
Criar Conteúdo Digital em Lote
Para gerenciar recursos digitais, você deve ter as seguintes funções:
- Operador de Acervo Digital
- Operador de Acervo Digital Estendido (necessário para operações de exclusão)
- Operador de Acervo de Coleções (necessário ao adicionar uma nova representação digital)
Criar Conteúdo Digital em Lote
O fluxo para uploads em lote no Alma consiste das seguintes etapas:
- Configurar um perfil de importação digital que informa ao Alma como processar recursos digitais ao realizar um upload em lote no Alma. Para mais informações, veja Gerenciar Perfis de Importação.
- Preparar um arquivo de metadados dos registros bibliográficos que o perfil de importação usará ao importar os arquivos. Para mais informações, veja Preparar o Arquivo XML de Metadados e Preparar o Arquivo CSV de Metadados.
- Fazer upload de arquivos com seus metadados no Alma usando o Digital Uploader. Para mais informações, veja Fazer Upload de Arquivos no Alma.
Fazer Upload de Arquivos no Alma
Você pode usar o Digital Uploader do Alma para fazer upload de arquivos em lote no Alma. Os títulos (registros bibliográficos) são colocados na coleção selecionada ao fazer o upload. Para mais informações sobre coleções, veja Gerenciar Coleções.
Cada grupo de arquivos preparado no Alma para upload é chamado de ingest.
A preparação do ingest é feita em quatro etapas:
- Criação de um ingest
- Adicionar arquivos ao ingest (incluindo arquivos de MD)
- Upload dos arquivos
- Envio do ingest
As informações da pasta do ingest ficam no armazenamento local do seu navegador. Portanto, se você acessar o Uploader de outro navegador (ou do mesmo navegador, mas conectado como outro usuário) ou se você limpar o armazenamento local do navegador, não verá as pastas de ingest criadas anteriormente. Isso não afeta os dados já enviados.
Para fazer upload e enviar arquivos para o Alma:
- Abra a página do Digital Uploader (Recursos > Ferramentas Avançadas > Digital Uploader).
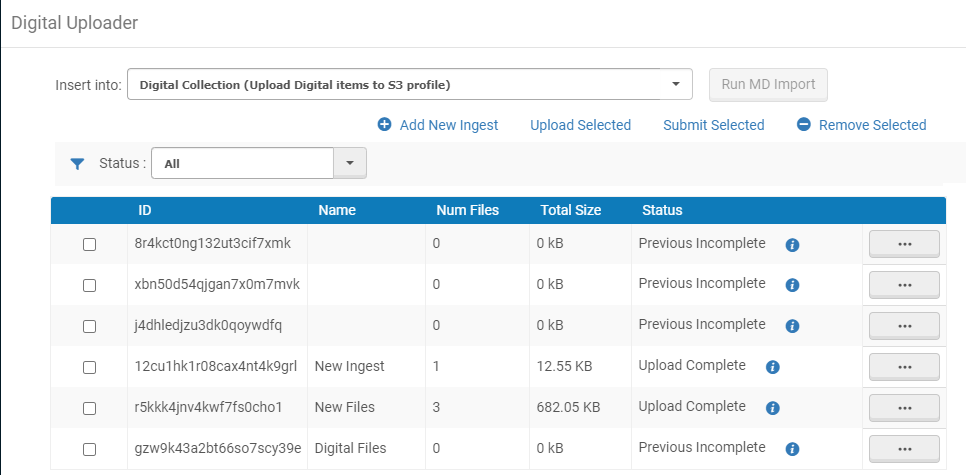
- Na lista dropdown Inserir em, selecione a coleção na qual serão colocados os arquivos e o perfil de importação digital que define a forma como os arquivos são importados para a coleção.
- Adicione arquivos que serão enviados para o Alma usando um dos seguintes:
- Arrastar e soltar - Adicione um ingest arrastando e soltando uma pasta na Lista de Ingests e adicione arquivos a um ingest existente arrastando e soltando-os em um ingest da Lista de Ingests.No momento, a função de arrastar e soltar pastas tem suporte somente para Chrome. Para arquivos, ela funciona em todos os navegadores suportados.
