Konfiguration der Katalogisierung
- Katalog-Administrator
Diese Rolle wird für die Bearbeitung von MARC-basierenden Profilen mithilfe von Erweiterungsstapeln benötigt. Das Hinzufügen, Entfernen und Beitragen von Erweiterungspaketdateien auf Gemeinschaftszonenebene erfordert spezielle Berechtigungen, die dieser Rolle zugewiesen sind. Wenn Sie nicht mit Erweiterungspaketdateien arbeiten können, wenden Sie sich an den Kundensupport, um diese Berechtigungen zu erhalten.)
- Allgemeiner Systemadministrator
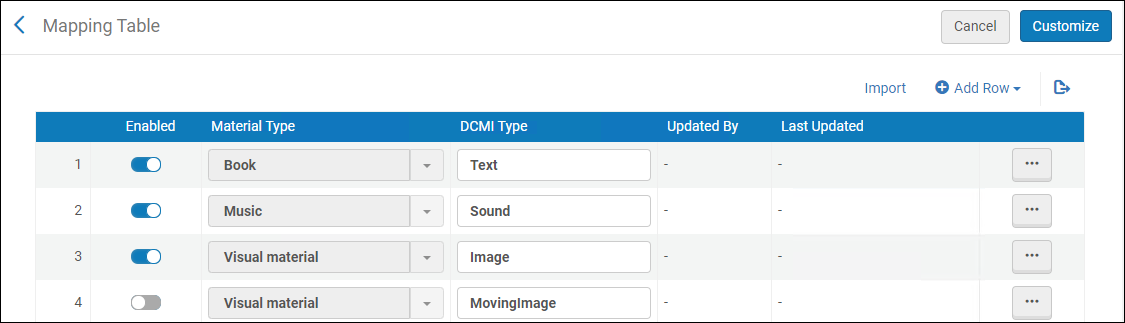
Dieser Abschnitt behandelt die Konfiguration der Metadaten-Umgebung. Die im Abschnitt Aktive Profile der Seite Metadaten-Konfigurationsliste konfigurierten Profile definieren die Katalogisierungsumgebung, die Sie bei der Arbeit im MD-Editor verwenden. Die für Sie auf der Seite Metadaten Konfigurationsliste zur Konfiguration verfügbaren bibliografischen Profile werden von der Einstellung Aktive Register für Ihre Institution durch Ex Libris festgelegt. Die folgenden aktiven Register können für Alma konfiguriert werden:
- MARC 21
- UNIMARC
- KORMARC
- CNMARC
- Dublin-Core
- MODS
- ETD
- DC Anwendungsprofile
- Welche Metadaten-Felder und Unterfelder im Metadaten-Editor erscheinen und ob diese wiederholbar sind
- Ob die Unterfelder einen vorgegebenen Wortschatz verwenden
- Normierungsprozesse
- Überprüfungsprozesse
Anzeige von Metadaten-Profil-Details
- Allgemeine Informationen (nur DC Anwendungsprofile)
- Felder
- Formen
- Normierungsprozesse
- Überprüfungsprozesse
- Überprüfung - Fehlerprofilliste
- Andere Einstellungen
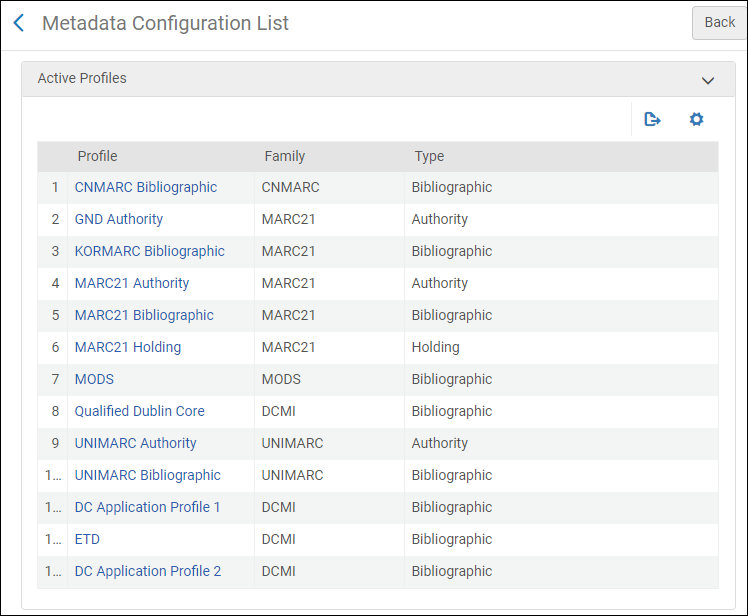
- Klicken Sie auf der Seite Metadaten-Konfigurationsliste (Konfigurationsmenü > Ressourcen > Katalogisierung > Metadaten-Konfiguration) auf den Link (z. B. MARC 21-Titeldaten) für das Profil, das Sie ansehen möchten. Die Seite Profil-Details erscheint.
 Seite MARC 21 Titelsatz-Profildetails
Seite MARC 21 Titelsatz-Profildetails - Wählen Sie Ansicht in der Zeilen-Aktionsliste für die Profildetails, die Sie sehen möchten. Die Seite Felddetails erscheint.
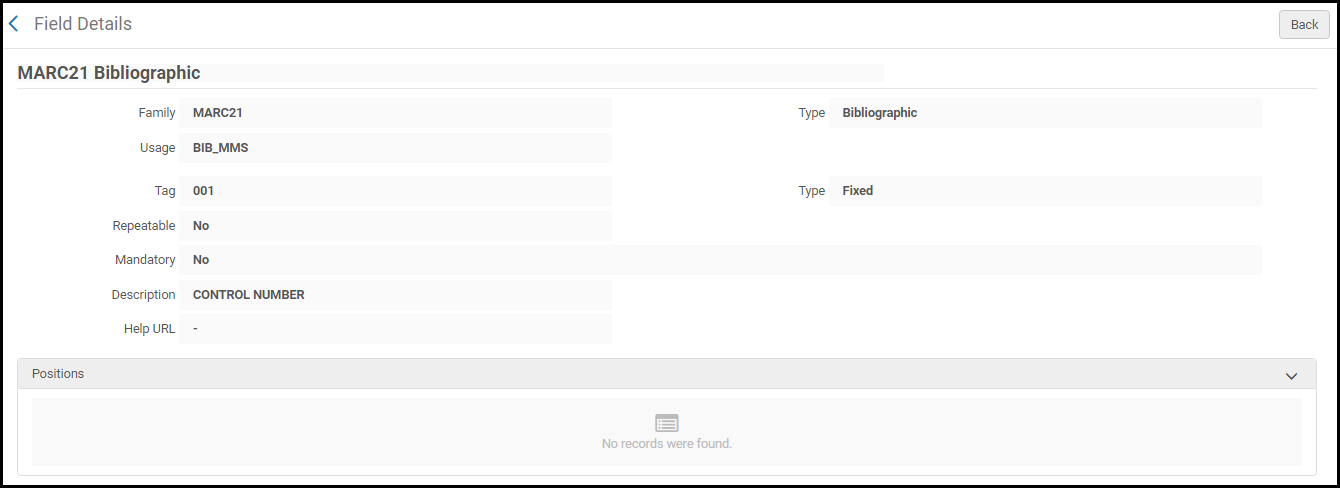 Seite Feld-Details
Seite Feld-Details
Dateidetails bearbeiten
- Allgemeine Informationen (nur DC Anwendungsprofile) – für weitere Informationen siehe DC Anwendungsprofile - Registerkarte Allgemeine Informationen
- Felder – Siehe Bearbeiten von Feldern
- Formulare - Siehe Arbeiten mit Formularen.
- Normierung Prozesse – Siehe Arbeiten mit Normalisierungsprozessen.
- Überprüfungsprozesse – Siehe Bearbeiten von Überprüfungsprozessen.
- Überprüfungs-Ausnahmeprofil-Liste – Siehe Arbeiten mit Überprüfungs-Ausnahmeprofilen
- Anderer Einstellungen - Siehe Konfiguration anderer Einstellungen.
Bearbeiten von Feldern
- Klicken Sie auf der Seite Metadaten-Konfigurationsliste (Konfigurationsmenü > Ressourcen > Katalogisierung > Metadaten-Konfiguration) auf den Link (z. B. MARC 21-Titeldaten) für das Profil, das Sie bearbeiten möchten. Die Seite Profil-Details erscheint.
- Aktivieren Sie für fixe Felder, die im Metadaten-Editor ein Formular zur Katalogisierung anbieten, Formular-Bearbeitung erzwingen, um die Nutzung des Formulars für die Katalogisierung vorauszusetzen. Wenn diese Funktion für ein Feld aktiviert ist, ist die Katalogisierung in Freitext-Form keine Option im Metadaten-Editor.
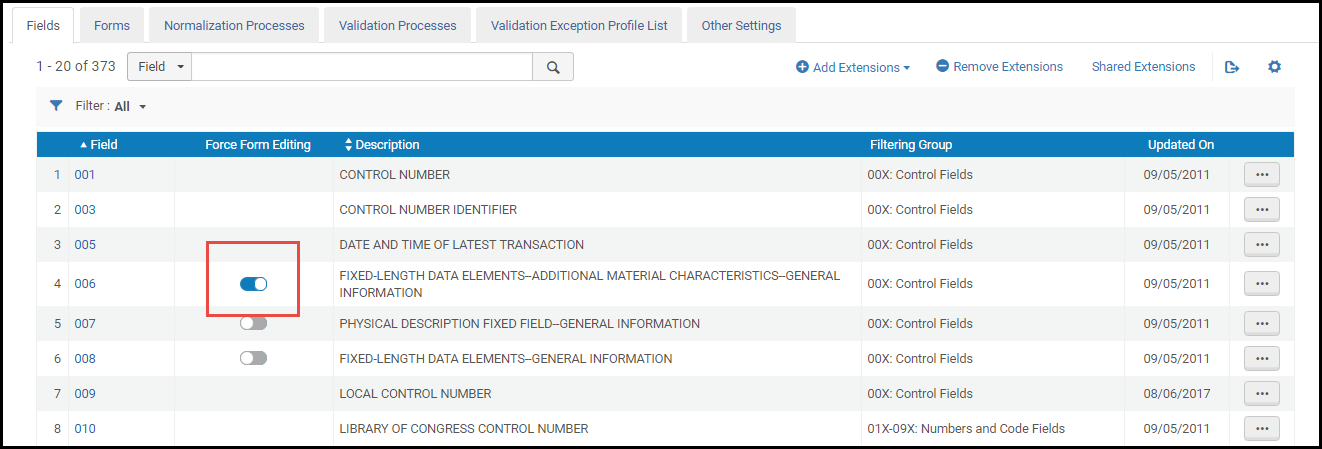 Konfigurationsschieber Formular-Bearbeitung erzwingenSiehe Die Alma-Benutzeroberfläche für Informationen über das Arbeiten mit Schiebern.
Konfigurationsschieber Formular-Bearbeitung erzwingenSiehe Die Alma-Benutzeroberfläche für Informationen über das Arbeiten mit Schiebern. - Wählen Sie für das Feld, das Sie bearbeiten wollen, Anpassen (oder Bearbeiten) in der Zeilen-Aktionsliste. Die Seite Felddetails erscheint.
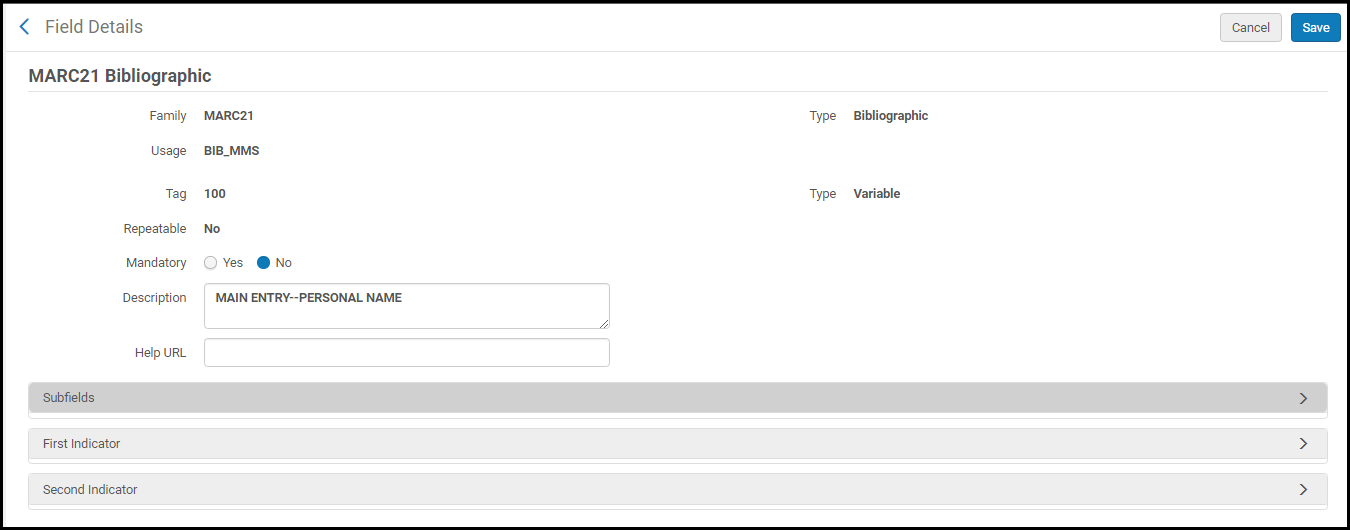 Seite Felddetails anpassen (bearbeiten)
Seite Felddetails anpassen (bearbeiten) - Bearbeiten Sie die folgenden Feld-Optionen (die variieren können), um Ihren Anforderungen zu entsprechen:
- Obligatorisch - Ja oder Nein.
- Beschreibung – Details für Ihre Referenz.
- Hilfe-URL - Eine URL, die zur Hilfe verwendet werden kann. Die Hilfe-Informationen, auf die diese URL verweist, erscheinen in der Registerkarte Information im MD-Editor. Wenn Sie dieses Feld leer lassen, sind die Standard-Katalogisierungsinformationen der Library of Congress Standard.
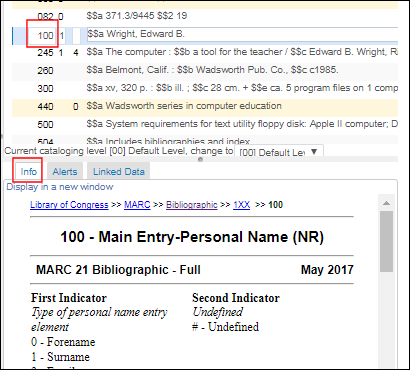 MD-Editor - Registerkarte Information, in Verbindung mit der Hilfe-URL-Option
MD-Editor - Registerkarte Information, in Verbindung mit der Hilfe-URL-Option - Unterfelder – Sie können für jedes Unterfeld Ja oder Nein wählen, um anzuzeigen, dass das Unterfeld ein Pflichtfeld und/oder wiederholbar ist.
- Wählen Sie Vorgegebenen Wortschatz zuweisen in der Zeilen-Aktionsliste für das Unterfeld, dem Sie einen spezifischen, vorgegebenen Wortschatz zuweisen wollen. Die Seite Profildetails erscheint mit dem Abschnitt Neuen CV-Wert erstellen.
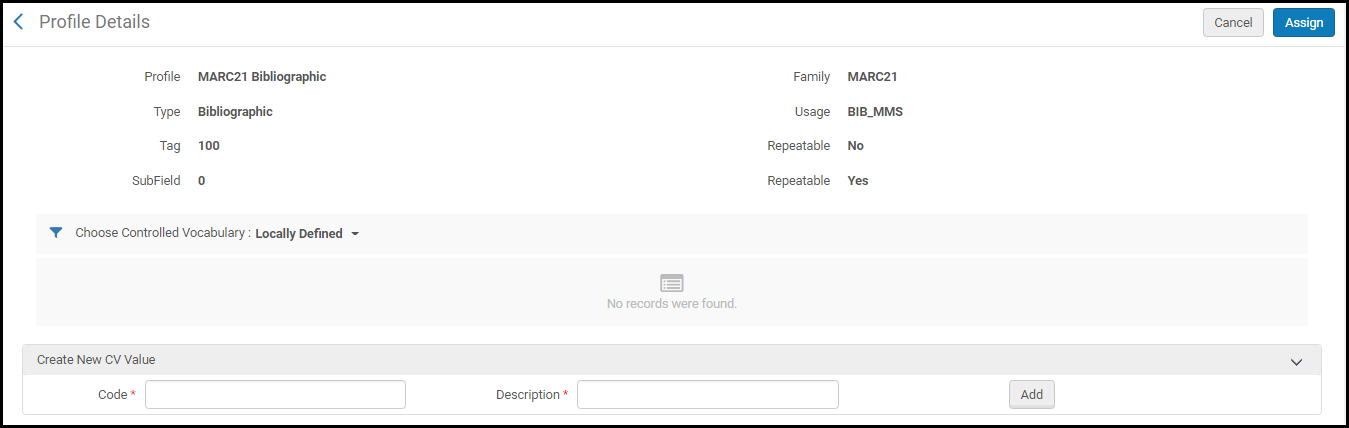
- Wählen Sie einen vorgegebenen Wortschatz (CV) aus der Dropdown-Liste Vorgegebenen Wortschatz auswählen. Die in dieser Liste angezeigten Optionen werden unter Konfigurieren des vorgegebenen Wortschatz-Registers konfiguriert. Die Details des von Ihnen ausgewählten vorgegebenen Wortschatzes erscheinen. Klicken Sie auf Zuweisen, um diese Auswahl zu speichern.
Sie können den Abschnitt Neuen CV-Wert erstellen nach Belieben verwenden, um vorgegebene Wortschatz-Begriffe hinzuzufügen. Die Begriffe, die Sie hier hinzufügen, gelten nur für das Feld, das Sie bearbeiten. Wenn Sie diese Begriffe in einem anderen Feld nutzen wollen, verwenden Sie das vorgegebene Wortschatz-Register (siehe Konfiguration eines vorgegebenen Wortschatz-Registers), um ein CV zu erstellen, das in mehr als einem Feld verwendet werden kann.Um einen vorgegebenen Wortschatz-Wert im Abschnitt Neuen CV-Wert erstellen hinzuzufügen, geben Sie einen Code und eine Beschreibung ein und klicken Sie auf Hinzufügen. Wenn Sie mit dem Hinzufügen der Begriffe fertig sind, klicken Sie auf Zuordnen.
