
Reports and Notifications for the Smart Harvesting Framework
Overview
This page describes how to work with the following reports in Smart Harvesting:
- Author Matching report
- Potential Duplicate Researchers report
- Bulk Merge Duplicate Researchers report
For background information, see:
Author Matching Report / Update Author Matches
The Author Matching report lists author-researcher matches for assets captured by Smart Harvesting or Smart Expansion, as well as those imported via an import profile (migration) or via SWORD. The report can be used to approve assets in bulk, and, for Smart Harvesting only, it can also be used to reject assets in bulk. The following describes the steps of this workflow:
- Export a list of potential author-researcher matches as an Excel file; see Exporting the Report, below.
- In the Excel file, mark all the matches that you want to approve (and/or reject, for Smart Harvesting), and then save the file; see Approving or Rejecting Matches, below.
- Import the marked file back into Esploro to implement the changes; see Updating Approvals and Rejections, below.
Any matches that are not marked for either approval or rejection in the imported file must be managed manually in the Administrative interface; see Author Matching Approval Task List for more information.
When new assets are approved for a researcher and added to their profile, the New Research Outputs Added to Profile Letter is sent to the researcher.
The Author Matching report can be accessed at Researchers > Researchers > Author Matching Report/Update Author Matches. Both the export and import operations are managed from this page.
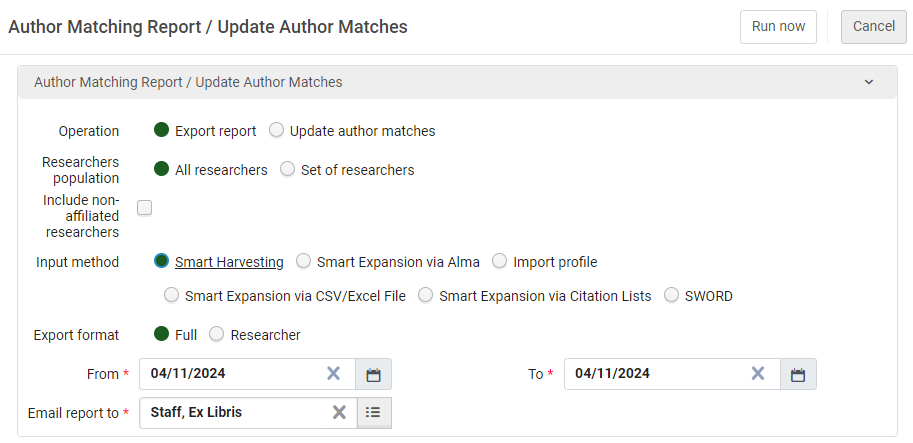
Exporting the Report
- From the Author Matching Report/Update Approved Matches page (Researchers > Researchers > Author Matching Report/Update Author Matches).
- From the Author Matching task list (Repository > Smart Harvesting > Author Matching Approval Tasks List or the Task List (
 ) in the Persistent Menu). Generating the report in this way enables you to narrow down the list of tasks included in the report, because the currently applied filters are implemented for the report.
) in the Persistent Menu). Generating the report in this way enables you to narrow down the list of tasks included in the report, because the currently applied filters are implemented for the report.
- Under Operation, select Export report.
- Select the parameters, as follows:
- Researchers population – The report can include all researchers or only researchers included in a set of researchers.
- Include non-affiliated researcher – Select this checkbox to include non-affiliated researchers in the report. The default is to exclude non-affiliated researchers.
- Input method – The source from which the assets were imported into Esploro: Smart Harvesting, Smart Expansion via Alma, Import profile, Smart Expansion via CSV/Excel File, Smart Harvest via Citation Lists, SWORD. (For information on the various types of Smart Expansion, see Working with Smart Expansion. For information on SWORD deposits, see SWORD Deposits in the Developer Network.)
- Export Format:
- Full – Includes all fields
- Researcher – A format intended for a researcher in which most of the researcher information (which the researcher already knows) is not included.
- From/To – Select the range of asset import dates to include in the report.
- Email report to – Add the email address to which the report should be sent. By default, the email of the operator is used.
- Select Run now. A job ID is displayed. The job can be monitored in the Monitor Jobs page (Admin > Manage Jobs and Sets > Monitor Jobs). When the job finishes running, the report is emailed to the email address specified. See the next section for information about the format of the report.
- In the Author Matching task list, set the desired task-list filters.