- Com a caixa Adicionar Novo Ingest:
- Na página Digital Uploader, selecione Adicionar Novo Ingest. Aparecerá o seguinte:
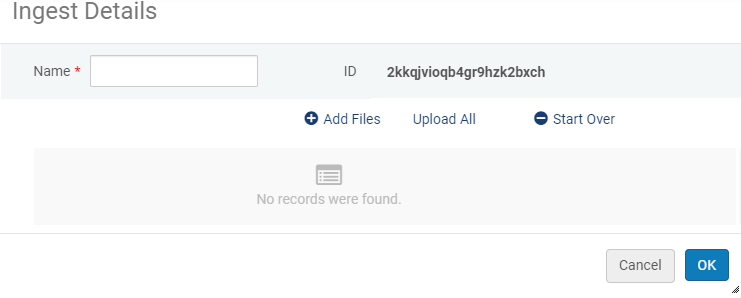 Adicionar Novo Ingest
Adicionar Novo Ingest - Insira um nome para o ingest.
- Clique em Adicionar Arquivos e selecione os arquivos cujo upload deseja fazer. O nome e o tamanho do arquivo e, se possível, um thumbnail gerado automaticamente para os seguintes formatos de arquivo aparecem na caixa de diálogo de Ingest.
- jpg
- png
- mp4
- wav
- m4v
- doc
- ppt
- docx
- pptx
- jpeg2000
- Cada arquivo pode ter no máximo 1GB.
- Você pode incluir um máximo de 1000 arquivos em um único ingest.
- O upload de ingests acima desse limite pode ser feito diretamente no armazenamento do S3. Para mais informações, consulte a Developers Network.
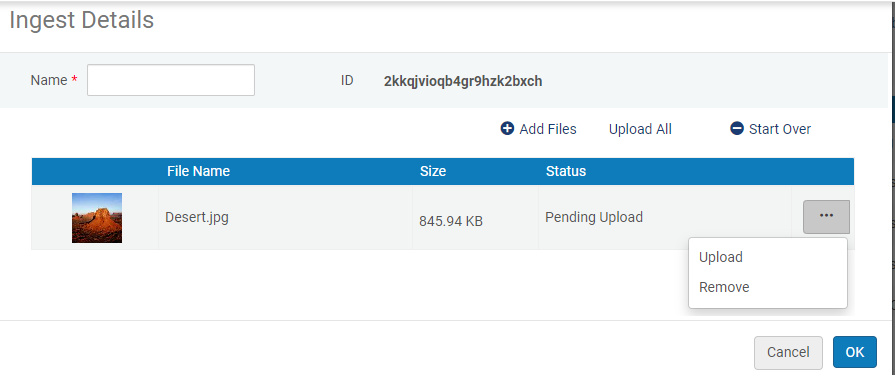 Iniciar Ingest
Iniciar Ingest- Você pode incluir um arquivo de thumbnail no ingest, que aparecerá nos resultados da busca no repositório e no Visualizador Digital, por exemplo. Para mais informações, veja Adicionar um Arquivo de Thumbnail ao Ingest.
- Você pode incluir um arquivo de legendas no formato .vtt, com o mesmo nome do arquivo de vídeo no ingest, para exibir as legendas ao reproduzir o vídeo. Para mais informações, veja O Novo Visualizador Digital.
- Adicione um ou mais arquivos de metadados para o ingest (veja Preparar o Arquivo XML de Metadados ou Preparar o Arquivo CSV de Metadados).Se você não adicionar um arquivo de metadados ao ingest, um ícone de aviso
 aparecerá na lista de ingests.
aparecerá na lista de ingests. - Para fazer upload de um arquivo no ingest, selecione Upload. Para fazer upload de todos os arquivos ao mesmo tempo no ingest, selecione Fazer Upload de Todos. Para remover os arquivos e começar de novo, clique em Recomeçar.