- Wählen Sie Vorgegebenen Wortschatz zuweisen in der Zeilen-Aktionsliste für das Unterfeld, dem Sie einen spezifischen, vorgegebenen Wortschatz zuweisen wollen. Die Seite Profildetails erscheint mit dem Abschnitt Neuen CV-Wert erstellen.
- Erster Indikator – Nehmen Sie im Abschnitt Erster Indikator auf der Seite Felddetails die erforderlichen Änderungen vor.
- Zweiter Indikator – Nehmen Sie im Abschnitt Zweiter Indikator auf der Seite Felddetails die erforderlichen Änderungen vor.
- Wählen Sie Speichern. Die Änderungen der Felder werden im Metadaten-Profil gespeichert.
- Wählen Sie Umsetzen.
Wiederherstellen von Profil-Feld-Details
- Wählen Sie aus der Registerkarte Felder auf der Seite Profildetails für das Profil, das Sie wiederherstellen wollen, Aktionen > Wiederherstellen in der Zeilen-Aktionsliste. Die Änderung des Profils, das lokal angepasst wurde, wird wieder auf den Standardwert des Feldes zurückgesetzt.
- Wählen Sie Umsetzen.
Bearbeiten von MARC-basierenden Profilen mit Erweiterungsstapeln
| Profile Element | LDR | Kontrollfelder/Fixes Feld | Datenfeld |
|---|---|---|---|
|
Feldcodes |
Voreingestellte Felder und angepasste Felder, die im Profil bestehen, blieben unverändert. Neue Felder aus dem Erweiterungsstapel werden hinzugefügt. |
Voreingestellte Felder und angepasste Felder, die im Profil bestehen, blieben unverändert. Neue Felder aus dem Erweiterungsstapel werden hinzugefügt. |
|
|
Unterfeld-Codes |
Voreingestellte Codes und angepasste Codes, die im Profil bestehen, blieben unverändert. Neue Codes aus dem Erweiterungsstapel werden hinzugefügt. |
||
|
Positionen |
Voreingestellte Positionen, die im Profil bestehen, werden entfernt. Angepasste Positionen, die im Profil bestehen, bleiben unverändert. Neue Positionen aus dem Erweiterungsstapel werden hinzugefügt. |
Voreingestellte Positionen, die im Profil bestehen, werden entfernt. Angepasste Positionen, die im Profil bestehen, bleiben unverändert. Neue Positionen aus dem Erweiterungsstapel werden hinzugefügt. |
|
|
Positionswerte |
Voreingestellte Werte, die im Profil bestehen, blieben unverändert. Angepasste Werte, die im Profil bestehen, werden durch die neuen Werte aus dem Erweiterungspaket ersetzt. |
Voreingestellte Werte, die im Profil bestehen, blieben unverändert. Angepasste Werte, die im Profil bestehen, werden durch die neuen Werte aus dem Erweiterungspaket ersetzt. |
|
|
Indikator Werte |
Voreingestellte Werte, die im Profil bestehen, blieben unverändert. Angepasste Werte, die im Profil bestehen, werden durch die neuen Werte aus dem Erweiterungspaket ersetzt. |
||
|
Steuerunterfeld Wortschatz |
Voreingestellte und angepasste Werte, die im Profil bestehen, werden durch die neuen Werte aus dem Erweiterungspaket ersetzt. |
Verwalten von Erweiterungsstapeln
- Erstellen Sie lokal eine .xml-Erweiterungsdatei (siehe Erweiterungsstapel .xml-Dateibeispiel für weitere Informationen).
- Klicken Sie auf der Seite Metadaten-Konfigurationsliste auf den Link für das MARC-basierende Profil, das Sie erweitern wollen (Konfigurationsmenü > Ressourcen > Katalogisierung > Metadaten-Konfiguration).
-
Wählen Sie in der Registerkarte Felder eine Option im Menü Erweiterungen hinzufügen.
- An Institution
Verwenden Sie diese Option, um einen Erweiterungsstapel als .xml-Datei zum Profil hinzuzufügen, das Sie konfigurieren.Wenn Sie diese Option auswählen, können Sie sich entscheiden, einen Erweiterungsstapel als .xml-Datei zu Ihrem MARC-basierenden Profil von der Gemeinschaftszone oder einem Ihrer lokalen Felder hinzuzufügen.
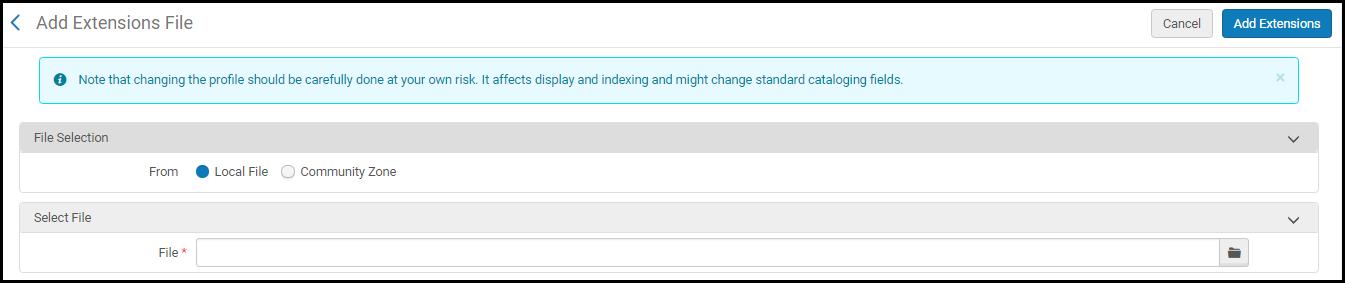 Hinzufügen eines Erweiterungsstapels als .xml-Datei zum MARC-basierenden ProfilWenn Sie die Option Gemeinschaftszone auswählen, erscheint eine Liste der in der Gemeinschaftszone gemeinsam genutzten .xml-Dateien und Sie können wählen, einen Erweiterungsstapel als .xml-Datei in Ihren lokalen Speicher herunterzuladen oder den Erweiterungsstapel als .xml-Datei direkt zu Ihrem Profil hinzuzufügen.
Hinzufügen eines Erweiterungsstapels als .xml-Datei zum MARC-basierenden ProfilWenn Sie die Option Gemeinschaftszone auswählen, erscheint eine Liste der in der Gemeinschaftszone gemeinsam genutzten .xml-Dateien und Sie können wählen, einen Erweiterungsstapel als .xml-Datei in Ihren lokalen Speicher herunterzuladen oder den Erweiterungsstapel als .xml-Datei direkt zu Ihrem Profil hinzuzufügen.
- An Institution
- An Gemeinschaft
Verwenden Sie diese Option, um einen Erweiterungsstapel als .xml-Datei zur Gemeinschaftszone hinzuzufügen, um sie mit anderen Institutionen gemeinsam zu nutzen.Wenn Sie diese Option auswählen, werden Sie aufgefordert, die folgenden Details für den Beitrag des Erweiterungsstapels anzugeben: Name des Erweiterungsstapels, Beschreibung, Name des Kontaktes für den Erweiterungsstapel, E-Mail-Adresse des Kontaktes und der Erweiterungsstapel als .xml-Datei.
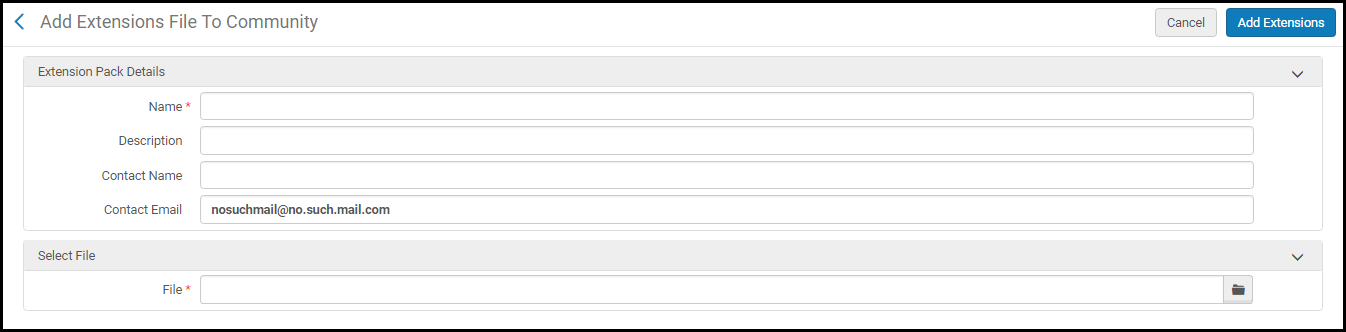 Hinzufügen eines Erweiterungsstapels zur Gemeinschaftszone
Hinzufügen eines Erweiterungsstapels zur Gemeinschaftszone - Wählen Sie Erweiterungen hinzufügen. .
Für zur Gemeinschaftszone hinzugefügte Erweiterungsstapel als .xml-Dateien, erscheint die hinzugefügte Datei und die Beitrags-Meldung auf der Seite Geteilte Erweiterungen.
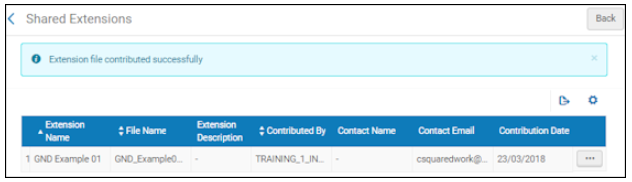 Seite Geteilte ErweiterungenWenn das System während der Bearbeitung mehr als ein Ereignis mit demselben Wert auftritt, zählt das erste Ereignis und die überzähligen Ereignisse werden ignoriert.
Seite Geteilte ErweiterungenWenn das System während der Bearbeitung mehr als ein Ereignis mit demselben Wert auftritt, zählt das erste Ereignis und die überzähligen Ereignisse werden ignoriert. - Überprüfen und bestätigen Sie Ihre Änderungen.
- Wählen Sie Umsetzen.
Wenn ein Mitglied einen Institutionszonen-Datensatz eines MARC-Profils bearbeitet, das ein Erweiterungspaket auf der IZ-Ebene hat, ist der kontrollierte Wortschatzteil des IZ-Erweiterungspakets nur dann verfügbar, wenn ein lokales Erweiterungsfeld (mit dem Institutionssymbol
Extension Pack .xsd
<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema"
elementFormDefault="qualified" targetNamespace="http://com/exlibris/repository/mdprofile/xmlbeans"
xmlns="http://com/exlibris/repository/mdprofile/xmlbeans">
<!-- marc_profile element definition -->
<xs:element name="marc_profile">
<xs:complexType>
<xs:sequence>
<xs:element ref="leader_configuration" minOccurs="1"
maxOccurs="1" />
<xs:element ref="control_fields_list" minOccurs="1"
maxOccurs="1" />
<xs:element ref="data_fields_list" minOccurs="1"
maxOccurs="1" />
</xs:sequence>
</xs:complexType>
</xs:element>
<!-- XSD element definition -->
<!-- leader element definition -->
<xs:element name="leader_configuration">
<xs:complexType>
<xs:sequence>
<xs:element name="positions_list" minOccurs="1"
maxOccurs="1" type="positionsListType" />
</xs:sequence>
</xs:complexType>
</xs:element>
<!-- control_fields_list element definition -->
<xs:element name="control_fields_list">
<xs:complexType>
<xs:sequence>
<xs:element name="control_field_configuration" minOccurs="0"
maxOccurs="unbounded">
<xs:complexType>
<xs:sequence>
<xs:element name="description" minOccurs="1"
maxOccurs="1" type="xs:string" />
<xs:element name="help_url" minOccurs="0"
maxOccurs="1" type="xs:string" />
<xs:element name="materials_type_list" minOccurs="1"
maxOccurs="1" type="materialstypeListType" />
</xs:sequence>
<xs:attribute name="tag" type="tagType" use="required" />
<xs:attribute name="repeatable" type="xs:boolean"
use="required" />
<xs:attribute name="mandatory" type="xs:boolean" use="optional" />
</xs:complexType>
</xs:element>
</xs:sequence>
</xs:complexType>
</xs:element>
<!-- data_fields_list element definition -->
<xs:element name="data_fields_list">
<xs:complexType>
<xs:sequence>
<xs:element name="data_field_configuration" minOccurs="0"
maxOccurs="unbounded">
<xs:complexType>
<xs:sequence>
<xs:element name="description" minOccurs="1"
maxOccurs="1" type="xs:string" />
<xs:element name="help_url" minOccurs="0"
maxOccurs="1" type="xs:string" />
<xs:element name="first_indicator_configuration" type="indicatorType"
minOccurs="0" maxOccurs="1" />
<xs:element name="second_indicator_configuration"
type="indicatorType" minOccurs="0" maxOccurs="1" />
<xs:element name="sub_fields_list" minOccurs="0"
maxOccurs="1" type="subfieldType">
<xs:key name="sub_field_configuration-unique">
<xs:selector xpath="sub_field_configuration" />
<xs:field xpath="@code" />
</xs:key>
</xs:element>
</xs:sequence>
<xs:attribute name="tag" type="tagType" use="required" />
<xs:attribute name="repeatable" type="xs:boolean"
use="required" />
<xs:attribute name="mandatory" type="xs:boolean" use="optional" />
</xs:complexType>
</xs:element>
</xs:sequence>
</xs:complexType>
</xs:element>
<!-- XSD complex type definition -->
<xs:complexType name="positionsListType">
<xs:sequence>
<xs:element name="position_configuration" type="positionType"
minOccurs="0" maxOccurs="unbounded" />
</xs:sequence>
</xs:complexType>
<xs:complexType name="positionType">
<xs:sequence>
<xs:element name="description" minOccurs="1" maxOccurs="1"
type="xs:string" />
<xs:element name="values" minOccurs="1" maxOccurs="1"
type="valuesType" />
</xs:sequence>
<xs:attribute name="start" type="customIntegerType" use="required" />
<xs:attribute name="end" type="customIntegerType" use="required" />
</xs:complexType>
<xs:complexType name="valuesType">
<xs:sequence>
<xs:element name="value" minOccurs="0" maxOccurs="unbounded">
<xs:complexType>
<xs:simpleContent>
<xs:extension base="xs:string">
<xs:attribute name="code" type="codeType" use="required" />
</xs:extension>
</xs:simpleContent>
</xs:complexType>
</xs:element>
</xs:sequence>
</xs:complexType>
<xs:complexType name="subfieldValuesType">
<xs:sequence>
<xs:element name="value" minOccurs="0" maxOccurs="unbounded">
<xs:complexType>
<xs:simpleContent>
<xs:extension base="xs:string">
<xs:attribute name="code" type="codeType" use="required" />
</xs:extension>
</xs:simpleContent>
</xs:complexType>
</xs:element>
</xs:sequence>
<xs:attribute name="codeTable" type="xs:string" />
</xs:complexType>
<xs:complexType name="indicatorType">
<xs:sequence>
<xs:element name="description" minOccurs="1" maxOccurs="1"
type="xs:string" />
<xs:element name="values" minOccurs="1" maxOccurs="1"
type="valuesType" />
</xs:sequence>
<xs:attribute name="mandatory" type="xs:boolean" use="optional" />
</xs:complexType>
<xs:complexType name="subfieldType">
<xs:sequence>
<xs:element name="sub_field_configuration" minOccurs="0"
maxOccurs="unbounded">
<xs:complexType>
<xs:sequence>
<xs:element name="description" minOccurs="1" maxOccurs="1"
type="xs:string" />
<xs:element name="values" minOccurs="0" maxOccurs="1"
type="subfieldValuesType" />
<xs:element name="materials_type_list" minOccurs="0"
maxOccurs="1" type="materialstypeListType" />
</xs:sequence>
<xs:attribute name="code" type="subfieldCodeType" use="required" />
<xs:attribute name="repeatable" type="xs:boolean" use="required" />
<xs:attribute name="mandatory" type="xs:boolean" use="optional" />
</xs:complexType>
</xs:element>
</xs:sequence>
</xs:complexType>
<xs:complexType name="materialstypeListType">
<xs:sequence>
<xs:element name="material_type_configuration" minOccurs="0"
maxOccurs="unbounded" type="materialtypeType">
</xs:element>
</xs:sequence>
</xs:complexType>
<xs:complexType name="materialtypeType">
<xs:sequence>
<xs:element name="positions_list" minOccurs="1" maxOccurs="1"
type="positionsListType" />
</xs:sequence>
<xs:attribute name="name" type="xs:string" use="required" />
</xs:complexType>
<!-- XSD simple type definition -->
<xs:simpleType name="tagType">
<xs:restriction base="xs:string">
<xs:pattern value="[0-9]{3}" />
</xs:restriction>
</xs:simpleType>
<xs:simpleType name="customIntegerType">
<xs:restriction base="xs:string">
<xs:pattern value="[0-9]+" />
</xs:restriction>
</xs:simpleType>
<xs:simpleType name="codeType">
<xs:restriction base="xs:string">
<xs:pattern value="[a-z#0-9|]+" />
</xs:restriction>
</xs:simpleType>
<xs:simpleType name="subfieldCodeType">
<xs:restriction base="xs:string">
<xs:pattern value="[a-z0-9]{1}" />
</xs:restriction>
</xs:simpleType>
</xs:schema>
Extension Pack .xml File Example
<marc_profile xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:noNamespaceSchemaLocation="marc21_profile_configuration.xsd">
<control_fields_list>
<control_field_configuration mandatory="true" repeatable="false"
tag="003">
<description>PERSISTENT RECORD IDENTIFIER</description>
<materials_type_list />
</control_field_configuration>
</control_fields_list>
<data_fields_list>
<data_field_configuration repeatable="true" mandatory="false" tag="020" xmlns="http://com/exlibris/repository/mdprofile/xmlbeans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<sub_fields_list>
<sub_field_configuration code="9" mandatory="false" repeatable="true">
<description>Former ISBN
</description>
</sub_field_configuration>
</sub_fields_list>
</data_field_configuration>
<data_field_configuration repeatable="true" mandatory="false" tag="024" xmlns="http://com/exlibris/repository/mdprofile/xmlbeans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<sub_fields_list>
<sub_field_configuration code="9" mandatory="false" repeatable="true">
<description>Former ISSN
</description>
</sub_field_configuration>
</sub_fields_list>
</data_field_configuration>
<data_field_configuration repeatable="false" mandatory="false" tag="689" xmlns="http://com/exlibris/repository/mdprofile/xmlbeans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<description>SUBJECT HEADING CHAIN</description>
<help_url>http://www.google.com</help_url>
<first_indicator_configuration>
<description>Type of subject heading chain</description>
<values>
<value code="0">Simple chain</value>
<value code="1">Complex chain</value>
</values>
</first_indicator_configuration>
<second_indicator_configuration>
<description>Undefined</description>
<values>
<value code="#">Undefined</value>
</values>
</second_indicator_configuration>
<sub_fields_list>
<sub_field_configuration code="a" mandatory="true" repeatable="false">
<description>Heading chain first element
</description>
</sub_field_configuration>
<sub_field_configuration code="b" mandatory="false" repeatable="true">
<description>Heading chain second element</description>
</sub_field_configuration>
<sub_field_configuration code="c" mandatory="true" repeatable="true">
<description>Type of chain</description>
<values>
<value code="0">GND chain</value>
<value code="1">DNB chain</value>
</values>
</sub_field_configuration>
</sub_fields_list>
</data_field_configuration>
</data_fields_list>
</marc_profile>
Arbeiten mit Formularen
Sie können zudem MARC-Felder Beschriftungen zuordnen, die zum Erstellen von Formularen verwendet werden. Siehe MARC Slim Konfiguration.
