
Der KI-Metadaten-Assistent im Metadaten-Editor
Was ist der KI-Metadaten-Assistent?
Der AI Metadata Assistant verwendet eine generative KI mit großem Sprachmodell, um Informationen zu einer Bibliotheksressource zu verarbeiten und dem Katalogisierer relevante Metadaten vorzuschlagen, um den Katalogisierungsprozess schneller und effizienter zu gestalten. Der Katalogisierer kann dann die vorgeschlagenen Daten prüfen und akzeptieren, korrigieren oder ablehnen sowie komplexere, fachspezifische Metadaten und bibliotheksspezifische Metadaten hinzufügen.
Der AI Metadata Assistant kann Bilder einer Bibliotheksressource mit anderen bereitgestellten Informationen verarbeiten, Text und Bedeutung extrahieren und sie gemäß Katalogisierungsstandards strukturiert zurückgeben. Er kann zum Erstellen neuer Titelsätze sowie zum Anreichern vorhandener Kurztitel verwendet werden.
Phase I
Phase I des KI-Metadaten-Assistenten von Alma unterstützt das Erstellen und Anreichern von MARC 21-Datensätzen in englischer Sprache – in zukünftigen Phasen werden weitere Katalogisierungs- und Ressourcensprachen und -formate hinzugefügt, da wir mit der Community zusammenarbeiten, um die Fähigkeiten der KI und die Qualität der Metadaten zu bewerten.
Die bereitgestellten Themen werden anhand des Wortschatzes der Library of Congress validiert. In zukünftigen Phasen ist geplant, die Auswahl an Normdatei-Wortschätze zu erweitern.
Zukunftspläne
Die Pläne für zukünftige Phasen umfassen die Unterstützung weiterer Sprachen, Normdatei-Wortschätze und Katalogisierungsformate.
Wir arbeiten mit verschiedenen Bibliotheken weltweit zusammen, um die Benutzerfreundlichkeit und Metadatenqualität für folgende Bereiche zu bewerten:
- Mehr Sprachen, Fach-Wortschatz und Katalogisierungsformate.
- Anreicherungsprozesse von Datensätzen in großen Mengen
- Erstellungsprozesse von Datensätzen in großen Mengen
Wir prüfen auch Optionen für Mengenprozesse und beurteilen, welche Metadaten in welchen Szenarien und Arbeitsabläufen für Bibliotheken nützlich sein könnten.
Funktionen und Beschränkungen
Dieser Service wendet generative KI an, was zu Einschränkungen, Ungenauigkeiten oder Verzerrungen in der Ausgabe führen kann – der vermittelte Arbeitsablauf kombiniert die KI-Funktionen mit der Expertise des Bibliothekars, um Effizienz und Genauigkeit in Einklang zu bringen.
Generative KI-Tools für große Sprachmodelle sind flexibel, ihre Reaktionen unterscheiden sich je nach Verwendungszweck und entwickeln sich im Laufe der Zeit weiter. Wir arbeiten kontinuierlich mit der Community zusammen, um die Nützlichkeit und Genauigkeit der ausgegebenen Daten zu maximieren und die Effizienz unserer Systemmeldungen und Datenverarbeitung aufrechtzuerhalten.
Obwohl wir unsere Systemmeldungen sorgfältig formulieren, gibt es Fälle, in denen sich die KI wie folgt verhält:
- Gibt ungenaue oder allgemeine Daten zurück (z. B. irrelevante Ausgabeinformationen).
- Befolgt die Katalogisierungsstandards nicht so genau, wie es ein professioneller Katalogisierer tun würde (z. B. fehlende ISBD-Zeichensetzung oder Verwendung falscher MARC-Feld-Indikatoren).
- Gibt nicht alle angeforderten Metadaten-Felder zurück.
- Die Verarbeitung einiger Sprachen beim Katalogisieren von Ressourcen in diesen Sprachen erfolgt nicht korrekt.
- Gibt für bestimmte Normdatei-Wortschätze keine korrekten Schlagwörter zurück.
- Unter bestimmten Bedingungen können Bilder nicht immer verarbeitet werden, z. B. bei schlechter Bildqualität, starkem Rauschen im Bildhintergrund oder wenn das Bild nicht hochkant ist.
Was wir tun, um diese Beschränkungen abzumildern
-
Zusammenarbeit mit Katalogisierern und der Alma-Community, um die Qualität der Metadaten zu bewerten und zu verbessern.
-
Prüfen der zurückgegebenen Schlagwörter anhand von Normdateien: Wir prüfen, ob das zurückgegebene Schlagwort mit einem bestehenden Normdatensatz übereinstimmt, und verknüpfen es entweder vollständig oder teilweise. Es kann entweder mit der Ansetzungsform oder mit der Verweisungsform übereinstimmen, wenn von der KI eine Verweisungsform vorgeschlagen wird, kann es auf die Ansetzungsform geändert werden, entweder durch den Katalogisierer, indem er F3 im Metadaten-Editor benutzt, oder automatisch durch den geplanten Prozess „Normdateien - Ansetzungsform-Korrektur“ (für weitere Informationen siehe Mit Normdatensätzen verknüpfte Prozesse).