- Selecione OK para retornar à página do Digital Uploader. Veja Digital Uploader.
- Na página Digital Uploader, selecione Adicionar Novo Ingest. Aparecerá o seguinte:
- O ID do Ingest
- O nome do Ingest
- O número de arquivos no ingest.
- O tamanho total do ingest
- O status do ingest. Os seguintes status são possíveis:
- Novo - O ingest não contém nenhum arquivo.
- Upload Pendente - O ingest não teve o upload feito.
- Upload Concluído - O ingest não foi enviado.
- Enviado - O ingest foi enviado.
- Para remover um arquivo de um ingest, clique no botão de ações na lista de ações de linha do ingest e, então, selecione Remover.
- Para remover um ingest, selecione o ingest e clique em Remover Selecionados.
- Arrastar e soltar - Adicione um ingest arrastando e soltando uma pasta na Lista de Ingests e adicione arquivos a um ingest existente arrastando e soltando-os em um ingest da Lista de Ingests.
- Para fazer upload de ingests, selecione os ingests e clique em Fazer Upload de Selecionados.
- Para enviar ingests para processamento, selecione os ingests que deseja enviar e clique em Enviar Selecionados.
- A etapa de envio é necessária para que você possa continuar adicionando arquivos com segurança ao seu ingest, e não é processada até que você selecione Enviar.
- O campo Nome do Arquivo de Metadados no perfil de importação associado ao ingest deve conter o caminho e o nome do arquivo de metadados corretos para que o ingest seja enviado.
- Normalmente, o serviço de Importação de MD é executado de acordo com um agendamento. Para executar o serviço de importação de MD manualmente, selecione Executar Serviço de Importação.O serviço de Importação de MD será executado e o ingest será processado.
Arquivos com mais de 30 dias (exceto arquivos bloqueados) são excluídos pelo serviço de manutenção semanal.
Preparar o Arquivo XML de Metadados
A fim de usar o Digital Uploader para realizar um upload de arquivos em lote, você pode preparar um arquivo XML no formato MARC ou DC com metadados para os registros bibliográficos. Cada arquivo de metadados pode conter informações para múltiplos registros bibliográficos. O Alma cria os registros bibliográficos e as representações para os arquivos com as informações contidas neste arquivo de metadados.
Os elementos do registro no arquivo devem ser agrupados em um único elemento de coleção.
O tipo de informação necessária no arquivo de metadados depende da configuração do perfil de importação. Por exemplo, se você configurou o perfil de importação para buscar pelo nome do arquivo no subcampo u do campo MARC 856, o arquivo de metadados deve conter as informações neste campo.
Caso o registro bibliográfico contenha informações de coleção, o registro será atribuído à coleção indicada. Caso contrário, o registro será atribuído à coleção selecionada como Atribuição de Coleção Padrão no perfil de importação digital.
Atribuição de Coleção MARC XML
Para registros MARC, se você ativar um processo de normalização que contenha addBibToCollectionNormalizationTask, a importação atribuirá o registro a uma coleção de acordo com a seguinte prioridade de regras:
- Se o MARC 787$w contiver um ID de coleção do Alma válido, o registro será atribuído a esta coleção.
- Se o MARC 787$o contiver os valores dos campos de sistema externo e de ID externo, conforme configurado em uma coleção existente do Alma, o registro será atribuído a esta coleção. O campo deve conter o sistema e o ID no seguinte formato: ({system}){ID}, por exemplo, (Rosetta)123454321 (semelhante à estrutura do campo 035).
- Se o MARC 787$t contiver o nome de uma coleção geral do Alma, o registro será atribuído a esta coleção.
- Se nenhuma das opções acima se aplicar, o registro será atribuído à coleção do Alma definida como padrão para o perfil de importação.
Ao fazer upload de um arquivo de metadados com um único registro, o campo 856 não é necessário. O registro criado inclui todos os arquivos que estão na pasta de ingest.
