
Working with Normalization Rules
- Catalog Administrator
- Catalog Manager
- Cataloger
- To apply normalization rules to an individual record, use the Enhance Record option (refer to the section MD Editor Menu and Toolbar Options) or Apply Changes to an individual record when you preview normalization rules (see To preview the outcome of a rule).
- To apply normalization rules to a set of records, you need to create a process using the MarcDroolNormalization, MarcXSLNormalization or DcDroolNormalization tasks (see Working with Normalization Processes) and specify the normalization rule created with the MD Editor (refer to the procedure To create a new normalization rule file). Once you have created the process, you can run a job using that process (see Running Manual Jobs on Defined Sets). In addition, you can create a process that enables application of normalization rules when selecting Save in the MD Editor (see Working with Normalization Processes).
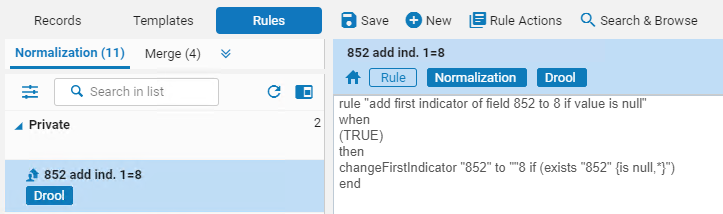
- View the normalization rules and metadata records side by side
- Preview the outcome of a rule when run on a metadata record
- Toggle between the rule and the preview changes
- Edit rules and test immediately
- For a short overview of Normalization Rules, watch Normalization Rules (6:00).
- For detailed information on Normalization rules with examples, watch Normalization Rules (1 hr).
Creating Normalization Rules
- On the MD Editor page (Resources > Cataloging > Open Metadata Editor), open the Rules area.
- To create a normalization rule for a MARC or Dublin Core record, select New > Normalization. The Normalization Rules Properties (New Rule) dialog box opens.
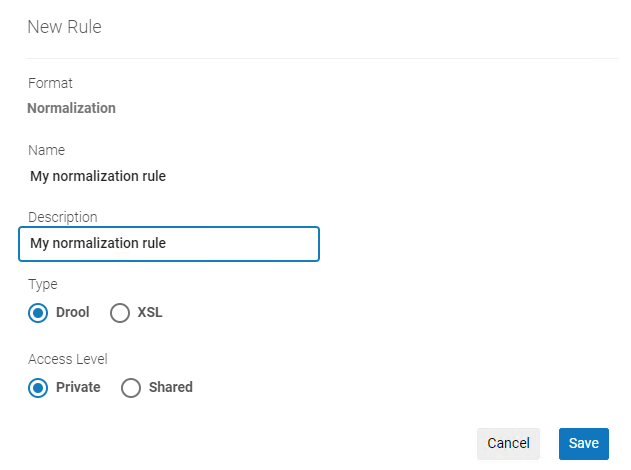 Normalization Rules Properties Dialog Box
Normalization Rules Properties Dialog Box - Enter a name and a description for the normalization rule.
- The word rule must not be capitalized if used in the rule name. If capitalized, the rule does not work.
- Do not use a backslash (\) in the rule name! Otherwise, the rule cannot be used for the filter set functionality.
- The character limit for rule names/descriptions is 255 characters.
- To create a normalization rule for a MARC record, select Drool. To create a normalization rule for a DC (Dublin Core) record, select XSL.
MARC record normalization rules also support XSL.
- Select an access option, Private or Shared. If you select Private, only you can work on the rule, and the rule cannot be included in a normalization process. If you select Shared, your rule is shared among catalogers. In this case, more than one user can view the rule at the same time; if two or more people have the rule open for editing, a warning message appears when one of you tries to save changes. (You have the option of keeping your changes or allowing the other user to make and save changes.)
- Select Save. The Metadata Editor editing pane opens.
You can include existing rule syntax (Edit > Add Rule > {type of rule}) or define a rule (for details, see Normalization Rules Syntax). - Select Save. The rule is added to the list of rule files under the Normalization Rules tab.
