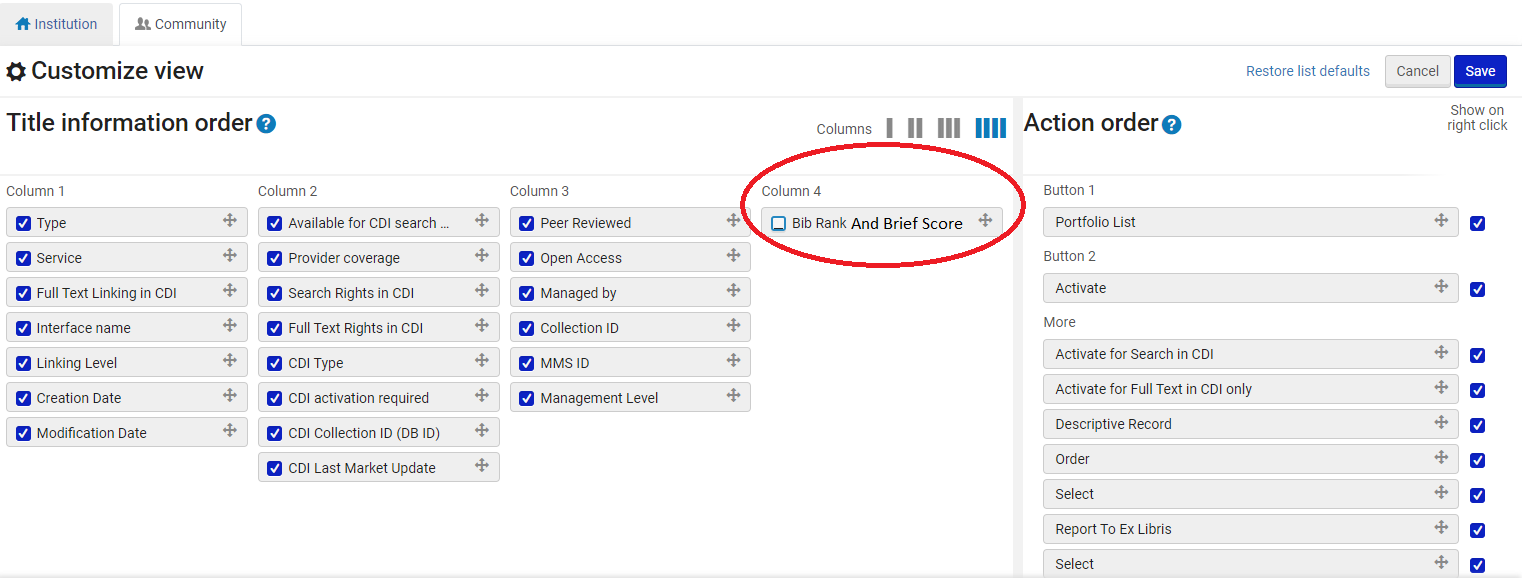
Die Option zum Anpassen von Ansichten wurde um die Felder „Bibliografischer Rang“ und „Kurztitel-Ebene“ für Informationen auf Portfolioebene erweitert. Benutzer können diese Details auf Wunsch in den Suchergebnissen anzeigen. Weitere Informationen zur Berechnung des Feldes Kurztitel-Ebene finden Sie unter Ebene 1 – Breite im bibliografischen Rangalgorithmus.
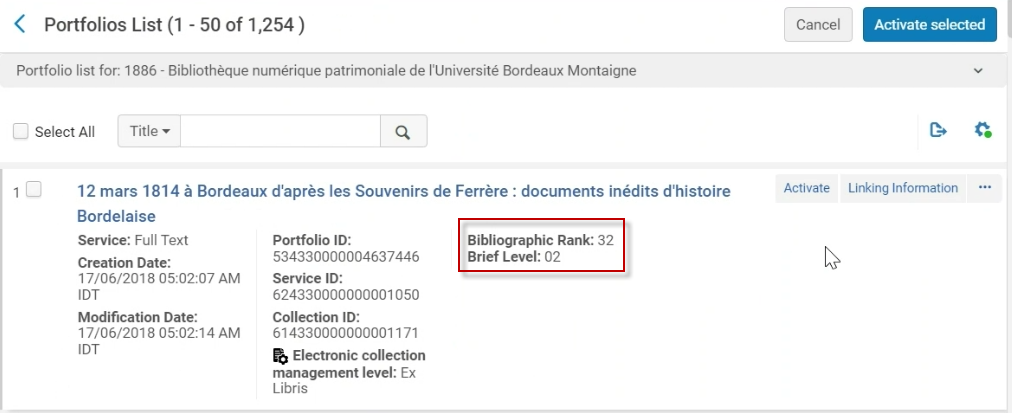
- Greifen Sie auf eine beliebige Suchdatensatzentität zu und wählen Sie das Symbol „Spaltenanzeige verwalten“ aus (
 ).
). - Wählen Sie in Spalte 4 des Bildschirms Ansicht anpassen die Option "BIB-Relevanz und Kurz-Auszug".
Hinweis: Um die Ansicht zu deaktivieren, deaktivieren Sie Sie die Option BIB-Relevanz und Kurz-Auszug. - Klicken Sie auf Speichern.
Bibliographischer Rang-Algorithmus
Alma bewertet die Vollständigkeit und den Umfang von MARC 21-Titelsätzen anhand von Informationen, die Kennungen, Namen, Themen, informative LDR- und 008-Felder, Veröffentlichungsdetails usw. umfassen. Dies spiegelt sich im bibliografischen Rang wider, der Bibliotheken ein hilfreiches Werkzeug zur Identifizierung von Datensätzen, die möglicherweise Aufmerksamkeit erfordern, bieten soll. Der neue bibliografische Rang wird in der Datensatzansicht und im Metadaten-Editor angezeigt.
Der bibliografische Rangbereich liegt zwischen 1 und 150. Im Allgemeinen gelten Datensätze mit einem Rang über 75 als gute Datensätze.
Der bibliografische Rang wird durch einen Algorithmus erstellt, der weiter unten beschrieben wird.
Allgemeines Modell
Dies ist ein Ansatz auf zwei Ebenen:
-
Ebene 1 - Breite: Der Schwerpunkt liegt hier auf der Erfassung:
Felder werden in Kategorien gruppiert, und wenn ein Datensatz eines der Felder in einer Kategorie enthält, erhält er eine Punktzahl entsprechend der Wichtigkeit dieser Kategorie.
