
规范化规则处理
- 编目管理员
- 编目经理
- 编目员
- 要应用规范化规则到单个记录,使用完善记录选项(见元数据编辑器菜单和工具栏选项部分)或在预览规范化规则时应用更改到单个记录(见要预览规则的结果)。
- 要对一组记录应用规范化规则,您需要使用MarcDroolNormalization、MarcXSLNormalization或DcDroolNormalization任务(见使用规范化进程)创建进程,并指定使用元数据编辑器创建的规范化规则(见创建新规范化规则文件)。创建该进程后,您可以使用该进程运行作业(见 在既定集合上运行手动作业)。此外,您可以创建在元数据编辑器中选择保存时启用应用规范化规则的进程(见使用规范化进程)。
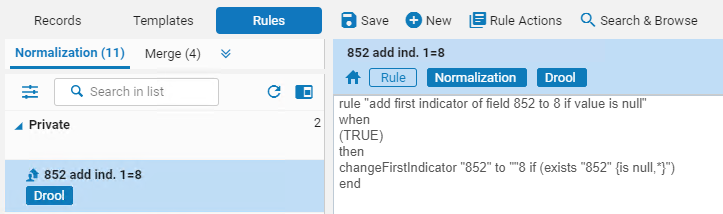
- 并行查看规范化规则和元数据记录
- 在元数据记录运行时预览规则结果
- 在规则和预览更改之间切换
- 编辑规则并立即测试
创建规范化规则
- 在元数据编辑器页面(资源 > 编目 > 打开元数据编辑器)打开规则区域。
- 要对MARC记录或都柏林核心记录创建规范化规则,选择新建 > 规范化。 规范化规则属性(新规则)对话框打开。
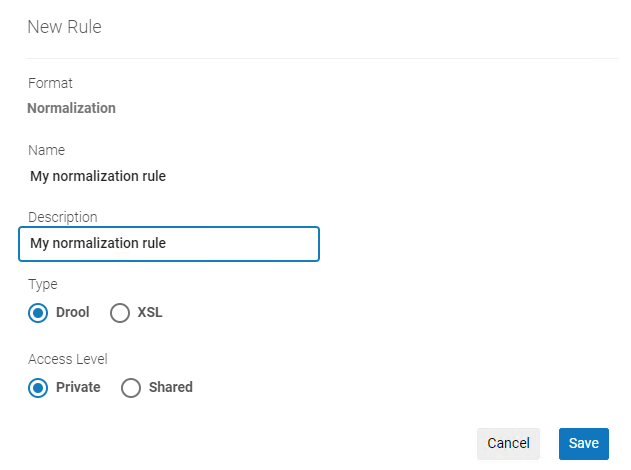 规范化规则属性对话框
规范化规则属性对话框 - 输入规范化规则名称和描述。 如果规则名称中使用单词“rule”,则必须不能大写。如果大写,规则将无法使用。
不要在规则名称中使用反斜杠(\)!如果这样做,规则将无法用于过滤结果集功能。 - 要对MARC记录创建规范化规则,选择Drool。要对都柏林核心元数据记录创建规范化记录,选择‘XSL’。
- 选择访问选项,专用 或 共享。如果选择专用,只有您可以处理该规则,并且规则不能包含在规范化进程中。如果选择共享,您的规则将在编目员之间共享。在这种情况下,多个用户可以同时查看规则,如果两个或更多的人打开规则进行编辑,当您尝试保存更改时,会显示一条警告消息。(您可以选择保留更改或允许其他用户进行更改并保存更改。)
- 选择保存。元数据编辑器编辑面板打开。
您可以包括现有的规则语法(编辑 > 添加规则 > {type of rule})或定义一个规则(详情参见规范化规则语法)。 - 选择保存。规则将添加到规范化规则选项卡下的规则文件列表中。
- 在元数据编辑器页面(资源 > 编目 > 打开元数据编辑器),选择规则选项卡并展开规范化文件夹。
- 要复制,打开共享区文件夹。右键点击要复制的规则并选择复制。
复制规则对话框打开。指示名称和描述并指示是否保存为专有(仅对您可用)或共享规则(对您的机构中的所有用户可用)。
提交规则到共享区的Alma用户的名字和联系电子邮箱在对话框中显示,有问题可以联系该用户。 - 要提交规则到共享区,右键点击规则并选择提交到共享区。
规则共享对话框打开。提供描述性名称和描述并选择保存在共享区中保存规则。
- 在元数据编辑器页面(资源 > 编目 > 打开元数据编辑器),选择规则选项卡并展开规范化文件夹显示保存的规则。
- 选择要使用的规则,然后选择下列选项:
- 编辑 – 打开规则语法文本框,修改语法(详细信息见规范化规则语法)。
- 删除 – 点击是确认删除规则文件。
- 复制 – 复制所选的规则文件,修改并将其另存为新规则,而不影响原始文件。
- 属性 – 打开规范化规则属性对话框,修改规则文件的属性。
- 要重命名规则,复制规则,给复制的规则命名,然后删除旧规则。
- 找到要处理的书目记录(使用仓储检索或元数据编辑器 > 记录选项卡),并在元数据编辑器中打开它。
- 按(F6)或选择拆分编辑器图标。
- 在左面板选择规则选项卡并展开规范化文件夹。
- 在专用或共享文件夹中(不是共享区)右击想要预览或测试的规则并选择编辑。
规则显示在元数据编辑器的右窗格中。
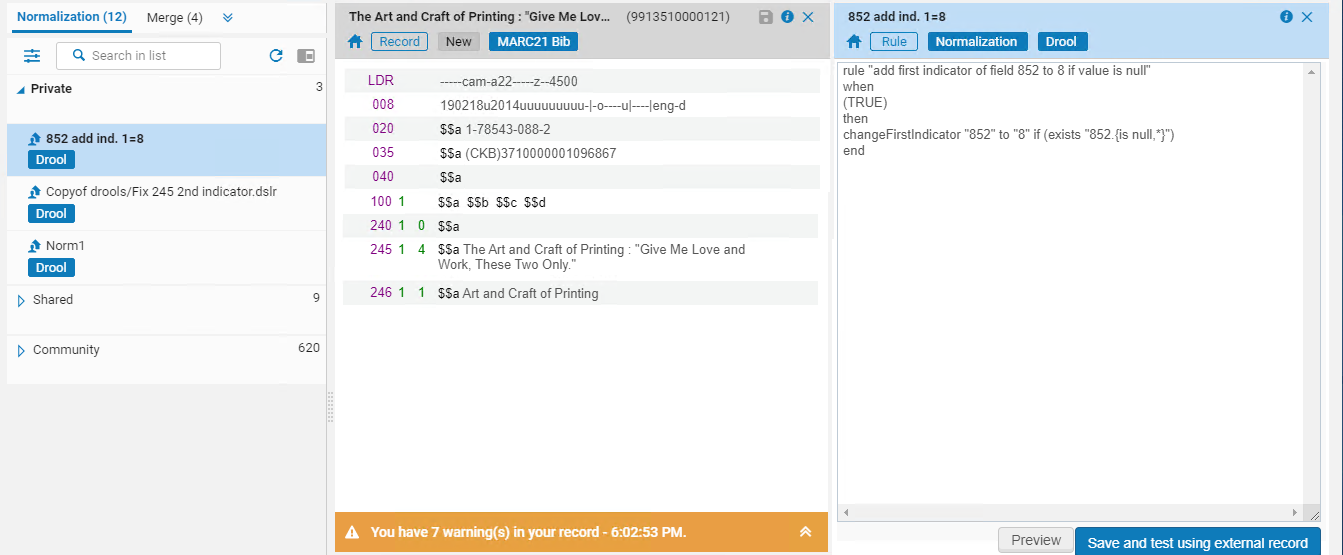
- 选择预览。规则将应用于记录,并显示结果。
要更新网络区记录,规范化必须由网络区机构运行(不是成员)。机构无法更新网络区记录,因此规范化仅应用于本地字段(成员的本地扩展)。预览网络区记录规则时,显示以下消息:请注意,在规范化进程运行时规范仅应用于本地字段。
- 选择应用更改保存对记录的修改或点击返回到规范化规则。
- 当您对规范化规则进行最后更改时,选择保存并使用外部记录测试以保存最终版本的规范化规则。有关详情,见测试外部数据源的规范化规则。
都柏林核心和MODS记录的规范化规则
在元数据编辑器中,有以下类型的规则与都柏林核心和MODS相关:
- XSL指示规则
- XSL规范化规则