- On the Metadata Editor page (Resources > Cataloging > Open Metadata Editor), select the Rules tab and expand the Normalization folder.
- To copy, open the Community folder, right-click the rule you want to copy and select Duplicate. The Duplicate Rule dialog opens. Enter your name and description and indicate whether you want to save as a private (available only to you) or a shared rule (available to all users in your institution).
The dialog box indicates the Alma user name and contact email of the user who contributed the rule to the Community Zone. If you have any questions, you can contact this user. - To contribute your own rule to the Community Zone, right-click the rule and select Contribute to CZ.
The Rule Sharing dialog opens. Provide a descriptive name and description, and select Save to save the rule in the Community Zone.
- On the Metadata Editor page (Resources > Cataloging > Open Metadata Editor), select the Rules tab and expand the Normalization folder to display the saved rules.
- Select the rule with which you want to work and select one of the following options:
- Edit – Opens the text box with the rule(s) syntax, enabling you to modify this syntax (for details, see Normalization Rules Syntax).
- Delete – Select Yes to confirm the rule file’s deletion.
- Duplicate – Duplicates the selected rule file, enabling you to modify and save it as a new rule without affecting the original file.
- Properties – Opens the Normalization Rules Properties dialog box, enabling you to modify the properties of the rule file.
- To rename the rule, duplicate the rule, give the duplicate the desired name, and then delete the old rule.
- Locate the bibliographic record with which you want to work (using the Repository Search or within the MD Editor > Records tab) and open it in the Metadata Editor.
- Press F6 or select the Split Editor icon.
- Select the Rules tab in the left pane and expand the Normalization folder.
- Right-select the rule that you want to preview or test in the Private or Shared (not the Community) folder and select Edit.
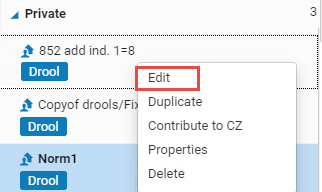
The rule is displayed in the Metadata Editor right pane.
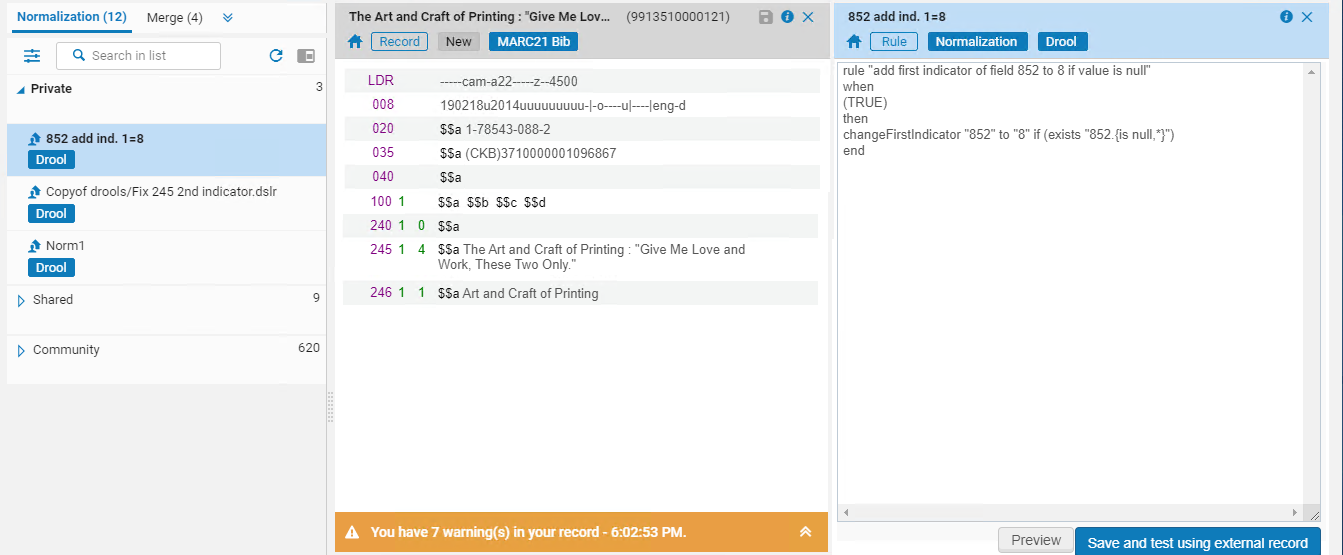
- Select Preview. The rule is applied to the record, and the outcome appears.
