
Digitalen Inhalt gesammelt erstellen
Um digitale Ressourcen zu verwalten, müssen Sie die folgenden Rollen innehaben:
- Digital Bestands-Mitarbeiter
- Digitaler Bestands-Mitarbeiter, erweitert (erforderlich für Löschvorgänge)
- Sammlungsbestands-Mitarbeiter (erforderlich, wenn Sie eine neue digitale Repräsentation hinzufügen)
Digitalen Inhalt gesammelt erstellen
Der Arbeitsablauf für Sammel-Uploads besteht in Alma aus den folgenden Schritten:
- Konfiguration eines digitalen Importprofils, das Alma sagt, wie digitale Ressourcen bearbeitet werden sollen, wenn Sie einen Sammel-Upload zu Alma durchführen. Für weitere Informationen siehe Importprofile verwalten.
- Vorbereiten einer Metadaten-Datei der Titelsätze, die das Importprofil beim Import der Dateien verwendet. Für weitere Informationen siehe Vorbereiten der XML-Metadaten-Datei und Vorbereiten der CSV-Metadaten-Datei.
- Hochladen der Dateien mit deren Metadaten in Alma unter Verwendung des Digital Uploader. Für weitere Informationen siehe Hochladen der Dateien in Alma.
Hochladen der Dateien in Alma
Sie verwenden Almas Digital Uploader, um einen Sammel-Upload von Dateien in Alma durchzuführen. Die Titel (Titelsätze) werden in die Sammlung eingefügt, die Sie beim Upload auswählen. Für weitere Informationen zu Sammlungen siehe Sammlungen verwalten.
Jede Gruppe an Dateien, die Sie in Alma für den Upload vorbereiten, wird Aufnahme genannt.
Die Vorbereitung der Aufnahme geschieht in vier Schritten:
- Erstellen einer Aufnahme
- Hinzufügen von Dateien zur Aufnahme (einschließlich MD-Dateien)
- Hochladen der Dateien
- Absenden der Aufnahme
Informationen zum Aufnahmen-Ordner werden im lokalen Speicher Ihres Browsers gespeichert. Daher können Sie zuvor erstellte Aufnahme-Ordner nicht sehen, wenn Sie von einem anderen Browser auf den Uploader zugreifen (oder vom selben Browser, aber als anderer angemeldeter Benutzer), oder wenn Sie den lokalen Speicher Ihres Browsers löschen. Dies wirkt sich nicht auf bereits abgesendete Daten aus.
Um Dateien in Alma hochzuladen und abzusenden:
- Öffnen Sie die Seite Digital Uploader (Ressourcen > Erweiterte Tools > Digital Uploader).
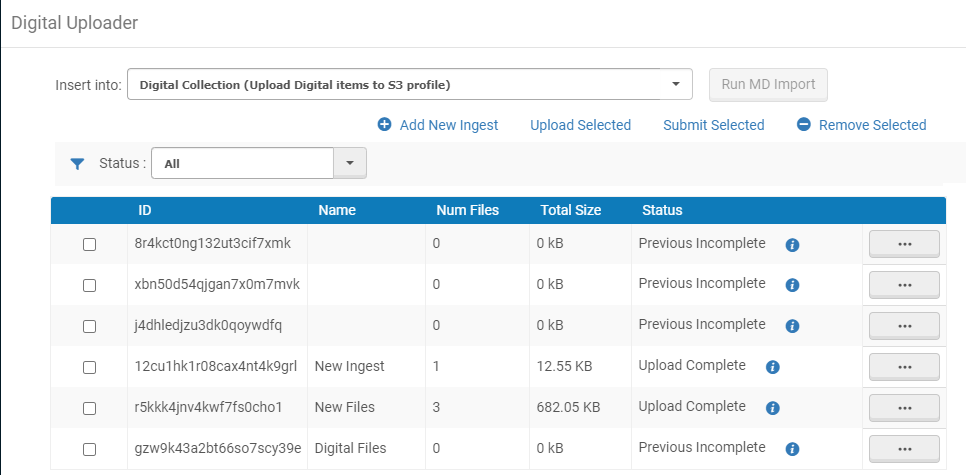
- Wählen Sie für die Dropdown-Liste Einfügen in die Sammlung aus, in die die Dateien platziert werden, und das digitale Importprofil, das definiert, wie die Dateien in die Sammlung importiert werden.