- NIEDRIGE Wichtigkeit gibt 1 Punkt
- MITTLERE Wichtigkeit gibt 3 Punkte
- HOHE Wichtigkeit gibt 7 Punkte
Die Kategorie Schlagwörter hat beispielsweise eine hohe Wichtigkeit, daher ist ihr die Punktezahl 7 zugewiesen. Die Kategorie Stornierte Kennungen ist weniger wichtig und hat daher nur die Punktezahl 1. Es gibt 27 Kategorien. Die vollständige Liste wird unten in Kategorien beschrieben.
-
Ebene 2 - Tiefe: Der zweite Schwerpunkt liegt auf der Tiefe. Beispielsweise wird nicht nur überprüft, ob es ein Feld 6XX gibt, sondern es wird darauf geachtet, wie viele 6XX-Felder enthalten sind.
Die Tiefe ist nur für einige der Kategorien relevant. Wenn ein Datensatz eine solche Kategorie hat, werden die Felder dieser Kategorie gezählt. Die Anzahl der Felder ergibt die Tiefen-Punktzahl der Kategorie.Jede relevante Kategorie hat einen „Grenzwert für die Tiefe“, um zu vermeiden, dass viele Felder zu viel Gewicht haben.
Die gesamte Punktzahl besteht aus Punktezahl für die Breiten + Punktezahl für die Tiefe.
Kategorien
Nachfolgend sehen Sie die vollständige Liste der Kategorien. Für jede Kategorie werden die folgenden Informationen angegeben:
- Liste der Felder in der Kategorie
- Wichtigkeit
- Indikator, ob relevant für die Tiefe; wenn ja:
- Grenzwert für die Tiefe
| # | Kategorie-Name | Felder | Wichtigkeit | Relevant für die Tiefe? | Grenzwert für die Tiefe |
|---|---|---|---|---|---|
| 1 | Stornierte Kennung |
|
NIEDRIG |
Nein |
|
| 2 | Klassifizierung und Signatur |
|
HOCH |
Ja |
3 |
| 3 | Codierte Sprache/Ort/Zeit |
|
NIEDRIG |
Ja |
3 |
| 5 | Kontrollfelder |
|
MITTEL |
Nein |
|
| 5 | 008 Common data |
Eines oder mehrere der folgenden Felder muss einen Wert haben, der nicht | und nicht # ist:
|
HOCH |
Ja |
5 |
| 6 | 008 Bücherdaten
(Wenn Leader/06 = a und Leader/07 = a, c, d oder m) |
Eines oder mehrere der folgenden Felder muss einen Wert haben, der nicht | und nicht # ist:
|
NIEDRIG |
Nein |
|
| 7 | 008 Computer files data
(Leader/06 = m) |
Eines oder mehrere der folgenden Felder muss einen Wert haben, der nicht | und nicht # ist:
|
NIEDRIG |
Nein |
|
| 8 | 008 Music data
(Leader/06 = c, d, i oder j) |
Eines oder mehrere der folgenden Felder muss einen Wert haben, der nicht | und nicht # ist:
|
MITTEL |
Ja |
5 |
| 9 | 008 Visual Materials data
(Leader/06 = g, k, o oder r) |
Eines oder mehrere der folgenden Felder muss einen Wert haben, der nicht | und nicht # ist:
|
MITTEL |
Ja |
5 |
| 10 |
008 Maps data Leader/06 = e oder f) |
Eines oder mehrere der folgenden Felder muss einen Wert haben, der nicht | und nicht # ist:
|
MITTEL |
Ja |
5 |
| 11 | 008 Continuing Resources
(Leader/06 = a und Leader/07 = b, i oder s) |
Eines oder mehrere der folgenden Felder muss einen Wert haben, der nicht | und nicht # ist:
|
MITTEL |
Nein |
|
| 12 | Ausgabe |
250 - Ausgabe-Angabe |
HOCH |
Nein |
|
| 13 | Kennung |
|
HOCH |
Ja |
10 |
| 14 | Leader |
|
HOCH |
Nein |
|
| 15 | Namen |
|
HOCH |
Ja |
5 |
| 16 | Notiz |
|
NIEDRIG |
Nein |
|
| 17 | Bibliografie |
|
NIEDRIG |
Nein |
|
| 18 | Schlagwörter |
Eines oder mehrere der folgenden Felder muss als zweiten Indikator 0/1/2/3/5/6/7 haben.
|
HOCH |
Ja |
15 |
| 19 | Andere physische Informationen |
|
MITTEL |
Ja |
3 |
| 20 | Physikalische Beschreibung |
• 300 - Physische Beschreibung |
MITTEL |
Ja |
5 |
| 21 | Publishing-Details |
• 260 - Veröffentlichung, Ausfertigung etc. (Impressum) |
HOCH |
Nein |
|
| 22 | Verbundenes Exemplar |
Eines oder mehrere der folgenden Felder. Muss $a oder $t enthalten: |
NIEDRIG |
Nein |
|
| 23 | Serie |
Eines oder mehrere der folgenden Felder. Muss $a enthalten: 780 - Eintrag - Vorstehend 785 - Eintrag - Nachfolgend |
MITTEL |
Ja |
3 |
| 24 | Übersicht |
• 520 - Übersicht etc |
MITTEL |
Nein |
|
| 25 | Inhaltsverzeichnis |
• 505 - Notiz - Formatierte Inhalte |
MITTEL |
Nein |
|
| 26 | Titel |
• 245 mit mindestens $a oder $k |
HOCH |
Nein |
|
| 27 | Einheitstitel |
• 130 - Haupteintrag - Einheitstitel |
NIEDRIG |
Nein |
Überprüfungen
Zusätzlich zu den Punktezahlen für Breite und Tiefe werden einige Alma-Validierungen durchgeführt, um die Grundlagen des MARC21-Formats zu überprüfen. Die folgenden Überprüfungen werden durchgeführt:
- Pflichtfelder existieren (LDR und 245)
- Kontrollfelder haben legitime Daten
- Indikatoren haben legitime Daten
- Nur Felder, die wiederholbar sind, werden mehrfach angezeigt
- Nur Unterfelder, die wiederholbar sind, werden mehrfach angezeigt
- Alle Unterfelder sind gemäß MARC-Standard gültig
Wenn es ein Problem gibt, wird die Gesamt-Punktzahl um 1 Punkt reduziert.
Genauigkeit
Zusätzlich zur oben genannten Validierung wird überprüft, ob die Daten korrekt sind:
- ISBN-Prüfziffer
- ISSN-Prüfziffer
- „Andere Standardnummer“-Prüfziffer
- Materialform im Feld 006 (Position 0) stimmt mit der Materialart im Leader (LDR) überein
Wenn es ein Problem gibt, wird die Gesamt-Punktzahl um 1 Punkt reduziert.