To update Network records, the normalization must be run by the Network institution (not by a member). An institution cannot update Network records; therefore, the normalization is only applied to local fields (the local extensions of the member). When previewing a rule for a Network record, the following message is displayed: Note that the rules are applied only to local fields when the normalization process is run.
- Select Apply Changes to save the modifications to the record or select Back to normalization rules to continue editing.
- When you have made your final changes to the normalization rule, select Save and test using external record to save the final version of your normalization rule. For details, see Testing Normalization Rules for External Data Sources.
Normalization Rules for Dublin Core and MODS Records
In the Metadata Editor, there are the following types of rules related to Dublin Core and MODS:
- XSL indication rules
- XSL normalization rule
XSL Normalization Rule does not support discovery:local.
Dublin Core and MODS normalization rules cannot be written in a regular Normalization Rule format, but only as an XSL. This means that you compose the XSL directly in the Metadata Editor (as explained above), or you can compose it in Notepad (or another external application of your choice) and then copy it to the Metadata Editor.
You can view the below examples of XSL Normalization Rules for Dublin Core in the Community Zone in the Metadata Editor:
- EXL – Change dc:language value en to English
- EXL – Generic rule to replace string in Dublin Core record
- EXL_Add_field_accessRights
- Write the XSL in an external application of your choice.
- Open the Metadata Editor > Rules section.
- Copy and paste the XSL to the Metadata Editor and save the rule.
Normalization Rules for Primo VE and Esploro
In addition to Alma normalization rules, you can create normalization rules for Primo VE and Esploro. To create these rules, select New, and then select:
-
Normalization (Discovery) – This option appears only when Primo VE is defined in the system. Select this option if you are creating DC or XML normalization rules for bibliographic records that are loaded into Primo VE and not managed in Alma. For information regarding the syntax of these rules, see Normalization Rule Syntax for DC and XML Formats.
-
Normalization (Research) – This option appears only when Esploro is defined in the system. For details, see Managing Asset Normalization Rules (Esploro).
Normalization Rule Syntax
(<conditions on MARC record>) then
Action
End
- “When” must be the only word in the first line. The condition must be placed on a separate line.
- You can use multiple conditions on the whole record in the “When” condition only.
- While it is permissible to include multiple Boolean Operators in the rules, when a large number of Boolean operators are selected, slower performance is likely to result. Thus each rule should include no more than 200 Boolean operators.
- If not specified, the condition will work on the record level. If you want the condition to work on each MARC21 field separately, the condition should be specified per field. For example, when there are multiple MARC21 fields with the same tag.
Understanding Escape Characters in Normalization Rules
When writing normalization rules, you may need to include special characters such as quotation marks, tabs, or backslashes. To do this correctly, you use escape characters, which are special combinations that tell the system how to interpret these symbols.
Valid Escape Sequences
- \b - backspace
- \t - tab
- \n - new line
- \f - form feed
- \r - carriage return
- \" - double quote
- \' - single quote
- \\ - backslash
Common Mistakes to Avoid
Using an incorrect number of backslashes can cause errors. For example:
- \z or \\\z are not valid and will trigger an error.
- A lone backslash (\) without a valid escape character is also invalid.
How to Fix Errors
If you see an error like:
"Invalid escape sequence (valid ones are \b \t \n \f \r "'\)"
You can fix it by adjusting the backslashes. Here are some examples:
- replacing \\\ with \\
- replacing \. with .
- replacing \( with ( and \) with )
- replacing \\\| with \\|
These changes preserve the intended behaviour of your rule while avoiding syntax errors.
