
FAQs for Smart Harvesting Framework
Smart Harvesting and Smart Expansion FAQ
Listed below are some Frequently Asked Questions regarding Smart Harvesting and Smart Expansion.
What is the difference between Smart Harvesting and Smart Expansion?
Smart Expansion is a way to load assets that are known to belong to your researcher. Currently, there are two types of Smart Expansion:
- Smart Expansion via CDI (also known as CDI migration) which requires an input file with researcher ID and associated DOI or PMID of their assets.
- Smart Expansion via Citation Lists which requires an input file of assets in RIS or BIBtex format.
Smart Harvesting is exploratory, it tries to find assets written by the researcher in CDI.
When should I run Smart Expansion and when Smart Harvesting?
Smart Expansion should be run before running Smart Harvesting. Smart Harvesting will work better if the researcher already has associated assets. Also note that Smart Expansion via Citation Lists is generally comprehensive and the system treats this as being the equivalent of a retrospective Smart Harvesting and updates the "Last Smart Harvesting Run Date" with the year of the latest publication (the date can be deleted or modified in the manage researcher page if necessary). Smart Harvesting will then run in ongoing mode for this researcher.
Is Smart Harvesting meant to be iterative? Do we reject false matches and then re-run the SH so it does better the next time?
Smart Harvesting is not iterative and when it runs again it will only bring in new assets added to CDI since the last run (based on the "Last Smart Harvesting Date"). The matching algorithm is undergoing continual improvement but does not yet learn directly from your rejections. This type of local self-learning may be added in future.
The system does keep track of rejections at the researcher level and will not offer the same record twice for the same researcher.
How often should we run SH to keep results up to date for a given researcher? Can/should we put researchers on a schedule?
Use the scheduled job to run ongoing Smart Harvesting. This job will run daily and once a week for every researcher for who Smart Harvesting (or Smart Expansion) has already been run.
Why are we seeing duplicate records for the same publication? Does SH not include deduping?
Smart Harvesting has two levels of deduplication:
- Deduping records fetched from CDI. CDI typically gets records from multiple sources. CDI groups these records (i.e dedups) but this does not work in all cases. Smart Harvesting does another round of deduplication but can still fail to deduplicate due to data issues.
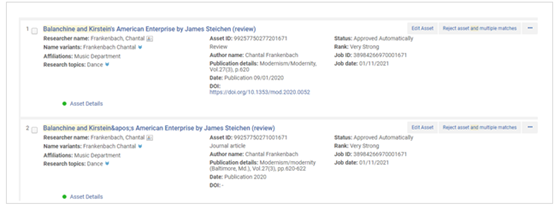
For example:
There is no shared DOI and the title differs – one asset has an error in the title:
.png?revision=1)
-
Before an asset is added, the system checks if it is already in the repository.
In general, the system tries to dedup but it depends on the data. ExLibris continually trying to improve the matching but if the data does not suffice – matching will fail.
Which record is selected from CDI?
In many cases CDI has several versions of an asset received from different sources. CDI groups these versions. Esploro uses one of the records and selects the one that is best in terms of metadata. Priority is given to a record with well formatted and rich author details (name, affiliation, IDs like ORCID or email) then to whether the record has an abstract and/or keyword.
Esploro cannot make use of some sources – even if our customer has a subscription. This includes records from Scopus and WoS. CDI has close to full coverage for both these repositories from other sources.
What is a difference between rejecting an asset and rejecting a author-researcher match. What does it mean to reject multiple matches?
These two are related.
It is important to keep in mind that every author in a record must be matched with a researcher (affiliated or non-affiliated). An asset may have multiple matched affiliated authors and a separate task is opened for each one. This means that an author match cannot be rejected – it needs to be replaced. You can reject a match (without replacing) only if you reject the entire asset. When you reject an asset, you are also rejecting all author matches related to it.
If there are multiple tasks for an asset (i.e multiple matched affiliated authors), the option is "Reject asset and multiple matches". If there is a single task (i.e single matched affiliated author), the option is " Reject match and asset".
Several of the results are not on the researcher CV. How can we feel confident these are their publications without asking them to review it themselves?
If you have reason to believe that the CV is complete and current – the match may be a mistake or maybe it is an output they don’t want in their profile. The best way of being sure is to ask the researcher of course. Researcher self-approval is on the roadmap.
There is a report which produces an excel that you can send to researchers for approval, see: Author Matching Report / Update Approved Matches. If you can link to the publisher site (easy to do if there is a DOI), there is general information about the researcher (email and affiliation, which is a big help in deciding).
Author matching tasks were opened for researchers which were not included in the Smart Harvesting run. Why is this happening?
This is happening because many assets have multiple authors and since researchers often collaborate with colleagues from the same institution – more than one author may be matched with an affiliated researcher.
Smart Harvesting matches all authors. So, if the researcher for who you run Smart Harvesting co-authored with other affiliated researchers – they may be matched as well, and tasks created for them even though Smart Harvesting was not run for them.
Is it possible to limit the search in CDI to the institution’s level or to a certain time frame?
This is not an option.
It is possible to edit the "Last Smart Harvesting run" date in the Manage Researcher page and start Smart Harvesting from a specific date.