Automatisches Erstellen von Verfassernummern
- 905 $d - Erstellt durch eine Kopie von 093 $a unter Verwendung einer Alma-Normalisierungsregel
- 905 $e - Basierend auf dem Inhalt in $a der Felder 100, 110, 111 oder 245, der in der Zuordnungstabelle Verfassernummernlisten erstellten Zuordnungstabelle und der Menüoption Allgemeine Verfassernummer im Metadaten-Editor (siehe den Vorgang unten) erstellt
- 905 $s - Mithilfe einer Alma-Normalisierungsregel erstellt, um die Inhalte von 905 $d, 905 $e, 905 $v (kein Pflichtfeld) und 905 $y (kein Pflichtfeld) zu verknüpfen, mit einem Vorwärtsslash (/) zum Trennen der Inhalte der einzelnen Unterfelder.
- Die Verfasser-Nummernliste in der Zuordnungstabelle Verfasser-Nummernlisten konfigurieren
Beachten Sie, dass die standardisierte Liste der Chinesischen Verfasser-Signaturen (aus der Cutter Sauborn Three-Figure Author Table) in Alma verwaltet wird und mithilfe der Zuordnungstabelle Verfassernummernlisten konfiguriert werden kann. Siehe Konfiguration der Verfassernummernlisten für weitere Informationen zur Konfiguration dieser Tabelle.
- Die Normalisierungsregeln für die Erstellung von 905 $d und 905 $s erstellen.
- Öffnen Sie im Metadaten-Editor einen Titelsatz, zu dem Sie die Verfassernummer 905 hinzufügen wollen.
- Machen Sie das Feld 100, 110, 111, oder 245 zum aktiven Feld. Das Feld, das Sie als aktives Feld auswählen, muss Inhalt in $a haben.
- Wählen Sie Aktionen bearbeiten > Verfassernummer erstellen (oder drücken Sie auf F4). 905 d wird automatisch mit der Verfassernummer erstellt.
- Speichern Sie Ihren Datensatz.
Erstellen eines UNIMARC-Titelsatzes
- Öffnen Sie den Metadaten-Editor (Ressourcen > Katalogisierung > Metadaten-Editor öffnen).
- Öffnen Sie die standardmäßige bibliografische Vorlage (Neu > UNIMARC Bibliografisch).
- Geben Sie Ihren bibliografschen Inhalt ein.
In gleicher Weise wie bei MARC 21-Titelsätzen bietet der Metadaten-Editor für UNIMARC-Titelsätze eine für UNIMARC spezifizierte Gültigkeitsprüfung unter Einsatz der Registerkarte Alarme.Ähnlich der Pop-Up-Unterstützungsmöglichkeit für einige MARC 21 Felder in Almas Metadaten-Editor (siehe die Abbildung oben), wird dieselbe Autovervollständigen-Funktion geboten, um Katalogisierern zu helfen, indem sie für bestimmte UNIMARC-Felder Inhaltsvorschläge anbieten.Es gibt ein bekanntes Problem bei UNIMARC 327 $a und 327 $b. Diese Unterfelder basieren auf der gleichen Funktionalität. Das hat zur Folge, dass das Pop-Up-Fenster die Werte beider Unterfelder vorschlägt, wenn der Inhalt entweder in 327 $a oder in 327 $b eingegeben wird.Für eine Liste äquivalenter UNIMARC-Felder, die durch die Autovervollständigen-Funktion bereitgestellt werden, siehe die Tabelle unten. Nachdem die ersten drei Zeichen getippt werden, versucht das System, für die einzugebenden Felder/Unter-Felder einen Vorschlag bereitzustellen.
Zum Autovervollständigen angebotene äquivalente UNIMARC-Felder MARC 21 Titeldaten-Felder UNIMARC-Felder 260 $a 210 $a 260$b 210 $c 260 $e 210 $e 260 $f 210 $g 505 $r 327 $z 505 $t 327 $a 505 $t 327 $b 561$a 317 $a
Es gibt keine Benutzerhilfe wird für die UNIMARC-Felder 4XX. - Bevor Sie Ihre Änderungen speichern, öffnen Sie die Menüs Datensatz-Aktionen und Aktionen bearbeiten , um alle auf den UNIMARC-Datensatz anzuwendenden, aktiven Optionen anzuzeigen. In gleicher Weise wie bei der Bearbeitung der MARC 21-Datensätze können Sie Vorlagen anlegen, Datensätze erweitern (unter Einsatz der Normalisierung), aus einer Vorlage heraus erweitern, usw.
- Klicken Sie auf Speichern, um Ihren UNIMARC-Titelsatz zu speichern.
Durchgeführte Interpunktion für angezeigte UNIMARC-Datensätze
| UNIMARC Zuordnung | Interpunktion | Erläuterungen |
|---|---|---|
| 700ab, 701ab, 710a,b,c,d,f,e, 711a,b,c,d,f,e wenn $7=ba oder nicht existiert | 70X a, b Beispiel: Vian, Boris 71X a. b. c (d ; e ; f) Beispiel: Canadian andrology society. Tagung (4. ; 1976 ; Toronto) |
70X b hat als Präfix ,^ (wobei ^ ein Leerzeichen ist)
71X bh at als Präfix .^ c hat als Präfix .^ e hat als Präfix ^;^ f hat als Präfix ^;^ Unterfeld-Gruppe def hat als Präfix ( und als Suffix ) - Beachten Sie, dass die 3 Unterfelder nicht immer vorhanden sind und (d) oder (d ; f) oder (d ; e ; f) etc. sein können. |
| 700a-z, 701a-z, 710a-z, 711a-z wenn $7=ba oder nicht existiert | Alle Unterfelder a bis z werden angezeigt | 70X Unterfelder bc haben als Präfix ,^ Unterfelder fg haben als Präfix ( und als Suffix ) Alle anderen Unterfelder haben als Präfix ^ 71X b hat als Präfix .^ c hat als Präfix .^ e hat als Präfix ^;^ f hat als Präfix ^;^ Unterfeld-Gruppe def hat als Präfix ( und als Suffix ) - Beachten Sie, dass die 3 Unterfelder nicht immer vorhanden sind und (d) oder (d ; f) oder (d ; e ; f) etc. sein können. Alle anderen Unterfelder haben als Präfix ^ |
| 500a-z (erster Indikator = 1) wenn $7=ba oder nicht existiert | alle Unterfelder a bis z werden angezeigt | m hat als Präfix ( und als Suffix ) i hat als Präfix , wenn nach h. Wenn nicht, hat i als Präfix .^ Alle anderen Unterfelder (mit Ausnahme von Unterfeld a) haben als Präfix .^ |
| 200a,e wenn $7=ba oder nicht existiert | 200 a : e | e hat als Präfix ^:^ (wobei ^ ein Leerzeichen ist) |
| 200a,e | 200 a : e | e hat als Präfix ^:^ (wobei ^ ein Leerzeichen ist) |