XSL规范化规则不支持discovery:local。
无法按照常规的规范化规则编写都柏林核心和MODS规范化规则,只能写为XSL。这意味您需要在元数据编辑器(如上文所述)中直接写XSL,或者可以在记事本(或其他外部应用)中写好然后复制到元数据编辑器。
您可以在元数据编辑器中查看共享区中都柏林核心的以下XSL规范化规则示例:
- EXL – 更改dc:language的值en为English
- EXL – 替换都柏林核心记录中的字符串的通用规则
- EXL_Add_field_accessRights
- 在外部应用中写好XSL。
- 打开元数据编辑器 > 规则部分。
- 复制并粘贴XSL到元数据编辑器然后保存规则。
Primo VE和Esploro的规范化规则
除了Alma规范化规则,您可以对Primo VE和Esploro创建规范化规则。要创建这些规则,请选择新建,然后选择:
-
规范化(发现) - 该选项仅在Primo VE在系统中定义时显示。如果对加载到Primo VE且不在Alma中管理的书目记录创建DC或XML规范化规则时选定。有关这些规则的语法,见下文的DC和XML格式的规范化规则语法。
-
规范化(研究) - 该选项仅在Esploro在系统中定义时显示。有关详情,见管理资料规范化规则(Esploro)。
规范化规则语法
(<conditions on MARC record>) then
Action
End
- When 必须是第一行中唯一的字。条件必须放在单独的一行上。
- 您仅可以在“When”条件中对整个记录使用多个条件。每条规则必须只有一个action(在“Then”行之后)。如果想要在“Then”行之后使用多个action,分成多条规则,每条有一个action。
- 尽管在规则中允许使用多个布尔运算符,但当选择大量布尔运算符时会降低运行速度。因此每条规则应包含不超过200个布尔运算符。
- 如果未指定,则条件将在记录级别起作用。如果您希望条件分别作用于每个MARC21字段,则应为每个字段指定条件。例如,当有多个带相同标签的MARC21字段时。
- \b
- \t
- \n
- \f
- \r
- \"
- \'
- \\
- replacing \\\ with \\
- replacing \. with .
- replacing \ with \\
- replacing \( with (
- replacing \) with )
- replacing \\\| with \\|
记录元素
| 表达 | 意义 |
|---|---|
| "<tag>", "<new tag>" | 表示一个字段标签,例如001、245等。 |
| "<oldCode>", "<newCode>" | 表示子字段代码,例如a,b,c。 |
| "<element>" 用于数据字段 | 以下是数据字段的可能值:
|
| "<element>" 用于控制字段 | 以下是控制字段的可能值:
|
| 固定位置字段的"<element>" | 以下为固定位置的UNIMARC/CNMARC 1XX字段的可能值:
仅与UNIMARC/CNMARC 1XX字段相关。 |
| 记录级别的CONDITION | 以下是可能的条件选项。见下个部分的重要信息(条件)。
以下为仅与UNIMARC/CNMARC 1XX字段相关的可能条件选项:
|
条件
- WHEN子句 - 整个记录必须满足的条件,以确定规则是否应用于记录
- IF (一个操作) - 适用于单个字段的条件,以确定是否对该字段执行特定操作
- containsScript - 使用该条件检测特定语言。containsScript条件使用如下可检查的语言列表:Arabic, Armenian, Bengali, Bopomofo, Braille, Buhid, Canadian_Aboriginal, Cherokee, Cyrillic, Devanagari, Ethiopic, Georgian, Greek, Gujarati, Gurmukhi, Han, Hangul, Hanunoo, Hebrew, Hiragana, Inherited, Kannada, Katakana, Khmer, Lao, Latin, Limbu, Malayalam, Mongolian, Myanmar, Ogham, Oriya, Runic, Sinhala, Syriac, Tagalog, Tagbanwa, TaiLe, Tamil, Telugu, Thaana, Thai, Tibetan 和 Yi。见以下语法示例:rule "Is CJK in Authority"