- Fügen Sie Dateien hinzu, die an Alma gesendet werden sollen, indem Sie einen der folgenden Schritte ausführen:
- Ziehen und ablegen - Fügen Sie eine Aufnahme hinzu, indem Sie einen Ordner in die Liste der Aufnahmen ziehen und ablegen; und fügen Sie Dateien zu einer bestehenden Aufnahme hinzu, indem Sie diese in eine Aufnahme in der Liste der Aufnahmen ziehen und ablegen.
Ziehen und ablegen von Ordnern wird derzeit nur für Chrome unterstützt. Dateien können in allen unterstützten Browsern gezogen und abgelegt werden.
- Mit dem Feld Neue Aufnahme hinzufügen:
- Klicken Sie auf der Seite Digital Uploader auf Neue Aufnahme hinzufügen. Die folgende erscheint:
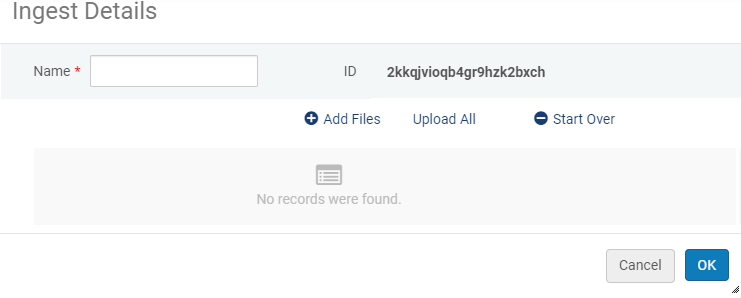 Neue Aufnahme hinzufügen
Neue Aufnahme hinzufügen - Geben Sie einen Namen für die Aufnahme ein.
- Klicken Sie auf Neue Dateien und wählen Sie die Dateien aus, die Sie hochladen wollen. Der Name der Datei, die Dateigröße und, wenn möglich, ein automatisch erstelltes Miniaturbild erscheinen für die folgenden Formate im Dialogfenster Aufnahme.
- jpg
- png
- mp4
- wav
- m4v
- doc
- ppt
- docx
- pptx
- jpeg2000
- Jede Datei kann maximal 1 GB haben.
- Sie können maximal 1000 Dateien in eine einzelne Aufnahme einfügen.
- Bei Aufnahmen über diesen Grenzwerten können Sie direkt in den S3-Speicher hochladen. Für weitere Informationen siehe Developer Netzwerk.
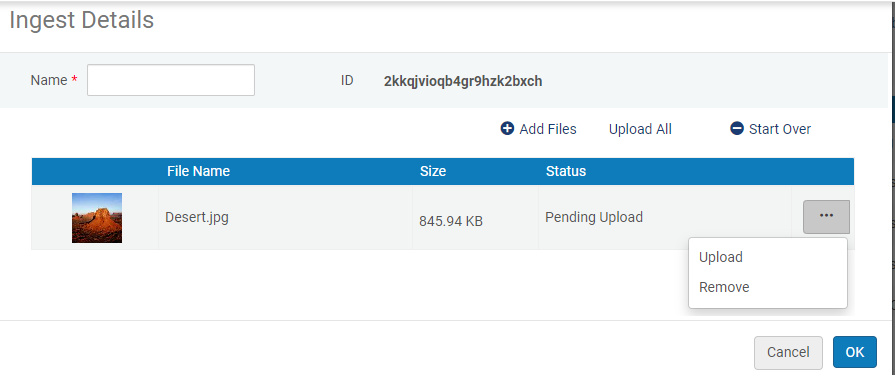 Aufnahme beginnen
Aufnahme beginnen- Sie können eine Miniaturbild-Datei in die Aufnahme einfügen, die beispielsweise in den Ergebnissen der Bestandssuche und im digitalen Viewer angezeigt wird. Für weitere Informationen siehe Hinzufügen einer Miniaturbild-Datei zur Aufnahme.
- Sie können eine Untertiteldatei im .vtt-Format mit demselben Namen wie die Videodatei in die Aufnahme einfügen, um Untertitel beim Abspielen des Videos anzuzeigen. Die Untertitel-Datei sollte abc.mp4.vtt.captions genannt werden, wenn das hochgeladenen Video abc.mp4 heißt. Für weitere Informationen siehe Der neue digitale Viewer.