| 200a,b,c,e,d,h,i,f,g wenn $7=ba oder nicht existiert | 200 a [b] . c: e d .h, i /f ; g | b hat als Präfix [ und als Suffix ] c hat als Präfix .^ d hat kein Präfix, die Interpunktion ist im Datensatz katalogisiert e hat als Präfix ^:^ f hat als Präfix ^/^ g hat als Präfix ^;^ h hat als Präfix .^ i hat als Präfix , wenn nach h. Wenn nicht, hat i als Präfix .^ |
| 200a,b,e,h,i,f,g wenn $7=ba oder nicht existiert | 200 a [b] : e .h, i /f ; g | b hat als Präfix [ und als Suffix ] e hat als Präfix ^:^ f hat als Präfix ^/^ g hat als Präfix ^;^ h hat als Präfix .^ i hat als Präfix , wenn nach h. Wenn nicht, hat i als Präfix .^ |
| 205a wenn $7=ba oder nicht existiert | ||
| 205a,b,f,g wenn $7=ba oder nicht existiert | 205 a b / f ; g | f hat als Präfix ^/^ g hat als Präfix ^;^ |
| 206a-z, 208a,b, 230a | ||
| 210a wenn $7=ba oder nicht existiert | ||
| 210c wenn $7=ba oder nicht existiert | ||
| 210d | ||
| 328a-z, 210c wenn $7=ba oder nicht existiert | jedes Unterfeld hat als Präfix ^ | Alle Unterfelder haben als Präfix ^ |
| 210d (1),h (2), 100/09-16 (3), 207a (4) | 100/09-12 - 13-16 | 100/09-16 hat einen Bindestrich zwischen Position 12 und 13 |
| Beispiel: 1981-2003 | ||
| 326a | ||
| 326b | ||
| 3XX -3X9 -39X,327,330 | jedes Unterfeld hat als Präfix ^ | |
| 3X9, 39X | jedes Unterfeld hat als Präfix ^ | |
| 225 a,e,h,i | 225 a : e . i | e hat als Präfix ^:^ (wobei ^ ein Leerzeichen ist) i hat als Präfix .^ Das Feld 255 hat als Präfix ( und als Suffix ) |
| 225v | ||
| 60Xa-z -23, 616a-z -23, 617a-z -23, 610a | jedes Unterfeld hat als Präfix ^ | |
| 69X und 6X9 | jedes Unterfeld hat als Präfix ^ | |
| 010a | ||
| 019 (Sudoc) | ||
| 011a,f | ||
| 011f wenn LDR/06 ungleich l | ||
| /001 | ||
| 200b | ||
| 327a-z, 330a | jedes Unterfeld hat als Präfix ^ | |
| LDR | ||
| 101a | ||
| 700a-z, 701a-z, 710a-z, 711a-zwenn $7 existiert und nicht gleich Bearbeitungsauftrag ist | Alle Unterfelder a bis z werden angezeigt | 70X Unterfelder bc haben als Präfix ,^ Unterfelder fg haben als Präfix ( und als Suffix ) Alle anderen Unterfelder haben als Präfix ^ 71X b hat als Präfix .^ c hat als Präfix .^ e hat als Präfix ^;^ f hat als Präfix ^;^ Unterfeld-Gruppe def hat als Präfix ( und als Suffix ) - Beachten Sie, dass die 3 Unterfelder nicht immer vorhanden sind und (d) oder (d ; f) oder (d ; e ; f) etc. sein können. Alle anderen Unterfelder haben als Präfix ^ |
| 500a-z wenn $7 existiert und nicht gleich ba ist | m hat als Präfix ( und als Suffix ) i hat als Präfix , wenn nach h. Wenn nicht, hat i als Präfix .^ Alle anderen Unterfelder (mit Ausnahme von Unterfeld a) haben als Präfix .^ |
|
| 200a,e wenn $7 existiert und nicht gleich ba ist | 200 a : e | e hat als Präfix ^:^ (wobei ^ ein Leerzeichen ist) |
| 200a,b,c,d,e,h,i,f,g wenn $7 existiert und nicht gleich ba ist | 200 a [b] . c: e d .h, i /f ; g | b hat als Präfix [ und als Suffix ] c hat als Präfix .^ d hat kein Präfix; die Interpunktion ist im Datensatz katalogisiert e hat als Präfix ^:^ f hat als Präfix ^/^ g hat als Präfix ^;^ h hat als Präfix .^ i hat als Präfix , wenn nach h. Wenn nicht, hat i als Präfix .^ |
| 205a wenn $7 existiert und nicht gleich ba ist | ||
| 205a,b,f,g wenn $7 existiert und nicht gleich ba ist | 205 a b / f ; g | f hat als Präfix ^/^ g hat als Präfix ^;^ |
| LDR/06 | ||
| LDR/07 | ||
| 200 $b | ||
| 100a/08 | ||
| 100 a,09-12 | ||
| 100a/13-16 | ||
| 102 a,c | ||
| 010 a,z | ||
| 200a,b,c,d,e,h,i,f,g | 200 a [b] . c: e d .h, i /f ; g | b hat als Präfix [ und als Suffix ] c hat als Präfix .^ d hat kein Präfix; die Interpunktion ist im Datensatz katalogisiert e hat als Präfix ^:^ f hat als Präfix ^/^ g hat als Präfix ^;^ h hat als Präfix .^ i hat als Präfix , wenn nach h. Wenn nicht, hat i als Präfix .^ |
| 020a | ||
| 035a(1),z (2) | ||
| 700a-z, 701a-z, 710a-z, 711a-z | Alle Unterfelder a bis z werden angezeigt | 70X Unterfelder bc haben als Präfix ,^ Unterfelder fg haben als Präfix ( und als Suffix ) Alle anderen Unterfelder haben als Präfix ^ 71X b hat als Präfix .^ c hat als Präfix .^ e hat als Präfix ^;^ f hat als Präfix ^;^ Unterfeld-Gruppe def hat als Präfix ( und als Suffix ) - Beachten Sie, dass die 3 Unterfelder nicht immer vorhanden sind und (d) oder (d ; f) oder (d ; e ; f) etc. sein können. Alle anderen Unterfelder haben als Präfix ^ |
| 410 a,t,o,h,i,x | 400 a t : o. h, i | h hat als Präfix .^ i hat als Präfix , wenn nach h. Wenn nicht, hat i als Präfix .^ o hat als Präfix ^:^ |
| 203a,b | ||
| 203c | ||
| Keine Übereinstimmung | ||
| 126a,b | ||
| 125a,b | ||
| 115a,b | ||
| 135a, 230a | ||
| Keine Übereinstimmung | ||
| 145a-i,146a-i |
Arbeiten Multiscript UNIMARC Titeldatensätzen
Latein Anzeige
- 200, 205, 206, 207, 208, 210
- 327
- All 4XX fields: 410, 411, 412, 413, 421, 422, 423, 424, 425, 430, 431, 432, 433, 434, 435, 436, 437, 440, 441, 442, 443, 444, 445, 446, 447, 448, 451, 452, 453, 454, 455, 456, 461, 463, 464, 470, 481, 482, 488
- All 5XX fields: 500, 501, 503, 510, 511, 512, 513, 514, 515, 516, 517, 518, 520, 530, 431, 532, 540, 541, 545
- 600, 601, 602, 605
- All 7XX fields: 700, 701, 702, 710, 711, 712, 716, 720, 721, 722
Normdaten-Verwaltung
- Normdateien - BIB-Indexeinträge verknüpfen
- Normdateien - Ansetzungsform-Korrektur
- F3
Verwendung mehrerer Zugriffspunkte für UNIMARC
Erstellen eines KORMARC-Titelsatzes
- Öffnen Sie den Metadaten-Editor (Ressourcen > Katalogisierung > Metadaten-Editor öffnen).