when
containsScript "Han" "1**"
then
set indication."true"
end - exists <element> – 找到至少一个匹配
- exists <element> – 应用于数据字段在IF子句中使用时,操作元素和由条件测试的元素必须在同一(数据)字段。
- existsControl <element> – 应用于控制字段在IF子句中使用时,操作元素和由条件测试的元素必须在同一(控制)字段。
- existsMoreThanOnce "{element}" – 找到多个匹配项应用于数据字段。在IF子句中使用时,操作元素和由条件测试的元素必须在同一(数据)字段。
- not exists <element> – 无匹配项
- not exists <element> – 应用于数据字段在IF子句中使用时,操作元素和由条件测试的元素必须在同一(数据)字段。
- not existsControl <element> – 应用于控制字段在IF子句中使用时,操作元素和由条件测试的元素必须在同一(控制)字段。
- recordHasDuplicateSubfields(有关指示规则,见使用指示规则) – 如果根据字段、子字段找到当前记录的重复子字段(子字段和内容),返回true,且按以下格式处理忽略字符(charsToIgnore)字符串:recordHasDuplicateSubfields "<tag>" "<code>" "<charsToIgnore>"可以指定由逗号分隔的多个标签(字段)。可指定多个代码(子字段),并不需要空格分隔。可以指定没有空格分隔的一个或多个字符在用于评估重复的子字段的内容的结果为忽略字符。有关更多信息,见示例6。对于满足recordHasDuplicateSubfields条件(返回true)的记录,创建一组记录。
- 如果某个特定条件不正确,则应用,例如:addControlField "{element}" if(not exists "{condition}")
- 如果某个特定条件为真,则应用,例如:addControlField "{element}" if(exists "{condition}")
- 无条件应用,例如:addControlField "{element}"
操作列表
| 操作 | 格式/示例 | 评论 |
|---|---|---|
| 将字段和子字段替换为其它字段和子字段。 | changeControlField "<tag>" to "<new tag>" 例如:changeControlField "007" to "008" | 更改控制字段的标记标识符;不修改内容。 |
| changeField "<tag>" to "<new tag>" 例如:changeField "245" to "246" | 改变标签标识符;不修改指示符或子字段。 | |
| changeSubField "<tag>.<code>" to "<new code>" changeSubFieldOnlyFirst "<tag>.<code>" to "<new code>" changeSubFieldExceptFirst "<tag>.<code>" to "<new code>" 例如:changeSubField "035.b" to "a" | 在"<tag>"字段中更改子字段(或仅第一个子字段,或除第一个子字段之外的所有子字段)"<code>"为子字段"new code"。 | |
| changeFirstIndicator "<tag>" to "<value>" changeSecondIndicator "<tag>" to "<value>" 例如:changeFirstIndicator "245" to "3" | 在<tag>中设置指定的指示符值。 | |
| combineFields "<tag>" excluding "<comma-separated subfield list>" 例如:combineFields "852" excluding "a,b" | 合并指定数字的所有字段。将所有子字段从第二行和后续行复制到第一行,不包括命名子字段;只有第一次排除的子字段被复制,并且只有在第一行不存在的情况下。 | |
| 添加字段和子字段 | addField "<tag>.<code>.<value>" addField "<tag>.{<ind1>,<ind2>}.<code>.<value>" 例如:addField "999.a.RESTRICTED" | 将字段添加到MARC记录。将子字段的值设置为指定值。 |