- Fügen Sie eine oder mehrere Metadaten-Dateien für die Aufnahme hinzu (siehe Vorbereiten der XML-Metadaten-Datei oder Vorbereiten der CSV-Metadaten-Datei).
Wenn Sie der Aufnahme keine Metadaten-Datei hinzufügen, erscheint ein Warnsymbol in
 der Liste der Aufnahmen.
der Liste der Aufnahmen. - Um eine Datei in die Aufnahme hochzuladen, klicken Sie auf Upload. Um alle Dateien gleichzeitig in die Aufnahme hochzuladen, klicken Sie auf Alle hochladen. Um die Dateien zu entfernen und von vorne zu beginnen, klicken Sie auf Neustart.
- Klicken Sie auf OK, um zur Seite Digital Uploader zurückzukehren. Siehe Digital Hochladen.
- Klicken Sie auf der Seite Digital Uploader auf Neue Aufnahme hinzufügen. Die folgende erscheint:
- Die ID der Aufnahme
- Der Name der Aufnahme
- Die Anzahl der Dateien in der Aufnahme
- Die Gesamtgröße der Aufnahme
- Der Status der Aufnahme. Mögliche Status sind folgende:
- Neu – Die Aufnahme enthält keine Felder.
- Upload ausstehend – Die Aufnahme wurde noch nicht hochgeladen.
- Upload abgeschlossen – Die Aufnahme wurde noch nicht abgesendet.
- Abgesendet – Die Aufnahme wurde abgesendet.
- Um eine Datei von einer Aufnahme zu entfernen, wählen Sie die Aktionstaste aus der Zeilen-Aktionsliste für die Aufnahme und klicken Sie danach auf Entfernen.
- Um eine Aufnahme zu entfernen, wählen Sie die Aufnahme aus und klicken Sie auf Auswahl löschen.
- Ziehen und ablegen - Fügen Sie eine Aufnahme hinzu, indem Sie einen Ordner in die Liste der Aufnahmen ziehen und ablegen; und fügen Sie Dateien zu einer bestehenden Aufnahme hinzu, indem Sie diese in eine Aufnahme in der Liste der Aufnahmen ziehen und ablegen.
- Um Aufnahmen hochzuladen, wählen Sie die Aufnahmen aus und klicken Sie auf Auswahl hochladen.
- Um die Aufnahme zur Verarbeitung abzusenden, wählen Sie die Aufnahme aus, die Sie absenden wollen, und klicken Sie auf Auswahl absenden.
- Der Schritt Absenden ist erforderlich, sodass Sie fortfahren können, Dateien sicher zu Ihrer Aufnahme hinzuzufügen, die nicht verarbeitet wird, solange Sie nicht auf Absenden klicken.
- Das Feld Metadaten-Dateiname im Importprofil, das der Aufnahme zugeordnet ist, muss den korrekten Pfad und Dateinamen der Metadaten-Datei enthalten, damit die Aufnahme gesendet werden kann.
- Der MD-Importprozess wird üblicherweise planmäßig ausgeführt. Um den MD-Importprozess manuell auszuführen, klicken Sie auf Importprozess ausführen.
Der MD-Importprozess wird ausgeführt und die Aufnahme wird verarbeitet.
Dateien, die älter sind als 30 Tage (mit Ausnahme von gesperrten Dateien), werden durch den wöchentlichen Wartungsprozess gelöscht.
Vorbereiten der XML-Metadaten-Datei
Um den Digital Uploader zur Durchführung eines Sammel-Uploads von Dateien zu verwenden, können Sie eine XML-Datei entweder im MARC- oder DC-Format mit Metadaten für die Titelsätze vorbereiten. Jede Metadaten-Datei kann Informationen für mehrere Titelsätze enthalten. Alma erstellt die Titelsätze und Repräsentation für die Dateien mit den Informationen in dieser Metadaten-Datei.
Die Datensatz-Elemente in der Datei sollten in einem einzelnen Sammlungselement verschachtelt werden.
Die Art der Informationen, die in der Metadaten-Datei erforderlich sind, hängt davon ab, wie Sie das Importprofil konfiguriert haben. Wenn Sie beispielsweise das Importprofil konfiguriert haben, nach dem Dateinamen im MARC Feld 856, Unterfeld u, zu suchen, muss die Metadaten-Datei diese Informationen in diesem Feld enthalten.