- Select Export (
 ) > AM Report Format. The report is generated and available for download from your browser.
) > AM Report Format. The report is generated and available for download from your browser.
Author Matching Report Format
The Author Matching report lists all the potential matches between asset authors and researchers that were identified by Esploro and not yet approved. It is sorted by the researcher's internal ID, and has the following columns:
- Control info – Information required in order to perform the update approvals operation (see Approving or Rejecting Matches, below):
- Researcher User ID – The internal researcher ID
- Author Type – Indicates if the author is a creator or contributor; this information is important for the update process
- Asset ID – this is the asset ID.
- Researcher info – most of these columns are not included in the "Researcher" format:
- Researcher Name
- Researcher Type – Indicates if the researcher is affiliated or non-affiliated
- Researcher Email
- Researcher Primary ID
- Researcher Affiliation – Researcher affiliations, if any
- Researcher Keywords – Research topics and keywords from the researcher's record
- Researcher Area of Interest – From the researcher's record.
- Status – The status of the match: whether the researcher is affiliated or unaffiliated, and the strength of the match (Matched on ID, Very Strong match, Strong match, Uncertain match)
- Asset info
- Author Name
- Asset Type
- Title
- Publication Details
- Publication Date
- DOI
- PMID
- Asset Research Topics – Research topics and keywords assigned to the asset
- Asset Abstract – Description of the asset
- Approval info and functions
- Additional AM Tasks (Smart Harvesting only) – "Yes" when the asset has two or more authors that were matched to affiliated researchers, resulting in an author matching (AM) task for each. "No" when the asset has only one author that was matched to an affiliated researcher.
- Provisional Asset (Smart Harvesting only) – "Yes" if the asset has not had at least one author-researcher match approved. "No" if at least one author-researcher match has already been approved for the asset.
An asset harvested by Smart Harvesting is considered “provisional” until the first author-researcher match is approved, because only then is it clear that the record is relevant to the repository. A provisional asset is not included in the repository of assets, and can only be found in the Author Matching Task list. - Approved – The column in which you can approve a match (initially blank); see Approving or Rejecting Matches, below
- Rejected (Smart Harvesting only) – The column in which you can reject a match (initially blank); see Approving or Rejecting Matches, below. When a match is marked for rejection, if the asset to which it is linked has no pending or approved matches to other researchers, or all of its matches are pending and are marked for rejection in the report, all its matches are rejected and the asset is deleted from the database. If these conditions are not met, all rejections for the asset are ignored.
Approving or Rejecting Matches
Once you have received the exported report, review it, and do one of the following:
- For each match you want to approve, in the Approved (add X if approved) column, insert an X (uppercase or lowercase).
- For Smart Harvesting reports only, for each match you want to reject, in the Rejected (add X if rejected) column, insert an X (uppercase or lowercase).
Note that if any other text besides the letter X appears in either of these columns, the match is not approved/rejected.
When you are finished, save the file (as an Excel file).
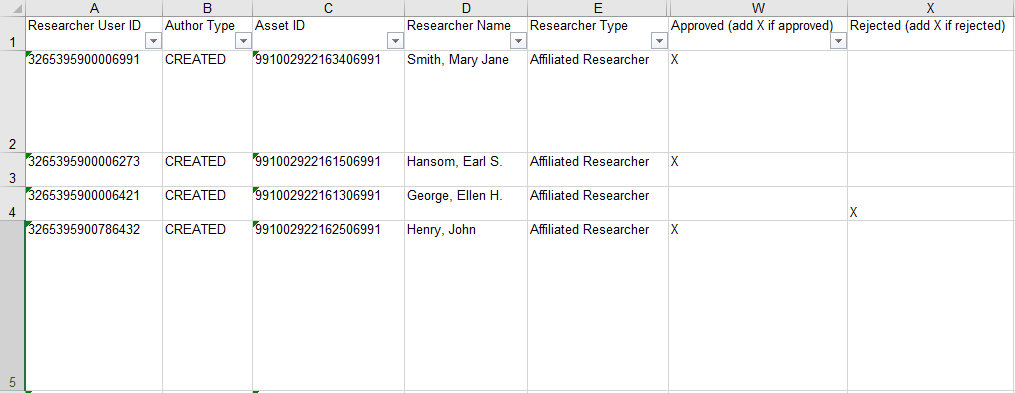
In order for the import of the file to be performed successfully, the column titles must not be modified. In addition, the input file must contain at least the following four mandatory columns: Researcher User ID, Author Type, Asset ID, Approved. The other columns can be removed, if desired.