| addControlField "<tag>.<value>" 例如:addControlField "008.820305s1991####nyu###########001#0#eng##" | 将控制字段添加到MARC记录。 | |
| addSubField "<tag>.<code>.<value>" addSubField "<tag>.{<ind1>,<ind2>}.<code>.<value>" 例如: addSubField "245.h.[Journal]" | 添加子字段 <code> with value <value>to field <tag>.如果该字段不存在,则不添加。 | |
| addSystemNumber "<element>" from "<tag>" prefixed by "<prefix tag>" 例如:addSystemNumber "035.a" from "001" prefixed by "003" | 使数据字段<element>等于括号中的第二个控制字段<prefix tag>的内容,其后为第一个控制字段<tag>的内容。 例如,如果001的值为9945110100121,003的值为DAV,左侧的示例条件将产生035,值为‡(DAV)9945110100121。 | |
| 复制字段 | copyField "<tag>" to "<new tag>" copyField "<tag>.<code>" to "<new tag>.<new code>" copyField "<tag>" to "<new tag>.{<ind1>,<ind2>}" 例如:copyField "971.a" to "100.u" | 将字段复制到另一个字段。在第一版中,未指定子字段(<code>和<new code>),新字段含有所有旧字段中相同的子字段。在第二版中,如果只是未指定<new code>,新子字段与<code>中指定的相同。 copyField 创建一个单独的字段,而不是将其添加到任何现有的字段。您可能希望将新字段与现有字段组合(见 组合字段)。 |
| 删除字段和子字段 | removeControlField "<tag>" 例如:removeControlField "009" | 删除所有出现的控制字段。 请注意,如果移除控制字段008,如果您没有重新创建它Alma会立刻重新创建。考虑在移除后重新添加字段,例如: rule "remove 008" when (TRUE) then removeControlField "008" addControlField "008.######s2013####xx######r#####000#0#eng#d" end |
| removeField "<tag>" 例如:removeField "880" | 删除所有出现的字段 <tag>. | |
| removeSubField "<tag>.<code>" 例如:removeSubField "245.h" | 从指定字段删除所有出现的子字段 <code>。 | |
| 替换字段或子字段中的文本 | replaceControlContents "<tag>.{<position>,<length>}. <value>" with "<new value>" 示例: replaceControlContents "LDR.{7,1}.s" with "m" | Replaces <value> with "<new value>" in starting position <position> to <position>+<length> of control field <tag>.仅替换匹配的文本 <value>。 |
| replaceContents "<tag>.<code>.<value>" with "<new value>" replaceContentsOnlyFirst "<tag>.<code>.<value>" with "<new value>" replaceContentsExceptFirst "<tag>.<code>.<value>" with "<new value>" 例如: replaceContents "245.h.[Journal]" with "[Book]" | 使用“new value”替换字段“<tag>”的子字段<code>中匹配的字符串(或仅第一个匹配的字符串或除第一个匹配字符串以外的所有字符串)<value>。无匹配<value>的字符串或部分字符串未被修改。 | |