- Wählen Sie die Registerkarte Formulare, wenn Sie qualifizierte Dublin-Core-, MARC Bibliografisch- oder MODS-Profile konfigurieren.
- Klicken Sie auf Neues Formular und wählen Sie eine der folgenden Optionen:
Die folgende erscheint:
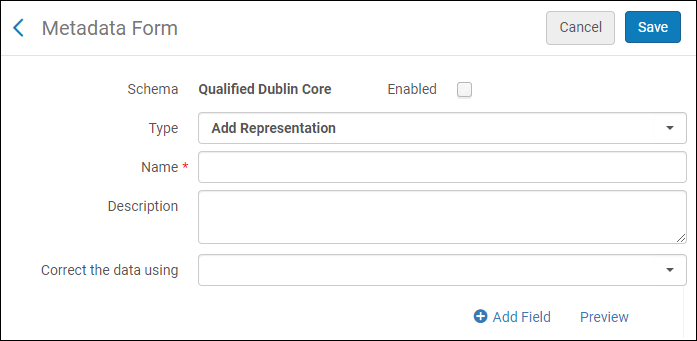 Metadaten-Formulare
Metadaten-Formulare - Füllen Sie Felder des Formulars aus und klicken Sie auf Neues Feld. Eine Liste der Feldtypen wird angezeigt:
- Kontrollkästchen - Ein einzelnes Kontrollkästchen, das ausgewählt oder deaktiviert werden kann
- Kombinationsfeld Mehrfachauswahl - Eine Dropdown-Liste mit Kontrollkästchen. Es können mehrere Kontrollkästchen aktiviert werden.
- Kombinationsfeld Einzelauswahl- eine Dropdown-Liste mit Optionen. Es kann nur eine Option ausgewählt werden.
- Datum – eine Datumsauswahl
- Verborgen - Ein verborgenes Feld, das zum automatischen Hinzufügen vordefinierter Felder und Werte zum Metadatensatz verwendet wird.
- Optionsfeld - Es werden mehrere Optionsfelder angezeigt. Es kann nur eine Option ausgewählt werden.
- Textbereich - ein mehrzeiliges Textfeld
- Textfeld - ein einzeiliges Textfeld
- Nachschlagen – Optionen werden während der Eingabe angezeigt, oder Sie wählen das Symbol aus, um eine Seite mit Optionen zu öffnen. Es kann nur eine Option ausgewählt werden.
Das Hinzufügen des Feldes Nachschlagen zu Formularen ist nur für Repräsentationen und von Mitarbeitern vermittelte Depots verfügbar.
- Wählen Sie einen Feldtyp. Die Felder für den von Ihnen ausgewählten Feldtyp werden angezeigt. Beispiel:
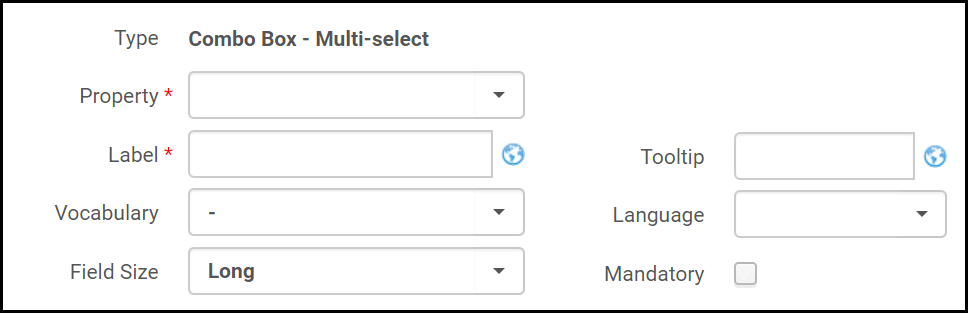 Formularfelder (Dublin Core Formular)
Formularfelder (Dublin Core Formular) - Füllen Sie die Felder folgendermaßen aus:
- Eigenschaft / Feld - Die Eigenschaft, die Sie dem Formular hinzufügen möchten (für Dublin Core), oder das Feld, das Sie dem Formular hinzufügen möchten (für MARC 21).
- Attributname – (nur MODS) Wählen Sie einen Attributnamen für das ausgewählte Feld aus.
- Attributwert – (nur MODS) Geben Sie einen Wert für das ausgewählte Attribut ein.
- Beschriftung – Die Beschriftung der Eigenschaft.
- Wortschatz - Wählen Sie einen Wortschatz aus, um die Optionen zu bestimmen, die dem Benutzer für dieses Feld angezeigt werden. Weitere Informationen finden Sie unter Vorgegebener Wortschatz - Register - Formulare.
- Feldgröße – Wählen Sie, ob das Feld kurz oder lang sein soll.
- Kurzinfo - Eine Kurzinfo-Nachricht, die angezeigt werden soll.
- Sprache - die Sprachen, die die Institution als Abschluss- oder Dissertationssprache akzeptiert.
- Standardwert - Wählen Sie einen Standardwert aus, der im Formular erscheinen soll.
- Obligatorisch – Wählen Sie diese Option aus, wenn das Feld ein Pflichtfeld sein soll.
- Wiederholbar - Wählen Sie diese Option, damit der Benutzer mehrere Instanzen des Felds hinzufügen kann.
- Klicken Sie auf Speichern in Liste. Die Eigenschaft wird zum Formular hinzugefügt.
- Wiederholen Sie die Schritte, um Felder zum Formular hinzuzufügen. Klicken Sie auf Vorschau , um eine Vorschau des Formulars anzusehen.
- Wenn Sie mit dem Hinzufügen von Feldern zum Formular fertig sind, klicken Sie auf Speichern.
Arbeiten mit Normierungs-Prozessen
- Erstellen eines benutzerdefinierten Normalisierungsprozesses. Siehe Konfiguration der Katalogisierung unten.
- Bearbeiten eines Normalisierungsprozesses – Wählen Sie Bearbeiten aus der Zeilen-Aktionsliste. Die Einstellungen für einen bestehenden Normalisierungsprozess erscheinen in den folgenden Registerkarten:
- Allg. Angaben
- Aufgabe List
- Aufgaben-Parameter
- Duplizieren Sie einen Normalisierungsprozess, um Änderungen an der Kopie vorzunehmen – Wählen Sie Kopieren aus den Zeilen-Aktionen.
- Deaktivieren eines Normalisierungsprozesses – Wenn der Normalisierungsprozess aktuell nicht benötigt wird, aber in Zukunft vielleicht noch benötigt wird, können Sie ihn deaktivieren, indem Sie auf das Häkchen in der Spalte Aktiv klicken.
- Löschen eines Normalisierungsprozesses – Wählen Sie Löschen aus der Zeilen-Aktionsliste.
Einen Normierungsprozess erstellen
- Wählen Sie auf der Seite Profildetails in der Registerkarte Normalisierungsprozesse Neuer Prozess(Konfigurationsmenü > Ressourcen > Katalogisierung > Metadaten-Konfiguration und wählen Sie einen Profil-Link). Alternativ können Sie Prozesse auch auf der Seite Prozessliste erstellen (Konfigurationsmenü > Ressourcen > Allgemein > Prozesse).
Um eine Kopie eines bestehenden Prozesses zu erstellen, wählen Sie Kopieren aus der Zeilen-Aktionsliste. Sobald Sie den Prozess kopiert haben, können Sie ihn nach Bedarf ändern.
- Im Abschnitt Allgemeine Informationen:
- Geben Sie den Namen und die Beschreibung für den Prozess ein. Diese Werte sind auf der Seite Prozessliste für Benutzer sichtbar.
- Wählen Sie im Feld Status aus, ob der Prozess aktiviert ist (Aktiv) oder nicht. Ein Prozess, der deaktiviert ist, kann im System gespeichert und bearbeitet werden, ohne ausgeführt zu werden. Er kann jederzeit aktiviert werden.
- Klicken Sie auf Weiter und dann auf Neue Aufgaben.
- Wählen Sie die erforderlichen Aufgaben aus und klicken Sie auf Hinzufügen und schließen.
Diese Seite enthält einen vordefinierten Speichereine vordefinierte Liste an Aufgaben, die Sie in Ihren Prozess (oder Ihre Aufgabenkette) aufnehmen können. Siehe Optionen der Aufgabenliste für die Beschreibung der Aufgaben.
Sie können keine zusätzlichen Aufgaben definieren und die meisten dieser Aufgaben haben feste Parameter. Die Aufgaben variieren abhängig von der Metadaten-Konfiguration, die Sie bearbeiten.
Klicken Sie auf die Aufgabe "MarcDroolNormalization" (DcDroolNormalization oder Marc XSL Normalisierung),um im nächsten Schritt die Normalisierungsregeln auszuwählen, die Sie im MD-Editor erstellt haben (siehe Arbeiten mit Normalisierungsregeln). - Verwenden Sie die Aufwärts- und Abwärts-Pfeile, um die Reihenfolge zu ordnen, in der die Aufgaben ausgeführt werden sollen.
- Wählen Sie Weiter. Die nächste Seite des Assistenten erscheint.
Die angezeigten Parameter variieren je nach ausgewählten Aufgaben. - Wählen Sie Speichern.
Optionen der Aufgabenliste
| Prozessname | Beschreibung |
|---|---|
|
852 Feld-Normierung |
Führt eine Aufgabe aus, die die Kontrollnummer des Titelsatzes entnimmt und sie in das korrekte Unterfeld im Lokalsatz einfügt. Für weitere Informationen siehe Arbeiten mit MARC 21 Bestandsprofilen. |
| addBibToCollectionNormalizationTask | Weist importierte digitale Titel dem Wert im Feld 787 des MARC-Datensatzes automatisch zu einer Sammlung zu. Für weitere Informationen siehe Importprofile verwalten. |
| Hinzufügen von Transkriptionen von Hanja zu Hangul | Wandelt durch Konfiguration von Quell- und Zielfeldern Inhalte, wie einen Titel, von Hanja zu Hangul um. Für weitere Informationen siehe Arbeiten mit CJK-Transliterationen in der Katalogisierung. Dieser Transliterations-Prozess kann für die Konfigurationen von MARC 21-Titeldaten und MARC 21-Normdateien verwendet werden, sowie für eine Vielzahl an MARC-Konfigurationen wie KORMARC, UNIMARC, CNMARC usw. |
| Hinzufügen von Transkriptionen von Hanja zu Hangul CK | Wandelt durch Konfiguration von Quell- und Zielfeldern Inhalte, wie einen Titel, von Hanja zu Hangul CK um. Für weitere Informationen siehe Arbeiten mit CJK-Transliterationen in der Katalogisierung. Dieser Transliterations-Prozess kann für die Konfigurationen von MARC 21-Titeldaten und MARC 21-Normdateien verwendet werden, sowie für eine Vielzahl an MARC-Konfigurationen wie KORMARC, UNIMARC, CNMARC usw. |
| Hinzufügen von Transkriptionen von Hanja zu Hangul MOE | Wandelt durch Konfiguration von Quell- und Zielfeldern Inhalte, wie einen Titel, von Hanja zu Hangul MOE um. Für weitere Informationen siehe Arbeiten mit CJK-Transliterationen in der Katalogisierung. Dieser Transliterations-Prozess kann für die Konfigurationen von MARC 21-Titeldaten und MARC 21-Normdateien verwendet werden, sowie für eine Vielzahl an MARC-Konfigurationen wie KORMARC, UNIMARC, CNMARC usw. |
| Hinzufügen von Transkriptionen von Hanja zu Pinyin | Wandelt durch Konfiguration von Quell- und Zielfeldern Inhalte, wie einen Titel, von Hanja zu Pinyin um. Für weitere Informationen siehe Arbeiten mit CJK-Transliterationen in der Katalogisierung. Dieser Transliterations-Prozess kann für die Konfigurationen von MARC 21-Titeldaten und MARC 21-Normdateien verwendet werden, sowie für eine Vielzahl an MARC-Konfigurationen wie KORMARC, UNIMARC, CNMARC usw. |
| Hinzufügen von Transkriptionen von Hanzi zu Pinyin | Wandelt chinesische Inhalte zu Pinyin um.
Konfiguration
Die Konfiguration für diesen Prozess erfordert, dass Sie die Quell- und Zielfelder/-unterfelder von Hanzi zu Pinyin spezifizieren
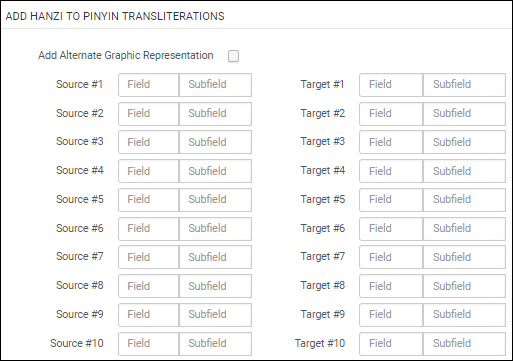 Aufgabenkonfiguration: Hanja zu Pinyin
Wenn die Normalisierung verarbeitet wird, sind die ersten und zweiten Indikatoren im Zielfeld gleich wie die Indikatoren im Quellfeld.
Die transkribierten Worte werden in das Zielfeld/-unterfeld platziert und nur die Worte, die mehr als eine Transliteration haben, werden im Zielfeld/-unterfeld in eckige Klammern < > gestellt. Der Katalogisierer kann das richtige auswählen und die anderen löschen.
Beachten Sie, dass bei Institutionen, die für die Hongkong-Chinesisch-Suchsprache konfiguriert sind, der Transkriptionsprozess von Hanzi nach Pinyin die am häufigsten verwendete Transkription des Wortes zum Datensatz hinzufügt, anstatt alle möglichen Transkriptionsoptionen in spitzen Klammern anzugeben.
Wenn Inhalte im Ziel-Unterfeld existieren, werden sie vom Normalisierungsprozess überschrieben.
Das Löschen der Unterfelder wird nicht als Teil dieses Normalisierungsprozesses behandelt. Um Unterfelder zu löschen, wählen Sie einen Normalisierungsprozess aus, der für diese Ausgabe vorgesehen ist.
Wählen Sie die Option Neue alternative grafische Darstellung, um das Feld 880 als Ziel für die Transkription von Hanzi zu Pinyin identifizieren. Wenn Sie diese Option verwenden, müssen Sie nur die Quellfelder angeben. Alle Teilfelder in den Quellfeldern werden zu 880-Feldern transliteriert.
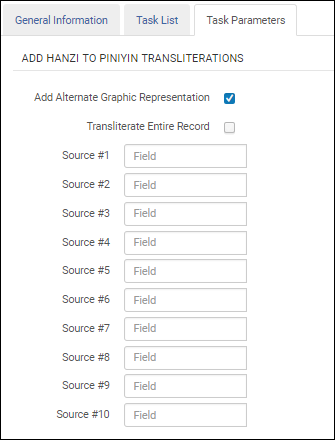 Neue alternative grafische Darstellung
Wählen Sie die Option Gesamten Datensatz transkribieren, um alle Felder eines Datensatzes on Hanja zu Pinyin zu transkribieren. Diese Option erscheint, nachdem Sei die Option Neue alternative grafische Darstellung gewählt haben. Da alle Felder (mit Ausnahme jener ohne chinesischer Zeichen) transkribiert werden, müssen Sie keine Quellenfelder in der Aufgabenkonfiguration festlegen.
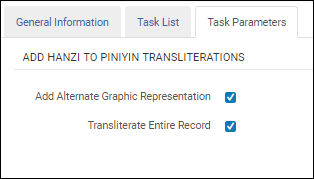 Gesamten Datensatz transkribieren
Großschreibung
Bei allen MARC 21 Feldern, die mit einem chinesischen Zeichen beginnen und transkribiert werden, wird das erste transkribierte Zeichen groß geschrieben.
Personennamen
Wenn Sie die Normalisierungsaufgabe Hinzufügen von Transkriptionen von Hanzi zu Pinyin verwenden und Ihre Institution von Ex Libris mit der Suchsprachen-Konfiguration Hongkong konfiguriert ist, werden Personennamen, die sich im Unterfeld $a der Felder 100, 600, 700 und 800 befinden, folgendermaßen bearbeitet:
Im nachfolgenden Beispiel sehen Sie die Hongkong Transkription im Vergleich zur Chinesischen Transkription.
Hongkong:
毛澤東 => Mao, Zedong
Chinesisch:
毛澤東 => mao ze dong
Für weitere Informationen siehe Arbeiten mit CJK-Transliterationen in der Katalogisierung. Dieser Transliterationsprozess kann für die Profile MARC 21-Titeldaten und CNMARC verwendet werden.
|
| Hinzufügen von Transkriptionen von Kana zu Hangul | Wandelt durch Konfiguration von Quell- und Zielfeldern Inhalte, wie einen Titel, von Kana zu Hangul um. Für weitere Informationen siehe Arbeiten mit CJK-Transliterationen in der Katalogisierung. Dieser Transliterations-Prozess kann für die Konfigurationen von MARC 21-Titeldaten und MARC 21-Normdateien verwendet werden, sowie für eine Vielzahl an MARC-Konfigurationen wie KORMARC, UNIMARC, CNMARC usw. |
| Hinzufügen von Transkriptionen von Kana zu romanisiertem Kana | Wandelt durch Konfiguration von Quell- und Zielfeldern Inhalte, wie einen Titel, von Kana zu romantisiertem Kana um. Für weitere Informationen siehe Arbeiten mit CJK-Transliterationen in der Katalogisierung. Dieser Transliterations-Prozess kann für die Konfigurationen von MARC 21-Titeldaten und MARC 21-Normdateien verwendet werden, sowie für eine Vielzahl an MARC-Konfigurationen wie KORMARC, UNIMARC, CNMARC usw. |
| addMmsIdToDcIdentifier | Fügt die MMSID dem Feld dc:identifier von DC-Datensätzen hinzu. |
| AuthorityGenerateControlNumberSequence | Führt eine Aufgabe aus, die eine Kontrollnummernfolge für einen Normdatei-Datensatz erzeugt. |
| BibGenerateControlNumberSequence | Führt eine Aufgabe aus, die eine Kontrollnummernfolge für einen Titelsatz erzeugt. |
|
BibGenerateLocalControlNumberSequence |
Führt eine Aufgabe (in MARC 21) zur Erstellung einer Signatur aus, die im Feld 035 gespeichert wird, wenn beispielsweise Bearbeiten > Datensatz erweitern während der Bearbeitung eines Datensatzes im MD-Editor ausgewählt ist.