- Öffnen Sie die standardmäßige bibliografische Vorlage (Neu > KORMARC Bibliografisch).
- Geben Sie Ihren bibliografschen Inhalt ein.
Bei der Eingabe der folgenden Felder bietet Ihnen das System eine Popup-Unterstützung nach der Eingabe der ersten drei Zeichen:
- 260 $$a, b, e, f
- 264$b
- 505 $$r, t
- 561$a
In gleicher Weise wie bei MARC 21-Titelsätzen bietet der Metadaten-Editor für KORMARC-Titelsätze eine für KORMARC spezifizierte Gültigkeitsprüfung unter Einsatz der Registerkarte Alarme.Wenn Sie den Formular-Editor (Aktionen bearbeiten > Formular-Editor öffnen) für das Kontrollfeld KORMARC 008 öffnen, werden die folgenden KORMARC-Feldoptionen bereitgestellt:- Korea Regierungsbehörde
- Korea Universität
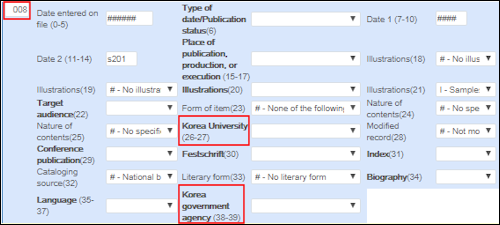 KORMARC Kontrollfeld 008 - Metadaten-Editor-Optionen
KORMARC Kontrollfeld 008 - Metadaten-Editor-Optionen - Klicken Sie auf Speichern, um Ihren KORMARC-Titelsatz zu speichern.
Automatisches Erstellen der Verfassernummer für das lokale Signaturfeld 090 in einem KORMARC Titelsatz
- 090 $a - Dewey-Signatur, die aus 082 $a kopiert wird
- 090 $b - Verfasser-Nummer, die aus einer standardisierten Verfasser-Nummernliste mit einem Präfix aus dem Anfangsbuchstaben des Nachnamen des Verfassers und einem Suffix, das den Anfangsbuchstaben des Titels enthält, wie z. B. G329w, abgeleitet wird
- 090 $c - Jahr, das aus 260 $c kopiert wird
- Öffnen Sie im Metadaten-Editor einen Titelsatz, zu dem Sie die Verfassernummer 090 hinzufügen wollen.
- Machen Sie ein Verfasserfeld 100 oder 700 zum aktiven Feld.
-
Wählen Sie Aktionen bearbeiten > Verfassernummer erstellen (oder drücken Sie auf F4).Wenn Sie in der Konfiguration der Verfasser-Nummernlisten nur eine Verfasser-Nummernliste aktiviert haben (Konfigurationsmenü > Ressourcen > Katalogisierung > Verfasser-Nummernlisten), wird das Zielfeld und das Unterfeld, das Sie in der Konfiguration der Verfasser-Nummernlisten gekennzeichnet haben, automatisch mit der Verfassernummer erstellt.Wenn Sie bei der Konfiguration der Verfasser-Nummernlisten mehr als eine Verfasser-Nummernliste aktiviert haben, werden Sie vom System aufgefordert, die zu verwendende Verfasser-Nummernliste auszuwählen.
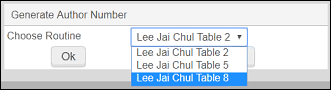 Verfasser-Nummernliste auswählenWeitere Informationen finden Sie unter Konfigurieren von Standard-Autorenummernlisten.
Verfasser-Nummernliste auswählenWeitere Informationen finden Sie unter Konfigurieren von Standard-Autorenummernlisten. - Speichern Sie Ihren Datensatz.
Erstellen eines CNMARC-Titelsatzes
- Öffnen Sie den Metadaten-Editor (Ressourcen > Katalogisierung > Metadaten-Editor öffnen).
- Öffnen Sie die standardmäßige bibliografische Vorlage (Neu > CNMARC Bibliografisch).
- Geben Sie Ihren bibliografschen Inhalt ein.
In gleicher Weise wie bei MARC 21-Titelsätzen bietet der Metadaten-Editor für CNMARC-Titelsätze eine für CNMARC spezifizierte Gültigkeitsprüfung unter Einsatz der Registerkarte Alarme. Die Überprüfungskriterien können im Metadatenprofil CNMARC angepasst werden (siehe Bearbeiten von Überprüfungsroutinen).
- Verwenden Sie das Menü Datei oder klicken Sie auf das Symbol Speichern, um Ihren CNMARC-Titelsatz zu speichern.
Verwendung mehrerer Zugriffspunkte für CNMARC 6XX-Felder.

Erstellen eines Dublin Core Titelsatzes
- Öffnen Sie den Metadaten-Editor (Ressourcen > Katalogisierung > Metadaten-Editor öffnen).
- Klicken Sie auf Neu > Dublin Core.
Der Metadaten-Editor öffnet die Standardvorlage zur Eingabe Ihres Dublin Core-Datensatzes.
- Geben Sie die Daten für Ihren Dublin Core-Datensatz ein. Siehe den Abschnitt Menü- und Werkzeugleisten-Optionen des Metadaten-Editors für weitere Informationen.