-
Schrittweise Unterstützung für verschiedene Sprachen und Vokabeln in Zusammenarbeit mit den darin arbeitenden Bibliotheken und entsprechend den wachsenden Fähigkeiten des KI-Modells.
-
Anwenden von Normalisierungsprozessen zum Formatieren und Bereinigen von Daten sowie zum Hinzufügen von Informationen zur Datenherkunft.
-
Überwachen des Feedbacks der Katalogisierer und regelmäßiges Aktualisieren unserer Eingabeaufforderungen mithilfe eines neuen geplanten Prozesses, KI-Einstellungen synchronisieren.
-
Entwicklung von Werkzeugen für Bibliotheken zur Konfiguration lokaler Normierungsprozesse und zum Treffen eigener Entscheidungen darüber, welche Daten behalten oder hinzugefügt werden sollen.
Aktivieren des AI Metadata Assistant in Ihrer Alma-Umgebung
Um den AI Metadata Assistant zu aktivieren, müssen Sie über die folgenden Rollen verfügen:
- Allgemeiner Administrator
- Katalog-Administrator
- Bestands-Administrator
Der AI Metadata Assistant ist in allen Institutionen standardmäßig deaktiviert.
Sobald die Administratoren die Vorteile und Grenzen dieses generativen KI-Tools kennen, müssen sie die Risiken verstehen und entscheiden, ob und wie ihre Bibliothek damit arbeitet. Sie können den Haftungsausschluss KI-Metadaten-Assistent im Metadaten-Editor unter Konfigurationsmenü > Ressourcen > Katalogisierung > KI-Verwendungsprofil akzeptieren, indem sie diese Option auf Ja einstellen und speichern.
Nachdem der Administrator den KI-Metadaten-Assistenten in einer Umgebung aktiviert hat, können Katalogisierer mit der Rolle KI-gestützte Katalogisierung mit der Verwendung beginnen.
Testen in einer Sandbox-Umgebung
Die Einstellungen des KI-Metadaten-Assistenten werden regelmäßig mithilfe des Prozesses KI-Einstellungen synchronisieren aktualisiert. Dies stellt sicher, dass die KI-Eingabeaufforderung effektiv und aktuell bleibt, auch wenn sich KI-Modelle weiterentwickeln und ändern.
Da geplante Prozesse in Sandbox-Umgebungen deaktiviert sind, führen Sie vor dem Testen des KI-Metadaten-Assistenten die Funktion KI-Einstellungen synchronisieren aus, um dies mit den aktuellen Einstellungen zu testen.
- Klicken Sie auf Prozesse überwachen > Registerkarte Angesetzt.
- Filtern Sie nach Arbeitsfeld = Datenservices.
- Klicken Sie auf Jetzt ausführen (verfügbar in Sandbox-Umgebungen) in den Zeilen-Aktionen für KI-Einstellungen synchronisieren.
Nachdem der Prozess abgeschlossen ist, können Katalogisierer mit den erforderlichen Rollen den KI-Assistenten im MD-Editor testen. Für weitere Informationen siehe KI-Metadaten-Assistenten.
Konfiguration des KI-Metadaten-Assistenten
Um den KI-Metadaten-Assistenten zu konfigurieren, müssen Sie über die folgenden Rollen verfügen:
- Allgemeiner Administrator
- Katalog-Administrator
Korrigieren generierter Metadaten mithilfe eines Normalisierungsprozesses
Um Bibliotheken mehr Kontrolle über die Verwendung von durch KI generierten Metadaten zu geben, kann die Institution diese mithilfe eines Normalisierungsprozesses korrigieren. Normalisierungsregeln können verwendet werden, um Metadatenfelder und -unterfelder zu entfernen, zu ersetzen oder hinzuzufügen. So kann eine Institution beispielsweise lokale Felder hinzufügen, die für ihren Katalog relevant sind, ein Unterfeld zur Datenherkunft (z. B. $$7 in Notizfeldern) zu bestimmten Feldern hinzufügen, wenn diese von der KI generiert wurden, bestimmte Felder entfernen, die keine generierten Metadaten enthalten sollen, wenn sie generiert wurden, usw.
Der ausgewählte Normalisierungsprozess wird sowohl im Erstellungs- als auch im Anreicherungs-Arbeitsablauf auf die generierten Metadaten angewendet, bevor der resultierende Entwurf dem Katalogisierer zur Verfügung steht.
Wenn die generierten Daten mit einem vorhandenen Datensatz zusammengeführt werden (beim Erweitern eines Datensatzes mit dem KI-Assistenten) oder aus einer Vorlage erweitert werden, um fehlende Felder hinzuzufügen (beim Erstellen eines neuen Datensatzes), wird der Normalisierungsprozess nur auf die von KI generierten Daten angewendet, bevor diese Zusammenführung stattfindet.
Sie können den Normalisierungsprozess, der bei der Arbeit mit dem KI-Metadaten-Assistenten verwendet wird im KI-Verwendungsprofil (Konfigurationsmenü > Ressourcen > Katalogisierung > AI-Verwendungsprofil) im Abschnitt KI-Metadaten-Assistent – andere Einstellungen konfigurieren.

