
Match and Merge in CDI
Introduction
Content in the Central Discovery Index (CDI) comes from a variety of sources, including publishers, content aggregators, open access repositories, institutional repositories, and more. In total we ingest content from over 2,000 sources, and as such, we sometimes have more than one record for a given citation. Displaying all of these records separately can confuse users and make it harder for the user to find what they are looking for in the results.
However, we also strive to present the user with the highest quality, most detailed, most extensive metadata available, as clearly as possible, while also providing the user with the best available method to access the content in question. In order to leverage as much of the available metadata as possible for this purpose, while also minimizing duplication and ambiguity, we employ a process we call Match & Merge.
Match & Merge is essentially a set of criteria that controls which records ("physical records") can and cannot be combined into composite records that we call "logical records". In these logical records, the available metadata from the participating physical records is synthesized such that a single record can be presented to the end user that is more complete and robust than any of the individual physical records. Below is a picture showing an abstract representation of this process.

Match & Merge: Rules
Match & Merge generally relies on various kinds of identifiers: if two or more records share the same identifier, they can be merged, provided that they also satisfy other criteria, depending on the identifier. Most content types are eligible for Match & Merge, although some are excluded in certain cases and some are excluded altogether (see Match & Merge Filters).
Please note that a "fuzzy title match" is a comparison of two records' combined DocumentTitle and DocumentSubtitle fields, disregarding case, whitespace, punctuation, diacritics, and other special characters.
External Identifiers:
- DOI – also requires fuzzy title match; does not apply to Journal & eJournal
- PMID – also requires fuzzy title match; does not apply to Journal & eJournal
- ISBN/EISBN – also requires fuzzy title match; years of publication must be within one year of each other
- ISSN/EISSN – PublicationPlace or publication year must also match; applies to Journal & eJournal only
- LCCN – for Journal/eJournal, PublicationPlace or publication year must also match; for Book, eBook, Dissertation, and Government Document, fuzzy title match required, and year of publication must also match
- OCLC – same additional criteria as for LCCN
Internal identifiers:
Records with an ISSN, EISSN, ISBN, or EISBN are assigned an identifier, internal to Ex Libris, that corresponds to the relevant title. Match & Merge is done using this identifier in different circumstances, and the process works differently for title- and publication-level records.
- Publication level: Applies to Newspaper, Magazine, Journal, eJournal, Book, and eBook. Only requires the title-level identifiers to match.
- Article level: Applies to Journal Article, Magazine Article, Newspaper Article, Trade Publication Article, Book Review, and Conference Proceeding. In addition to the title-level identifier, the DocumentTitle, year of publication, Volume, Issue, and StartPage are all required to match.
Other scenarios:
- Reference records can merge based only on a fuzzy title match
- Dissertation records can merged based only on a URI (direct link) match
Match & Merge Filters
Filters are essentially the inverse of rules: they dictate under which circumstances records cannot be merged. Note that filters supersede rules in cases where both can potentially be applied.
Mismatched metadata: if any of the following data points are mismatched, the records are prevented from merging.
- DOI
- PMID
- URI (if records come from the same set of content, from the same content provider)
- Language
Excluded Content Types:
- Archival Material
- Image
- Microform
- Music Recording
- Patent
- Report
- Technical Report
- Standard
- Video Recording
Other filters:
- Records identified as being from an Institutional Repository will never be merged
- Records having the content type Newspaper Article and a date of publication prior to January 1, 2000, will never be merged
- Record exclusion flag: we can flag specific records to be excluded from Match & Merge; this is typically done at the express request of the content provider or uploading client
- Note: the following content providers have asked that this record exclusion flag be applied to all their records:
-
Artstor
-
CABI Direct content
-
CAIRN International Journals
-
- Note: the following content providers have asked that this record exclusion flag be applied to all their records:
-
"Bad Titles": we maintain an internal list of especially short and generic titles that we don't want to merge at all because of the high probability of false positives
-
Overmatch: any record having a title that occurs on more than 4,000 records in the index will not be merged. Stop words are ignored when matching titles to the overmatch list. For example, records with a title of “In the blood” will not merge because “Blood” is in the overmatch list.
Transitive Merge
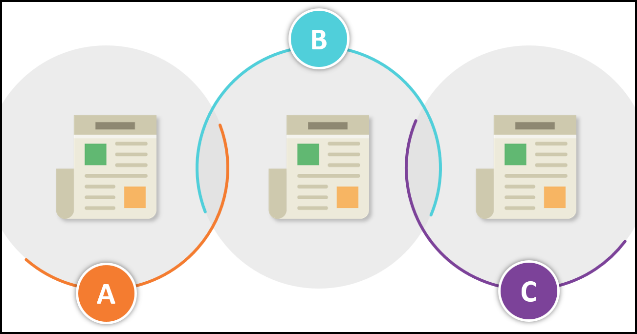
A "transitive merge" is a scenario where three or more records are merged, where at least two of the records would not be able to merge on their own. For example, in the diagram below, Record A can merge with Record B, and Record B can merge with Record C, but Record A would not ordinarily be able to merge with Record C. But because of the commonalities that both Records A and C share with Record B, all three records can be merged into the same logical record.
Match & Merge: How it affects users' search experience with CDI
Match & Merge improves CDI's search capabilities in various ways.
Better Discoverability
The use of logical records created by Match & Merge improves the discoverability of items compared to searching for physical records individually. This is because the logical records inherit all field values of their participating records. For example, if there are variations of certain field values, such as titles and author names, among the participating physical records, they are all included in the logical records. Similarly, if only some participating physical records provide full text, references, identifiers, or other metadata, they are all included in the logical records regardless of the library's source activation status and are all used for discovery.