Wenn der Titelsatz Sammlungsinformationen enthält, wird der Datensatz der im Datensatz angegebenen Sammlung zugewiesen. Ansonsten wird der Datensatz der Sammlung zugeordnet, die als Standard-Sammlungszuordnung im digitalen Importprofil ausgewählt wurde.
Wenn eine XML-Datei im falschen Format hochgeladen wird oder Elemente in der Datei fehlen, wird der Metadaten-Upload-Prozess mit Fehlern abgeschlossen. Der Prozess schlägt so lange fehl, bis der Benutzer die fehlerhafte Metadatendatei entfernt oder ersetzt.
MARC XML Sammlungszuordnung
Wenn Sie bei MARC-Datensätzen einen Normalisierungsprozess aktivieren, der addBibToCollectionNormalizationTask enthält, ordnet der Import den Datensatz einer Sammlung gemäß der folgenden Regelpriorität zu:
- Wenn MARC 787$w eine gültige Alma-Sammlungs-ID enthält, wird der Datensatz dieser Sammlung zugewiesen.
- Wenn MARC 787$o die Werte des externen Systems und der externen ID-Felder enthält, wie in einer vorhandenen Alma-Sammlung konfiguriert, wird der Datensatz dieser Sammlung zugeordnet. Das Feld muss das System und die ID im folgenden Format enthalten: ({system}){ID}, zum Beispiel (Rosetta)123454321 (ähnlich wie die Feldstruktur 035).
- Wenn der MARC 787$t den Namen einer Alma-Sammlung der obersten Ebene enthält, wird der Datensatz dieser Sammlung zugewiesen.
- Wenn keiner der oben genannten Optionen zutrifft, wird der Datensatz der Alma-Sammlung zugewiesen, die als Standard für das Importprofil definiert ist.
Wenn Sie eine Metadaten-Datei mit einem einzelnen Datensatz hochladen, ist kein Feld 856 erforderlich. Der erstellte Datensatz enthält alle Dateien, die im Aufnahme-Ordner enthalten sind.
Nachfolgend sehen Sie ein Beispiel einer XML-Metadaten-Datei:
<?xml version="1.0" encoding="UTF-8" ?>
<collection>
<record>
<leader>01139cam a2200277 a 4500</leader>
<controlfield tag="001">ocm27832725113 </controlfield>
<controlfield tag="003">OCoLC</controlfield>
<controlfield tag="005">20131108731707.4</controlfield>
<controlfield tag="008">970910r19451931pk b 000 0 eng </controlfield>
<datafield tag="035" ind1=" " ind2=" ">
<subfield code="a">(OCoLC)27832725113</subfield>
</datafield>
<datafield tag="100" ind1="1" ind2=" ">
<subfield code="a">Representation of rec 1</subfield>
<subfield code="b">jpg files</subfield>
</datafield>
<datafield tag="245" ind1="1" ind2="2">
<subfield code="a">Record 1 - Civil war</subfield>
</datafield>
<datafield tag="856" ind1=" " ind2=" ">
<subfield code="a">Soldier on a Horse</subfield>
<subfield code="u">civil war.jpg</subfield>
</datafield>
<datafield tag="856" ind1=" " ind2=" ">
<subfield code="a">North and South</subfield>
<subfield code="u">civil2.jpg</subfield>
</datafield>
<datafield tag="650" ind1=" " ind2="0">
<subfield code="a">Digital items loaded to Amazon</subfield>
</datafield>
</record>
</collection>
<collection>
<record>
<leader>01139cam a2200277 a 4500</leader>
<controlfield tag="001">ocm27832725113 </controlfield>
<controlfield tag="003">OCoLC</controlfield>
<controlfield tag="005">20131108731707.4</controlfield>
<controlfield tag="008">970910r19451931pk b 000 0 eng </controlfield>
<datafield tag="035" ind1=" " ind2=" ">
<subfield code="a">(OCoLC)27832725113</subfield>
</datafield>
<datafield tag="100" ind1="1" ind2=" ">
<subfield code="a">Representation of rec 1</subfield>
<subfield code="b">jpg files</subfield>
</datafield>
<datafield tag="245" ind1="1" ind2="2">
<subfield code="a">Record 1 - Civil war</subfield>
</datafield>
<datafield tag="856" ind1=" " ind2=" ">
<subfield code="a">Soldier on a Horse</subfield>
<subfield code="u">civil war.jpg</subfield>