Ersteller eines Titelsatzes
Das Feld „Ersteller“ eines Titelsatzes gibt an, wie der Datensatz erstellt wurde:
- „import“ (Kleinbuchstabe „i“), wenn der Datensatz aus der Migration stammt
- „System“, wenn der Datensatz aus einem Importprofil stammt
- „CKB“, wenn der Datensatz aus einem Update der Gemeinschaftszone stammt

Zusammenführen von Titeldatensätzen
- Katalogisierer, erweitert
- Bestellposten
- Elektronische Sammlung
- Elektronische Portfolios
- Physische Exemplare
- Digitale Repräsentationen
- Ausleihen
- Vormerkungen
- Literaturlisten
- Zuordnung eines verknüpften Datensatzes (basierend auf MMS-ID)
Wenn der sekundäre Datensatz einen verknüpften Datensatz mit der MMS-ID des sekundären Datensatzes hat, die in einem der Felder 76X-78X festgelegt ist, wird die MMS-ID während auf die MMS-ID des primären Datensatzes geändert, um eine Zuordnung beizubehalten (und zu vermeiden, dass es einen verknüpften Datensatz ohne Parent-Zuordnung gibt – dies ist ein "Orphan-Datensatz").
-
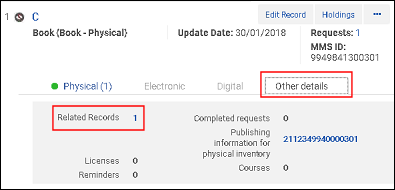
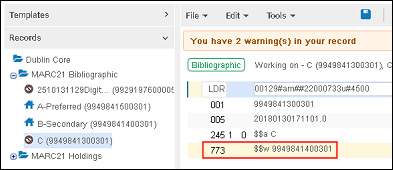 Mit dem sekundären Datensatz verknüpfter Datensatz vor dem Zusammenführen/MMS-ID in 773$w
Mit dem sekundären Datensatz verknüpfter Datensatz vor dem Zusammenführen/MMS-ID in 773$w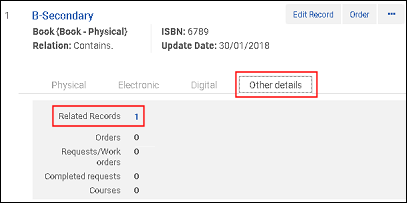 Sekundärer Datensatz mit verknüpftem Datensatz vor dem Zusammenführen
Sekundärer Datensatz mit verknüpftem Datensatz vor dem Zusammenführen
- Sie können zwei Titelsätze nur zusammenführen, wenn beide Datensätze Institutionszonen-Datensätze oder beide Networkzonen-Datensätze sind. Sie können einen Institutionszonen-BIB-Datensatz nicht mit einem Netwerkzonen-BIB-Datensatz zusammenführen.
- Informationen zur Positionierung einer Kennung vom sekundären Datensatz in den primären Datensatz beim Zusammenführen von Datensätze finden Sie unter Konfiguration von BIB-Weiterleitungsfeldern.
- Beim Zusammenführen von Titeldatensätzen in der Netzwerkzone prüft der Prozess, ob der nicht bevorzugte Titelsatz von anderen Mitgliedern "gehalten" wird. Wenn ja, verschiebt der Prozess den Bestand aller Mitglieder in den bevorzugten Titelsatz. In diesem Fall wird ein nicht bevorzugter Datensatz unterdrückt und die Unterdrückung wird vom bevorzugten Datensatz übernommen.
- Lokalisieren Sie die beiden Titelsätze, die Sie zusammenführen möchten. Der primäre Datensatz wird mit den Informationen des sekundären Datensatzes aktualisiert.
- Bearbeiten Sie die beiden Datensätze, sodass beide in der Registerkarte Datensätze im Metadaten-Editor erscheinen.
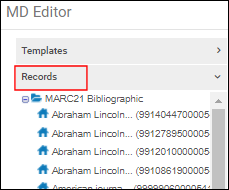
 Titeldatensätze in der Registerkarte Datensätze
Titeldatensätze in der Registerkarte Datensätze - Klicken Sie im Navigationsfenster unter der Registerkarte Datensatz den primären Datensatz an.
- Klicken Sie auf das Symbol Editor teilen und klicken Sie dann auf den sekundären Datensatz, sodass dieser rechts erscheint.
- Wählen Sie Datensatz-Aktionen > Datensätze zusammenführen und kombinieren.
Das Dialogfeld Datensätze zusammenführen und Bestand kombinieren öffnet sich.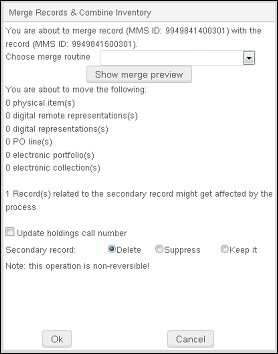 Beim Zusammenführen und Kombinieren wird der Bestand des zu verschiebenden sekundären (nicht bevorzugten) Datensatzes nur dann im Zähler angezeigt, wenn er ein lokaler Datensatz ist. Dies ist in den beiden nachfolgenden Fällen zutreffend:
Beim Zusammenführen und Kombinieren wird der Bestand des zu verschiebenden sekundären (nicht bevorzugten) Datensatzes nur dann im Zähler angezeigt, wenn er ein lokaler Datensatz ist. Dies ist in den beiden nachfolgenden Fällen zutreffend:
- Wenn Sie in der Institution angemeldet sind, die eine lokale (Cache-) Version des NZ-Datensatzes mit Bestand hat.
- Wenn das Zusammenführen und Kombinieren in einer selbständigen Institution erfolgt, in der beide Datensätze in jedem Fall lokal sind. - Prüfen Sie alle angezeigten Meldungen. Beachten Sie insbesondere, dass dieser Vorgang nicht rückgängig gemacht werden kann.
Unter Sie verschieben Folgendes: listet das System die Änderungen auf, die nach der Zusammenführung auftreten werden. Zusätzlich werden Vormerkungen, Ausleihen und Literaturlisten, die an den sekundären Datensatz angehängt sind, aktualisiert. Zudem wird in einem Datensatz, der mit dem sekundären Datensatz verknüpft ist, die in einem der Felder 76X-78X festgelegte MMS-ID auf die MMS-ID des primären Datensatzes geändert, die im Prozess Datensätze zusammenführen und Bestand kombinieren festgelegt wurde.Wenn Bestellungen vorhanden sind, erscheint die Anzahl der Bestellungen. Aufgrund einer technischen Einschränkung zeigt das Dialogfeld nicht "0 Bestellungen" an, wenn es keine Bestellungen gibt; stattdessen erscheint die Zeile mit den Bestellungen einfach nicht.