Veja abaixo um exemplo de um arquivo XML de metadados:
<?xml version="1.0" encoding="UTF-8" ?>
<collection>
<record>
<leader>01139cam a2200277 a 4500</leader>
<controlfield tag="001">ocm27832725113 </controlfield>
<controlfield tag="003">OCoLC</controlfield>
<controlfield tag="005">20131108731707.4</controlfield>
<controlfield tag="008">970910r19451931pk b 000 0 eng </controlfield>
<datafield tag="035" ind1=" " ind2=" ">
<subfield code="a">(OCoLC)27832725113</subfield>
</datafield>
<datafield tag="100" ind1="1" ind2=" ">
<subfield code="a">Representation of rec 1</subfield>
<subfield code="b">jpg files</subfield>
</datafield>
<datafield tag="245" ind1="1" ind2="2">
<subfield code="a">Record 1 - Civil war</subfield>
</datafield>
<datafield tag="856" ind1=" " ind2=" ">
<subfield code="a">Soldier on a Horse</subfield>
<subfield code="u">civil war.jpg</subfield>
</datafield>
<datafield tag="856" ind1=" " ind2=" ">
<subfield code="a">North and South</subfield>
<subfield code="u">civil2.jpg</subfield>
</datafield>
<datafield tag="650" ind1=" " ind2="0">
<subfield code="a">Digital items loaded to Amazon</subfield>
</datafield>
</record>
</collection>
<collection>
<record>
<leader>01139cam a2200277 a 4500</leader>
<controlfield tag="001">ocm27832725113 </controlfield>
<controlfield tag="003">OCoLC</controlfield>
<controlfield tag="005">20131108731707.4</controlfield>
<controlfield tag="008">970910r19451931pk b 000 0 eng </controlfield>
<datafield tag="035" ind1=" " ind2=" ">
<subfield code="a">(OCoLC)27832725113</subfield>
</datafield>
<datafield tag="100" ind1="1" ind2=" ">
<subfield code="a">Representation of rec 1</subfield>
<subfield code="b">jpg files</subfield>
</datafield>
<datafield tag="245" ind1="1" ind2="2">
<subfield code="a">Record 1 - Civil war</subfield>
</datafield>
<datafield tag="856" ind1=" " ind2=" ">
<subfield code="a">Soldier on a Horse</subfield>
<subfield code="u">civil war.jpg</subfield>
</datafield>
<datafield tag="856" ind1=" " ind2=" ">
<subfield code="a">North and South</subfield>
<subfield code="u">civil2.jpg</subfield>
</datafield>
<datafield tag="650" ind1=" " ind2="0">
<subfield code="a">Digital items loaded to Amazon</subfield>
</datafield>
</record>
</collection>
Veja abaixo exemplos de uso do campo MARC 787 para atribuir um registro a uma coleção:
- O seguinte registro:<datafield tag="245" ind1="1" ind2="4">
<subfield code="a">The politics of our lives :</subfield>
<subfield code="b">the Raising Her Voice in Pakistan experience /</subfield>
<subfield code="c">Jacky Repila.</subfield>
</datafield>
<datafield tag="787" ind1=" " ind2=" ">
<subfield code="w">8131549940000121</subfield>
</datafield>Será adicionado a esta coleção: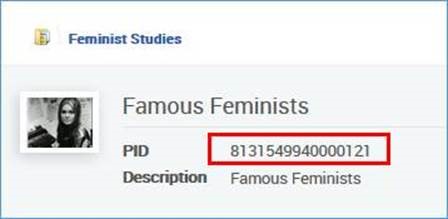 Exemplo 1
Exemplo 1 - O seguinte registro:<datafield tag="245" ind1="0" ind2="0"><subfield code="a">New South Asian feminisms :</subfield><subfield code="b">paradoxes and possibilities /</subfield><subfield code="c">edited by Srila Roy.</subfield></datafield><datafield tag="787" ind1=" " ind2=" "><subfield code="w">8131549960000121</subfield></datafield>Será adicionado a esta coleção:
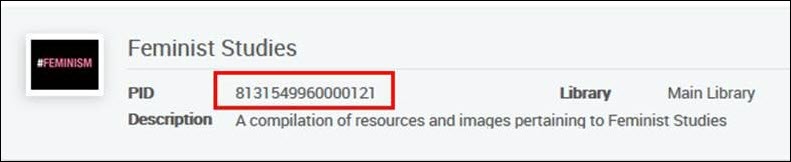 Exemplo 2
Exemplo 2
Atribuição de Coleção DC XML
Para DC, se você ativar um processo de normalização que contenha addBibToCollectionNormalizationTask, o Alma busca nos campos dc:relation e dcterms:isPartOf. O Alma verificará cada um desses campos na seguinte ordem e atribuirá os registros importados à coleção.