</datafield>
<datafield tag="856" ind1=" " ind2=" ">
<subfield code="a">North and South</subfield>
<subfield code="u">civil2.jpg</subfield>
</datafield>
<datafield tag="650" ind1=" " ind2="0">
<subfield code="a">Digital items loaded to Amazon</subfield>
</datafield>
</record>
</collection>
Im Folgenden finden Sie Beispiele für die Verwendung des MARC 787-Felds zum Zuordnen eines Datensatzes zu einer Sammlung:
- Der folgende Datensatz:
<datafield tag="245" ind1="1" ind2="4">
<subfield code="a">The politics of our lives :</subfield>
<subfield code="b">the Raising Her Voice in Pakistan experience /</subfield>
<subfield code="c">Jacky Repila.</subfield>
</datafield>
<datafield tag="787" ind1=" " ind2=" ">
<subfield code="w">8131549940000121</subfield>
</datafield>Wird zu dieser Sammlung hinzugefügt: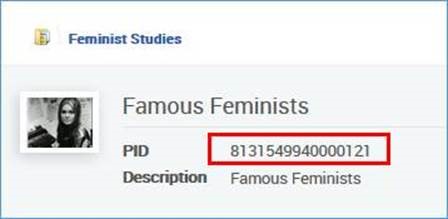 Beispiel 1
Beispiel 1 - Der folgende Datensatz:
<datafield tag="245" ind1="0" ind2="0"><subfield code="a">New South Asian feminisms :</subfield><subfield code="b">paradoxes and possibilities /</subfield><subfield code="c">edited by Srila Roy.</subfield></datafield><datafield tag="787" ind1=" " ind2=" "><subfield code="w">8131549960000121</subfield></datafield>Wird zu dieser Sammlung hinzugefügt:
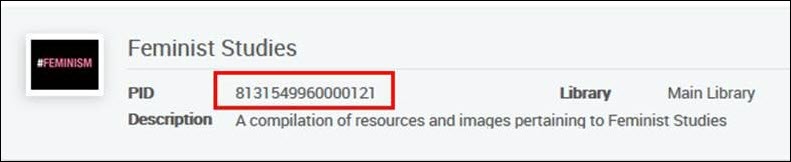 Beispiel 2
Beispiel 2
DC XML Sammlungszuordnung
Wenn Sie für Dublin-Core einen Normalisierungsprozess aktivieren, der die addBibToCollectionNormalizationTask enthält, betrachtet Alma die Felder dc:relation und dcterms:isPartOf. Alma überprüft diese beiden Felder in der folgenden Reihenfolge und ordnet die importierten Datensätze dieser Sammlung zu.
- Nach interner Sammlungs-ID:
<dc:relation>alma:{INST_CODE}/bibs/collections/{COLLECTION_ID}</dc:relation>
- Nach externer Sammlungs-ID:
<dc:relation>beliebiger Text</dc:relation>
- Nach Sammlungsname (nur für Top Level Sammlungen):
<dc:relation>beliebiger Text</dc:relation>
- Nach Standard-Sammlung (nur wenn 1-3 mit keiner bestehenden Sammlung übereinstimmen).
MODS XML Sammlungszuordnung
Erstellen Sie die Normalisierungsregel BIB der Sammlung hinzufügen für MODS. Dies funktioniert wie bei DC und ermöglicht die Zuweisung nach Sammlungs-ID, externer Sammlungs-ID und Sammlungsname:
- <relatedItem@type="host"><identifier>alma:{INST_CODE}/bibs/collections/{COLLECTION_ID}</identifier></relatedItem>
- <relatedItem@type="host"><identifier>{external_id}</identifier></relatedItem>
- <relatedItem@type="host"><identifier>{collection_name - top level only}</identifier></relatedItem>
Vorbereiten der CSV-Metadaten-Datei
Um den Digital Uploader zur Durchführung eines Sammel-Uploads von Dateien zu verwenden, können Sie eine CSV-Datei mit Metadaten für die Titelsätze vorbereiten. Die CSV-Datei ist auf Bestand basierend, das heißt, dass jede Zeile eine Repräsentation darstellt. Jede Zeile kann vollständige bibliografische Informationen haben (die einen neuen Titelsatz erstellen) oder auf einen bestehenden Titelsatz verweisen, nach Match-Regeln abgeglichen, und digitalen Bestand zum verwiesenen Titelsatz hinzufügen. Der Inhalt auf Dateiebene wird in derselben Zeile eingefügt, die den gesamten Dateipfad (entsprechend dem Aufnahme-Ordner) und eine (optionale) Beschriftung enthält. Es werden mehrere Dateien pro Repräsentation unterstützt. Mehrere Repräsentationen pro Titelsatz werden von zwei Zeilen dargestellt, die den gesamten Titelsatz enthalten (mit Regeln, um die Erstellung mehrerer Datensätze zu verhindern). Weisen Sie in diesem Fall den Repräsentationen dieselbe group_id zu, damit Alma weiß, dass die Repräsentationen Teil desselben Titelsatzes sind.