Record Elements
| Expression | Meaning |
|---|---|
| "<tag>", "<new tag>" | Represents a field tag, for example, 001, 245, etc. |
| "<oldCode>", "<newCode>" | Represents a subfield code, for example, a, b, c. |
| "<element>" for a data field | The following are the possible values for the data field:
|
| "<element>" for a control field | The following are the possible values for a control field:
|
| "<element>" for a fixed position field |
The following are the possible values for a fixed position UNIMARC/CNMARC 1XX field:
Relevant only for UNIMARC/CNMARC 1XX fields. |
| CONDITION at record level | The following are the possible condition options. See the next section (Conditions) for important information.
The following are the possible condition options relevant only for UNIMARC/CNMARC 1XX fields:
|
Conditions
- WHEN clause – A condition that must be met by the entire record in order to determine whether the rule is applied to the record
- IF (within an action) – A condition that applies to a single field in order to determine whether the specific action is taken on that field
-
containsScript – Use this condition to detect a specific language. The containsScript condition uses the following fixed list of languages for which you can check: Arabic, Armenian, Bengali, Bopomofo, Braille, Buhid, Canadian_Aboriginal, Cherokee, Cyrillic, Devanagari, Ethiopic, Georgian, Greek, Gujarati, Gurmukhi, Han, Hangul, Hanunoo, Hebrew, Hiragana, Inherited, Kannada, Katakana, Khmer, Lao, Latin, Limbu, Malayalam, Mongolian, Myanmar, Ogham, Oriya, Runic, Sinhala, Syriac, Tagalog, Tagbanwa, TaiLe, Tamil, Telugu, Thaana, Thai, Tibetan, and Yi. See the following syntax example:rule "Is CJK in Authority"
when
containsScript "Han" "1**"
then
set indication."true"
end - exists <element> – At least one match is found
- exists <element> – Applies to data fields. When used in an IF clause, both the action element and the element tested by the condition must be the same (data) field.
- existsControl <element> – Applies to control fields. When used in an IF clause, both the action element and the element tested by the condition must be the same (control) field.
- existsMoreThanOnce <element> – Multiple matches are found. Applies to data fields. When used in an IF clause, both the action element and the element tested by the condition must be the same (data) field.
- not exists <element> – No match is found
- not exists <element> – Applies to data fields. When used in an IF clause, both the action element and the element tested by the condition must be the same (data) field.
- not existsControl <element> – Applies to control fields. When used in an IF clause, both the action element and the element tested by the condition must be the same (control) field.
-
recordHasDuplicateSubfields (for indication rules; see Working with Indication Rules) – Returns true if duplicate subfields (subfield and its contents) are found for the current record according to the fields, subfields, and the characters to ignore (charsToIgnore) string that were passed as parameters in the following format:recordHasDuplicateSubfields "<tag>" "<code>" "<charsToIgnore>"Multiple tags (fields) separated by commas can be specified. Multiple codes (subfields) can be specified with no spaces to separate them. One or more characters (alphanumeric or punctuation) with no spaces to separate them can be specified as characters to ignore at the end of the content in the subfields that are being evaluated for duplication. See Example 6 for more information.For the records that meet the recordHasDuplicateSubfields condition (returns true), a set of the records is created.
- Applies if a specific condition is not true, for example: addControlField "{element}" if(not exists "{condition}")
- Applies if a specific condition is true, for example: addControlField "{element}" if(exists "{condition}")
- Applies unconditionally, for example: addControlField "{element}"
The if (exists...) condition is met if the value in the condition appears somewhere in the record. It is not possible to copy/remove a subfield with a specific value using this rule. To remove or copy a subfield with a specific value, use the XSL transformation rules.