| replaceSubFieldContents "<tag>.<code>" with "<tag>.<code>" 例如: replaceSubFieldContents "245.b" with "100.a" | 用另一个子字段的内容替换子字段的内容。 | |
| replaceFixedContents "<tag>.{<1_ind>,<2_ind>}.<code>.{<position>,<length>}.<value>" with "<new value>" Example: replaceFixedContents "100.{1,2}.a.{0,8}.20150226" with "20220724" | 替换UNIMARC和CNMARC 1XX固定位置字段中的<value>为<new value>。 仅与UNIMARC/CNMARC 1XX字段相关。 | |
| 在子字段中添加文本 | prefix "<tag>.<code>" with "<value>" 例如: prefix "035.b" with "(OCoLC)" | 向"<tag>"字段的"<code>"子字段的值添加前缀。 新值为<code>后带有旧值。 |
| prefixSubField "<tag>.<code>" with "<source tag>.<source code>" 例如:prefixSubField "910.a" with "906.a" | 向"<source tag>"字段中添加"<source code>"子字段的值,并作为子字段"<code>"的前缀添加到"<tag>"。 新值将为"<source tag>"字段中子字段"<source code>"的值并跟有旧值。 | |
| suffix "<tag>.<code>" with "<value>" 例如:suffix "035.b" with "(OCoLC)" | 向"<tag>"字段的"<code>"子字段的值添加后缀。 新值为旧值后带有<value>。 | |
| suffixSubField "<tag>.<code>" with "<source tag>.<source code>" 例如:suffixSubField "910.a" with "907.c" | 向"<source tag>"字段中添加"<source code>"子字段的值,并作为子字段"<code>"的后缀添加到"<tag>"。 新值将为旧值后带有"<source tag>"字段中子字段"<source code>"的值。 | |
| 在书目和规范记录中维护代理信息 例如,该语法可用于在MARC 21书目元数据配置任务列表中选择的规范化规则,以便在保存时规范化网络区书目记录。 此功能正在建设中。要启用此语法,请联系Ex Libris支持。 | addCreatingAgency "<tag>.<code>" 例如: addCreatingAgency "040.a" | 在“<tag>”字段的“<code>”子字段中添加创建代理商ISIL代码。 |
| addModifyingAgency "<tag>.<code>" 例如:addModifyingAgency "040.d" | 在“<tag>”字段的“<code>”子字段中添加修改代理ISIL代码。如果“<tag>.<code>”中已经有一个修改代理机构,那么会增加另一个代理商的ISIL代码。 | |
| replaceModifyingAgency "<tag>.<code>" 例如:replaceModifyingAgency "040.d" | 在“<tag>”字段的“<code>”子字段中添加修改代理ISIL代码。存在于“<tag>.<code>”中的修改代理都将被替换。 | |
| 拆分子字段 | splitSubField "<tag>.{ind1,ind2}.<code>.<delimiter>" to "<tag>.{<ind1>,<ind2>}.<code>" addSeq "<code>" 示例1: splitSubField "866.a.;" to "555.{0,0}.a" addSeq "8" 示例2: splitSubField "555.a.– " to "859.{0,0}.a" addSeq "8" 示例3: splitSubField "859.a.\\\\." 示例4: splitSubField "999.a.;" to "555.a" addSeq "8" | 标签为必备。 指示符可选。 因为拆分在子字段层级,代码为必备。 分隔符可为任意字符串。如果分隔符不存在,完整的子字段复制为第一段,并添加后续。 to组件可选。如果指定,创建多个to tag.code,每个都含有数据直到分隔符。见示例1和2。如果未指定to组件,子字段在相同字段中拆分为其他的相同子字段,如示例3。 addSeq组件可选。如果to组件未指定则无关。指定addSeq时,如示例1添加含有序列的子字段;如果子字段已在初始字段中存在,序列添加到字段中如示例2。 |