- Wählen Sie eine Prozedur zur Zusammenführung aus der Dropdown-Liste. Die Zusammenführungsroutinen, die in der Liste erscheinen, sind unter der Registerkarte Regeln im Metadaten-Editor aus der Liste der Zusammenführungsregeln gezogen
- Für eine Vorschau der Ergebnisse der Zusammenführung klicken Sie auf Vorschau zusammenführen anzeigen. Klicken Sie auf Ok, um die Ansicht Vorschau zusammenführen zu schließen.
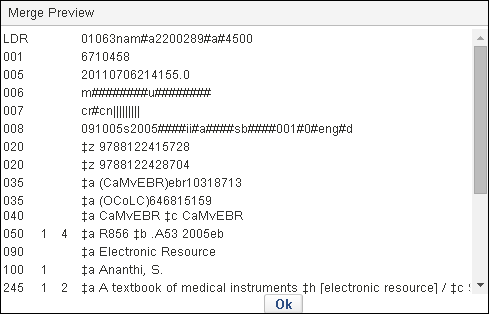 Vorschau zusammenführen
Vorschau zusammenführen - Optional können Sie Bestands-Signatur aktualisieren asuwählen. Wenn Sie diese Option auswählen, aktualisiert das System die Informationen der Signatur (unter Verwendung der bibliografischen Signatur) für alle Bestände, die mit dem primären Datensatz verbunden sind. Diese Änderung wird am Bestand angewendet, der nach der Titelsatz-Zusammenführung mit dem primären Datensatz verknüpft ist. Beachten Sie, dass, wenn eines der Signatur-Felder im Titelsatz aktualisiert wird, dies Auswirkungen auf die Signatur haben könnte, die schließlich im Lokalsatz erscheint.
- Wählen Sie aus den nachfolgenden Optionen, wie Sie die sekundären Titelsätze (nach der Zusammenführung) behandeln möchten:
- Löschen
- Unterdrücken
- Behalten
- Sobald Sie zur Zusammenführung der beiden Datensätze bereit sind, klicken Sie auf Ok.
Ansicht von Titelsätzen
Verwalten von Titelsätzen
Titelsätze löschen
- Katalogisierer, erweitert
Datensätze müssen lokalisiert werden, bevor sie im Metadaten-Editor gelöscht werden können. Siehe hierfür Titelsätze der Gemeinschaftszone ohne Portfolios aus der Institutionszone entfernen.
Benutzer können einen Titelnsatz einer Netzwerkzone auf der Registerkarte „Institution“ löschen, auch wenn der Datensatz seinen Ursprung in der Gemeinschaftszone hat.
Für Titelsatz-Aufbewahrung markierte Datensätze werden nicht gelöscht. Weitere Informationen finden Sie unter Titelsatz-Aufbewahrung.
- Wählen Sie Titelsatz löschen aus der Metadaten-Editor-Symbolleiste unter Datensatz-Aktionen aus.
Ein Titelsatz kann nur gelöscht werden, wenn es:
-
Keine Bestellposten gibt
-
Geschlossene Bestellposten gibt
-
Gelöschte Bestellposten
-
Keine aktiven Kaufbestellungen
Wenn Sie einen Titelsatz im Institutionsbereich löschen und die letzte Bibliothek im Konsortium sind, in der er gespeichert ist, dann wird der Datensatz automatisch in der Netzwerkzone gelöscht. Wenn Sie nicht möchten, dass er in der NZ automatisch, sondern stattdessen manuell aus der Netzwerkzone gelöscht werden soll, stellen Sie den Kundenparameter delete_nz_bib_without_inventory (Konfiguration > Ressourcen > Allgemein > Andere Einstellungen) auf falsch (siehe Konfiguration anderer Einstellungen (Ressourcen-Verwaltung)).
Beim Löschen eines Titelsatzes, der aus der Gemeinschaftszone stammt, wird dem Benutzer eine Benachrichtigungsmeldung angezeigt, die darauf hinweist, dass nicht der Gemeinschaftszonendatensatz, sondern nur der lokale Datensatz gelöscht wird.
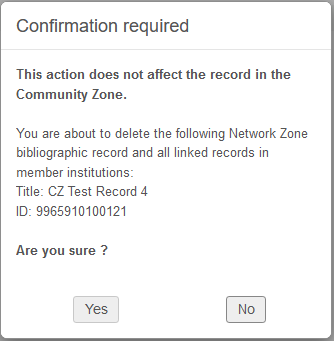
Löschen von Titelsatz-Sets
- Katalog-Administrator
- Katalog Manager
- Führen Sie den Prozess Titelsätze löschen aus. Datensätze, die wegen einer der oben beschriebenen Bedingungen nicht gelöscht werden können, werden im Prozessbericht gekennzeichnet.
Wählen Sie die Option „Alle verbundenen Bestandsressourcen löschen“, wenn Sie den mit diesen Datensätzen verknüpften Bestand löschen möchten.
Titelsatz-Aufbewahrung
Alma ermöglicht es Bibliotheken, das Löschen eines Titelsatzes zu verhindern. Um dies durchzuführen, kann die Tabelle Definition der Aufbewahrung bibliografischer Sammlungen (Konfigurationsmenü > Ressourcen > Aufbewahrung von Sammlungen > Definition der Aufbewahrung bibliografischer Sammlungen) konfiguriert werden. Administratoren können Bedingungen für die Aufbewahrung von Datensätzen festlegen. Fügen Sie ein Feld und ein Unterfeld hinzu, damit der Datensatz vor dem Löschen geschützt wird, wenn das Unterfeld einen Wert enthält. Alternativ können Sie einen bestimmten Wert festlegen, damit nur Datensätze mit diesem Wert im Unterfeld aufbewahrt werden.

Nach der Konfiguration der Tabelle führt Alma beim Versuch, einen Titelsatz zu löschen, Überprüfungen durch. Es wird überprüft, ob der Datensatz den festgelegten Inhalt der Tabelle enthält. Wenn der Inhalt vorhanden ist, wird der Datensatz vor dem Löschen geschützt. Außerdem wird nach der Aktualisierung der Tabelle jeder Datensatz, der den definierten Kriterien entspricht, als archivierungspflichtig markiert, um bei der nächsten Indexierung beibehalten zu werden (wenn er geändert und gespeichert wird, oder bei der halbjährlichen Neu-Indexierung). Dadurch können die aufbewahrten Datensätze im System durchsucht werden.
Als Muss beibehalten werden markierte Datensätze werden mit dem Symbol Muss beibehalten werden ![]() ), angezeigt, das darauf hinweist, dass der Datensatz vor der Löschung geschützt wird.
), angezeigt, das darauf hinweist, dass der Datensatz vor der Löschung geschützt wird.