List of Actions
| Action | Format / Example | Comment |
|---|---|---|
| Replace fields and subfields with other fields and subfields | changeControlField "<tag>" to "<new tag>"
Example: changeControlField "007" to "008"
|
Changes the tag identifier of a control field; does not modify contents. |
| changeField "<tag>" to "<new tag>"
Example: changeField "245" to "246"
|
Changes the tag identifier; does not modify indicators or subfields. | |
| changeSubField "<tag>.<code>" to "<new code>"
changeSubFieldOnlyFirst "<tag>.<code>" to "<new code>"
changeSubFieldExceptFirst "<tag>.<code>" to "<new code>"
Example: changeSubField "035.b" to "a"
|
Changes the subfields (or only the first subfield, or all except the first subfield) "<code>" to the subfield "<new code>" in field "<tag>". | |
| changeFirstIndicator "<tag>" to "<value>"
changeSecondIndicator "<tag>" to "<value>"
Example: changeFirstIndicator "245" to "3"
|
Sets the value of the specified indicator in tag <tag>. | |
| combineFields "<tag>" excluding "<comma-separated subfield list>"
Example: combineFields "852" excluding "a,b"
|
Combine all fields of the specified number. Copy all subfields from the second and subsequent lines to the first line, excluding the named subfields; only the first occurrences of excluded subfields are copied, and only if they do not already exist in the first line. | |
| Add fields and subfields | addField "<tag>.<code>.<value>"
addField "<tag>.{<ind1>,<ind2>}.<code>. <value>"
Example: addField "999.a.RESTRICTED"
|
Adds the field to the MARC record. Sets the value of the subfield to the indicated value. |
| addControlField "<tag>.<value>"
Example: addControlField "008.820305s1991####nyu###########001#0#eng##"
|
Adds the control field to the MARC record. | |
| addSubField "<tag>.<code>.<value>"
addSubField "<tag>.{<ind1>,<ind2>}.<code>.<value>"
Example: addSubField "245.h.[Journal]"
|
Adds the subfield <code> with value <value> to field <tag>. If the field does not exist, nothing is done. | |
| addSystemNumber "<element>" from "<tag>" prefixed by "<prefix tag>"
Example: addSystemNumber "035.a" from "001" prefixed by "003"
|
Makes the data field <element> equal to the contents of the second control field <prefix tag> in parentheses followed by the contents of the first control field <tag>.
For example, if 001 has the value 9945110100121 and 003 has the value DAV, the example condition on the left will produce 035 with the value ‡(DAV)9945110100121.
|
|
| Copy fields | copyField "<tag>" to "<new tag>"
copyField "<tag>.<code>" to "<new tag>.<new code>"
copyField "<tag>" to "<new tag>.{<ind1>,<ind2>}"
Example: copyField "971.a" to "100.u"
|
Copies the field to another field. In the first version, the subfields are not specified (<code> and <new code>), and the new field contains all the same subfields as the old field. In the second version, if just <new code> is not specified, the new subfield is the same as the one specified by <code>.
copyField creates a separate field rather than adding it to any existing field. You may want to combine the new field with any existing fields (see combineFields).
|
| Remove fields and subfields | removeControlField "<tag>"
Example: removeControlField "009"
|
Removes all occurrences of the control field.