| correctDuplicateSubfields "<tag>" "<code>" 例如: 从字段610和630移除重复的子字段x、y和z。 | 根据作为参数传递的字段和子字段保留当前记录中第一次出现的内容并移除其他内容,以此更正重复子字段(例如,带有相同代码和相同值的子字段)。 您可能想要使用recordHasDuplicateSubfields创建提供给使用correctDuplicateSubfields的规范化规则的结果集。有关更多信息,见示例6。 对于带有不同值的子字段的重复数据删除,请见: | |
| moveSubfieldsToEndOfField "<tag>" "<code>" 例如: 移动子字段9和2到字段650末尾。 | 移动每个子字段的第一个内容到字段末尾并移除相同子字段的其他内容。 如果定义了多个子字段,根据规则将其按顺序放置在末尾。该例子中,子字段9放置在末尾,子字段2紧随其后。 请注意moveSubfieldsToEndOfField操作不支持if声明。 | |
| 更正当前记录的重复字段 | correctDuplicateFields "{fields}" 例如: correctDuplicateFields "610,630,650" | 该操作使用一个参数,含有按逗号分隔字段值的字段,例如610,630,650。 该操作根据由参数通过的字段更正当前记录的重复字段。 此操作仅可用于识别和纠正在同一字段的多个实例之间发现的重复数据。 |
| 查找重复字段 (指示规则;见使用指示规则) | recordHasDuplicateFields "{fields}" 例如: recordHasDuplicateFields "610,630,650" | 该操作使用一个参数,含有按逗号分隔字段值的字段,例如610,630,650。 该操作可以为true或false。如果根据由参数通过的字段如果在当前记录中找到了重复字段,返回true。 此操作仅可用于识别和纠正在同一字段的多个实例之间发现的重复数据。 |
通配符和特殊字符
when
(TRUE)
then
replaceContents "300.a.1 v\\\\." with "Leaves"
end
when
(exists '245.{*, }.c.\"')
then
replaceControlContents "008.{7,4}" with "2016"
end
when
((exists '260.{*, }.c.תשע\\"ו') OR (exists '264.{*, }.c.תשע\\"ו'))
then
replaceControlContents "008.{7,4}" with "2016"
end
- 不能在条件或值的第一个字符使用通配符。
- 要使用反斜杠(\),其后附上另一个反斜杠:\\。
- 当句点为字符串的最后字符时,使用四个反斜杠(\\\\)代表句点。当句点后面是另一个字符时,它不需要前面的四个反斜杠(比如 addField "907.a.F.L.T\\\\.")。但是,最佳做法是在规范化规则中始终使用四个反斜杠,以确保最一致的预期结果。见下例。
- 如上文所述,如果在用单引号引用的条件中使用双引号或单引号,必须在其后附上双反斜杠。
- 如果(|)符号是值的一部分,使用四个反斜杠(\\\\)避开,例如: removeField "866" if (exists "866.8.0\\\\|99")仅当条件中使用(|)符号时需要这样处理。
示例:在使用replaceContents的规范化规则中使用句点。
when
(TRUE)
then
replaceContents "245.a.\\\\." with ""
replaceContents "246.a.\\\\." with ""
end
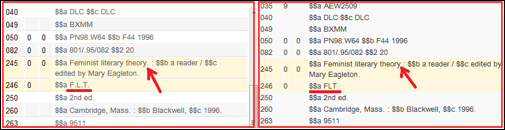
示例:在使用addField的规范化规则中使用句点
salience 100
when
TRUE
then
addField "906.a.Architecture\\\\."
addField "907.a.F\\\\.L\\\\.T\\\\."
end