Updating Approvals and Rejections
In order to apply the approvals and rejections that you marked in the Approved and Rejected columns of the Excel file, you must import the file back into Esploro. This is done from the same page from which the Excel file was originally generated – the Author Matching Report/Update Author Matches page (Researchers > Researchers > Author Matching Report/Update Approved Matches).
Importing the file initiates the Author Matching Bulk Approve job, which implements the updates. During this process, if any matches were marked for rejection in the Excel file, extensive validations are performed in order to ensure that the rejected assets are provisional and that all their matches in the report were rejected. Assets that meet these criteria are deleted, and their matches are rejected. When the job is completed, the job report lists all the rows that were marked for rejection but could not be rejected because they did not meet these requirements.
- Under Operation, select Update Approvals.
- Under File, select the file.
- Select Run now. A job ID is displayed. The job can be monitored in the Monitor Jobs page (Admin > Manage Jobs and Sets > Monitor Jobs). Upon completion, a job report, containing information about the job, the number of records processed by it, and any rejection requests that were blocked, can be accessed from the History tab of the Monitor Jobs page. The job report is also sent to the operator.
Checking and Bulk Merging for Duplicate Researchers
Duplicate researchers can be created by the various ingest flows. This can happen due to problematic data and incorrect matching by the Author Matching algorithm. There are two scenarios:
- A new non-affiliated researcher is created instead of correctly matching to an affiliated researcher
- A new non-affiliated researcher is created instead of correctly matching to an existing non-affiliated researcher
It is recommended to run the Potential Duplicate Researcher Report on an ongoing basis to check if the potential researchers are indeed duplicate, and then merge them. For general information on managing researchers see Working with Researchers.
For video showing this functionality see How to Bulk Merge Duplicate Researchers.
Running the Potential Duplicate Researcher Report
What the Report Checks
The report checks for duplicates among affiliated and non-affiliated researchers using:
- Identifiers
- Normalized names (case insensitive, punctuation ignored, middle names ignored unless different, wildcards used for initials, and diacritics compared to ASCII characters)
Running the Report
-
Navigate to Research > Researchers > Potential Duplicate Researcher Report.
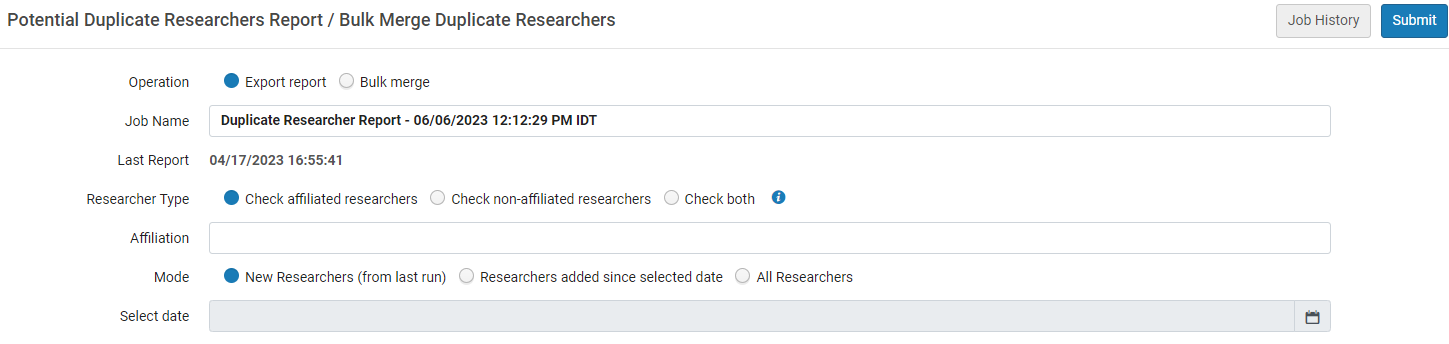 Potential Duplicate Researchers Report
Potential Duplicate Researchers Report -
Optionally enter a name for the job.
-
Select the type of researcher to check
-
Check affiliated researchers – check affiliated against non-affiliated
-
Check non-affiliated – check non-affiliated against non-affiliated
-
Check both
It is recommended to first check affiliated researchers, merge as needed, and only then check non-affiliated researchers.