Wenn Sie einen neuen Prozess hinzufügen, klicken Sie auf Neue Aufgaben, dann wählen Sie Generieren einer lokalen Kontrollnummernfolge, klicken Sie auf Hinzufügen und schließen und anschließend auf Weiter, um die Aufgabenparameter einzustellen.
Beachten Sie, dass „BIB-Zielfeld“ eine einzelne Option auflistet: '035 Unterfeld a'. |
| BibGenerateHandle | |
| CnmarcBibAdd005Task | Das Feld 005 wird nur hinzugefügt, wenn es im MD-Editor gespeichert wird. |
| CnmarcBibClearEmptyFieldsTask | Dieser Prozess führt eine Aufgabe aus, die die bibliografischen Felder löscht, die leer sind. |
| CnmarcBibReSequenceTask | Dieser Prozess führt eine Aufgabe aus, die die bibliografischen Felder in ihre korrekte Reihenfolge bringt — zum Beispiel 001, 100, 200, usw.
Felder zwischen 500 und 899 sind nicht sortiert (oder nur nach Hunderten sortiert).
|
| CnmarcBibTag100OpenDateTask | Wenn das Feld 100 vorhanden ist, wird das aktuelle Datum zu Beginn von 100 $a in den Positionen 00-07 eingefügt, wobei das Format YYYYMMDD verwendet wird. |
| CnmarcBibTag100Task | Alma fügt automatisch Daten ein oder korrigiert diese in den Positionen 09-12 und 13-16 des CNMARC-Feldes 100 entsprechend des Datums, das in CNMARC 210 $d eingegeben wurde (und in $h, wenn es vier aufeinanderfolgende Zahlen enthält). Zusätzlich wurden die Daten für 210 $d standardisiert. Alma ersetzt zum Beispiel für Daten wie 198? oder 19? die Fragezeichen und Leerzeichen mit "-" (Bindestrichen). |
| Create210BasedOn010 | Diese Normalisierungsprozess-Aufgabe fügt das Feld MARC 210 $a zum Datensatz hinzu und positioniert den Chinesischen Verfasser in das Feld 210, basierend auf der ISBN in MARC 010 $a und einer in Alma verwalteten Tabelle. Nach dem erstellen und Speichern eines Normalisierungsprozesses mit dieser ausgewählten Aufgabe können Sie die Option Bearbeiten > Datensatz erweitern im MD-Editor verwenden, um Datensätze, die Sie katalogisieren, zu ändern.
Siehe Datensatz erweitern in der Tabelle MD Editor - Menü bearbeiten unter Navigieren auf der Seite MD-Editor für weitere Informationen.
|
| DcBibClearEmptyFieldsTask | Führt eine Aufgabe aus, die die Dublin Core Felder löscht, die leer sind. |
| DcBibResequenceTask | Führt eine Aufgabe aus, die die Dublin Core Felder in ihre korrekte Reihenfolge bringt. |
| DcDroolNormalization | Wählen Sie die auszuführenden Normalisierungsregeln aus. Weitere Informationen finden Sie unter MARC Drools-Normalisierung.
Es können nur Normalisierungsregeln ausgewählt werden, die als gemeinsam genutzte Regeln im MD-Editor erstellt wurden.
Für weitere Informationen siehe Arbeiten mit Normalisierungsregeln.
|
| Identifikation von Kurztitel-Ebenen | Führt eine Aufgabe durch, welche die Kurztitel-Ebene eines Datensatzes berechnet. |
| Erzeugen einer chinesischen Verfasser-Signatur | Führt eine Aufgabe (in CNMARC) zur Erstellung einer Signatur für einen chinesischen Verfasser aus, die im Feld 905 gespeichert wird, wenn beispielsweise Bearbeiten > Datensatz erweitern während der Bearbeitung eines Datensatzes im MD-Editor ausgewählt ist.
Wenn Sie einen neuen Prozess hinzufügen, klicken Sie auf Neue Aufgaben, wählen Sie Erzeugen einer chinesischen Verfasser-Signatur, klicken Sie auf Hinzufügen und schließen und auf Weiter, um auf eine Routine zum Erzeugen von Verfasser-Signaturen in der Dropdown-Liste Routinen zum Erzeugen von Verfasser-Signaturen zuzugreifen und eine solche auszuwählen.
Wählen Sie eine der folgenden Verfassernummer-Erzeugung - Prozeduroptionen:
Dies ist die Signatur-Erzeugungsroutine für die CNMARC bibliographischen Datensätze auf Grundlage der Tabelle Chinesische Verfasser-Signatur, die die Verfassernummer im Feld 090 mit der Prozedur 2 erzeugt.
Dies ist die Signatur-Erzeugungsroutine für die CNMARC bibliographischen Datensätze auf Grundlage der Tabelle Chinesische Verfasser-Signatur, die die Verfassernummer im Feld 090 mit der Prozedur 3 erzeugt.
Die nächste Sequenz wird im Feld 905 erzeugt.
Diese Routine sollte nur verwendet werden, wenn Sie einen Datensatz manuell bearbeiten, nicht in Batch-Prozessen.
Diese Wartungsroutine speichert die Sequenz vom Feld 905 im Titelsatz in Alma. Dies erzeugt keine neue Sequenz, sondern speichert stattdessen bestehende Sequenzen aus dem Titelsatz. Dies kann nach Batch-Updates verwendet werden, beispielsweise nach einer Migration oder einem MD-Import. Dies wird verwendet, um die Alma-Sequenz und alles, was sonst im Titelsatz gespeichert ist, zu erzeugen.
Wählen Sie den Parameter Bei der Erstellung der Autoren-Nummer im MD-Editor (F4), um im MD-Editor die Art der Autorennummergenerierung zuzulassen, die im Wählen Sie Autorennummer-Generierungsroutine-Parameter ausgewählt wurde.
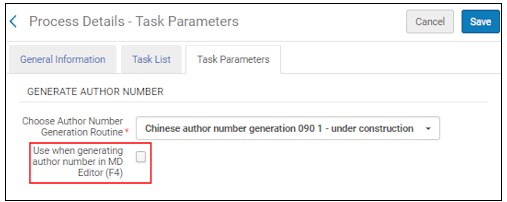 Parameter Bei der Verfassernummer-Erzeugung im MD-Editor verwenden (F4)
Wenn Sie diese Option für die Normalisierung auswählen, wird durch Drücken von F4 im MD-Editor das System die in dieser Profile identifizierte Autorennummer-Generierungsroutine anstelle der regulären Autorennummergenerierung verwenden.
|
| Signatur MARC 21 Normdateien erstellen | Führt eine Aufgabe (in MARC 21) zur Erstellung einer Signatur für einen chinesischen Verfasser aus, die im Feld 905 gespeichert wird, wenn beispielsweise Bearbeiten > Datensatz erweitern während der Bearbeitung eines Datensatzes im MD-Editor ausgewählt ist. Dies ist die MARC 21 Version des Prozesses Erzeugen einer chinesischen Verfasser-Signatur.
Wenn Sie einen neuen Prozess hinzufügen, klicken Sie auf Neue Aufgaben, wählen Sie Erzeugen einer chinesischen Verfasser-Signatur, klicken Sie auf Hinzufügen und schließen und auf Weiter, um auf eine Routine zum Erzeugen von Verfasser-Signaturen in der Dropdown-Liste Routinen zum Erzeugen von Verfasser-Signaturen zuzugreifen und eine solche auszuwählen.
Dies ist die Signatur-Erzeugungsroutine für die MARC 21 bibliographischen Datensätze auf Grundlage der Tabelle Chinesische Verfasser-Signatur, die die Verfassernummer im Feld 090 mit der Prozedur 3 erzeugt.
Dies ist die Signatur-Erzeugungsroutine für die MARC 21 bibliographischen Datensätze auf Grundlage der Tabelle Chinesische Verfasser-Signatur, die die Verfassernummer im Feld 090 mit der Prozedur 4 erzeugt.
Dies ist die Signatur-Erzeugungsroutine für die MARC 21 bibliographischen Datensätze auf Grundlage der Tabelle Chinesische Verfasser-Signatur, die die Verfassernummer im Feld 905 mit der Prozedur 1 erzeugt.
Die nächste Sequenz wird im Feld 905 erzeugt.
Diese Routine sollte nur verwendet werden, wenn Sie einen Datensatz manuell bearbeiten, nicht in Batch-Prozessen.
Diese Wartungsroutine speichert die Sequenz vom Feld 905 im Titelsatz in Alma. Dies erzeugt keine neue Sequenz, sondern speichert stattdessen bestehende Sequenzen aus dem Titelsatz. Dies kann nach Batch-Updates verwendet werden, beispielsweise nach einer Migration oder einem MD-Import. Dies wird verwendet, um die Alma-Sequenz und alles, was sonst im Titelsatz gespeichert ist, zu erzeugen.
Wählen Sie den Parameter Bei der Erstellung der Autoren-Nummer im MD-Editor (F4), um im MD-Editor die Art der Autorennummergenerierung zuzulassen, die im Wählen Sie Autorennummer-Generierungsroutine-Parameter ausgewählt wurde.
Wenn Sie diese Option für die Normalisierung auswählen, wird durch Drücken von F4 im MD-Editor das System die in dieser Profile identifizierte Autorennummer-Generierungsroutine anstelle der regulären Autorennummergenerierung verwenden.
|
| MARC-Normierungsregeln | Führt die Normierungsregeln aus, die in der Registerkarte Aufgaben-Parameter als Parameter ausgewählt sind. |
|
Aufgabe MARC21 Bestand erweitern mit 863/4/5 |
Führt eine Aufgabe aus, die ein 863/864/865 zusammenfassendes Aussagen-Bestandsfeld hinzufügt. Für weitere Informationen siehe Arbeiten mit MARC 21 Bestandsprofilen. |
|
Aufgabe MARC21 Bestand erweitern mit 866/7/8 |
Führt eine Aufgabe aus, die eine Beschreibung der 866/867-868 Textbestands-Angabefelder hinzufügt. Für weitere Informationen siehe Arbeiten mit MARC 21 Bestandsprofilen. |
| Marc21AuthClearEmptyFieldsTask | Führt eine Aufgabe aus, die die Normdatei-Felder löscht, die leer sind. |
| Marc21AuthResequenceTask | Führt eine Aufgabe aus, die die Normdatensatz-Felder in ihre korrekte Reihenfolge bringt. |
| Marc21BibClearEmptyFieldsTask |
Führt eine Aufgabe aus, die die bibliografischen Felder löscht, die leer sind. Diese Aufgabe kann nicht aus dem Standardprozess entfernt werden, da Datensätze mit leeren Feldern nicht gespeichert werden können. |
| Marc21BibResequenceTask | Führt eine Aufgabe aus, die die bibliografischen Felder in ihre korrekte Reihenfolge bringt—zum Beispiel 001, 100, 200, usw.
Felder zwischen 500 und 899 sind nicht sortiert (oder nur nach Hunderten sortiert). Das Feld 689 (nur relevant für deutsche Märkte) wird nach seinen Indikatoren sortiert.
|
| Marc21createControlNumber | Führt eine Aufgabe aus, die eine neue Kontrollnummer der Felder 001 und 003 des Titelsatzes erstellt und diese im Feld 035 einfügt. |
|
Marc21HoldingClearEmptyFieldsTask |
Führt eine Aufgabe aus, die die Bestandsfelder löscht, die leer sind. Für weitere Informationen siehe Arbeiten mit MARC 21 Bestandsprofilen. |
|
Marc21HoldingResequenceTask |
Führt eine Aufgabe aus, die die Bestandsfelder in ihre korrekte Reihenfolge bringt. Die Felder 5XX und 8XX sind nicht sortiert. Für weitere Informationen siehe Arbeiten mit MARC 21 Bestandsprofilen. |
|
Schreibt ein 001-Feld in den Bestandssatz. Für weitere Informationen siehe Arbeiten mit MARC 21 Bestandsprofilen. |
|
| MarcDroolNormalisierung | Wählen Sie die auszuführenden Normalisierungsregeln aus. Normalisierungsprozesse verwenden als Bausteine die gemeinsamen Normalisierungsregeln, die bereits im Metadaten-Editor definiert und gespeichert wurden (siehe Arbeiten mit Normierungsregeln).
Private Normalisierungsregeln können nicht wie in einem Normalisierungsprozess verwendet werden.
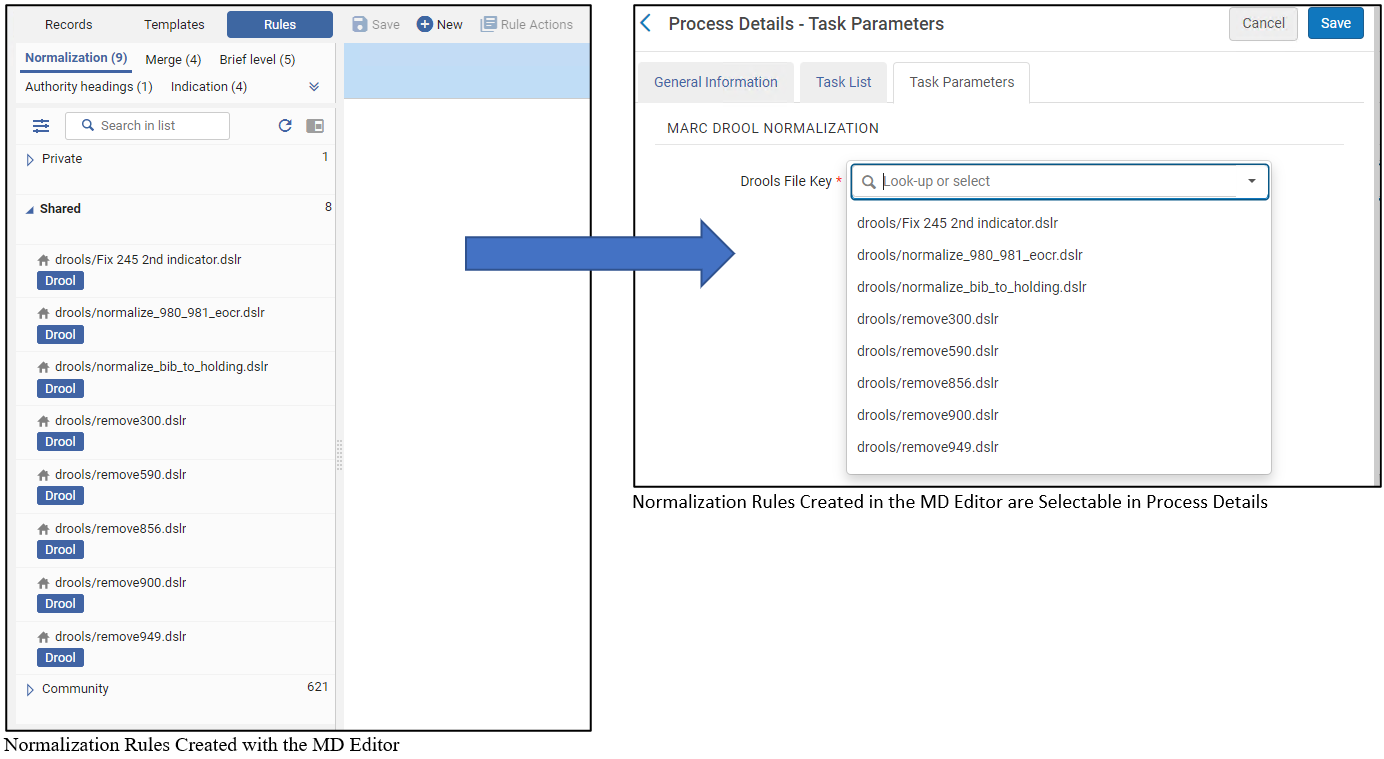 Für weitere Informationen zum Erstellen von Normalisierungsregeln siehe Arbeiten mit Normalisierungsregeln. |
| MarcXSL-Normierung | Wählen Sie die auszuführenden Normalisierungsregeln aus.
Normalisierungsprozesse verwenden als Bausteine die gemeinsamen Normalisierungsregeln, die bereits im Metadaten-Editor definiert und gespeichert wurden (siehe Arbeiten mit Normierungsregeln). Private Normalisierungsregeln können nicht wie in einem Normalisierungsprozess verwendet werden.
 Für weitere Informationen zum Erstellen von Normalisierungsregeln siehe Arbeiten mit Normalisierungsregeln. |
| MmsTagSuppressed | Führt eine Aufgabe aus, die die Titelsätze aus Discovery unterdrückt/ihre Unterdrückung aufhebt, entsprechend dem ausgewählten Wert Richtig oder Falsch (Richtig für Datensätze, die vom Publishing für Primo unterdrückt werden sollen, und Falsch, um das Publishing der Datensätze in Primo zu erlauben). |
| MmsTagSyncExternal |
Führt eine Aufgabe aus, die die Richtlinie für die Synchronisierung der Titelsätze mit dem externen Katalog entsprechend einem der folgenden ausgewählten Werte einstellt:
|
| MmsTagSyncNationalCatalog | Führt eine Aufgabe aus, die die Richtlinie für die Synchronisierung der Titelsätze mit dem nationalen Katalog entsprechend einem der folgenden ausgewählten Werte einstellt:
|
|
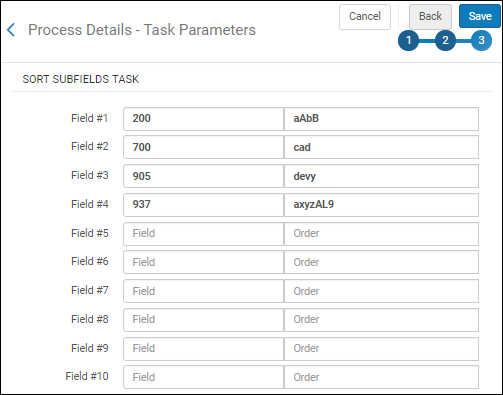
Wählen Sie diese Aufgabe aus, um die Reihenfolge der Unterfelder für ein bestimmtes Feld während der Normalisierung zu sortieren. Nachdem Sie diese Aufgabe zur Seite Prozessdetails - Aufgaben hinzufügen hinzugefügt haben und Weiter auswählen, wird der Abschnitt Sortierung der Unterfelder-Aufgabe angezeigt, in dem Sie die Reihenfolge der Unterfelder für ein bestimmtes Feld für bis zu zehn verschiedene Felder anpassen können.