Die CSV-Datei muss in UTF-8-Codierung vorliegen (nicht UTF-8-BOM).
Wenn Sie Metadaten importieren, können Sie CSV-Datensätze mit einem externen System und einer ID zur Zuordnung an eine Sammlung einbringen, in der Spalte collection_external (mit demselben Format wie für MARC-Datensätze). Das Feld ist wiederholbar.
Die CSV kann vier Arten von Feldern enthalten:
- Sammlung – reserviert für die Sammlungszuordnung. Enthält den Namen oder die ID einer Sammlung (collction_name ist nur für Top Level Sammlungen), der der Titelsatz zugeordnet ist. Dieses Feld ist Optional. (Wenn keine Sammlungsfelder existieren, wird der Titelsatz der im MD-Importprofil definierten Sammlung zugeordnet). Wiederholbar.
Wenn das Zielformat im Importprofil auf MARC gesetzt ist, werden die Namen der CSV-Indexeinträge den MARC-Feldern wie folgt zugeordnet:
- collection_name – 787 t
- collection_id – 787 w
- collection_external – 787 o
Wenn das Zielformat im Importprofil auf Dublin Core gesetzt ist, werden die Namen der CSV-Indexeinträge dem Feld dc:relation zugeordnet.Sie müssen die Normalisierungsregel BIB zur Sammlung hinzufügen im Importprofil für den Importprozess festlegen, um die Sammlung anhand dieser Felder zuzuweisen. Andernfalls wird die Standardsammlung verwendet. - Titelsatzebenen-Felder – Es gibt zwei Sub-Typen:
- mms_id und originating_system_id – wird zum Abgleich der Datensätze mit bestehenden Datensätzen verwendet. Beide Felder können existieren, wenn Sie mit mms_id abgleichen und eine originating_system_id hinzufügen wollen (diese wird von den Regeln verarbeitet). mms_id ist nicht-wiederholbar.
- Andere Titelsatz-Felder – werden entsprechend der Tabelle im Developer Netzwerk (https://developers.exlibrisgroup.com/alma/integrations/digital/almadigital/ingest) dem Ziel-MD-Format zugeordnet. Siehe die Tabelle für Details zur Wiederholbarkeit. (Nicht-wiederholbare Felder werden als NR gekennzeichnet.)
- Repräsentationsebenen-Felder – werden den Repräsentations-Eigenschaften zugeordnet. Reservierte Felder sind nicht wiederholbar (ausgenommen rep_note).
- Dateiebenen-Felder. Wiederholbar.
CSV-Inhalt sollte dem Excel-Parsing entsprechend erstellt und bearbeitet werden. Beispielsweise müssen Felder mit Kommas von Anführungszeichen umschlossen werden.
Krieg und Frieden,“Tolstoy, Leo”,1862,...
Alle in MARC-XML unterstützten Zeichen werden in CSV unterstützt.
Ein Beispiel für eine CSV-Datei finden Sie unter Beispiel CSV.
Zuordnung von CSV zu Dublin Core
Wenn Sie CSV als physisches Quellenformat und Dublin Core als Zielformat auswählen, konvertiert Alma die Informationen im CSV-Datensatz in das Format Dublin Core. Die meisten Übereinstimmungen sind intuitiv, zum Beispiel: Beitragender wird dc:contributor zugeordnet. Beachten Sie aber Folgendes:
- MMS_ID sollte nur für den Abgleich mit einer bestehenden Alma MMS-ID verwendet werden. Die Syntax ist: alma:{INST_CODE}/bibs/{MMS_ID}. Dieses Feld wird nicht als Teil des Datensatz-Importes gespeichert.