Auswählen einer Zusammenführungsmethode zum Verbessern von Datensätzen mit dem KI-Assistenten
Wenn Sie einen Datensatz mit dem KI-Metadaten-Assistenten erweitern, werden die generierten Metadaten mit dem erweiterten Datensatz zusammengeführt und der vorhandene Datensatz der Bibliothek wird als bevorzugter Datensatz betrachtet.
Die Daten der Bibliothek werden standardmäßig nicht überschrieben. Die von der KI generierten Metadaten werden dem Datensatz hinzugefügt, wenn:
- Das Feld ist wiederholbar
- Das Feld ist nicht wiederholbar und existiert noch nicht im bevorzugten Datensatz
Institutionen können die Verwendung der vom KI Metadaten-Assistenten generierten Daten im Anreicherungsprozess steuern, indem sie die Standard-Zusammenführungsregel außer Kraft setzen und eine lokale Zusammenführungsregel auswählen, zum Beispiel durch die Auswahl, dass bestimmte wiederholbare Felder (z. B. Produktions- und Veröffentlichungsinformationen) nicht hinzugefügt werden, wenn sie bereits im Datensatz vorhanden sind, oder das Überschreiben bestimmter Felder, von denen bekannt ist, dass sie problematisch sind. Siehe Arbeiten mit Zusammenführungsregeln für weitere Informationen.
Sie können die übergeordnete Zusammenführungsmethode konfigurieren, die bei der Erweiterung eines Datensatzes mit dem KI-Metadaten-Assistent auf der Seite „KI-Verwendungsprofil“ verwendet werden soll. (Konfigurationsmenü > Ressourcen > Katalogisierung > KI-Verwendungsprofil).

Konfiguration der an den KI-Metadaten-Assistenten gesendeten Metadaten-Anfragetypen
Neben der Korrektur der von KI vorgeschlagenen Metadaten durch einen Normalisierungsprozess können Administratoren auch auswählen, zur Erzeugung welcher Arten von Metadaten die KI auf der Seite KI-Verwendungsprofil (Konfigurationsmenü > Ressourcen > Katalogisierung > KI-Verwendungsprofil) im Abschnitt KI-Metadaten-Assistent – andere Einstellungen aufgefordert wird.

Generative KI-Tools für große Sprachmodelle sind flexibel, ihre Reaktionen unterscheiden sich je nach Verwendungszweck und entwickeln sich im Laufe der Zeit weiter. Die von der KI zurückgegebenen Metadaten variieren von Mal zu Mal und können mehr oder weniger Metadaten enthalten als jene, die angefordert wurden. Die Anforderung einer spezifischen Art von Metadaten erhöht die Wahrscheinlichkeit, dass sie von der KI generiert werden, garantiert dies aber nicht.
Sie können einen bestimmten Typ von Metadaten aus der an die KI gesendeten Anfrage entfernen, indem Sie ihn in der Tabelle Angeforderte Metadatenkonfiguration deaktivieren. Die Zeilen in dieser Tabelle können nur aktiviert oder deaktiviert werden (die Reihenfolge und die eingestellten Standardwerte haben keinen Einfluss auf die Arbeit des KI-Metadaten-Assistenten).

Wenn die Übersicht aktiviert ist, können Sie auch auswählen, welche Art von Übersicht-Anfrage an die KI gesendet werden soll:
- Eine Kopie der Übersicht anfordern, falls verfügbar, und eine Übersicht erstellen, falls nicht verfügbar (Standard) — die KI wird aufgefordert, die Beschreibung des Herausgebers zu kopieren, falls sie in den bereitgestellten Daten oder Bildern vorhanden ist, die dem Herausgeber zugeschrieben werden, oder, falls dies nicht möglich ist, eine Beschreibung der Ressource mit eigenen Worten zu erstellen.
- Eine Kopie der Übersicht anfordern, falls verfügbar — die KI wird aufgefordert, die Beschreibung des Herausgebers zu kopieren, falls sie in den bereitgestellten Daten oder Bildern vorhanden ist, die dem Herausgeber zugeschrieben werden.
- Eine erstellte Übersicht anfordern — die KI wird aufgefordert, eine Beschreibung der Ressource in ihren eigenen Worten zu erstellen.

Arbeiten mit dem AI Metadata Assistant
Um mit dem AI Metadata Assistant im Metadaten-Editor arbeiten zu können, müssen Sie über die beiden folgenden Rollen verfügen:
- Katalogisierer
- KI-gestützte Katalogisierung
Die Arbeit mit dem AI Metadata Assistant erfordert eine dedizierte Rolle, um Bibliotheken die Kontrolle darüber zu geben, welche Katalogisierer mit generativen KI-Tools arbeiten.
Mit dem AI Metadata Assistant können Sie einen neuen Titelsatz erstellen oder einen vorhandenen Kurztitel anreichern. Sobald der Assistent die Verarbeitung des Datensatzes abgeschlossen hat, wird der Entwurf mit den vorgeschlagenen Metadaten an den Metadaten-Editor weitergeleitet, damit Sie ihn überprüfen und akzeptieren, korrigieren oder verwerfen können. Eine Benachrichtigung in Echtzeit zeigt an, dass der Entwurf zur Bearbeitung für Sie bereitsteht.
