
Service Disruption Communication Policy 1.1
Version 1.1
Introduction
Ex Libris, a ProQuest company, proactively strives to ensure the service reliability, security, and data privacy of all data it holds in the Ex Libris cloud environment. Ex Libris must be able to detect, avoid, respond to, report, and learn from any service disruption. This policy defines a consistent way to handle, avoid and communicate any service disruption.
Purpose
The aim of this policy is to ensure that Ex Libris reacts appropriately to any actual or suspected events relating to Ex Libris cloud systems and data. This policy defines the steps that Ex Libris personnel must use to provide a process for documentation, appropriate reporting internally and externally, and communication so that organizational learning occurs. Finally, it establishes responsibility and accountability for all steps in the process of addressing events.
Reporting Methods of Service Disruption to Ex Libris
Ex Libris Network & Security Operations Center (NOC/SOC) provides 24x7 logging and monitoring for all logical network access to customer data and information asset usage and is audited. Ex Libris monitoring consists of multi-layered, fully redundant systems that monitor the services inside and outside the Data Center to validate that services are running at the highest performance levels.
If you are experiencing a service disruption issue, please inform Ex Libris by one of the following options:
Option 1: Open system down case
- Opening a customer support request with Priority equal to “System-Component Down”
See Ex Libris Support Portal User Guide
Note: Once a System-Component Down is reported, the Hub will respond within 1 hour. Typically, a response is sent within 15 minutes.
Option 2: send mail to the Hub 24x7
- Sending an email to 24x7Hub@exlibrisgroup.com, describing the problem.
Note: Once a System-Component Down is reported, the Hub will respond within 1 hour. Typically, a response is sent within 15 minutes
Option 3: Call the Hub
- Calling one of the Hub toll-free numbers.
See Ex Libris contact details for the 24x7 Hub - Call the Hub without a Toll-Free number at: +972-2-6499444

The Hub’s response to the case will differ based on the environment status.
- In case the Hub has no service disruption on the relevant environment, the case will be escalated to support and the Hub and an automated response will be sent to the customer.
- In case the Hub is aware of the service disruption for the relevant environment a response will be sent to the customer.
In this scenario, as soon as the disruption is over, the Hub is responsible for updating the SF case that the disruption is over, regardless of the Status Page’s ongoing updates.
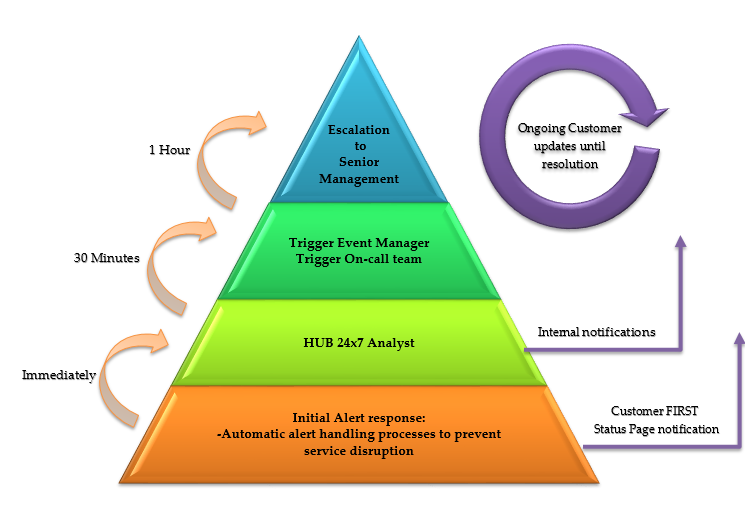
Event Management and On-Call Process
The Event Manager function is fulfilled by our Cloud Managers. All Cloud Managers participate in an on-call Event Manager duty rotation. Triggering the Event Manager is part of the Hub Service Disruption handling. We always have two Cloud Managers assigned to the Event Manager duty rotation, so that a secondary Event Manager is available as a redundancy and/or to help manage the rare cases of multiple simultaneous major service disruptions
Ex Libris implements end-to-end procedures and processes in order to proactively identify, avoid, respond and mitigate any service disruption by defining a use case scenario for each service that is monitored, with step-by-step actions to resolve that specific issue. For every domain (product or infrastructure) there are 24x7 On-call engineers available for escalation purposes.
The On call engineer is structured in a tier model-
- The Ex Libris Hub staff and automation tools function as a proactive system that for defined scenarios, will automatically trigger scripts and other processes to achieve issue resolution – thereby preventing service disruption where possible.