- ISBN und ISSN werden <dc:identifier xsi:type="dcterms:URI"> zugeordnet, mit dem Präfix urn.
- Originating_system_id wird dc:identifier zugeordnet.
- Für Sammlungen wird collection_id an dc:relation im folgenden Format zugeordnet: <Inst-code>/bibs/collections/<collection id>
- Alle Felder sind wiederholbar und keine Felder sind Pflichtfelder.
- Der Wortschatz vom Typ DCMI ist für Typ empfohlen (mit Ausnahme von Sammlung, dieser sollte nicht verwendet werden).
- Die Zuordnung mehrerer Repräsentationen zu einem Titelsatz wird unterstützt, indem die Repräsentationen derselben group_id zugeordnet werden.
- Codierung von Schemen und Sprachen wird unterstützt. Das Format ISO 639-1 ist für einen Sprachcode mit 2 Buchstaben erforderlich und ISO 639-2/3 für einen Sprachcode mit 3 Buchstaben.
Die Syntax ist folgende:
- Nur Codierung – property.schema (zum Beispiel dc:subject.dcterms:LCSH)
- Nur Sprache – property lang=\{2 or 3 letter code} (zum Beispiel dc:subject lang=en)
- Sowohl Codierung als auch Sprachen – property.schema lang=\{2 or 3 letter code} (zum Beispiel dc:subject.dcterms:LCSH lang=en)
Vorbereiten der Excel-Metadaten-Datei
Für Informationen zum Vorbereiten der Excel-Metadaten-Datei siehe Datensätze mit CSV- oder Excel-Dateien importieren.
Hinzufügen einer Miniaturbild-Datei zur Aufnahme
Sie können eine Miniaturbild-Datei zur Aufnahme hinzufügen (nur im Format jpg, png oder gif), mit demselben Namen wie die digitale Datei, mit der Endung .thumb. Beispiel:
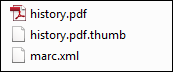
Miniaturbild-Datei
Dies ermöglicht es Alma, das .thumb-Bild als Miniaturbild für die entsprechende Datei zu speichern. Das Miniaturbild erscheint in den Ergebnissen der Bestandssuche, im digitalen Viewer und in Primo.
Um Ihre Datei erfolgreich mit der Erweiterung .thumb umzubenennen, müssen Sie die Dateierweiterungen im Windows-Datei-Explorer aktiviert haben. Andernfalls behält die Datei ihr Format bei und fügt dem Namen die Endung .thumb hinzu. Um Dateinamenerweiterungen im Datei-Explorer anzuzeigen, wählen Sie das Dropdown-Menü Ansicht, dann Anzeigen und anschließend die Option Dateinamenerweiterungen.

Hinzufügen einer Volltext-Datei zur Aufnahme
Sie können der Aufnahme eine Volltextdatei im einfachen oder im ALTO-Format mit demselben Namen wie die digitale Datei mit der Erweiterung .text.plain oder .text.alto hinzufügen. Auf diese Weise können Sie eine Textsuche für das Bild im Book Reader Viewer durchführen.
Sie können die OCR-Dateien während der Aufnahme mit Ihren anderen digitalen Dateien verknüpfen..
Wenn Sie eine .tif-Datei namens abc.tif und eine OCR-Datei vom Typ „plain“ für diese .tif-Datei haben, bereiten Sie den Aufnahmeordner wie folgt vor:
<folder name>
abc.tif
abc.tif.text.plain
Wenn Sie eine CSV-Datei für die Aufnahme verwenden, fügen Sie den Ordner mit den Dateien wie oben beschrieben hinzu.
Sie müssen die OCR-Dateinamen nicht in der CSV-Datei auflisten.
Wenn Sie eine .tif-Datei namens abc.tif und eine OCR-Datei vom Typ „plain“ für diese .tif-Datei haben, bereiten Sie den Aufnahmeordner wie folgt vor:
<folder name>
abc.tif
abc.tif.text.plain
Wenn Sie eine CSV-Datei für die Aufnahme verwenden, fügen Sie den Ordner mit den Dateien wie oben beschrieben hinzu.
Sie müssen die OCR-Dateinamen nicht in der CSV-Datei auflisten.