Erstellen eines neuen Datensatzes
Sie können mit dem KI-Assistenten neue Datensätze im Metadaten-Editor erstellen.
- Klicken Sie im Metadaten-Editor unter Neu auf Mit KI-Assistent erstellen. Das Popup Neuer Datensatz vom KI-Assistenten wird geöffnet.
Neuer Datensatz vom KI-Assistenten Feld Beschreibung Titel Obligatorisch. Geben Sie den Titel der zu erstellenden Ressource an. Verfasser Optional. Geben Sie Informationen zum Verfasser oder Ersteller der Ressource an. ISBN Optional. Geben Sie die ISBN eines Buches an. Inhaltsnotiz Optional. Geben Sie Informationen zum Inhalt der Ressource an. Übersicht - Notiz Optional. Geben Sie eine Zusammenfassung der Ressource an. Datensatzformat Derzeit wird nur MARC 21 unterstützt. Aus Vorlage erweiternDie Vorlage, die beim Erweitern der generierten Metadaten verwendet werden soll.Wenn diese Option ausgewählt ist, werden nach der Verarbeitung und Normalisierung der von der KI generierten Metadaten alle fehlenden Felder der Vorlage zum resultierenden Entwurfsdatensatz hinzugefügt, um sicherzustellen, dass der Katalogisierer keine von der Bibliothek benötigten Felder übersieht.Alma merkt sich Ihre ausgewählte Vorlage für die zukünftige Verwendung des KI-Metadaten-Assistenten. Sie müssen diese Einstellung daher nur ändern, wenn Sie den Typ der zu katalogisierenden Ressource ändern und eine andere Vorlage verwenden müssen.AnhängeOptional. Laden Sie bis zu vier Dateien hoch, die relevante Informationen zur Ressource enthalten (z. B. die Rückseite eines Buches, ein Inhaltsverzeichnis, eine vom Herausgeber erhaltene Ressourcenbeschreibung usw.).Unterstützte Formate:-
JPEG
-
PNG
-
GIF
-
PDF - beim Hochladen einer PDF-Datei werden die ersten vier Seiten des PDFs von der KI extrahiert und verarbeitet.
-
DOCX - beim Hochladen einer Word-Datei (docx) werden die ersten vier Seiten der Datei extrahiert und von der KI verarbeitet.
Sie können eine Datei von Ihrem Gerät auswählen oder mit der Kamera Ihres Geräts Bilder der Ressource aufnehmen. Die Bilder können zugeschnitten werden, um den Fokus auf den Bereich mit den relevanten Informationen zu richten und so die Qualität der zurückgegebenen Antwort zu verbessern.Wenn Ihr Gerät über mehrere Kameras verfügt, können Sie auswählen, welche Kamera Sie verwenden möchten.Angeforderte MetadatenDefiniert die angeforderten Arten von Metadaten, die die KI generieren soll. Wenn diese Option ausgewählt ist, wird die KI nur aufgefordert, die spezifischen Metadaten zu erstellen. Die Optionen sind von der Konfiguration des Administrators abhängig (siehe Konfiguration der an den KI-Metadaten-Assistenten gesendeten Metadaten-Anfragetypen) und sind folgende:-
Alle — Aufforderung an die KI, alle verfügbaren Metadaten zu generieren, die von Ihrem Administrator freigegeben wurden.
-
Schlagwörter anfordern — Aufforderung an die KI, Vorschläge für Schlagwörter zu generieren.
-
Übersicht anfordern — Aufforderung an die KI, eine Übersicht für die Ressource zu kopieren und/oder zu erstellen.
-
Inhaltsinformationen anfordern - Aufforderung an die KI, eine Inhaltsnotiz zu erstellen (relevant, wenn der KI Informationen über den Inhalt der Ressource zur Verfügung gestellt werden, beispielsweise ein Bild des Inhaltsverzeichnisses oder der Titelliste einer CD).
-
Zusätzliche Metadaten anfordern — Aufforderung an die KI, alle anderen verfügbaren Metadaten zu generieren, die von Ihrem Administrator aktiviert wurden.
-
Alma merkt sich Ihre ausgewählte Vorlage für die zukünftige Verwendung der Option Mit KI-Assistent erstellen. Sie müssen diese Einstellung daher nur ändern, wenn Sie den Typ der zu katalogisierenden Ressource ändern und andere Metadaten anfordern müssen.
-
Generative KI-Tools für große Sprachmodelle sind flexibel, ihre Reaktionen unterscheiden sich je nach Verwendungszweck und entwickeln sich im Laufe der Zeit weiter. Die von der KI zurückgegebenen Metadaten variieren von Mal zu Mal und können mehr oder weniger Metadaten enthalten als jene, die angefordert wurden. Die Anforderung einer spezifischen Art von Metadaten erhöht die Wahrscheinlichkeit, dass sie von der KI generiert werden, garantiert dies aber nicht.
-
- Wählen Sie Datensatz erstellen, um die Informationen an die KI zu übermitteln.