- The Hub analyst functions as Tier 1 technician that responds to service alerts triggered by the Ex Libris layered monitoring system and system down SF cases, resolving 98% of issues. In cases where escalation is needed, the Hub analyst will trigger Tier 2.
- The Cloud Operations and Product Support teams function as Tier 2 and are immediately triggered by Tier 1 once additional analysis is required.
- The Cloud Engineering and Development teams function as Tier 3 and are immediately triggered by Tier 2 if further analysis is required.
Event Manager Roles & Responsibilities
The Ex Libris Event Manager is responsible for leading an effective investigation, in order to return the service back to normal as soon as possible. Part of the Event Manager’s role is to handle internal and external communications, follow escalation procedures, and to add any on-call technical personnel as needed. The Event Manager’s primary directive is to ensure problem analysis is carried both thoroughly and expeditiously to determine the cause of the service disruption, and then proceeding towards a solution in order to return the service to normal as soon as possible.
Event Manager’s roles:
- Verify that the relevant technical personnel are participating in the event -Ex Libris has 24x7 duty rotations for expert infrastructure engineers, including Security, Network, DBA, Storage & Systems, as well as dedicated professional Application Developers. All applicable experts are triggered by the Hub as required in the event of a service disruption.
- Verify that the event is proceeding towards a solution -The primary responsibility of the Event Manager is to bring the service back to full functionality as soon as possible
- Handle External Communication (via Status Page) – Once every 30 minutes, or when a new update is relevant, a message will be posted to the Status Page.
- Handle Internal Updates (via email) – Once every hour, or when relevant, the Event Manager will update Ex Libris Management
- Internal Escalation –
If the event is not advancing towards a solution:- Within 30 minutes, the Event Manager will ask the Hub to trigger an alert to the Hub Manager or a Cloud Director.
- Within 60 minutes, the Event Manager will ask the Hub to trigger an alert to the relevant Development VP or a Cloud VP.
- Within 90 minutes, the Event Manager will ask the Hub to trigger an alert to the Ex Libris COO or President.
- Root Cause Analysis -Once service has resumed fully, we complete a Root Cause Analysis (RCA) process which is published according to our SLA.
- Continuous Improvement steps- Following the RCA, as part of our policy of continuous improvement, we perform an internal “Lessons Learned” process.
Service Disruption Process and Timeline
Ex Libris Status Page
The Ex Libris System Status Page displays the latest information on the availability of all multi-tenant Ex Libris instances. You can check this page at any time to see current status information or subscribe to be notified via email of interruptions to any individual service. If you are experiencing a real-time operational issue that is not indicated on this page, please inform Ex Libris by submitting a case via our Support Portal.
The System Status Page lists all instances for hosted customers on SaaS environments. This site displays live data along with historical data for the previous five days. Customers with single tenant hosted environments can also receive updates on a product at the data center level.
The status of every instance is displayed via a Performance Indicator. More detailed information and timely updates can be found by hovering over these indicators.
| Status | Description |
|---|---|
 Service is Operating Normally Service is Operating Normally |
Service for the instance is operating normally |
| Service for the instance is operating normally, with some specific information provided by Ex Libris | |
| Service for the instance is available, but users may experience performance issues | |
| Service for the instance is unavailable or disrupted | |
| Planned maintenance is taking place |
Scheduled Maintenance
Notifications of future scheduled maintenance is published in the Scheduled Maintenance column. Detailed information such as start and end times can be found by hovering over the maintenance dates.
Locating an Instance Name
To locate your hosted instance name on the Support Portal (Salesforce), simply log onto the Support Portal and select the desired account asset. If your environment is on the system status, your instance name will be displayed under the Instance Name on the Status Page.
While you can register to the System Status Page notifications directly, we strongly encourage you to subscribe to the Email Preferences mailing lists, where you will receive updates from Support and the Cloud, and will also automatically be registered to the System Status notifications for your environment.
Cloud Status Notification Subscription
Email notifications regarding performance updates and upcoming maintenance of a hosted instance are sent to the instance’s subscribers.
In the Support Portal, you can set your “Email Preferences”. Setting your email preference for the product will automatically subscribe you to the correct environment in the System Status Page.
If you want to receive email notifications from the Status Page only, click the letter icon next to the desired instance and enter a valid email address. An email is sent to activate the subscription. (If you do not receive the email, check your spam box.)
Scheduled Downtime - Customers are notified about any downtime at least seven (7) days in advance, or during a standard maintenance window, as published by Ex Libris. In either of the foregoing two situations, Ex Libris will use commercially reasonable efforts to ensure that the Scheduled Downtime falls between the hours of Saturday [22:00/10PM] and Sunday [06:00/6AM] [US Central/Central European/Singapore] time, based on the data center region.
