
General Overview of Smart Harvesting Framework
This page gives an overview of what Smart Harvesting is used for and how it works. For a description of how to work with Smart Harvesting, see Working with Smart Harvesting. For a video on automated repository population (including Smart Migration, Smart Expansion, and Smart Harvesting) see here. For Smart Harvesting reports see here. For working with Smart Expansion see here.
What is Smart Harvesting
Smart Harvesting is intended to help the institution build up the list of assets for Researcher Profiles and the Repository – retrospective and ongoing.
Within the Smart Harvesting framework there are two types of mechanisms:
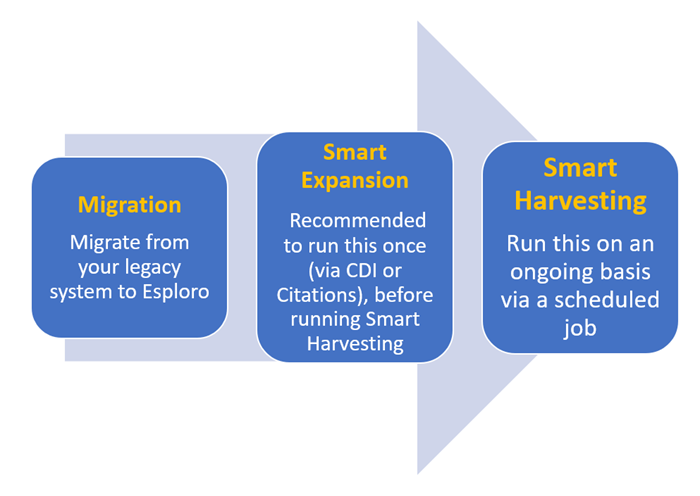
- Smart Expansion – there are several types of "Smart Expansion". In Smart Expansion you can load assets that are known to belong to the researcher. Types of Smart Expansion include:
- Smart Expansion via Citation List – Smart Expansion works with lists of citations known to belong to the researcher in BibTex or RIS format.
- Smart Expansion via CDI which works with lists of DOIs known to belong to the researcher. The asset is fetched from CDI. This option works as a type of Import Profile and not as a Smart Harvesting Profile.
Assets from Smart Expansion are either approved automatically or not according to the options selected for Asset Approval in the profile configuration. Assets from Smart Expansion that are not yet approved are in the pending approval status (see Author Matching Approval Task List).
For more information see Smart Expansion via CDI and Smart Expansion via Citation Lists.
For information on CDI and CDI sources see Central Discovery Index (CDI).
Additional types may be added in the future.
- Smart Harvesting - Smart harvesting is exploratory and searches for assets belonging to researchers in CDI. Smart Expansion should be run before Smart Harvesting which provides ongoing harvesting of new assets.
Currently, Smart Harvesting captures publications (articles, conference proceedings, books, book chapters, book reviews and reports) and datasets. In the future, it will also include patents, creative works and more.
Assets from Smart Harvesting are only added to the repository after at least one author-researcher match has been approved. Until this approval the assets are called provisional and will only display in the Author Matching Approval Task List.
Smart Expansion is retrospective and should be run before Smart Harvesting which can be used for ongoing harvesting of new assets. The two forms of Smart Harvesting are further explained below.
Both Smart Harvesting and Smart Expansion (as well as the migration) make use of an Author Matching algorithm to determine if the asset was indeed written by the researcher. In Smart Expansion this is used to match co-authors. The Author Matching algorithm uses Machine Learning techniques. Since unique IDs (e.g. ORCID) are very rarely found in both the incoming record AND the researcher record, in most cases the system needs to rely on the metadata (the author/researcher names and any additional supporting data it has).
How Does Smart Harvesting Work?
Smart Harvesting sends a query based on your affiliated researchers' names (preferred and all variants) and ORCID IDs to CDI (unless the Smart Harvesting option has been disabled for the researcher in Manage Researchers). The records returned by CDI are considered "candidate" assets and Smart Harvesting first checks if a record is indeed likely to be research output belonging to your researcher. If it is, Smart Harvesting attempts to match all the authors in the record to affiliated or non-affiliated researchers.
If the system determines that the candidate record is not likely to belong to the researcher, the record is discarded. If the system determines that the candidate record may belong to the researcher, the record goes on to asset matching. At present, if the asset matches an existing record, it is rejected. In future releases, the option to update an existing asset in the repository with data from a record captured by Smart Harvesting will be added, e.g. to add missing abstract or subject terms.
Since unique IDs (e.g., ORCID) are not consistently found in both the incoming record AND the researcher record in most cases, the system relies primarily on the metadata – the author/researcher names and any additional supporting data it has.
Matching names is a major challenge because names are not unique, they can be formatted in different ways and researchers can publish research outputs under different names. There are researchers with the same name publishing in the same subject area even in the same institution.