 Einen neuen Datensatz mit dem KI-Assistenten erstellen
Einen neuen Datensatz mit dem KI-Assistenten erstellen
Sie können in Alma weiterarbeiten, während die KI die Informationen verarbeitet. Sie werden benachrichtigt, wenn die generierten Metadatenvorschläge für die Bearbeitung im Metadaten-Editor bereitstehen. Für weitere Informationen siehe Überprüfen von KI-Metadatenvorschlägen.
Anreichern eines Kurztitels
Sie können Kurztitel anreichern.
- Öffnen Sie im Metadaten-Editor den Datensatz, den Sie im Bearbeitungsmodus anreichern möchten. Wählen Sie unter Bearbeiten von Aktionen Mit KI-Assistent verbessern.
Das Popup Datensatz vom KI-Assistenten anreichern wird geöffnet und zeigt den Titel des Datensatzes an, den Sie zur Anreicherung ausgewählt haben, sodass Sie sicher sein können, dass Sie den ausgewählten Datensatz anreichern.
Sie können außerdem bis zu vier Bilder der Ressource mit relevanten Informationen anhängen (z. B. die Rückseite eines Buches, ein Inhaltsverzeichnis, eine vom Herausgeber erhaltene Ressourcenbeschreibung usw.). Unterstützte Formate: JPEG, PNG, GIF und PDF(beim Hochladen einer PDF-Datei werden die ersten vier Seiten des PDFs von der KI extrahiert und verarbeitet).
Sie können eine Datei von Ihrem Gerät auswählen oder mit der Kamera Ihres Geräts Bilder der Ressource aufnehmen. Die Bilder können zugeschnitten werden, um den Fokus auf den Bereich mit den relevanten Informationen zu richten und so die Qualität der zurückgegebenen Antwort zu verbessern.
Wenn Ihr Gerät über mehrere Kameras verfügt, können Sie auswählen, welche Kamera Sie verwenden möchten.
-
(Optional) Klicken Sie bei Bedarf auf Angeforderte Metadaten.
Das Feld Angeforderte Metadaten gibt an, welche Arten von Metadaten von der KI generiert werden sollen. Wenn diese Option ausgewählt ist, wird die KI nur aufgefordert, die spezifischen Metadaten zu erstellen. Die Optionen sind von der Konfiguration des Administrators abhängig (siehe Konfiguration der an den KI-Metadaten-Assistenten gesendeten Metadaten-Anfragetypen) und sind folgende:- Alle — Aufforderung an die KI, alle verfügbaren Metadaten zu generieren, die von Ihrem Administrator freigegeben wurden.
- Schlagwörter anfordern — Aufforderung an die KI, Vorschläge für Schlagwörter zu generieren.
- Übersicht anfordern — Aufforderung an die KI, eine Übersicht für die Ressource zu kopieren und/oder zu erstellen.
- Inhaltsinformationen anfordern - Aufforderung an die KI, eine Inhaltsnotiz zu erstellen (relevant, wenn der KI Informationen über den Inhalt der Ressource zur Verfügung gestellt werden, beispielsweise ein Bild des Inhaltsverzeichnisses oder der Titelliste einer CD).
- Zusätzliche Metadaten anfordern — Aufforderung an die KI, alle anderen verfügbaren Metadaten zu generieren, die von Ihrem Administrator aktiviert wurden.
- Alma merkt sich Ihre ausgewählte Vorlage für die zukünftige Verwendung der Option Mit KI-Assistent erstellen. Sie müssen diese Einstellung daher nur ändern, wenn Sie den Typ der zu katalogisierenden Ressource ändern und andere Metadaten anfordern müssen.
- Generative KI-Tools für große Sprachmodelle sind flexibel, ihre Reaktionen unterscheiden sich je nach Verwendungszweck und entwickeln sich im Laufe der Zeit weiter. Die von der KI zurückgegebenen Metadaten variieren von Mal zu Mal und können mehr oder weniger Metadaten enthalten als jene, die angefordert wurden. Die Anforderung einer spezifischen Art von Metadaten erhöht die Wahrscheinlichkeit, dass sie von der KI generiert werden, garantiert dies aber nicht.
-
Wählen Sie Datensatz anreichern, um die Informationen an die KI zu übermitteln.
-
Der Datensatz ist bis zum Abschluss der KI-Verarbeitung für die Bearbeitung gesperrt und in MDE als schreibgeschützter Datensatz verfügbar. Sie können in Alma weiterarbeiten, während die KI die Informationen verarbeitet – und Sie werden benachrichtigt, wenn die vorgeschlagenen Metadaten zur Bearbeitung im Metadaten-Editor bereitstehen. Für weitere Informationen siehe Überprüfen von KI-Metadatenvorschlägen.

Überprüfung von KI-generierten Metadatenvorschlägen
Wenn der Entwurf mit den von der KI generierten Metadatenvorschlägen zur Bearbeitung bereitsteht, wird eine Benachrichtigung mit einem Link zum Entwurf im Metadaten-Editor angezeigt:

Informationen zu den abgeschlossenen Aufgaben des KI-Metadaten-Assistenten, die Sie ausgelöst haben, können Sie auch im Menü „Benachrichtigungen in Echtzeit“ in der Kategorie „Katalogisierung“ sehen:

Im Metadaten-Editor werden zu überprüfende Datensatzentwürfe zur einfachen Identifizierung mit einem „KI-generiert“- oder „KI-angereichert“-Kennzeichen gekennzeichnet. Sobald der Entwurf vom Katalogisierer überprüft und gespeichert wurde, wird dieses Kennzeichen entfernt:

Der Entwurf kann nach Bedarf bearbeitet, gespeichert oder verworfen werden.