Sortierung der Unterfelder-Aufgabe
Wenn andere Unterfelder in dem Feld vorhanden sind, die nicht in der Sortierreihenfolge angegeben sind, werden sie nach den sortierten Unterfeldern in ihrer ursprünglichen Reihenfolge angehängt. Alle Felder, die nicht für die Sortierung angepasst sind, behalten ihre ursprüngliche Unterfeldreihenfolge bei. Die Sortieranpassung berücksichtigt die Groß- und Kleinschreibung. Die Klein- und Großbuchstaben eines Briefes werden separat behandelt. |
|
|
UnimarcBibAdd005Task |
Das Feld 005 wird nur hinzugefügt, wenn es im MD-Editor gespeichert wird. Für Institutionen, die SBN nutzen, siehe Konfiguration der Aufgabe UnimarcBibAdd005Task für SBN / UNIMARC für weitere Informationen. |
| UnimarcBibClearEmptyFieldsTask | Dieser Prozess führt eine Aufgabe aus, die die bibliografischen Felder löscht, die leer sind. |
| UnimarcBibReSequenceTask | Dieser Prozess führt eine Aufgabe aus, die die bibliografischen Felder in ihre korrekte Reihenfolge bringt — zum Beispiel 001, 100, 200, usw.
Felder zwischen 500 und 899 sind nicht sortiert (oder nur nach Hunderten sortiert).
|
| UnimarcBibTag100OpenDateTask (neu) | Wenn das Feld 100 vorhanden ist, wird das aktuelle Datum zu Beginn von 100 $a in den Positionen 00-07 eingefügt, wobei das Format YYYYMMDD verwendet wird. |
| UnimarcBibTag100Task | Alma fügt automatisch Daten ein oder korrigiert diese in den Positionen 09-12 und 13-16 des UNIMARC-Feldes 100 entsprechend des Datums, das in UNIMARC 210 $d eingegeben wurde (und in $h, wenn es vier aufeinanderfolgende Zahlen enthält). Zusätzlich wurden die Daten für 210 $d standardisiert. Alma ersetzt zum Beispiel für Daten wie 198? oder 19? die Fragezeichen und Leerzeichen mit "-" (Bindestrichen). |
| Informationen zum Ursprungssystem aktualisieren | Verwenden Sie diese Option zum Einrichten der Ursprungssystemversion für die Versionsprävention beim Import von Datensätzen, wenn die Optionen Bei Übereinstimmung Überlagerung oder Zusammenführen und die Optionen Ursprungssystem berücksichtigen oder Ursprungssystem ignorieren ausgewählt sind. Datensätze, die im System vor der Freigabe im September 2015 gespeichert wurden, haben die Versionsinformationen des Ursprungssystems nicht. Alma bietet die Möglichkeit, diese Informationen mithilfe einer Prozessautomatisierung einzustellen, wenn Informationen zum Ursprungssystem aktualisieren im Prozesslistenspeicher ausgewählt ist. Für Datensätze, die nach der Freigabe im September 2015 importiert werden, werden das Ursprungssystem und die Ursprungssystemversion automatisch hinzugefügt.
Beachten Sie beim Verarbeiten von Datensätzen, die vor der Freigabe im September 2015 vorhandenen waren, dass die Normalisierungsaufgabe keine Datensätze modifiziert, die mit der Gemeinschaftszone verknüpft sind.
Siehe den Vorgang Normalisierung für die Verwaltung des Ursprungssystems konfigurieren und Versionsinformation des Ursprungssystems: für Schritte zum Einstellen eines Prozesses mithilfe der Option Informationen zum Ursprungssystem aktualisieren. |
Konfiguration der Normalisierung für die Verwaltung des Ursprungssystems
- Auf der Seite Prozessliste (Konfigurationsmenü >Ressourcen > Allgemein > Prozesse) klicken Sie auf Neuer Prozess.
- Wählen Sie aus den folgenden Optionen für die Parameter, die unten gekennzeichnet sind, aus und klicken sie auf Weiter.
- Geschäftseinheit – Bibliografischer Titel
- Typ – MARC 21 BIB-Normalisierung (oder eine Optionen eines anderen Typs, je nach Umgebung)
- Überprüfen Sie die allgemeinen Informationen und Planungs-Informationen und klicken Sie auf Weiter.
- Klicken Sie auf Neue Aufgaben und wählen Sie Wählen Sie Informationen zum Ursprungssystem aktualisieren.
- Klicken Sie auf Hinzufügen und schließen und dann auf Weiter.
- Wählen Sie Ihren Anforderungen entsprechend aus den folgenden Parametern:
Für ausgewählte Parameter müssen Sie auch den verknüpften Parameter angeben (falls zutreffend).
- Ursprungssystem aktualisieren – Das Ursprungssystem, das Sie in den Metadaten des importierten Datensatzes identifizieren möchten.
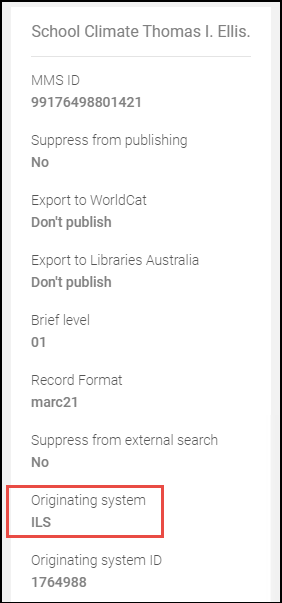 Ursprungssystem
Ursprungssystem - Ursprungssystemversion aktualisieren – Das Datum, das in den Metadaten des Datensatzes gespeichert werden soll. Dieses Datum wird verwendet, wenn Sie die Optionen Überlagern/Zusammenführen verhindern in Ihrem Importprofil für die Verarbeitung von Datensatz-Übereinstimmungen wählen (siehe Erstellen/Bearbeiten eines Importprofils: Match-Profil). Das Format dieses Datenparameters lautet MM/TT/JJJJ. Das Format der Ursprungssystemversion ist YYYYMMDDhhmmss.f (wobei hhmmss.f Stunden, Minuten, Sekunden, der Bruchteil einer Sekunde sind, und es wird das 24-Stunden-Format verwendet). Wenn eine Normalisierung mit diesem angegebenen Parameter auftritt, gibt das System YYYYMMDD000000.0 ein. Für den hhmmss.f Teil der Ursprungssystemversion werden Nullen eingegeben.
Wenn Sie den Metadaten-Import verwenden, entnimmt das System Datum und Zeit (im Format JJJJMMTThhmmss.f) für das Feld der Ursprungssystemversion aus dem Kontrollfeld 005 des importierten Datensatzes. Siehe die Abbildung unten für ein Beispiel des Kontrollfeldes 005 und das Format für Datum/Zeit.
 Der Normalisierungsprozess ändert das Feld Ursprungssystemversion entsprechend dem eingegebenen oder ausgewählten Datum im Kalender des Parameters Ursprungssystemversion. Wenn Sie beispielsweise einen Prozess Marc 21 BIB-Normalisierung ausführen, der einen Normalisierungsprozess mit einem Datum verwendet, das für den Parameter Ursprungssystemversion ausgewählt wurde, wird das angegebene Datum für alle Datensätze im Set, das Sie für den Prozess auswählen, angewendet.
Der Normalisierungsprozess ändert das Feld Ursprungssystemversion entsprechend dem eingegebenen oder ausgewählten Datum im Kalender des Parameters Ursprungssystemversion. Wenn Sie beispielsweise einen Prozess Marc 21 BIB-Normalisierung ausführen, der einen Normalisierungsprozess mit einem Datum verwendet, das für den Parameter Ursprungssystemversion ausgewählt wurde, wird das angegebene Datum für alle Datensätze im Set, das Sie für den Prozess auswählen, angewendet. - Ursprungssystemversion-Werte aktualisieren – Ob die Ursprungssystemversion, die Sie (oben) ausgewählt haben, eine bestehende Version überschreibt. Wenn nicht ausgewählt, bleibt die bestehende Version unverändert.
- Ursprungssystem aktualisieren – Das Ursprungssystem, das Sie in den Metadaten des importierten Datensatzes identifizieren möchten.
- Wählen Sie Speichern.
Um den Prozess auszuführen, den Sie gerade erstellt haben, um die Versionsinformationen des Ursprungssystems in einem Set an Datensätzen zu aktualisieren, folgen Sie den Schritten auf der Seite Prozesse an definierten Sets ausführen. Optional können Sie das Ursprungssystem und/oder die Versionsparameter des Ursprungssystems ändern/überschreiben, wenn Sie den Prozess ausführen.
Bearbeiten von Überprüfungsprozessen
- MARC 21 BIB - Übereinstimmungs-Überprüfung – definiert die Art, wie die Überprüfung vorgenommen wird, wenn eine Titelsatz-Übereinstimmung während des Importprozesses oder im MD-Editor ausgeführt wird.
- MARC 21 BIB - Überprüfung beim Speichern – definiert die Art, wie die Überprüfung vorgenommen wird, wenn MARC-Datensätze unter Verwendung eines Importprofils, mittels Copy Cataloging oder über eine externe Ressource (wie etwa WorldCat oder LoC) importiert werden und wenn ein Titelsatz im MD-Editor gespeichert wird.
- MARC 21 Normdatei Übereinstimmungs-Überprüfung – definiert die Art, wie die Überprüfung vorgenommen wird, wenn eine Normdatei-Übereinstimmung während des Importprozesses oder im MD-Editor ausgeführt wird.
- MARC 21 Normdatei - Überprüfung beim Speichern – definiert die Art, wie die Überprüfung vorgenommen wird, wenn MARC-Datensätze unter Verwendung eines Importprofils, mittels Copy Cataloging oder über eine externe Ressource importiert werden und wenn ein Normdatei-Datensatz im MD-Editor gespeichert wird.
- Wählen Sie die Zeilen-Aktion Bearbeiten für den Überprüfungsprozess, den Sie bearbeiten wollen, aus der Registerkarte Überprüfungsprozesse auf der Seite Profildetails aus (Konfigurationsmenü > Ressourcen > Katalogisierung > Metadaten-Konfiguration und klicken Sie auf einen Profil-Link).
 Registerkarte Überprüfungs-ProzesseDie Seite Prozess-Details wird mit der Registerkarte Allgemeine Informationen für den Überprüfungsprozess geöffnet.
Registerkarte Überprüfungs-ProzesseDie Seite Prozess-Details wird mit der Registerkarte Allgemeine Informationen für den Überprüfungsprozess geöffnet. Überprüfungsprozess – Registerkarte Allgemeine Informationen
Überprüfungsprozess – Registerkarte Allgemeine Informationen -
Bearbeiten Sie die Überprüfungs-Details nach Bedarf, indem Sie die Registerkarten des Überprüfungsprozesses auswählen (Allgemeine Informationen, Aufgabenliste, Aufgaben-Parameter), um auf die Informationen zuzugreifen, die Sie ändern wollen.Auf der Registerkarte Aufgabenliste können folgende Validierungsaufgaben ausgeführt werden:
- Mithilfe des Links Neue Aufgaben hinzugefügt
- Aus der vorhandenen Aufgabenliste mit der Zeilenaktion Entfernen entfernt
- In der vorhandenen Aufgabenliste mit den Aufwärts- / Abwärtspfeilen neu priorisiert, um die Reihenfolge der Zeilen zu ändern
Die in den Tabellen Zusammenfassung der Überprüfungsaufgaben für die Konfiguration der bibliografischen Metadaten von MARC21 und Zusammenfassung der Überprüfungsaufgaben für die Konfiguration der bibliografischen Metadaten von MARC21 beschriebenen Überprüfungsaufgaben sind für die Überprüfungsprozesse Marc21 Bib Überprüfung der Übereinstimmungen und Marc21 Bib Überprüfung beim Speichern beziehungsweise Marc-21-Normdatei – Überprüfung der Übereinstimmungen und Marc-21-Normdatei – Überprüfung beim Speichern verfügbar.Zusammenfassung der Überprüfungsaufgaben für die Konfiguration der bibliografischen Metadaten von MARC21 Überprüfung Aufgaben Beschreibung Überprüfung erkannter MARC 21-Felder Überprüft, ob alle Felder vom Profil erkannt werden. Überprüfung obligatorischer MARC21-Felder Überprüft das Vorhandensein von Pflichtfeldern. Überprüfung wiederholbarer MARC 21-Felder Überprüft die wiederholbaren Felder. Überprüfung festgelegter Feldpositionen im MARC 21 Bestand Überprüft legitime Daten im Kontrollfeld. Überprüfung variabler MARC 21-Felder Überprüft legitime Daten in den Indikatoren. Überprüfung erkannter MARC 21-Unterfelder Überprüft, ob alle Unterfelder vom Profil erkannt werden. Überprüfung obligatorischer MARC 21-Unterfelder Überprüft das Vorhandensein von Pflichtunterfeldern. Überprüfung wiederholbarer MARC 21-Unterfelder Überprüft wiederholbare Unterfelder. Marc21BibFindMatchesValidationTask Marc21Bib durchsuchen, ob es eine Übereinstimmung gibt. Überprüfungs-Wortschatz - Daten-Unterfelder MARC 21 Überprüft Wortschatzdaten. Überprüfen der alternativen grafischen Darstellung Überprüft alternative grafische Darstellungen. Überprüfen Bib_Heading Verfasser Überprüft, ob bibliografische Indexeinträge zulässig sind. Verwenden Sie diese Aufgabe, um zu überprüfen, ob die lokale Signatur für alle Titelsätze im Bestand eindeutig ist.
Für diese Aufgabe können Sie die folgenden Aufgabenparameter angeben (auf der Registerkarte Aufgabenparameter): 090, 091, 092, 093, 094, 095, 096, 097, 098, 099, and 905.
 Eindeutigkeit der lokalen Signaturen überprüfen
Eindeutigkeit der lokalen Signaturen überprüfenStandardmäßig werden alle 09X-Felder angegeben. Sie können auch festlegen, dass 905 zur Liste hinzugefügt werden soll (dies bestätigt $s in der 905).
Wenn Sie die gesamte Dropdown-Liste anzeigen, wählen Sie einen zu entfernenden Wert aus oder fügen das Häkchen hinzu, um anzugeben, welches 09X-Feld für die Eindeutigkeit validiert werden soll.
Wenn alle 09X-Felder ausgewählt sind, gilt die Eindeutigkeitsprüfung für das gleiche 09X-Feld in anderen Titelsätzen. Wenn Sie zum Beispiel das Feld 093 in der Liste Überprüfung des BIB Signatur-Felds auswählen, vergleicht die Validierungsprüfung alle anderen bibliografischen 093-Felder im Bestand, um festzustellen, ob doppelte Signaturen vorhanden sind.
Wenn alle 09X-Felder ausgewählt sind, gilt die Eindeutigkeitsprüfung für jedes 09X-Feld in anderen Titelsätzen. Wenn der Titelsatz beispielsweise eine lokale Signatur im Feld 093 enthält, führt die Validierungsprüfung einen Vergleich aller anderen 09X-Felder (nicht nur des Feldes 093) im Bestand durch, um festzustellen, ob doppelte Signaturen vorliegen.
Als Abkürzung können Sie das x neben dem Feld 09X auswählen, um es aus der Liste zu entfernen.
Für weitere Informationen siehe Überprüfung der Einmaligkeit einer 090-Signatur beim Speichern eines Datensatzes im Metadaten-Editor (.docx file).
Überprüfen der Prüfziffer "Andere Standardnummer"
Wenn Sie das bibliografische MARC21-Profil konfigurieren, wählen Sie diese Validierungsaufgabe aus, um die folgenden anderen Standardnummern-IDs in Feld 024 zu validieren:
- UPC (1. Indikator = 1)
- ISMN (1. Indikator = 2)
- IAN (1. Indikator = 3)
Nachdem Sie die Validierungsaufgabe Prüfziffer "Andere Standardnummer" validieren zur Aufgabenliste in der Registerkarte Aufgabenliste hinzugefügt haben, klicken Sie auf die Registerkarte Aufgabenparameter und identifizieren Sie die Unterfelder, die Sie im Feld 024 validieren möchten. Wenn Sie mehrere Unterfelder angeben, geben Sie die Unterfelder durch Komma und ohne Leerzeichen getrennt ein.
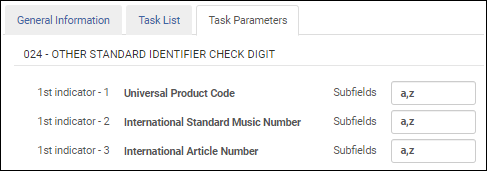 Andere Parameter für die Standardnummernüberprüfung - MARC 21 / KORMARC
Andere Parameter für die Standardnummernüberprüfung - MARC 21 / KORMARCISBN-Prüfziffer validieren
Wählen Sie diese Validierungsaufgabe aus, um die Internationale Standardnummer für fortlaufende Sammelwerke (International Standard Serial Number - ISBN) zu validieren.
Nachdem Sie die Validierungsaufgabe ISBN-Prüfziffer validierenzur Aufgabenliste in der Registerkarte Aufgabenliste hinzugefügt haben, klicken Sie auf die Registerkarte Aufgabenparameter und wählen Sie Felder und Unterfelder hinzufügen, um die Felder / Unterfelder zu identifizieren, die Sie validieren möchten. Wenn Sie mehrere Unterfelder angeben, geben Sie die Unterfelder durch Komma und ohne Leerzeichen getrennt ein.
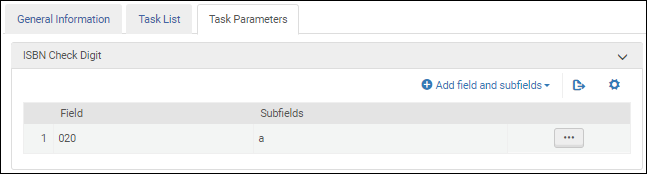 ISBN Validierung der Aufgabenparameter - MARC 21 / KORMARC
ISBN Validierung der Aufgabenparameter - MARC 21 / KORMARC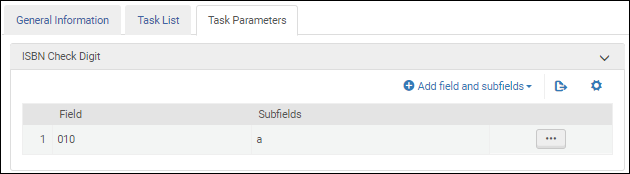 ISBN Validierungsaufgaben-Parameter - UNIMARC / CNMARC
ISBN Validierungsaufgaben-Parameter - UNIMARC / CNMARCÜberprüfen von leeren Feldern in neuen MARC 21-Titeldaten (Dies ist auch für die Bibliografischen Metadaten-Konfigurationsprofile KORMARC, UNIMARC und CNMARC verfügbar.)