Example:
Your institution has a researcher with the name Scott Shaw from the Physics Department. Based on the name, Smart Harvesting sends a query to CDI and gets back results including the following article:
Shaw, Scott K., Wenqi Liu, Seamus P. Brennan, María de Lourdes Betancourt-Mendiola, and
Bradley D. Smith. 2017. "Non-Covalent Assembly Method that Simultaneously Endows a
Liposome Surface with Targeting Ligands, Protective PEG Chains, and Deep-Red Fluorescence
Reporter Groups." Chemistry - A European Journal 23 (51): 12646-12654.
The author name is the same but was this article written by the institution's Scott Shaw or another person with same name?
Initial and Ongoing Smart Harvesting
When Smart Harvesting is run for the first time for a researcher it attempts to bring back all possible records for the researcher. Once this initial (or "retrospective") run has completed, Smart Harvesting will work in ongoing mode which means only new assets are brought in. The system knows if Smart Harvesting was run because it stores the last run date per researchers. For a general overview of Smart Harvesting, see Smart Harvesting Overview.
In some cases, Smart Expansion can be run instead of the initial Smart Harvesting.
The initial Smart Harvesting is run ad hoc in groups of up to 50 researchers. The ongoing Smart Harvesting is run via a scheduled job on a weekly basis.
Once a candidate asset is returned, Smart Harvesting will attempt to match ALL the authors. For instance, if the researcher for who you run Smart Harvesting co-authored with other affiliated researchers, they may be matched although Smart Harvesting was not run for them.
These are some points that are important to keep in mind:
- Smart Harvesting must have some information about the researcher – at minimum; a meaningful academic unit affiliation, research topics or a linked asset. The more information the system has, the better the results will be of author matching.
It is important to add name variants if the researcher publishes under different names or did so in the past, e.g. a nickname. There is no need to add initials as a variant since the algorithm takes this into account. - It is important to distinguish between approval of the asset and approval of an author-researcher match. The asset is considered approved and will be added to the Esploro repository (including being displayed in the Research Portal) as soon as at least one of the matches of an author to an affiliated researcher has been approved. An asset is displayed in the Researcher's profile only after the relevant author-researcher match has been approved.
- There may be some researchers (generally with very common names) who will return too many results from CDI and will be blocked. This limitation can be mitigated when both the researcher data and CDI entries include ORCID IDs.
- Researcher Manager
See also Working with Smart Harvesting.
Last Smart Harvesting Date
When Smart Harvesting runs its first checks, the Last Smart Harvesting date is displayed in the Researcher record under "Researcher Settings". The date is initially empty and can be updated in one of four ways, as described below. The next time Smart Harvesting runs for the researcher it will request records added to CDI since this date.
The Last Smart Harvesting date is updated in the following scenarios:
- After Smart Harvesting is run for the researcher.
- After Smart Expansion via Citation Lists or Smart Expansion via CSV is run. The system updates it with the year of the most current citation.
- The date was updated manually by editing it in the Researcher Settings section from Researchers > Manage Researchers (select Edit in the row actions menu).
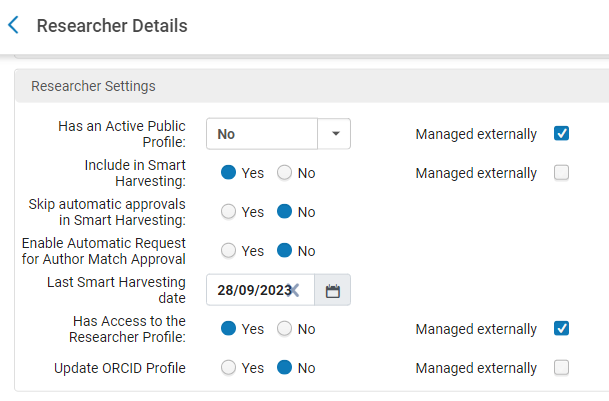
- When running the Update Set of Researchers job from Admin > Run a Job.
.png?revision=1)
Although the Last Smart Harvesting Date can be updated to any date, ongoing Smart Harvesting will not run if the Last Smart Harvesting Date is > 3 years.
See also Working with Smart Harvesting.
Supported Asset Types for Smart Harvesting
The following asset types are supported and are added to Esploro via the Smart Harvesting Framework:
- Journal article
- Book
- Book chapter
- Conference proceeding
- Report
- Book review
- Dataset
Additional References
- Video: Automated Repository Population
- Working with Smart Harvesting
- Running Manual Jobs on Defined Sets
- Smart Harvest Reports and Notifications
- Smart Harvesting Approval Flows and Author Matching
- CDI
- Smart Harvesting FAQs
- Smart Expansion
- Working with the Esploro Research Hub
- Quick Guide for Administrators in Esploro