Die von der KI generierten, nicht gespeicherten Metadatenvorschläge werden violett angezeigt, um den Katalogisierern die Identifizierung und Überprüfung zu erleichtern. Wenn Warnungen vorliegen, werden sie orange angezeigt (Felder mit Warnungen werden unabhängig von der Quelle gleich angezeigt): ein vorhandener Datensatz, eine Vorlage oder KI-generiert).


Arbeiten mit dem KI-Metadaten-Assistenten in der Alma Mobile 2 App
Mit der Alma Mobile App können Bibliothekare die Kamera eines mobilen Geräts verwenden, um Bibliotheksressourcen zu bearbeiten. Beispielsweise das Einscannen eines Exemplar-Barcodes.
Katalogisierer mit der Rolle KI-unterstützte Katalogisierung können damit problemlos Bilder von Bibliotheksressourcen aufnehmen und diese zur Verarbeitung an den KI-Metadaten-Assistenten senden.
Sobald der Assistent die Verarbeitung der Bilder abgeschlossen hat, wird der Entwurf mit den vorgeschlagenen Metadaten des KI-Assistenten an den Metadaten-Editor weitergeleitet, damit der Katalogisierer ihn prüfen und akzeptieren, korrigieren oder verwerfen kann.
Sie können einen bestehenden Datensatz anreichern, indem Sie den Strichcode des Exemplars scannen, um den anzureichernden Datensatz abzurufen. Verwenden Sie anschließend die Kamera Ihres Mobilgeräts, um Fotos von dem Exemplar zu machen und diese an den KI-Metadaten-Assistenten zu übermitteln.
Sie können auch einen neuen Datensatz erstellen, indem Sie einen Titel und Bilder übermitteln (und bei Bedarf weitere optionale Informationen eingeben).
Weitere Details zur Alma Mobile App finden Sie unter Einführung in die Alma Mobile 2 App.
Feedback senden
Um Feedback zur Qualität der generierten Metadatenvorschläge abzugeben, klicken Sie im MD-Editor auf die Schaltfläche „KI-Feedback“, während Sie an einem Entwurf arbeiten, der mit dem KI-Metadaten-Assistenten erstellt bzw. angereichert wurde. Dieses Feedback wird verwendet, um die Qualität der KI-generierten Metadaten im Laufe der Zeit zu überwachen und beizubehalten.

Wählen Sie die Punktzahl von 1 bis 5 aus, die Sie den KI-generierten Metadatenvorschlägen geben möchten, und geben Sie eine Anmerkung ein, um weitere Details anzugeben:

Identifizieren von Datensätzen mit von der KI vorgeschlagenen Metadaten
Wenn ein Datensatz mit dem KI Metadaten-Assistenten erstellt oder angereichert wird, werden diese Informationen auf zwei Arten in Alma verwaltet:
- MARC 21-Metadaten im generierten Entwurf:
- Zusätzlich zu den KI-generierten Metadatenvorschlägen wird dem Entwurf eine Notiz 588 - Quelle der Beschreibung hinzugefügt. Dieses Feld ist in Alma durchsuchbar.
- Wenn die von KI generierten Metadaten eine 520-Zusammenfassungsnotiz enthalten, wird ein Unterfeld „Datenherkunft“ ($$7) hinzugefügt, das angibt, dass es von KI generiert wurde (dies wird immer hinzugefügt, unabhängig davon, ob die Zusammenfassung von einem Bild kopiert oder von der KI erstellt wurde, da der KI-Prozess des Datenkopierens einige Änderungen daran mit sich bringen kann).
- Ein Administrator kann auch einen Normalisierungsprozess konfigurieren, der dem Entwurf weitere Felder oder Unterfelder hinzufügt (z. B. ein lokales Feld mit Informationen zu den KI-Metadatenrichtlinien des Katalogs) - weitere Informationen finden Sie unter Konfiguration des KI-Metadaten-Assistenten.
- Titelsatz-Informationen: Wenn ein Entwurf mit KI-generierten Metadatenvorschlägen gespeichert wird (ohne freigegeben oder verworfen zu werden) – werden die Informationen zur Verwendung des KI-Metadaten-Assistenten aufgezeichnet und können dann in Analytics und Datensatz-Versionen angezeigt werden.
Anzeigen von Informationen zum KI-Metadaten-Assistenten in Analytics
Informationen zum KI-Metadaten-Assistenten sind in der gemeinsamen Dimension „Titeldaten-Details“ von Analytics verfügbar.
Die bibliografischen Details für jeden Datensatz enthalten Informationen darüber, ob er mithilfe von KI erstellt oder mit KI angereichert wurde.
Bibliotheken können Berichte über die Anzahl der mit dem KI-Assistenten erstellten bzw. mit dem KI-Assistenten erweiterten Titel erstellen.