Improved Search Efficiency
The use of logical records also improves the search efficiency. This is first of all because the number of logical records is far fewer than the number of participant records, and secondly because there is no need to group together records for the same item at search time. As a result, search response times are generally faster, and the search system can handle larger search load. For a large index such as CDI that is constantly increasing in size, such measures are essential to provide a fast and consistent search experience.
Fast Updates
Since Match & Merge happens every time CDI's main index is updated, improvements to physical records are quickly reflected in the logical records. This improves the discoverability of all physical records associated with the updated logical records. This makes CDI a very dynamic index.
Facets
Faceted searches (filtering the search results by facets) use logical records. For example, when a user clicks on “articles” in the content type facet CDI filters the search results based on the logical records' content types. The facet counts (for example, the counts associated with facet values) are calculated based on the values in the logical records.
Record Display
The brief display fields (such as the title, authors, and snippets) displayed in the search results and the metadata fields displayed in the detailed view are based on the CDI records to which the library has access rights. They are either:
-
Records affiliated with the Community Zone collections indexed directly in CDI (where provider coverage is 'yes') that the library has activated.
-
Records in CDI that are freely available for searching, as alternative coverage for either:
-
Active Institution Zone collections.
-
Community Zone collections activated by the library where provider coverage is No.
-
Logical records' field values from the participating records to which the library does not have access rights are not be displayed. In addition, CDI applies a logic to select the most suitable field values for display among all field values from the displayable participant records. We distinguish between single source fields and multiple source fields. Single source fields are those that can contain only one unique value (such as the title, enumeration, date, and DOI) and fields that can have several values (such as the Author). For fields that have several values, all are taken from the same source to ensure consistency.
For fields with unique values, for example the title, CDI will return the value of the participant from the source type with the highest priority, preferring the primary publisher data over aggregations. Open Access and Institutional repositories and other non-specific sources have the least priority. If there are several different values from participant with the same source type (e.g. every participant has a slightly different version of the same title), CDI will choose the one that has the most occurrences. For fields that can have several values, CDI again chooses by type of source. Multiple source fields, such as the subject field, ISBN and ISSN, return all available (de-duplicated) values from all participants to which the library has access rights.
By using such logic, the process tries to show the best possible metadata, taking the customer’s rights into account. However, as a result, some matching search terms and phrases may not appear in the detailed view of the record because the match occurred within one of the participant records while the logical record may have shown slightly different metadata. This can, for example, lead to a subject heading not appearing because it comes from a participant for which you do not have rights. It is still searchable and can be found in the record. Also, please note that a search for a specific document ID returns only metadata from this one participant record. You may see a discrepancy in some metadata fields and possibly the link in a record, depending on whether you found it by searching for the document ID or keywords/phrases.
Match & Merge FAQ
-
Do my local records participate in match and merge?
Local records in the local Primo indexes will not match and merge with records from CDI. Records uploaded to CDI by clients are eligible for merging, however.
-
Does match and merge give preference to certain providers?
No. Match and merge is vendor-neutral.
-
Will identical values from a specific field coming from the various physical records comprising the logical records be merged (deduped) for display, search, and so forth?
Yes. For example, identical subject headings will be deduped so that you see only one instance of the heading, not multiple instances.
-
Can records with different Content Types merge?
Yes, subject to some restrictions: records that meet the criteria of at least one of the rules, and are not blocked by any of the filters, can merge. Some rules apply only to certain content types, other rules apply to all content types except for special exclusions; please see the Match & Merge: rules and Match & Merge: filters sections above for more specifics.
-
How can I submit suggestions for improvement to the match and merge process?
Please submit your ideas about changes to rules, new rules, or other general changes to the Idea Exchange. If you would like to report a specific problem with a record not merging correctly, please open a Support case.
-
Why don't my search terms or phrases appear in a returned record?
If the detailed view of a record in the search results does not show matching search terms or phrases, there are a few possibilities:
-
They matched in a metadata field in the logical records created by Match & Merge, but the matched values were not included in the displayed fields, which were taken from the participating physical records that the library has access rights to. For more details, see Match and Merge: How it affects users' search experience with CDI.
-
They matched in the full text field, but no snippet was created from the full text. Snippets from full text are taken from the first 1,000 characters of the full text, so if the search terms or phrases do not appear at the beginning of the full text, snippets are not generated. In addition, snippet creation from full text for some sources is suppressed due to contractual agreements with the content providers. Such matches can also apply to entire titles, if the title is part of the reference list of a record and that reference list is indexed. Such matches appear far lower in the result list than for example a title or subject heading match (see also field weighting).
-
-
Why doesn't the facet value I used for filtering appear in a returned record?
Like the regular searching, facet filtering uses logical records created by Match & Merge. The field value used for facet filtering may not appear in the detailed record display, as the record display is based on the physical records that the library has access rights to (for example, from the sources which the library has activated). For more details, see Match and Merge: How it affects users' search experience with CDI.
-
Why does a particular journal still appear in my search results after excluding it with the journal title facet?
Facet filtering uses logical records created by Match & Merge. Since we allow records with different resource types to merge, there are logical records in CDI with multiple resource types. For the Journal title facet, we limit the values to publication titles for records included in the search result with one of the following resource types: Journal, Journal article, Magazine, Magazine article, Newspaper, or Newspaper article. In case there are logical records in the results set for the journal excluded via the facet that has content types not included in this list, you may still see these journals appearing.