Nachdem Sie die Überprüfungsaufgabe Überprüfen von leeren Feldern in neuen MARC 21-Titeldaten zur Aufgabenliste hinzugefügt haben, wählen Sie die Registerkarte Aufgaben-Parameter und bestimmen Sie die Felder, für die Sie überprüfen wollen, ob sie leer sind. 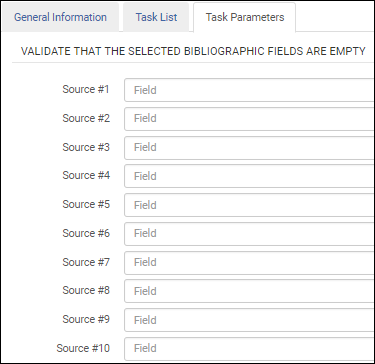 Leere Felder überprüfen
Leere Felder überprüfenUm eine spezifischen Fehler- oder Warnmeldung für diese Überprüfung einzustellen, müssen Sie ein Überprüfungs-Fehlerprofil erstellen. Für weitere Informationen siehe Arbeiten mit Überprüfungs-Ausnahmeprofilen.
Diese Überprüfung erfolgt nur für neue Datensätze, nicht für bestehende Datensätze, die Sie aktualisieren.
Für jede Funktion, die den Überprüfungsprozess verwendet (MD-Editor, API, Import, Bestellposten und Schnell-Katalogisierung) wird eine Fehler- oder Warnmeldung ausgegeben, wenn ein in den Aufgaben-Parametern festgelegtes Feld nicht leer ist. Im MD-Editor erscheinen die Meldungen zum Beispiel in der folgenden Weise, wenn 009 als zu überprüfendes Feld in der Registerkarte Aufgaben-Parameter konfiguriert ist:
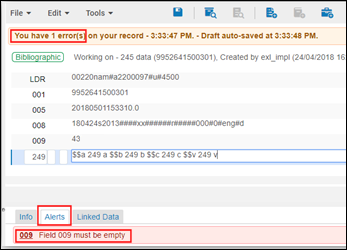 Überprüfungsmeldungen: Feld nicht leer
Überprüfungsmeldungen: Feld nicht leerÜberprüfungsform für Material MARC21
Überprüft, ob die Materialform im Feld 006 (Position 0) mit der Materialart im Leader (LDR) übereinstimmt.
ISSN-Prüfziffer validieren
Wählen Sie diese Validierungsaufgabe aus, um die Internationale Standardnummer für fortlaufende Sammelwerke (International Standard Serial Number - ISBN) zu validieren.
Nachdem Sie die Validierungsaufgabe ISSN-Prüfziffer validierenzur Aufgabenliste in der Registerkarte Aufgabenliste hinzugefügt haben, klicken Sie auf die Registerkarte Aufgabenparameter und wählen Sie Felder und Unterfelder hinzufügen, um die Felder / Unterfelder zu identifizieren, die Sie validieren möchten. Wenn Sie mehrere Unterfelder angeben, geben Sie die Unterfelder durch Komma und ohne Leerzeichen getrennt ein.
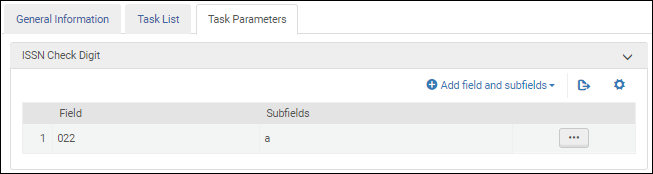 ISSN Validierung der Aufgabenparameter - MARC 21 / KORMARC
ISSN Validierung der Aufgabenparameter - MARC 21 / KORMARC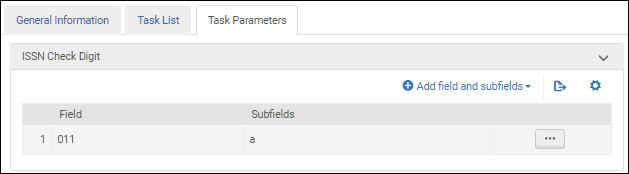 ISSN Validierungsaufgaben-Parameter - UNIMARC / CNMARC
ISSN Validierungsaufgaben-Parameter - UNIMARC / CNMARCUPC-Prüfziffer validieren
Wählen Sie diese Validierungsaufgabe aus, wenn Sie das UNIMARC-Bibliografie-Profil konfigurieren, um den Universalproduktcode (UPC) zu validieren.
Nachdem Sie die Validierungsaufgabe UPC-Prüfziffer validierenzur Aufgabenliste in der Registerkarte Aufgabenliste hinzugefügt haben, klicken Sie auf die Registerkarte Aufgabenparameter und wählen Sie Felder und Unterfelder hinzufügen, um die Felder / Unterfelder zu identifizieren, die Sie validieren möchten. Wenn Sie mehrere Unterfelder angeben, geben Sie die Unterfelder durch Komma und ohne Leerzeichen getrennt ein.
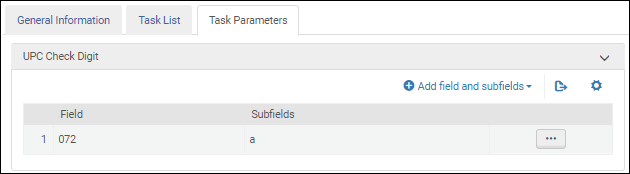 Universalproduktcode Validierungsaufgaben-Parameter - UNIMARC / CNMARC
Universalproduktcode Validierungsaufgaben-Parameter - UNIMARC / CNMARCISMN-Prüfziffer validieren
Wenn Sie das UNIMARC-Bibliografieprofil konfigurieren, wählen Sie diese Validierungsaufgabe aus, um die Internationale Standard-Musiknummer (ISMN) zu validieren.
Nachdem Sie die Validierungsaufgabe ISMN-Prüfziffer validierenzur Aufgabenliste in der Registerkarte Aufgabenliste hinzugefügt haben, klicken Sie auf die Registerkarte Aufgabenparameter und wählen Sie Felder und Unterfelder hinzufügen, um die Felder / Unterfelder zu identifizieren, die Sie validieren möchten. Wenn Sie mehrere Unterfelder angeben, geben Sie die Unterfelder durch Komma und ohne Leerzeichen getrennt ein.
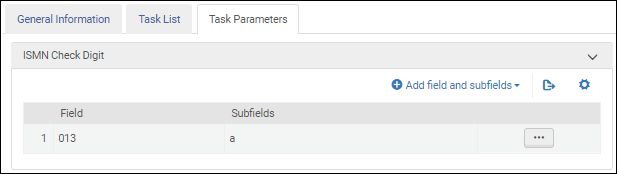 Parameter für die Überprüfung internationaler Standard-Musikummern - UNIMARC / CNMARC
Parameter für die Überprüfung internationaler Standard-Musikummern - UNIMARC / CNMARCNachdem Sie die Validierungsaufgabe IAN-Prüfziffer validierenzur Aufgabenliste in der Registerkarte Aufgabenliste hinzugefügt haben, klicken Sie auf die Registerkarte Aufgabenparameter und wählen Sie Felder und Unterfelder hinzufügen, um die Felder / Unterfelder zu identifizieren, die Sie validieren möchten. Wenn Sie mehrere Unterfelder angeben, geben Sie die Unterfelder durch Komma und ohne Leerzeichen getrennt ein.
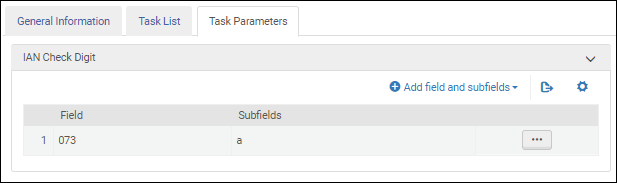 Parameter für die Überprüfung internationaler Artikelnummern - UNIMARC / CNMARC
Parameter für die Überprüfung internationaler Artikelnummern - UNIMARC / CNMARC - Wenn Sie mit dem Ändern der Prozessdetails auf den Registerkarten Allgemeine Informationen, Aufgabenliste und Aufgabenparameter fertig sind, wählen Sie Speichern.
Arbeiten mit Überprüfungs-Ausnahme-Profilen
- MARC XML BIB-Import – Es wird empfohlen, dieses Ausnahmeprofil auszuwählen, um ungültige Daten während des Imports zu verarbeiten.
- MARC XML BIB-Metadaten-Bearbeitung beim Speichern –Dieses Fehlerprofil wird verwendet, wenn Sie Copy Cataloging über eine externe Ressource (wie etwa WorldCat oder LoC) ausführen und wenn Sie einen Titelsatz im Metadaten-Editor katalogisieren/speichern.
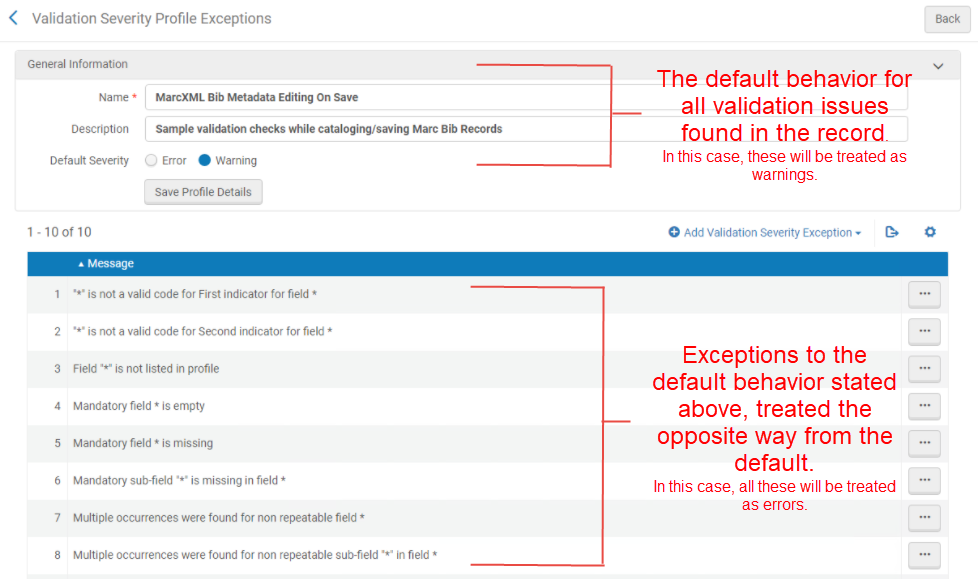
Im Gegensatz zu Validierungsprofilen (siehe Bearbeiten von Überprüfungsprozessen) definieren Sie ein Standardverhalten und Sie können auch Ausnahmen von diesem Verhalten definieren. Im oberen Abschnitt der Seite geben Sie den Standard-Schweregrad an, der den Standard-Schweregrad für alle im Datensatz gefundenen Validierungsprobleme darstellt. Im unteren Abschnitt können Sie Ausnahmen von diesem Standard festlegen. Dies sind die Regeln, die Sie anders als den Standard behandeln sollten. Im Screenshot unten wird alles in der Ausnahmeliste als Fehler behandelt, da die Standardeinstellung auf 'Warnung' gesetzt ist, da dies die Ausnahme von der Standardeinstellung ist.
Auf dieser Seite können Sie auch die vorhandenen Profile bearbeiten oder kopieren. Sie können die von Ihnen erstellten Profile löschen.
Hinzufügen eines Überprüfungs-Fehlerprofils
- Wählen Sie auf der Seite Profildetails (Konfigurationsmenü > Ressourcen > Katalogisierung > Metadaten-Konfiguration und klicken Sie auf einen Profil-Link) die Registerkarte Überprüfung – Fehlerprofilliste.
Klicken Sie auf Neues Fehlerprofil.
 Um ein vorhandenes Überprüfungs-Fehlerprofil zu kopieren und es zu ändern, um ein neues zu erstellen, wählen Sie die Zeilenaktion Kopieren und ändern Sie das duplizierte Profil entsprechend Ihren Anforderungen (siehe Bearbeiten eines Überprüfungs-Fehlerprofils).
Um ein vorhandenes Überprüfungs-Fehlerprofil zu kopieren und es zu ändern, um ein neues zu erstellen, wählen Sie die Zeilenaktion Kopieren und ändern Sie das duplizierte Profil entsprechend Ihren Anforderungen (siehe Bearbeiten eines Überprüfungs-Fehlerprofils). - Geben Sie für das Überprüfungs-Fehlerprofil folgendes ein:
- Name (erforderlich) und Beschreibung für das Überprüfungs-Fehlerprofil, das Sie hinzufügen wollen
- Wählen Sie Fehler oder Warnung, um den Standard-Schweregrad festzulegen. Der Standard-Schweregrad legt fest, ob die Verletzungen der Parameter auf Feld-Ebene, die in der Registerkarte Felder definiert wurden (zum Beispiel Pflichtfeld, nicht-wiederholbar), als Warnungen (die überschrieben werden können) oder als Fehler (die gelöst werden müssen) behandelt werden.
- Klicken Sie auf Neues Fehlerprofil. Das Profil wird der Liste der Überprüfungs-Ausnahmen-Profile hinzugefügt. Für Informationen zum Hinzufügen einer Meldung zu Ihrem Überprüfungs-Fehlerprofil siehe Bearbeiten eines Überprüfungs-Fehlerprofils.
Bearbeiten eines Überprüfungs-Fehlerprofils
- Wählen Sie in der Registerkarte Überprüfung - Fehlerprofilliste auf der Seite Profildetails (-Verwaltung > Ressourcen-Konfiguration > Konfigurationsmenü > Ressourcen >Katalogisierung > Metadaten-Konfiguration und klicken Sie auf einen Profil-Link) die Zeilen-Aktion Bearbeiten für das Überprüfungs-Fehlerprofil, das Sie ändern wollen.
- Im Bereich Allgemeine Informationen nehmen Sie nach Bedarf Änderungen am Namen, an der Beschreibung oder am Standard-Schweregrad vor.
- Wählen Sie im Bereich Meldung die Zeilen-Aktion Löschen, um unerwünschte Meldungen zu löschen.
- Klicken Sie auf Neue Fehlermeldung und wählen Sie eine Überprüfungs-Fehlermeldung aus der Dropdown-Liste Meldung.
Die Syntax der Meldungen in der Dropdown-Liste Meldung ist nicht konfigurierbar. - Klicken Sie auf Neue Fehlermeldung.
- Klicken Sie auf Profildetails speichern und auf Zurück.
Konfiguration anderer Einstellungen
- Eine Regel für Kurztitel-Ebenen wählen (siehe Einstellen der Standardregel für Kurztitel-Ebenen in der Metadaten-Konfiguration)
- Wählen Sie Parameter, um bestimmte Felder beim Speichern von Datensätzen in einer bestimmten Weise zu bearbeiten (siehe Konfiguration anderer Einstellungen.
Konfiguration der Parameter Andere Einstellungen
- 003 Löschen deaktivieren - Wählen Sie diesen Parameter, um den Inhalt des Felds 003 beizubehalten, wenn Sie Datensätze speichern. Wenn dieser Parameter nicht ausgewählt ist, ist das Standardverhalten beim Speichern eines Datensatzes das Löschen des 003-Feldes nach dem Verketten seines Inhalts mit der MMS-ID aus dem Feld 001, um eine ID wie (OCoLC)35397863 zu erstellen, die im Feld 035 platziert wird.
- Generierung von 035 basierend auf der MMS ID ausschließen – Wählen Sie diese Option, um die automatische Generierung des Feldes 035, das den Inhalt des Feldes 003 mit der MMS-ID verknüpft, aus dem Feld 001 beim Speichern von Datensätzen zu deaktivieren.
- 035 nur ab 001 generieren – (nur für die Profile UNIMARC-Titeldaten und Normdatei-Metadaten-Konfiguration) Wählen Sie diese Option, um beim Speichern von Datensätzen ein Feld 035 aus dem Inhalt des Felds 001 (MMS-ID) zu erstellen.
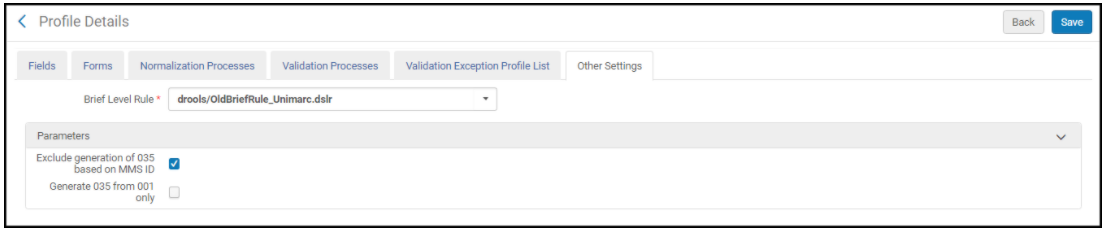 Metadaten-Konfiguration - Registerkarte Andere Einstellungen für UNIMARC
Metadaten-Konfiguration - Registerkarte Andere Einstellungen für UNIMARC - Skriptcode Neue alternative grafische Darstellung – Verwenden Sie diesen Parameter, um den verknüpften Skriptsprachen-Indikator in $6 hinzuzufügen oder auszulassen, wenn das Feld 880 erstellt wird. Wenn Sie diesen Parameter auswählen, wird der Skriptsprache-Indikator im Feld 880 zu $6 hinzugefügt. Für weitere Informationen siehe Arbeiten mit den mit 880 verknüpften Feldern in Titelsätzen.
Arbeiten mit UNIMARC-Feldern, Normalisierung und Überprüfung
- Klicken Sie auf den Link UNIMARC Titeldaten auf der Seite Metadaten-Konfigurationsliste (Konfigurationsmenü > Ressourcen > Katalogisierung > Metadaten-Konfiguration). Die Seite Profil-Details erscheint.