Weitere Informationen finden Sie unter: Titeldaten-Details.
Anzeigen von Informationen des KI-Metadaten-Assistenten in Datensatzentwürfen
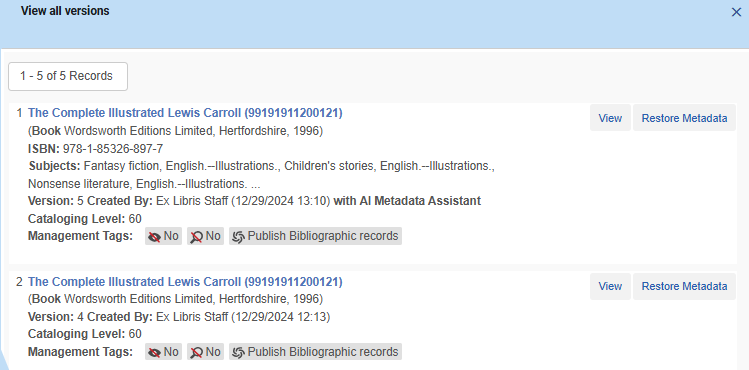
Für alle Datensätze, die nach der offiziellen Inbetriebnahme im Februar 2025 mit dem KI-Metadaten-Assistenten erstellt oder angereichert und anschließend von einem anderen Katalogisierer oder Prozess aktualisiert wurden (wodurch eine Datensatzversion generiert wird), ist es beim Anzeigen der Datensatzversionen möglich, zu erkennen, welche Version mit dem KI-Metadaten-Assistenten erstellt wurde:
In der Titelsuche angezeigtes KI-Symbol
In Almas neuer UX für die Titelsuche werden mit dem KI-Metadaten-Assistenten erstellte oder angereicherte Datensätze mit dem KI-Sternesymbol angezeigt, sodass sie leicht zu identifizieren sind.
Wenn Sie mit der Maus über das Symbol fahren, wird eine Kurzinfo mit Angaben dazu angezeigt, ob der Datensatz mit KI erstellt, mit KI angereichert oder beides wurde.

Häufig gestellte Fragen
-
F: Werden die Daten, die ich zum Erstellen oder Anreichern des Datensatzes verwende, zum Trainieren der KI verwendet?
A: Nein – wir geben die Daten nur zur Verarbeitung an die KI weiter, nicht um sie zu trainieren. -
F: Woher kommen die Metadaten?
A: Die Metadaten werden von einem AI LLM entsprechend den vom Katalogisierer bereitgestellten Informationen generiert (entweder manuell oder aus einem anzureichernden Bib-Datensatz). Als Eingabeinformationen werden derzeit bibliografische Metadaten wie der Titel der Ressource (Pflichtfeld) sowie Dateien mit Bildern der Ressource (z. B. Titelseite, Rückseite, Inhaltsverzeichnis, Beschreibung des Herausgebers) unterstützt.Wie bei allen KI-Modellen werden auch die Trainingsdaten des Modells zur Generierung einer Antwort verwendet. Dazu gehört das Wissen über MARC-Felder und -Unterfelder, relevante LC-Schlagwörter und ob in den Trainingsdaten des KI-Modells Informationen zu der jeweiligen Ressource vorhanden sind (z. B. Erscheinungsjahr, Geburtsjahr des Verfassers, Ressourcenbeschreibung), die auch bei der Generierung der Metadaten verwendet werden können.
-
F: Führt die KI eine Onlinesuche durch, um Daten für mich zu beschaffen?
A: Nein – unsere KI-Plattform verwendet keine Online-Suche. Die Metadaten werden auf Grundlage der von der Bibliothek erstellten Informationen und der in den KI-Trainingsdaten vorhandenen Informationen bereitgestellt. -
F: Wenn ich Bilder von Büchern hochlade – werden diese irgendwo gespeichert?
A: Nein, wir verwenden das Bild nur zur Angabe von Metadaten und speichern es nicht für andere Zwecke. -
F: Wird die KI für mich katalogisieren?
A: Der KI-Assistent macht Vorschläge für Metadaten zur Überprüfung durch einen Katalogisierer.
Der Katalogisierer prüft diese und kann die Vorschläge annehmen, korrigieren oder ablehnen. Da generative KI zu Ungenauigkeiten oder Verzerrungen in der Ausgabe führen kann, ermöglicht die Kombination menschlicher und technologischer Fähigkeiten ein rationalisierteres und effizienteres Katalogisierungserlebnis bei gleichzeitiger Wahrung der Datenintegrität. -
F: Warum werden mir bei jeder Verwendung des AI Metadata Assistant unterschiedliche Metadaten für dieselbe Ressource vorgeschlagen?
A: Generative KI-Tools für große Sprachmodelle sind flexibel, ihre Reaktionen unterscheiden sich je nach Verwendungszweck und entwickeln sich im Laufe der Zeit weiter. Die von der KI ausgegebenen Metadaten variieren jedes Mal je nach den ihr bereitgestellten Informationen, der katalogisierten Ressource und der internen Verarbeitung der KI selbst. -
F: Kann der AI Metadata Assistant verwendet werden, um beliebige Datensätze im Katalog anzureichern?