- Por ID interno da coleção:<dc:relation>alma:{INST_CODE}/bibs/collections/{COLLECTION_ID}</dc:relation>
- Por ID externo da coleção:<dc:relation>any text</dc:relation>
- Por nome da coleção (somente geral):<dc:relation>any text</dc:relation>
- Por coleção padrão (somente se 1-3 não corresponderem a uma coleção existente).
Atribuição de Coleção MODS XML
Crie a regra de normalização Adicionar BIB à Coleção para MODS. Isso funciona da mesma forma que para DC, permitindo a atribuição por ID da Coleção, ID Externo da Coleção e Nome da Coleção:
- <relatedItem@type="host"><identifier>alma:{INST_CODE}/bibs/collections/{COLLECTION_ID}</identifier></relatedItem>
- <relatedItem@type="host"><identifier>{external_id}</identifier></relatedItem>
- <relatedItem@type="host"><identifier>{collection_name - top level only}</identifier></relatedItem>
Preparar o Arquivo CSV de Metadados
A fim de usar o Digital Uploader para realizar um upload de arquivos em lote, você pode preparar um arquivo CSV com metadados para os registros bibliográficos. O arquivo CSV é baseado em acervo, o que significa que cada linha equivale a uma representação. Cada linha pode ter informações bibliográficas completas (o que gera um novo registro bibliográfico) ou pode fazer referência a um registro bibliográfico existente, com equivalência feita pelas regras de equivalência, e adicionar acervo digital ao registro bibliográfico referenciado. O conteúdo no nível do arquivo é incluído na mesma linha, contendo o caminho completo do arquivo (relativo à pasta do ingest) e uma etiqueta (opcional). São suportados múltiplos arquivos por representação. Múltiplas representações por registro bibliográfico são representadas por duas linhas contendo o registro bibliográfico completo (com regras para evitar a criação de múltiplos registros). Nesse caso, atribua às representações o mesmo group_id para que o Alma saiba que as representações fazem parte do mesmo registo bibliográfico.
O arquivo CSV deve estar na codificação UTF-8 (não UTF-8-BOM).
Ao importar metadados, você pode fornecer registros CSV com um sistema e um ID externos na coluna collection_external (com o mesmo formato dos registros MARC) para atribuí-los a uma coleção. Este campo é repetível.
O CSV pode conter quatro tipos de campos:
- Coleção - reservado para atribuição de coleção. Contém o nome ou ID de uma coleção (collection_name é somente para coleções gerais) à qual o registro bibliográfico está atribuído. Este campo é opcional. (Se não existirem campos de coleção, o registro bibliográfico é atribuído à coleção padrão definida no perfil de importação de MD). Repetível.Se o formato de destino estiver definido como MARC no perfil de importação, os nomes dos cabeçalhos CSV serão mapeados para os campos MARC da seguinte forma:
- collection_name - 787 t
- collection_id - 787 w
- collection_external - 787 o
Se o formato destino estiver definido como Dublin Core no perfil de importação, os nomes dos cabeçalhos CSV serão mapeados para o campo dc:relation.Você deve configurar a regra de normalização Adicionar BIB à coleção no perfil de importação do serviço de importação para atribuir a coleção de acordo com esses campos. Caso contrário, a coleção padrão será usada. - Campos do nível do registro bibliográfico - Existem dois subtipos:
- mms_id e originating_system_id - usado para equivalência de registros com registros existentes. Ambos os campos podem existir, e você pode fazer a equivalência por mms_id e adicionar um originating_system_id (isto é processado pelas regras). O mms_id não é repetível.