- Wählen Sie die Registerkarte Normalisierungsprozesse. Der folgende standardmäßige Normalisierungsprozess erscheint in der Registerkarte Normalisierungsprozesse:
- Unimarc Bib: Erste Normierung
- Unimarc Bib: Beim Speichern normalisieren
- Unimarc Bib: Neu sequenzieren
- Unimarc Bib: Neu sequenzieren und leere Felder löschen
-
Wählen Sie für einen der Normalisierungsprozesse Bearbeiten aus der Zeilen-Aktionsliste und wählen Sie die Registerkarte Aufgabenliste, um die verfügbaren UNIMARC-Aufgaben anzuzeigen.Für weitere Informationen siehe Konfiguration der Aufgabe UnimarcBibAdd005Task für SBN / UNIMARC.
- Wenn Sie fertig sind, klicken Sie auf Speichern.
- Klicken Sie auf den Link UNIMARC Titeldaten auf der Seite Metadaten-Konfigurationsliste (Konfigurationsmenü > Ressourcen > Katalogisierung > Metadaten-Konfiguration). Die Seite Profil-Details wird mit der Registerkarte Felder geöffnet.
- Lokalisieren Sie eines der 9XX-Felder.
- Wählen Sie Anpassen aus der Zeilen-Aktionsliste, um die verfügbaren Unterfelder und Indikatoren für die Anpassung anzuzeigen.
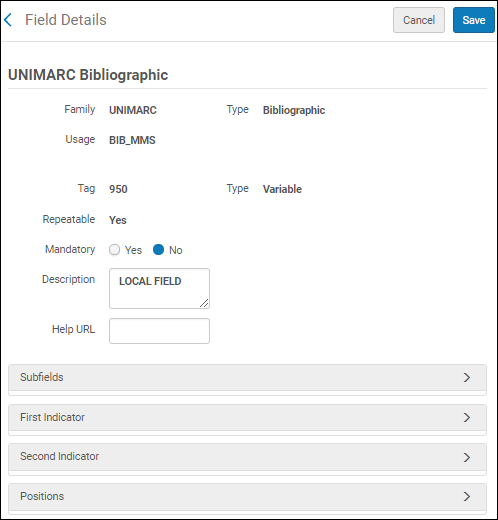 UNIMARC-Felddetails
UNIMARC-Felddetails - Erweitern Sie die Abschnitte Unterfelder, Erster Indikator und Zweiter Indikator, um die anpassbaren Optionen anzuzeigen.
- Klicken Sie auf den Link UNIMARC Titeldaten auf der Seite Metadaten-Konfigurationsliste (Konfigurationsmenü > Ressourcen > Katalogisierung > Metadaten-Konfiguration). Die Seite Profil-Details wird mit der Registerkarte Felder geöffnet.
- Filtern Sie die Registerkarte Felder, indem Sie die Option 1XX: Block - Codierte Informationen auswählen.
- Wählen Sie für das Feld 100 Ansicht aus der Zeilen-Aktionsliste. Die Seite Felddetails erscheint.
- Erweitern Sie den Abschnitt Positionen, um die zu überprüfenden Positionen einzusehen.
Die folgenden Positionsüberprüfungen wurden für UNIMARC hinzugefügt:
- In der Datei eingetragenes Datum
- Art des Veröffentlichungsdatums
- Veröffentlichungsdatum 1
- Veröffentlichungsdatum 2
- Klicken Sie nach Beendigung auf Zurück, bis Sie zur Seite Metadaten-Konfigurationsliste zurückkehren.
Verwalten lokaler UNIMARC-Normdatensätze
- Klicken Sie auf der Seite Metadaten-Konfigurationsliste (Konfigurationsmenü > Ressourcen > Katalogisierung > Metadaten-Konfiguration) auf Lokale Normdatei hinzufügen. Das Popup-Fenster Neue lokale Normdatei erscheint.
- Schließen Sie die Parameter ab, die für das lokale UNIMARC-Normdateiprofil erforderlich sind.
- Name – Geben Sie den Wortschatz-Namen ein, der für das Profil auf der Seite Lokale Normdatei - Register erscheinen soll.
- Code – Geben Sie den Wortschatz-Code ein, der beispielsweise bei der Konfiguration Ihres Importprofils angezeigt werden soll.
- Familie – Wählen Sie UNIMARC aus der Drohdown-Liste.
- Typ – Wählen Sie aus der Dropdown-Liste einen der folgenden Typen:
- Schlagwort
- Name
- Namen und Schlagwörter
- Klassifizierung
- Direktes ID-Präfix – Geben Sie das ID-Präfix ein, wenn eines verwendet wird.
- Mehrsprachig – Wählen Sie Ja oder Nein aus der Dropdown-Liste.
- Klicken Sie auf Hinzufügen und schließen. Das lokale Normdatei-Register, das Sie erstellt haben, erscheint in der Liste auf der Seite Lokale Normdatei - Register.
- Wählen Sie Speichern. Ihr lokales Normdateiprofil erscheint in der Liste auf der Seite Metadaten-Konfigurationsliste.
- Klicken Sie auf den Link UNIMARC Normdatei, um die Seite Profildetails zu öffnen und Felder, Normalisierung und Überprüfung zu konfigurieren, ähnlich wie bei MARC 21.
- Wenn Sie mit den Änderungen an den Profildetails fertig sind, klicken Sie auf Umsetzen.
Arbeiten mit KORMARC-Feldern, Normalisierung und Überprüfung
- Öffnen Sie die Seite Metadaten-Konfigurationsliste (Konfigurationsmenü > Ressourcen > Katalogisierung > Metadaten-Konfiguration).
- Klicken Sie auf den Link KORMARC-Titelsatz. Die Seite Profil-Details erscheint.
- Wählen Sie die Registerkarte Normalisierungsprozesse. Der folgende standardmäßige Normalisierungsprozess erscheint in der Registerkarte Normalisierungsprozesse:
- KORMARC BIB: beim Speichern normalisieren
- KORMARC BIB: Neu sequenzieren
- KORMARC BIB: Neu sequenzieren und leere Felder löschen
- Wählen Sie für einen der Normalisierungsprozesse Bearbeiten aus der Zeilen-Aktionsliste und wählen Sie die Registerkarte Aufgabenliste, um die verfügbaren KORMARC-Aufgaben anzuzeigen.
- Wenn Sie fertig sind, klicken Sie auf Speichern.
Arbeiten mit CNMARC-Feldern, Normalisierung und Überprüfung
- Öffnen Sie die Seite Metadaten-Konfigurationsliste (Konfigurationsmenü > Ressourcen > Katalogisierung > Metadaten-Konfiguration).
- Klicken Sie auf den Link CNMARC-Titelsatz. Die Seite Profil-Details erscheint.
- Wählen Sie die Registerkarte Normalisierungsprozesse. Der folgende standardmäßige Normalisierungsprozess erscheint in der Registerkarte Normalisierungsprozesse:
- Erste Cnmarc BIB-Normalisierung
- CNMARC BIB: beim Speichern normalisieren
- Cnmarc-BIB-Normalisierung bei Z39.50/SRU-Suchen
- CNMARC BIB: Neu sequenzieren
- Cnmarc Bib: Neu sequenzieren und leere Felder löschen
- Wählen Sie für einen der Normalisierungsprozesse Bearbeiten aus der Zeilen-Aktionsliste und wählen Sie die Registerkarte Aufgabenliste, um die verfügbaren CNMARC-Aufgaben anzuzeigen. Eine Erklärung der Normalisierungsaufgaben finden Sie in der Tabelle Optionen der Aufgabenliste.
- Wenn Sie fertig sind, klicken Sie auf Speichern.
Arbeiten mit MODS-Feldern, Normalisierung und Überprüfung
- Öffnen Sie die Seite Metadaten-Konfigurationsliste (Konfigurationsmenü > Ressourcen > Katalogisierung > Metadaten-Konfiguration).
- Klicken Sie auf die Verknüpfung MODS . Die Seite Profil-Details erscheint.
- Wählen Sie die Registerkarte Normalisierungsprozesse. Der folgende standardmäßige Normalisierungsprozess erscheint in der Registerkarte Normalisierungsprozesse:
- MODS BIB zu Sammlung hinzufügen
- MODS BIB-Normalisierung beim Speichern
- Titelsätze aus Discovery unterdrücken - MODS
- Wählen Sie für einen der Normalisierungsprozesse Bearbeiten aus der Zeilen-Aktionsliste und wählen Sie die Registerkarte Aufgabenliste, um die verfügbaren MODS-Aufgaben anzuzeigen.
- Wählen Sie Aufgaben hinzufügen, um dem Prozess eine Aufgabe hinzuzufügen. In der folgenden Tabelle sind die verfügbaren MODS-Aufgaben aufgeführt:
Aufgabe Beschreibung Mods-Drool-Normalisierung Wählen Sie auf der Registerkarte „Aufgaben-Parameter“ die auszuführenden Normierungsregeln aus. addBibToCollectionNormalizationTask Titelsatz zu einer Sammlung hinzufügen MmsTagSuppressed Stellt den Unterdrückt-Schalter von MMS MODS ein Aufgabe Bearbeitet die Migration Kopieren Sie Handles aus den Metadaten des Titelsatzes in das Kennungsfeld Handle des Datensatzes Datensatz-Kennung mit MMS-ID aktualisieren Aktualisieren Sie das Element recordIdentifier mit der MMS-ID. Aktivieren Sie das Kontrollkästchen Datensatz-Änderung in einem Datensatz-Kennung-Element, um die Änderung im Element Datensatz-Information-Notiz unter dem Element Datensatz-Kennung aufzuzeichnen. - Wählen Sie die Aufgaben aus, die Sie hinzufügen möchten.
- Wenn Sie fertig sind, klicken Sie auf Hinzufügen und schließen und dann auf Speichern.
Arbeiten mit Dublin-Core-Feldern, Normalisierung und Überprüfung
- Öffnen Sie die Seite Metadaten-Konfigurationsliste (Konfigurationsmenü > Ressourcen > Katalogisierung > Metadaten-Konfiguration).
- Klicken Sie auf den Link Qualifizierter Dublin-Core. Die Seite Profil-Details erscheint.
- Wählen Sie die Registerkarte Normalisierungsprozesse. Der folgende standardmäßige Normalisierungsprozess erscheint in der Registerkarte Normalisierungsprozesse:
- BIB der Sammlung hinzufügen.
- Qualifiziertes DC-Bib Normalisieren beim Speichern
- Qualifizierter Dublin-Core BIB bei Z39.50/SRU-Suche normalisieren
- Wählen Sie für einen der Normalisierungsprozesse Bearbeiten aus der Zeilen-Aktionsliste und wählen Sie die Registerkarte Aufgabenliste, um die verfügbaren Dublin Core Aufgaben anzuzeigen.
- Wenn Sie fertig sind, klicken Sie auf Speichern.
Arbeit mit DC Anwendungsprofilen
- Im MD-Editor beim Hinzufügen von Feldern zu einem Dublin Core-Datensatz (Ressourcen > Metadaten-Editor öffnen).
- Im Feld Datensatzformat, wenn eine Repräsentation in das Feld Datensatzformat eingetragen wird (Ressourcen > Neue digitale Repräsentation).
- Im Feld Datensatzformat beim Hinzufügen einer neuen Sammlung (Ressourcen > Sammlungen verwalten).
- Im Feld Zielformat beim Konfigurieren von Importprofilen (Ressourcen > Importprofile verwalten).
- Im Feld Aufzunehmende Titeldatensatzformate, wenn der Prozess Export digitaler Titel ausgeführt wird (Administrator > Prozess ausführen).
- In Bereichen, in denen Sie die Metadaten konfigurieren, die in Alma angezeigt werden:
- In Suchindizes, in denen Sie die Felder konfigurieren, die im Alma-Bestand durchsucht werden können (Konfiguration > Ressourcen > Suchkonfiguration > Suchindizes).
- In Lieferprofil-Metadaten konfigurieren Sie die Metadatenfelder, die beim Anzeigen digitaler Inhalte im digitalen Viewer angezeigt werden (Konfiguration > Benutzung > Lieferprofil-Metadaten).
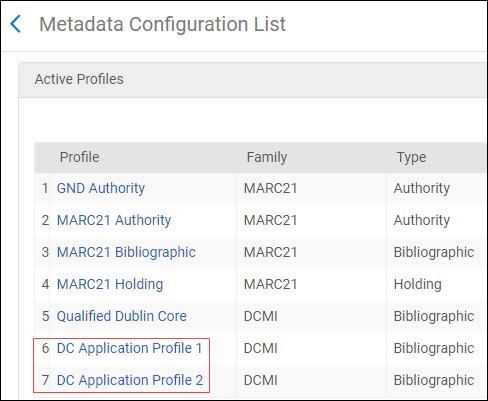
DC Anwendungsprofile - Registerkarte Allgemeine Informationen
Felder zu DC Anwendungsprofilen hinzufügen
- Standard - Fügen Sie ein qualifiziertes Standard-DC-Feld hinzu. Die folgende erscheint:
 Neues Standardfeld
Neues Standardfeld- Wählen Sie aus der Dropdown-Liste Feld ein qualifiziertesDC-Feld.
- Geben Sie eine Beschreibung für das Feld ein.
- Wählen Sie ein Sprachvorkommen aus.
- Wählen Sie aus, ob das Feld ein Pflichtfeld sein soll: Ja/Nein.
- Wählen Sie aus, ob das Feld wiederholbar sein soll: Ja/Nein.
- Lokal - fügen Sie ein lokales DC-Feld hinzu. Die folgende erscheint:
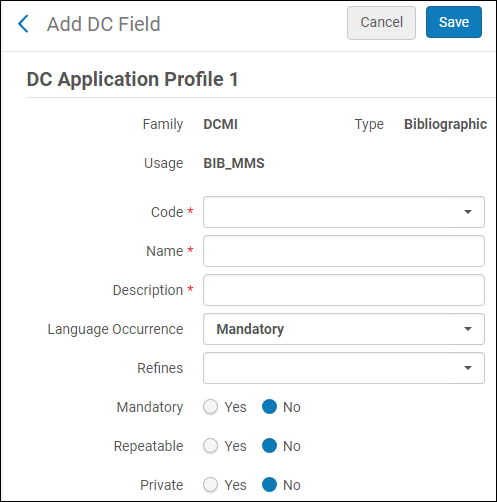 Neues lokales Feld
Neues lokales Feld- Wählen Sie im Feld Code einen Code für das lokale DC-Feld.
- Geben Sie einen Namen für das lokale DC-Feld ein.
- Geben Sie eine Beschreibung für das lokale DC-Feld ein.
- Wählen Sie ein Sprachvorkommen aus.
- Im Feld Verfeinerungen können Sie ein einfaches DC-Feld auswählen, das den Wert des lokalen Felds enthält, wenn es exportiert wird.
- Wählen Sie aus, ob das Feld ein Pflichtfeld sein soll: Ja/Nein.
- Wählen Sie aus, ob das Feld wiederholbar sein soll: Ja/Nein.
- Wählen Sie aus, ob das Feld privat sein soll: Ja/Nein. Wenn Sie Ja wählen, wird das Feld nicht exportiert (aber es wird indiziert).
- Insgesamt können 50 lokale Felder für alle Profile hinzugefügt werden, für die lokale Felder konfiguriert werden können (DCAP1, DCAP2 und ETD).
- Konfigurieren Sie jedes lokale Feld nur einmal in allen Profilen, d. h. wiederholen Sie denselben lokalen Feldcode nicht in mehreren Profilen.
Arbeiten mit dem Normdatenprofil GND
- Suchindizes, die das Auffinden von GND-Datensätzen erleichtern (siehe den Abschnitt GND-Normdatei - Stichwort-Suchindizes – Zuordnung)
- Feld/Unterfeld-Definitionen, die bei der Katalogisierung unterstützen
- Alle GND-Felder sind definiert, inklusive Pflichtfelddefinitionen.
- Von der GND vorgegebener Wortschatz ist vorhanden
- Spezifische Normalisierungsregeln
Arbeit mit MARC 21 Bestandsprofilen
- Felder
- Normierungsprozesse
- Überprüfungsprozesse
- Überprüfung - Fehlerprofilliste
Kontrolle der Anzeige und des Zugriffs auf globale Normdateien im MD-Editor
- Lokal verwaltet
Die Spalte Lokal verwaltet ermöglicht Ihnen, festzulegen, welche Normdatei-Wortschätze im MD-Editor angezeigt werden sollen. Um dies zu tun, können Sie den Wortschatz in dieser Spalte aktivieren oder deaktivieren.
- In der Gemeinschaft verwaltet
Die Spalte In der Gemeinschaft verwaltet legt die Wortschätze fest, die in der Gemeinschaftszone verwaltet werden. Diese Spalte dient nur Informationszwecken. Es gibt keine Option, den Wortschatz in dieser Spalte zu aktivieren oder zu deaktivieren.
- Registerkarten Vorlagen und Datensätze im MD-Editor
- Datensatz-Optionen Datei > Neu im MD-Editor
- Dropdown-Liste der Optionen für den Parameter Wortschatz-Code auf der Seite Importprofil-Details
- Öffnen Sie die Seite Metadatenliste - Konfiguration (Konfigurations-Menü > Ressourcen > Abschnitt Katalogisierung > Metadaten-Konfiguration ). Die Seite Metadaten-Konfigurationsliste erscheint.
Die Optionenliste Datei > Neu im MD-Editor zeigt die Optionen für den Wortschatz an, die in der Metadaten-Konfiguration als Lokal verwaltet gekennzeichnet sind.
 Optionen für den Normdatei-Wortschatz im MD-Editor
Optionen für den Normdatei-Wortschatz im MD-Editor - Aktivieren Sie die Wortschätze in der Spalte Lokal verwaltet, um die Wortschätze festzulegen, die im MD-Editor (und im Importprofil) angezeigt werden sollen.
Konfiguration eines vorgegebenen Wortschatz-Registers
- Katalog-Administrator
- General Systemadministrator
- Erstellen Sie einen vorgegebenen Wortschatz.
- Ordnen Sie das vorgegebene Wortschatz-Register einem bestimmten MARC 21-Unterfeld zu.
- Anzeige der Details eines vorgegebenen Wortschatzes (wählen Sie Ansicht aus der Zeilen-Aktionsliste)
- Fügen Sie einen vorgegebenen Wortschatz hinzu (siehe Hinzufügen/Bearbeiten eines vorgegebenen Wortschatzes)
- Löschen oder fügen Sie die Werte der Wortschatz-Codes hinzu (siehe Hinzufügen/Bearbeiten eines vorgegebenen Wortschatzes)
- Wiederherstellen eines geänderten, voreingestellten, vorgegebenen Wortschatzes (wählen Sie Wiederherstellen aus der Zeilen-Aktionsliste)
- Löschen eines vorgegebenen Wortschatzes, den Sie hinzugefügt haben (wählen Sie Löschen aus der Zeilen-Aktionsliste)
Hinzufügen/Bearbeiten eines vorgegebenen Wortschatzes
- Klicken Sie auf der Seite Vorgegebener Wortschatz - Register (Konfigurationsmenü > Ressourcen > Katalogisierung > Vorgegebener Wortschatz - Register) auf Neuer Wortschatz. Die Seite Vorgegebene Wortschatz-Details wird geöffnet.