-
Optionally, filter the list of researchers by affiliation (relevant to affiliated researchers).
-
Select whether to check researchers added from the last time this job was run, from a specific date, or for all researchers. If you select to run from a specific date, enter the date.
-
Select Submit to run the job. You are redirected to the Running tab on the Monitor Jobs page. You can select Refresh to view the latest status of the job.
-
When the job has completed, select the History tab on the Monitor Jobs page.
-
Open the report by selecting the report Name, or by selecting Report from the actions menu. The report shows the number of duplicates found. If this number is more than one, select Click to download report to list the potential duplicates in a CSV file.
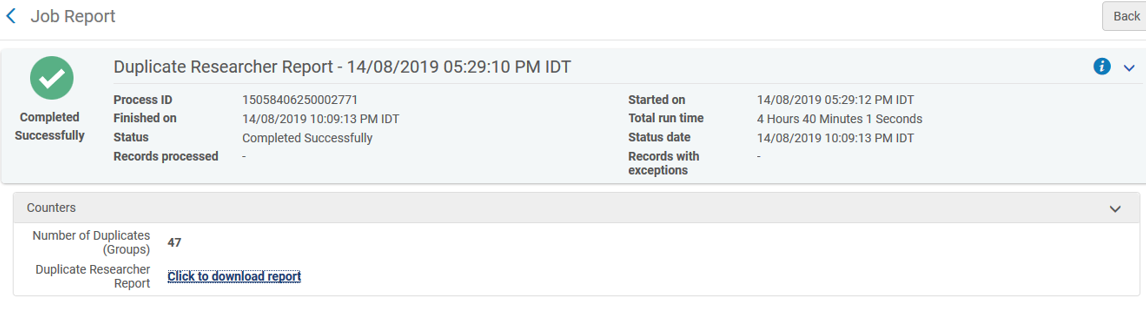
Report Structure
The report contains the following columns of information:
- Group Number
- Researcher name
- Affiliation type (affiliated/non-affiliated/previously affiliated)
- Academic units
- Primary ID
- Number of assets
- Subjects from the Researcher record including Research topics and Keywords
- Asset information from one of the assets belonging to the researcher, research topic and keywords or title
- Internal Researcher ID
- ORCID
- Other Identifiers
- Merge Status – this is required for the bulk Merge option (it is explained in the following section).
Options for Merging Duplicate Researchers
There are 2 ways to merge researchers that were identified as duplicate:
- Use the Move all assets and grants option (available only from non-affiliated researchers) to move all assets and other entities from the non-affiliated researcher to an affiliated researcher or another non-affiliated researcher, and then delete the non-affiliated researcher. See Working with Researchers for instructions on how to use this option.
- Use the option to Bulk Merge Duplicate Researchers in the Duplicate Researchers/Bulk Merge Duplicate Researchers feature. This performs the same actions as the Move all assets and grants option but in bulk mode.
Performing a Bulk Merge for Duplicate Researchers
When to Perform a Bulk Merge
The report can be used to check groups of researchers for duplicates. If you decide that any groups do include duplicates, you can then use the Bulk Merge Duplicate Researcher job to merge them in bulk.
What Fields to Merge
There are three mandatory fields for the bulk merge:
- Group ID – do not change this column.
- Internal Researcher ID – do not change this column.
- Merge Status - there are three possible values:
- K or k – indicates “Keep” this researcher i.e., merge other researchers to this researcher. Note that a group can have only one "Keep" researcher.
- M or m – indicates “Merge” this researcher i.e., merge this researcher to the “Keep” researcher. Only a non-affiliated researcher can be merged.
- Blank – no value is added i.e., do not change this researcher.
Performing the Merge for Duplicates
-
Navigate to Research > Researchers > Duplicate Researcher Report.
-
Select the Bulk merge option.

-
Load the file.
-
Select Submit - the Monitor jobs page displays.
-
The job report will report on the groups that were successfully merged and invalid groups. Groups can be invalid if:
-
Any of the mandatory columns is missing.
-
The internal ID is invalid.
-
Merge status is invalid.
-
A group has more than one keep.
-
The same researcher is a Keep in one group and a Merge in another.
-
-
After the Bulk Merge job has completed, it will trigger the Delete redundant non-affiliated researchers job that completes the deletion of all merged researchers. Once that job has completed, you can run the Potential Duplicate Researchers Report again. The report should reflect the latest changes.