A: Nein – der KI-Assistent kann nur zum Anreichern von Datensätzen verwendet werden, die nicht für die Bearbeitung gesperrt sind und die ich gemäß meiner Katalogisierungsrolle und -ebene bearbeiten darf.
Darüber hinaus unterstützt Phase I nur Datensätze im MARC 21-Format und nicht die Anreicherung von CZ-Datensätzen.
Für Netzwerkmitglieder – die Möglichkeit, Netzwerkdatensätze zu erstellen oder zu erweitern, hängt auch von den Netzwerkeinstellungen ab. -
F: Phase I unterstützt die englische MARC 21-Katalogisierung von Büchern unter Verwendung von LC-Normdateien – was ist für die nächsten Phasen geplant?
A: Wir sprechen mit Bibliotheken weltweit, um Arbeitsabläufe zu verstehen, den Bedarf zu ermitteln und gemeinsam mit der Community zu entscheiden, worauf wir uns als Nächstes konzentrieren. Zu den Optionen gehören mehr Arbeitsabläufe, mehr Katalogisierungssprachen und mehr Schlagwort-Wortschätze. -
F: Wie stellen Sie sicher, dass die zurückgegebenen Schlagwörter echt sind?
A: Wir prüfen, ob das zurückgegebene Schlagwort mit einem bestehenden Normdatensatz übereinstimmt, und verknüpfen es entweder vollständig oder teilweise. Es kann entweder mit der Ansetzungsform oder mit der Verweisungsform übereinstimmen – wenn von der KI eine Verweisungsform vorgeschlagen wird, kann es auf die Ansetzungsform geändert werden, entweder durch den Katalogisierer, indem er F3 im Metadaten-Editor benutzt, oder automatisch durch den geplanten Prozess „Normdateien - Ansetzungsform-Korrektur“ (für weitere Informationen siehe Mit Normdatensätzen verknüpfte Prozesse). -
F: Kann die KI beliebige MARC 21-Felder bereitstellen?
A: Nein. Wir bitten den KI-Assistenten, die nützlichsten Felder zu generieren und dabei ein Gleichgewicht zwischen Hilfestellung und Genauigkeit zu wahren. Alma verarbeitet die von der KI vorgeschlagenen Metadatenfelder und präsentiert dem Katalogisierer die Vorschläge im Format von Datensatz-Entwürfen, um die Überprüfung und den Arbeitsablauf zu erleichtern. Wir arbeiten mit der Community zusammen, um die Nützlichkeit der verschiedenen Felder zu beurteilen und zu entscheiden.
Die KI kann auch unaufgefordert Felder erzeugen, die hilfreiche Informationen enthalten können. Da die KI Metadaten auf probabilistische Weise generiert, kann es vorkommen, dass sie auch irrelevante Felder wie lokale Felder, Systemnummern oder Datensatz-Herkünfte generiert, die keinen Datensatz repräsentieren (da kein Datensatz kopiert wird, werden nur bestimmte Metadaten generiert) - diese Felder enthalten wahrscheinlich irrelevante oder generische Daten, und bei der Verarbeitung der Ergebnisse entfernt Alma diese. -
F: Kann jeder in der Bibliothek den AI Metadata Assistant verwenden?
A: Die Bibliothek kontrolliert den Zugriff hierauf: Der Arbeitsablauf des AI Metadata Assistant ist in den Metadaten-Editor eingebettet – ich muss ein Katalogisierer sein, um Titelsätze erstellen oder bearbeiten zu können, und außerdem über die neue Rolle „AI Assisted Cataloging“ verfügen, um die neuen Arbeitsabläufe verwenden zu können. -
F: Kann ich entscheiden, in meiner Bibliothek keine KI-angereicherten Daten zu verwenden?
A: Natürlich! Die Bibliothek hat die volle Kontrolle über die Verwendung dieses Werkzeugs. Um mit dem KI-Metadaten-Assistenten zu arbeiten, sollte der allgemeine Administrator der Bibliothek diesen zunächst für die Institution auf der neuen Konfigurationsseite des KI-Nutzungsprofils aktivieren. -
F: Ich bin ein Netzwerkmitglied – kann KI verwendet werden, um Netzwerkdatensätze anzureichern?
A: Natürlich! Wenn das Netzwerk den AI Metadata Assistant aktiviert, können alle Mitglieder, die ihn auch in ihrer Institution aktivieren, ihn zur Verbesserung der Netzwerkdatensätze verwenden. -
F: In meinem Netzwerk ist die Bearbeitung einiger Felder untersagt. Kann die KI diese trotzdem erstellen?
A: Nein. Alle vom Netzwerk erzwungenen Beschränkungen gelten auch für den Arbeitsablauf des AI Metadata Assistant. Katalogisierer können ihn nur zum Erstellen oder Anreichern von Metadaten verwenden, die sie manuell erstellen oder anreichern können. -
F: Mit welchem LLM arbeiten Sie?
A: Modelle unterliegen Änderungen, da sich Modelle und Funktionen weiterentwickeln. Ab der Version vom Februar 2025 arbeitete der AI Metadaten-Assistent mit dem LLM-Modell gpt_4o_2024_08_06.