- Outros campos de registro bibliográfico - mapeia para o formato de MD destino de acordo com a tabela na Developers Network (https://developers.exlibrisgroup.com/alma/integrations/digital/almadigital/ingest). Veja a tabela para detalhes sobre repetição de campos. (Campos não repetíveis são marcados como NR.)
- Campos de nível da representação - mapeia para propriedades da representação. Campos reservados não são repetíveis (exceto rep_note).
- Campos de nível do arquivo. Repetível.
O conteúdo CSV deve ser criado e processado de acordo com o parsing do Excel. Por exemplo, campos com vírgulas devem ser colocados entre aspas:
Guerra e Paz,“Tolstoy, Leo”,1862,...
Todos os caracteres suportados em MARC XML são suportados em csv.
Para exemplo de um arquivo CSV, veja Exemplo CSV.
Mapeamento de CSV para Dublin Core
Quando você seleciona CSV como formato físico da fonte e Dublin Core como formato destino, o Alma converte as informações do registro CSV para o formato Dublin Core. A maioria das equivalências são intuitivas, por exemplo: contributor é mapeado para dc:contributor. Entretanto, observe o seguinte:
- MMS_ID deve ser usado somente para equivalência com um ID do MMS existente no Alma. A sintaxe é: alma:{INST_CODE}/bibs/{MMS_ID}. Este campo não é armazenado como parte do registro importado.
- ISBN e ISSN são mapeados para <dc:identifier xsi:type="dcterms:URI"> com o prefixo urn.
- Originating_system_id é mapeado para dc:identifier.
- Para coleções, collection_id é mapeado para dc:relation no seguinte formato: <Inst-code>/bibs/collections/<collection id>
- Todos os campos são repetíveis e nenhum é obrigatório.
- Vocabulário de tipo DCMI é recomendado para tipo (exceto para coleções, em que não deve ser usado).
- O mapeamento de múltiplas representações para um único registro bibliográfico é suportado atribuindo o mesmo group_id às representações.
- Esquemas de codificação e idiomas são suportados. O formato ISO 639-1 é necessário para um código de idioma de 2 letras e ISO 639-2/3 para um código de 3 letras.
A sintaxe é a seguinte:
- somente codificação - property.schema (por exemplo, dc:subject.dcterms:LCSH)
- Somente idiomas - property lang=\{2 or 3 letter code} (por exemplo, dc:subject lang=en)
- codificação e idiomas - property.schema lang=\{2 or 3 letter code} (por exemplo, dc:subject.dcterms:LCSH lang=en)
Preparar o Arquivo Excel de Metadados
Para informações sobre como preparar o arquivo Excel de metadados, veja Importar Registros com Arquivos CSV ou Excel.
Adicionar um Arquivo de Thumbnail ao Ingest
Você pode adicionar um arquivo de thumbnail ao ingest (somente nos formatos jpg, png, gif), de mesmo nome do arquivo digital, com a extensão .thumb. Por exemplo:
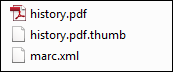
Arquivo de Thumbnail
Isso permite que o Alma armazene a imagem .thumb como um thumbnail do respectivo arquivo. O thumbnail aparecerá nos resultados da busca no repositório, no Visualizador Digital e no Primo.
Adicionar um Arquivo de Texto Completo ao Ingest
Você pode adicionar um arquivo de texto completo ao ingest, de mesmo nome do arquivo digital, em formato de texto simples ou ALTO com uma extensão .text.plain ou .text.alto. Isso permite que você faça buscas de texto para a imagem no Visualizador Book Reader.