- Geben Sie einen Namen und eine Beschreibung ein.
Dieser Name und diese Beschreibung werden auf der Seite Vorgegebener Wortschatz - Register und in den Dropdown-Listen der Optionen für Vorgegebenen Wortschatz auswählen angezeigt, wenn Sie einem MARC 21-Unterfeld einen vorgegebenen Wortschatz im Metadaten-Konfigurationsprofil zuordnen. Siehe Schritt 4 Bearbeiten von Feldern oben. Beachten Sie, dass ein vorgegebener Wortschatz erst nach dem Zuweisen an ein MARC 21-Unterfeld im MD-Editor verwendet werden kann, wie im Schritt 4 unten dargestellt.
- Nachdem Sie mindestens eine vorgegebene Wortschatzbezeichnung hinzugefügt haben, klicken Sie auf Speichern, um alle weiteren Änderungen der Beschreibung zu speichern.
- Im Bereich Neuen Wert hinzufügen geben Sie einen Code und eine Beschreibung ein. Bitte beachten Sie, dass der Code Leerzeichen und Sonderzeichen, aber keinen Unterfeld-Begrenzer enthalten kann.
Der Code, den Sie eingeben, ist der Begriff, der überprüft oder als Option bereitgestellt wird, wenn Sie einen Datensatz im MD-Editor eingeben.
 Kontrollierter Wortschatz - BeispielIm Beispiel oben werden die Codes, die Sie eingeben, zuerst in jeder Zeile angezeigt und die Beschreibung wird rechts von jedem Code in Klammern angezeigt.Die Beschreibung für den Code, die Sie im CV-Register eingeben, kann zusätzliche Informationen zu dem Begriff liefern, den Sie eingegeben haben.
Kontrollierter Wortschatz - BeispielIm Beispiel oben werden die Codes, die Sie eingeben, zuerst in jeder Zeile angezeigt und die Beschreibung wird rechts von jedem Code in Klammern angezeigt.Die Beschreibung für den Code, die Sie im CV-Register eingeben, kann zusätzliche Informationen zu dem Begriff liefern, den Sie eingegeben haben. - Klicken Sie auf Hinzufügen. Der Code wird der Liste der vorgegebenen Wortschatz-Register hinzugefügt.
- Wiederholen Sie Schritte 3 und 4, um zusätzliche Codes (Begriffe) hinzuzufügen.
- Klicken Sie neben einem Code auf Löschen, um diesen zu löschen. Eine Warnung erscheint, wenn Sie versuchen, einen Code-Wert zu löschen, der ursprünglich im voreingestellten Wortschatz enthalten war.
- Klicken Sie auf Abbrechen, um zur Seite Vorgegebener Wortschatz - Register zurückzukehren.
- Wählen Sie auf der Seite Vorgegebener Wortschatz - Register (Konfigurationsmenü > Ressourcen > Abschnitt Katalogisierung > Vorgegebener Wortschatz - Register) Aktionen > Konfigurieren oder Aktionen > Bearbeiten. Die Seite Vorgegebene Wortschatz-Details wird geöffnet.
- Fahren Sie mit den Schritten fort, die im oben stehenden Vorgang beschrieben sind, indem Sie mit Schritt 3 beginnen.
Konfiguration eines vorgegebenen Wortschatz-Registers - Formulare
- Katalog-Administrator
- Allgemeiner Systemadministrator
- Klicken Sie auf der Seite Vorgegebener Wortschatz - Formulare (Konfigurationsmenü > Ressourcen > Katalogisierung > Vorgegebener Wortschatz - Register - Formulare) auf Neuer Wortschatz. Die Seite Vorgegebene Wortschatz-Details wird geöffnet.
- Geben Sie einen Namen und eine Beschreibung ein. Dieser Name und diese Beschreibung werden auf der Seite Vorgegebener Wortschatz - Register - Formulare und in der Dropdown-Liste der Optionen für das Feld Wortschatz bei der Konfiguration von Formularen angezeigt.
- Wählen Sie auf der Seite Vorgegebenes Wortschatz-Register - Formulare den Wortschatz aus.
- Klicken Sie auf Neue Reihe.
- Geben Sie einen Code und eine Beschreibung ein und wählen Sie gegebenenfalls einen Standardwert aus. Diese Beschreibung ist der Begriff, der Benutzern als Option für das Feld bereitgestellt wird.
- Klicken Sie auf Neue Reihe.
- Fügen Sie zusätzliche Zeilen hinzu, um dem Wortschatz zusätzliche Werte hinzuzufügen.
Konfiguration der Verfasser-Nummernlisten
- Katalog-Administrator
- General Systemadministrator
Konfiguration der Standard-Verfassernummer-Listen
- cutter_three_figure_cn.txt
- cutter_three_figure_kor.txt
- lee_jai_chul_1.txt
- lee_jai_chul_2.txt
- lee_jai_chul_3.txt
- lee_jai_chul_4.txt
- lee_jai_chul_5.txt
- lee_jai_chul_6.txt
- lee_jai_chul_7.txt
- lee_jai_chul_8.txt
- Wählen Sie auf der Seite Zuordnungstabelle Verfasser-Nummernlisten (Konfigurationsmenü > Ressourcen > Katalogisierung > Verfasser-Nummernlisten) die Zeilen-Aktion Anpassen in der Zeile, die die Verfassernummer-Zuordnungstabelle enthält, die Sie verwenden wollen. Für weitere Informationen zu Zuordnungstabellen siehe Zuordnungtabellen.
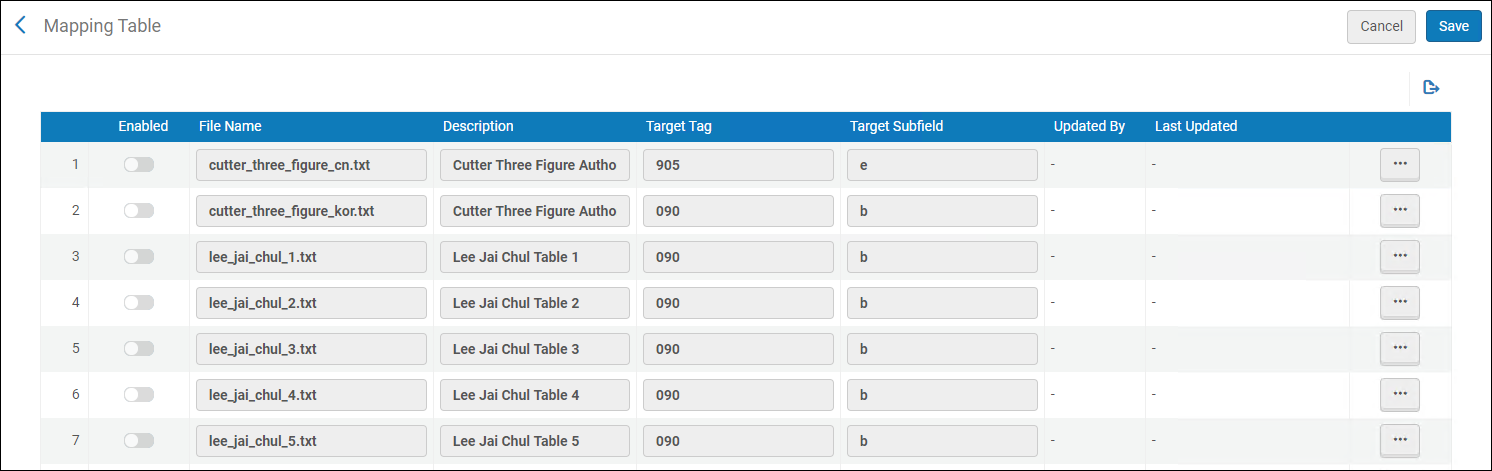 Seite Verfasser-Nummernlisten - Zuordnungstabelle
Seite Verfasser-Nummernlisten - Zuordnungstabelle - Bestätigen Sie, dass die Optionen für den Ziel-Feldcode und das Ziel-Unterfeld angepasst wurden, um Ihren Anforderungen zu entsprechen. Nehmen Sie bei Bedarf Änderungen vor.
- Wählen Sie Speichern.
Lee Jai Chul Methode Logik
Die Lee Jai Chul Methode wird mit der folgenden Logik in Alma implementiert:
- Der koreanische Verfassername existiert vermutlich in dem Feld, an dem der Cursor positioniert ist. Wenn in diesem Feld kein Name gefunden wird, wird keine Verfassernummer erstellt.
- Das erste Hangul-Zeichen des Verfassernamen wird gespeichert und das zweite Hangul-Zeichen des Verfassernamen wird auf Hangul Jam reduziert, mithilfe einer Hangul Konsonanten- und Vokal-Tabelle (mit zwei oder drei Jam pro Hangul, wie etwa 도 > ㄷ und ㅗ). Wenn das erste Zeichen des Verfassernamen einer der häufigsten Nachnamen ist, wird der Code der Zuordnungstabelle für den ersten Jamo (Konsonant) und den zweiten Jamo (Vokal) verbunden. Andernfalls wird der code der Zuordnungstabelle für den ersten Jamo entnommen.
- Die erstellte Verfassernummer ist eine Zeichenfolge, die sich aus der Manipulation des ersten und zweiten Hangul-Zeichens ergibt, wie im vorherigen Punkt beschrieben. Die Zeichenfolge wird in dem Feld/Unterfeld positioniert, das in der Konfiguration der Verfasser-Nummernlisten festgelegt wurde.
- Die Verfassernummer kann nach ihrer Erstellung vom Katalogisierer geändert werden.
- Wenn der von Ex Libris für die Lee-Jai-Chul-Methode (für die Nachnamen der Verfasser) eingestellte Parameter einen Stern enthält (*), dann gelten alle Namen als die beliebtesten.
Diese Logik hat die folgenden Ausnahmen:
- Wenn die 5., 6. oder 8. Tabelle der Lee Jai Chul Methode verwendet wird und wenn der erste Jam ㄱ ist, wird der zweite Jamo codiert, unabhängig davon, ob das erste Zeichen einer der häufigsten Nachnamen ist. Wenn beispielsweise die 5. Tabelle verwendet wird: 추경석 > 추14 (nicht “추1”).
- Wenn der numerische Code für den ersten Jamo zwei Stellen hat, muss kein Code für den zweiten zugeordnet werden. Wenn Sie beispielsweise die 2. Tabelle verwenden: 정필모 > 정84.
- Für Fälle, in denen ein Verfassername durch ein Komma getrennt ist, werden das Komma und das Leerzeichen danach in die erstellte Verfassernummer kopiert. Wenn Sie beispielsweise die 5. Tabelle verwenden: 맨, 마가레트 > 맨, 3.
- Wenn die benutzerdefinierte Aufgabe zur Signatur-Abgrenzung beim Prozess Überprüfung beim Speichern konfiguriert wird (siehe Marc 21 Bestandsüberprüfung beim Speichern), wird eine Duplikat-Überprüfung auf eine identische Verfassernummer im gesamten Bestand durchgeführt. Wenn ein Duplikat gefunden wird, zeigt das System dem Katalogisierer eine Meldung an.
- Einige Tabellen haben Abhängigkeiten, die beachtet werden. Wenn Sie beispielsweise die 3. Tabelle verwenden:
- 3 v ㅏ -ㄱㄷㅊ 1
Dies bedeutet, wenn der Wert des ersten Jamo nicht ㄱ, ㄷ oder ㅊ ist, ist der Code für den zweiten Jamoㅏ 1.
- 3 v ㅓ ㄱㄷ 3
Dies bedeutet, wenn der Wert des ersten Jamo ㄱ oder ㄷ ist, ist der Code für den zweiten Jamoㅏ 3.
- 3 v ㅏ -ㄱㄷㅊ 1
Weitere Informationen finden Sie unter Konfigurieren der benutzerdefinierten Transliteration für die Erstellung von Autorenummern.
- Hangul (in hexadezimalen Code-Punkten)
- Vereinfachtes Hangul
- Beschreibung des Zeichens
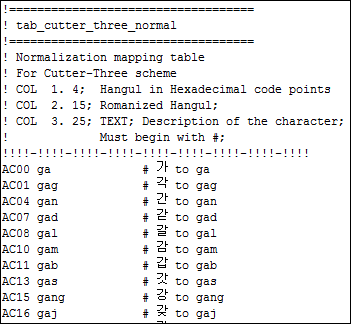
- Klicken Sie auf die Konfigurationsoption Konfiguration einer lokalen Transkriptionstabelle zur Verfassernummer-Erstellung (Konfigurationsmenü > Ressourcen > Katalogisierung >Konfiguration einer lokalen Transkriptionstabelle zur Verfassernummer-Erstellung). Die Seite local_transliteration_author_number.txt erscheint.
 Die Seite local_transliteration_author_number.txt erscheint.
Die Seite local_transliteration_author_number.txt erscheint. - Kopiere / füge deine benutzerdefinierte Transliterationsdatei in den dafür vorgesehenen Platz ein.
- Wählen Sie Speichern.
Standard-Katalogisierungsebene, die auf neue Datensätze angewendet wird, die durch den Metadaten-Import erstellt wurden
Immer wenn ein neuer Datensatz aus der Eingabedatei erstellt wird, ist die Katalogisierer-Ebene dieses Datensatzes die Standardkatalogisierer-Ebene oder "00", wenn kein Standard definiert ist.
Es wird empfohlen, in der Konfiguration "Katalogisierer-Berechtigungsebene" einen Standardwert festzulegen. Siehe Katalogisierungs-Berechtigungen für weitere Informationen.
Konfiguration der Katalogisierungsebenen als Beitrag zu den extern verwalteten Normdateien
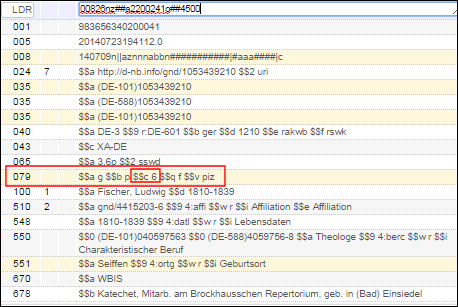
- Klicken Sie in der Zuordnungstabelle Katalogisierer-Ebene zu Wortschatz-Code (Konfigurationsmenü > Ressourcen > Katalogisierung > Zuordnung der Katalogisierungsebene für eine externe Stelle) auf Neue Reihe, um eine Alma-Katalogisiereungsebene der Katalogisierungsebene eines externen Systems zuzuordnen.
- Wählen Sie eine der Alma-Katalogisierungs-Ebenen aus. Die Katalogisierungs-Ebenen werden durch die Konfiguration der Katalogisierer-Berechtigungsebene festgelegt. Siehe Katalogisierungs-Berechtigungen für weitere Informationen.
- Geben Sie eine der Katalogisierungsebenen des externen Systems ein,um die Alma-Katalogisierungsebene, die Sie gewählt haben, zuzuordnen.
- Wählen Sie Richtig oder Falsch aus, um anzugeben, ob die Zuordnung, die Sie für die Ebene erstellen, die Standardzuordnung ist.
Da die Zuordnungstabelle die Spezifizierung von vielen Verknüpfungen zueinander ermöglicht, müssen Sie angeben, welche die Standardzuordnung ist.
- Wählen Sie den relevanten Wortschatz aus.
Die derzeitigen Optionen sind GND, BARE und NLI.
- Klicken Sie auf Neue Reihe.
Wenn Sie eine Zuordnung ändern müssen, wählen Sie die Aktion Löschen für die Zuordnung, die Sie ändern möchten, und erstellen Sie eine neue Zuordnung. - Nach Beendigung der Änderungen klicken Sie auf Speichern oder Speichern und zuteilen. Siehe Zentrale Verwaltung von Konfigurationstabellen für weitere Informationen, einschließlich einer Erläuterungvon Netzwerkverwaltung beenden.
Konfiguration mehrerer Zugriffspunkte für CNMARC 6XX-Felder
- Klicken Sie auf CNMARC 6XX - Konfiguration mehrerer Indexeinträge im Abschnitt Katalogisierung in der Konfiguration der Ressourcen-Verwaltung (Konfigurationsmenü > Ressourcen > Katalogisierung > CNMARC 6XX – Konfiguration mehrerer Indexeinträge). Die Zuordnungstabelle Kategorie CNMARC 6XX erscheint. Für weitere Informationen zu Zuordnungstabellen siehe Zuordnungtabellen.
- Im Abschnitt Neue Reihe Klicken Sie auf Neue Reihe, geben Sie das Feld 6XX und seine Beschreibung ein und klicken Sie für das Feld 6XX, das unterteilt werden soll, auf Neue Reihe.
 Hinzugefügtes CNMARC 6XX-Feld
Hinzugefügtes CNMARC 6XX-Feld - Wiederholen Sie Schritt 2 für alle 6XX-Felder, die Sie zur Zuordnungstabelle Kategorie CNMARC 6XX hinzufügen wollen.
- Wenn Sie mit dem Hinzufügen der 6XX-Felder fertig sind, klicken Sie auf Anpassen.
Konfiguration mehrerer Zugriffspunkte für UNIMARC
- Klicken Sie auf in der Konfiguration der Ressourcen-Verwaltung im Abschnitt Katalogisierung auf Konfiguration mehrerer UNIMARC-Normdatei-IDs( Konfigurationsmenü > Ressourcen > Katalogisierung > Konfiguration mehrerer UNIMARC-Normdatei-IDs). Die Liste der UNIMARC-Felder 6XX, die von mehreren Normdatensätzen gesteuert werden, erscheint. Für weitere Informationen zu Zuordnungstabellen siehe Zuordnungtabellen.
 UNIMARC 6XX Felder
UNIMARC 6XX Felder - Aktivieren oder deaktivieren Sie die 6XX-Felder, die Sie zur Identifikation mehrerer Normdateien verwenden möchten und passen Sie das Feld Beschriftung Ihrer Präferenz entsprechend an.
- Wenn Sie fertig sind, klicken Sie auf Anpassen.
MARC Slim Konfiguration
DCMI-Materialart-Zuordnung
Sie können Alma-Materialarten den DCMI-Typen in den Feldern dc:type und dcterms:type zuordnen. Öffnen Sie dazu die Zuordnungstabelle DCMI-Materialart unter Konfigurationsmenü > Ressourcen > Katalogisierung > DCMI-Materialart-Zuordnung. Für weitere Informationen zu Zuordnungstabellen siehe Zuordnungtabellen.