Note that if you remove control field 008, Alma immediately recreates it if you don't. Consider re-adding the field after removing it, for example: rule "remove 008"
when (TRUE) then removeControlField "008" addControlField "008.######s2013####xx######r#####000#0#eng#d" end |
| removeField "<tag>"
Example: removeField "880"
|
Removes all occurrences of the field <tag>. | |
| removeSubField "<tag>.<code>"
Example: removeSubField "245.h"
|
Removes all occurrences of the subfield <code> from the indicated field. | |
| Replace text in fields or subfields | replaceControlContents "<tag>.{<position>,<length>}. <value>" with "<new value>" Example: replaceControlContents "LDR.{7,1}.s" with "m"
|
Replaces <value> with "<new value>" in starting position <position> to <position>+<length> of control field <tag>. Replaces only the text that matches <value>. |
| replaceContents "<tag>.<code>.<value>" with "<new value>"
replaceContentsOnlyFirst "<tag>.<code>.<value>" with "<new value>"
replaceContentsExceptFirst "<tag>.<code>.<value>" with "<new value>"
Example: replaceContents "245.h.[Journal]" with "[Book]"
|
Replaces the matching strings (or every instance of the matching string in the first matching subfield, or all matching strings in all matching subfields except the first matching subfield) <value> in the subfield <code> of field "<tag>" with "<new value>". The string or part of the string that does not match <value> is not modified. | |
| replaceSubFieldContents "<tag>.<code>" with "<tag>.<code>"
Example: replaceSubFieldContents "245.b" with "100.a"
|
Replaces the subfield's contents with the contents of another subfield. | |
|
replaceFixedContents "<tag>.{<1_ind>,<2_ind>}.<code>.{<position>,<length>}.<value>" with "<new value>" Example: replaceFixedContents "100.{1,2}.a.{0,8}.20150226" with "20220724" |
Replaces <value> with <new value> in UNIMARC and CNMARC 1XX fixed position fields. Relevant only for UNIMARC/CNMARC 1XX fields. |
|
| Add text in subfields
|
prefix "<tag>.<code>" with "<value>"
Example: prefix "035.b" with "(OCoLC)"
|
Adds a prefix to the value of subfield "<code>" in the field "<tag>".
The new value will be <value> followed by the old value.
|
| prefixSubField "<tag>.<code>" with "<source tag>.<source code>"
Example: prefixSubField "910.a" with "906.a"
|
Adds the value of the subfield "<source code>" in the field "<source tag>" as a prefix to the subfield "<code>" in the field "<tag>".
The new value will be the value of the subfield "<source code>" in the field "<source tag>" followed by the old value.
|
|
| suffix "<tag>.<code>" with "<value>"
Example: suffix "035.b" with "(OCoLC)"
|
Adds a suffix to the value of subfield "<code>" in the field "<tag>".
The new value will be the old value followed by <value>.
|
|
| suffixSubField "<tag>.<code>" with "<source tag>.<source code>"
Example: suffixSubField "910.a" with "907.c"
|
Adds the value of the subfield "<source code>" in the field "<source tag>" as a suffix to the subfield "<code>" in the field "<tag>".
The new value will be the old value followed by the value of the subfield "<source code>" in the field "<source tag>".
|
|
| Maintain agency information in bibliographic and authority records
For example, this syntax can be used in normalization rules that are selected in the MARC 21 Bibliographic Metadata Configuration Task List to normalize Network Zone bibliographic records upon save.
This functionality is under construction. To enable this syntax, contact Ex Libris Support.
|
addCreatingAgency "<tag>.<code>"
Example: addCreatingAgency "040.a"
|
Adds the creating agency ISIL code to the subfield in "<code>" in the field "<tag>". |
| addModifyingAgency "<tag>.<code>"
Example: addModifyingAgency "040.d"
|
Adds the modifying agency ISIL code to the subfield in "<code>" in the field "<tag>". If there already is a modifying agency in the "<tag>.<code>", this adds another agency ISIL code. | |
| replaceModifyingAgency "<tag>.<code>"
Example: replaceModifyingAgency "040.d"
|
Adds the modifying agency ISIL code to the subfield in "<code>" in the field "<tag>". If any modifying agencies already exist in the "<tag>.<code>", all of them are replaced. | |
| Split subfields | splitSubField "<tag>.{ind1,ind2}.<code>.<delimiter>" to "<tag>.{<ind1>,<ind2>}.<code>" addSeq "<code>"
Example 1: splitSubField "866.a.;" to "555.{0,0}.a" addSeq "8"
Example 2: splitSubField "555.a. – " to "859.{0,0}.a" addSeq "8"
Example 3: splitSubField "859.a.\\\\."
Example 4: splitSubField "999.a.;" to "555.a" addSeq "8"
|
The tag is mandatory.
The indicators are optional.
Since the split is at the subfield level, the code is mandatory.
The delimiter can be any string. If the delimiter does not exist, the full subfield is copied as the first (and only) occurrence, and the sequence is added.