Ex Libris makes best efforts to ensure that no service is affected during maintenance activities unless absolutely required. If there is a service affecting activity, it will be performed during what we call an optimal MW [Sun 00:00 – 04:00] [US Central/Central European/Singapore] time.
Notifications of future scheduled maintenance are published in the Scheduled Maintenance column. Detailed information such as start and end times can be found by hovering over the maintenance dates.
In addition, an email at the beginning and end of the activity is sent to all customers that subscribed to the Salesforce broadcast.
Service disrupting activities that are carried out are:
- New releases and Service Packs
- 3rd party upgrades
- Infrastructure upgrades
- Activities required to maintain our Cloud environments
Note: All SaaS environment scheduled activity is communicated via the Ex Libris Status Page.
Planned activities - In order to prevent an unauthorized change in our Cloud environments, and to maintain the highest level of service to our customers, Ex Libris has implemented change management procedures so that all activities must be documented, scheduled, approved and recorded. Every change in our Cloud production servers must follow the following procedure:
- Planning stage – document, test procedure
- Approved cycle of the procedure, at least 4 eyes approval principle
- Coordination and notifications
- Execution during maintenance window
- Documentation
Hub 24x7 NOC/SOC and Cloud teams continuously monitor and audit such processes.
RCA
Root Cause Analysis (RCA) - Ex Libris performs internal root cause analyses for any service interruptions and takes the necessary steps to avoid them in the future.
- Ex Libris implements proactive and reactive problem management based on ITIL in order to minimize both the number and severity of incidents and potential problems
- For SaaS multi-tenant environments, Ex Libris publishes RCAs in the Customer Knowledge Center.
- For non-SaaS environments, RCA will be published via Salesforce in the relevant asset, per customer request.
- The RCA report will be published in the Knowledge Center within 5 business days.
- If the Root Cause is not found within 5 business days, RCA will report that the disruption is still under ongoing analysis, and that the final RCA will be published within 14 days.
- Notification on RCA is done via Status Page mailing to SaaS customers
Uptime Report Availability
For SaaS multitenant environments, Ex Libris publishes a quarterly availability report that measures and records system uptime.
These reports provide a comprehensive view of our uptime performance as measured over the last three months and over the last twelve months. This report is publicly available in the Customer Knowledge Center.
See our Uptime report example
Security and Privacy Incident Response
As part of the Ex Libris security and privacy incident response policy, we commit to take prompt action to investigate the incident, mitigate any harm stemming from the incident, and take action intended to prevent any similar incidents from occurring, including, without limitation, the installation of appropriate patches or software fixes as soon as reasonably practical.
See Ex Libris security and privacy incident response policy.
Ex Libris Cloud BCP
The Ex Libris cloud infrastructure is designed to be resilient even in cases of disruption.
The Ex Libris cloud infrastructure complies with the fundamental guidelines of business continuity: full redundancy, load balancing and failover. Each component in the system utilizes high-availability capabilities, including storage, servers, databases, network routers, redundant firewalls, and the utilization of multiple internet service providers to maintain network access to the data center.
This high-availability architecture protects services from failure of one or more components and offers a high level of resiliency and business continuity. Due to this architecture, Ex Libris achieved ISO 22301 certification, a comprehensive standard that reflects our commitment to business continuity and disaster preparedness.
Compliance
Violations of this policy will be reported to the Ex Libris Cloud senior management and may result in disciplinary action.
Policy Review and Update
This policy and its supporting procedures, will be reviewed at least annually, and updated as required.
Record of Changes
| Type of Information | Document Data |
|---|---|
|
Document Title: |
Service Disruption communication policy |
|
Document Owner: |
Tomer Shemesh – Ex Libris Chief Information Security Officer (CISO) Nirit Hirsch – Hub Manager |
|
Approved by: |
Barak Rozenblat – Ex Libris Cloud Services VP |
|
Issued: |
May 8 ,2018 |
|
Reviewed & Revised: |
May 29 ,2018 |
Revision Control
| Version Number | Nature of Change | Date Approved |
|---|---|---|
| 1.0 | Initial Version |
May 8 ,2018 |
| 1.1 |
Accuracy updates |
May 29 ,2018 |
Document Distribution and Review
The document owner will distribute this document to all approvers when it is first created and as changes or updates are made. This document will be reviewed and updated annually or upon written request by an approver or stakeholder. Questions or feedback about this document can be directed to the owner or a listed approver