Im Fall von Netzwerkzonen-Datensätzen wird die Aufbewahrungs-Richtlinie auf Grundlage der in der Tabelle Netzwerkzone festgelegten Konfiguration bestimmt. Beim Versuch, einen mit der Gemeinschaftszone verknüpften Titelsatz zu löschen, wird die Entfernung des verknüpften Datensatzes aus der lokalen Institution auf der Grundlage der von dieser Institution festgelegten spezifischen Konfiguration eingeschränkt. Lokale Erweiterungsfelder können nicht als Retentionsfelder verwendet werden. Ein Feld, das in der Institutionszone verwendet wird, ohne eine lokale Erweiterung zu sein, kann als Retentionsfeld verwendet werden.
Verwenden verknüpfter Daten beim Arbeiten mit Titelsätzen
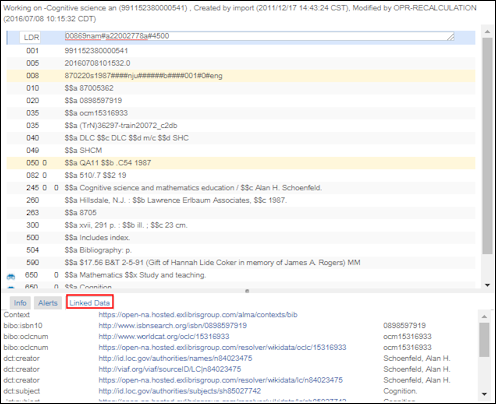
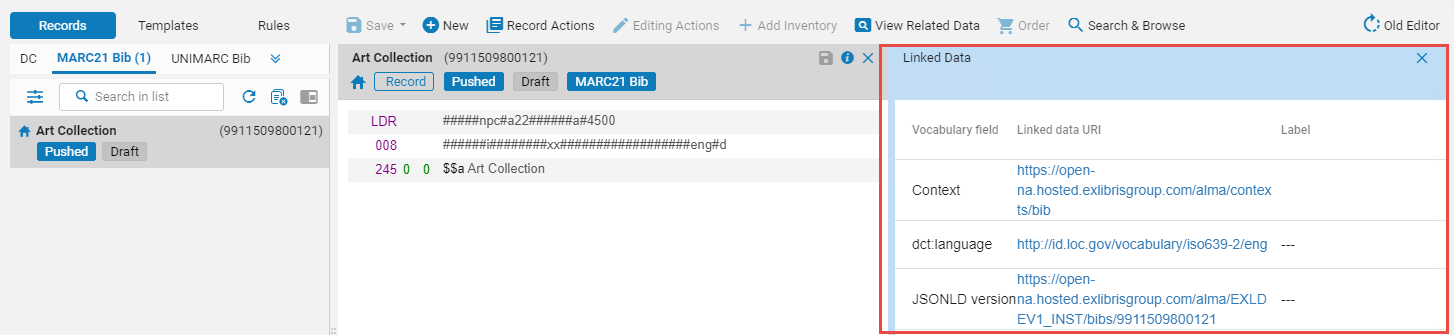
-
Wortschatz-Feld - Dieses wird dem Kontext entsprechend abgerufen. Der Standardkontext ist cname.alma.exlibrisgroup.com/[format]/[works_or_instances]/[MMSID]. Beispiel: bgu.alma.exlibrisgroup.com/bf/instances/9922819700121.
Wenn es ein aktives Integrationsprofil Verknüpfte Daten (siehe Verknüpfte Daten) mit einem Pfad zu diesem Kontext gibt, wird dieser Kontext verwendet.Alle früheren Alma-URI-Formate werden auf das neue Alma-URI-Format umgeleitet: cname.alma.exlibrisgroup.com/[format]/[works_or_instances]/[MMSID].
Wenn eine Institution dies wünscht, kann sie den Anfang der Webadresse (URL-Präfix) von cname.alma.exlibrisgroup.com in ihr eigenes oder ein anderes Präfix ändern. Beispiel: bgu.ac.il. Diese Änderung kann im Verknüpfte-Daten-Integrationsprofil vorgenommen werden und Datensätze werden gelöst, solange die Domain von der IT-Abteilung der Institution unter derselben IP-Adresse registriert wird.Sie müssen kein Integrationsprofil für verknüpfte Daten erstellen, um auf verknüpfte Daten aus den Suchergebnissen der Alma-Bestandssuche zuzugreifen. Allerdings ist es erforderlich, verknüpfte Daten im Format JSON-LD darzustellen (siehe Verknüpfte Daten für weitere Informationen). -
URI verknüpfter Daten
Verknüpfte Daten für Titelsätze, die mit IdRef-Normdatensätzen verknüpft sind, generieren jetzt auch URIs zu den IdRef-Normdatensätzen.
- Label - Für ISSN, ISBN und OCLC wird der Feldinhalt angezeigt. Für Ersteller und Schlagwort wird der Wert des Indexeintrages angezeigt.
Arbeiten mit UTF Zusammengesetzten / Zerlegten Unicode-Repräsentationen (UTF-8 und Zeichen mit diakritischen Zeichen)
Alma unterstützt das Normalisieren zerlegter Zeichen in ihre zusammengesetzte Form beim Speichern eines Titels oder eines Berechtigungsdatensatzes.
Zum Beispiel kann das Wort Amélie zwei kanonisch äquivalente Unicode-Formen haben:
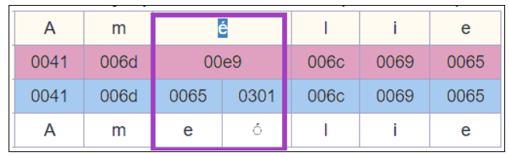
Mit dieser Funktion wird beim Speichern von Datensätzen, die diese Zeichen enthalten, das zerlegte Formular (0065 + 0301) auf die zusammengesetzte Form (00e9) normalisiert.
Wenn Sie Alma so einstellen, dass UTF-zusammengesetzte / zerlegte Repräsentationen verarbeitet werden, vermeiden Sie auch Indexeintrag ändern im Prozess Ansetzungsform. In Fällen, in denen die der Indexeintrag des Titelsatzes und der Normdatei-Indexeintrag dieselbe äquivalente UTF-Repräsentation haben (zusammengesetzt oder zerlegt), überspringt der PTC die Korrektur. Dadurch wird die Aktualisierung redundanter Indexeinträge aus der Aufgabenliste Normdateikontrolle und der Veröffentlichung herausgefiltert.
Beachten Sie, dass dies für alle Alma-Datensätze oder für einen bestimmten lokalen Wortschatz definiert werden kann.
Diese Funktion ist standardmäßig deaktiviert. Wenden Sie sich an die Mitarbeiter von Ex Libris, um dies in Abstimmung mit Ihrer Einrichtung zu aktivieren.