The to component is optional. If it is specified, multiple occurrences of the to tag.code are created, each with the data until the delimiter. See examples 1 and 2. If the to component is not specified, the subfield is split to the additional same subfields in the same field as shown in example 3.
The addSeq component is optional. It is not relevant if the to component is not specified. When addSeq is specified, the subfield with a sequence will be added as in Example 1; and if the subfield already exists in the original field, a sequence (preceded by a period) is added to that field as in Example 2.
|
|
correctDuplicateSubfields "<tag>" "<code>" Example: Removes duplicate subfields x, y and z from fields 610 and 630. |
Corrects duplicate subfields (for instance, subfields with the same code AND the same value) by keeping the first occurrence and removing the others from the current record according to the fields and subfields that were passed as parameters. You may want to use recordHasDuplicateSubfields to create the set that you supply to your normalization rule that uses correctDuplicateSubfields. See Example 6 for more information. For deduplication of subfields with different values, see: |
|
|
moveSubfieldsToEndOfField "<tag>" "<code>" Example: Moves subfields 9 and 2 to the end of field 650. |
Moves the first occurrence of each subfield to the end of the field and removes all other occurrences of the same subfield. If more than one subfield is specified, they are placed at the end in the same sequence as identified in the rule. In this example, subfield 9 is placed at the end followed by subfield 2. Note that the if statement is not supported with the moveSubfieldsToEndOfField action. |
|
|
Correct duplicate fields for the current record |
correctDuplicateFields "{fields}" Example: correctDuplicateFields "610,630,650" |
This action takes one parameter, fields, that contains comma-separated field values such as 610,630,650. This action corrects duplicate fields for the current record according to the fields that were passed as parameters. This action can only be used to identify and correct duplicate data found between multiple instances of the same field. |
|
Find duplicate fields (Indication Rules; see Working with Indication Rules) |
recordHasDuplicateFields "{fields}" Example: recordHasDuplicateFields "610,630,650" |
This action takes one parameter, fields, that contains comma-separated field values such as 610,630,650. This action can be either true or false. It returns true if duplicate fields were found for the current record according to the fields that were passed as a parameter. This action can only be used to identify and correct duplicate data found between multiple instances of the same field. |
Wildcards and Special Characters
when
(TRUE)
then
replaceContents "300.a.1 v\\\\." with "Leaves"
end
when
(exists '245.{*, }.c.\"')
then
replaceControlContents "008.{7,4}" with "2016"
end
when
((exists '260.{*, }.c.תשע\\"ו') OR (exists '264.{*, }.c.תשע\\"ו'))
then
replaceControlContents "008.{7,4}" with "2016"
end
- Wildcards cannot be used as the first character of a condition or value.
- To use a literal backslash (\), escape it with another backslash: \\.
- Use four backslashes (\\\\) to escape a period when it is the last character in the string. When the period is immediately followed by another character, it does not require four backslashes (as in addField "907.a.F.L.T\\\\."). However, it is best practice to always use the four backslashes in the normalization rule to ensure the most consistent desired results. See the following examples.
- As noted above, if a double quote is used in a condition (only) that is escaped using single quotes, or a single quote is used in a condition that is escaped using single quotes, you must further escape the double quote or quote with a double backslash.
- If the pipe symbol is part of the condition, use four backslashes to escape it, for example: removeField "866" if (exists "866.8.0\\\\|99"). This is required only when using a pipe symbol in the condition.
Example: Using the Period in a Normalization Rule with replaceContents
when
(TRUE)
then
replaceContents "245.a.\\\\." with ""
replaceContents "246.a.\\\\." with ""
end
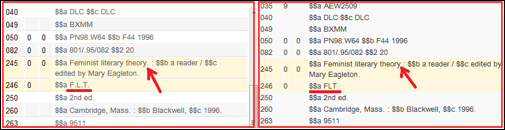
Example: Using the Period in a Normalization Rule with addField
salience 100
when
TRUE
then
addField "906.a.Architecture\\\\."
addField "907.a.F\\\\.L\\\\.T\\\\."
end
