
Smart Expansion via CSV or Excel
Overview
For an overview of the algorithm used to match authors see Author Matching Algorithm.
For details on the Asset Matching algorithm that is that is invoked after adding assets to Esploro, see Esploro Asset Matching Rules.
Configuring Smart Expansion via CSV/Excel
- Prepare the spreadsheet as described in CSV/Excel File Format.
- Go to Repository > Manage Profiles.
- Select the Comma Separated Values (CSV) Excel File profile. The Smart Expansion Profiles page displays.
- Leave the Active checkbox as marked.
- In the Asset Approval section select whether the asset will be automatically approved or will require manual intervention.
- Never automatically approve the asset: The asset is never approved. Operators must approve before the asset will display in the public portal and profiles (similar to a manual deposit).
- Always automatically approve the asset: The asset is always approved and displays in the portal upon load. It displays in Researcher Profiles when the
author-researcher match is approved. An approved asset displays in the portal and in the active researcher profile. It displays in affiliated co-author profiles if the match is approved. - Conditionally approve the asset: The asset is approved only if the specified conditions are met. The following conditions are possible:
- If asset type is any of: Multiple asset types can be selected.
AND/OR - If asset has a DOI or PMID
Author matching tasks are created for all asset authors. Assets that are pending approval can be approved in the task list at Repository > Author Matching Approval Task List and in the Asset Approval page at Repository > Smart Harvesting > Asset Approval (see here for more information).In addition, these assets can be accessed via the Smart Expansion via CSV – Asset approval task in the Tasks Widget (see Managing Widgets).If the researcher could not be found as an author he or she is added with the status "Added by System".
- If asset type is any of: Multiple asset types can be selected.
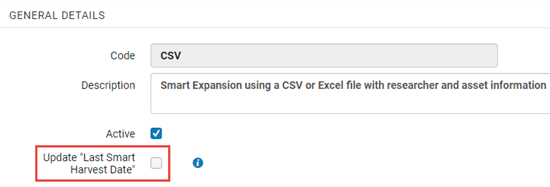
- Select the Update "Last Smart Harvest Date" to have Smart Harvesting run in an ongoing mode. It is recommended to check this option unless the input file includes a partial list of researcher publications. Note that out-of-the-box this option is selected.
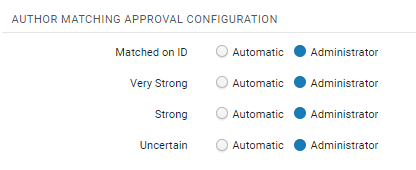
- The AUTHOR MATCHING APPROVAL CONFIGURATION options allow you to set the level of certainty at which assets will be automatically added to the researcher profile. For more information see Author Matching Algorithm.
Sources for Smart Expansion via CSV/Excel
Smart Expansion can bring information from various sources:
- ORCID (see ORCID Integration for more information)
- Pivot (relevant during the implementation stage at the customer)
Running Smart Expansion via CSV/Excel
- Upload the file in the File field in the Run section.
- Select the Notify Researchers checkbox in order to notify researchers about new assets that were added to their profile. Note that this option is only enabled when the NEW ASSETS ADDED TO RESEARCHER PROFILE NOTIFICATION job is active. See New Research Outputs Added to Profile Letter.
- Select Run Now. A message will display to let you know the job started.
- You can view the jobs at Admin > Monitor jobs.
- Select the Scheduled tab to view scheduled jobs, SP Scheduled to view jobs scheduled for a release, Running to view the jobs in progress and History to view previously run jobs.
- You can also view jobs by going to the list of Smart Harvesting jobs from Repository > Manage Profiles, and selecting the Monitor Captures button which takes you to the Monitor Captures page.
Monitoring the Running Jobs in the Monitor Captures Page
This page displays a list of the Smart harvesting job runs, and can be accessed from Repository > Smart Harvesting > Manage Profiles and selecting Monitor Captures.
There are (New for August) four jobs that run, and are displayed in the monitoring page. All jobs should be completed before access to the approval tasks list.

The Status column displays the status of the current running job. When the job finishes and the next job starts, the status of the next job is displayed.
The operator that invoked the Smart Harvesting run should get an email with a Job Report, once all the jobs have finished running. Once the job has completed, the author matching approval tasks for the captured assets can be displayed in the Author Matching Approval Task List.
Job Report for Smart Expansion via Excel/CSV
To view the report, in the Monitor Captures page, select View from the row actions menu, or select the job name. To view the job events see CSV/Excel Job Report below.
CSV/Excel File Format
| Column Name | Description | Mandatory | Notes |
|---|---|---|---|
|
USERID
|
Researcher ID |
Y |
ID in the user platform |
|
TITLE |
Title |
Y unless there is a DOI or PMID |
|
|
DOI |
DOI |
Y unless there is title |
|
|
PMID |
PMID |
Y unless there is title |
|
| WOSID | Web of Science ID | Y unless there is a title | |
| SCOPUS | Scopus ID | Y unless there is a title |
How it Works
Workflow
The following describes the main workflow for Smart Expansion via CSV/Excel.
- Match Assets: Match assets in the input file to remove duplicates. This can happen because multiple affiliated researchers exist for the same asset.
- Fetch Records: Fetch records from CDI and deduplicate the results. This is needed because CDI may have multiple records for the same asset. It can also happen because the deduplication in stage 1 failed due to lack of data.
- Author Matching: The "active" researcher is automatically approved and the rank is marked as Matched with ID. If for some reason the job cannot find the active researcher in the list of asset authors, the researcher is added by the system. The author match in this case is "Added by System" and considered approved. Matching approval for Co-authors is per the configuration in the profile.
- Update Last Smart Harvesting Date: If enabled in profile configuration, the "Last Smart Harvesting Date" is updated from beginning of last publication year of all the assets loaded for the researcher. Therefore if the last year is 2020, it should be 20200101. This will ensure that researchers are including in ongoing Smart Harvesting.
- Run Jobs: The merge non-affiliated researchers and delete redundant non-affiliated researchers (i.e., non-affiliated researchers with no assets) jobs are run. See also Working with Smart Harvesting.
How the Data is Used by the Job
- Deduping rows - Since a row is added per researcher and researchers collaborate, the job tries to match rows and work on them together. This is done first based on the data in the files and then again based on the data from the records fetched from CDI (in case there is insufficient data).
- Fetching records from CDI.
- Future use – validation of the input. This can be important if the quality of the source data is low.
Deduping Records in the CSV
The records (each row) are deduped based on the following keys:
- DOI + PUBYEAR or year from PUBDATE
- PMID + PUBYEAR or year from PUBDATE
- Normalized title + PUBYEAR or year from PUBDATE
- Normalized title (as long as it is > 4 words ) + normalized Publication title
- Normalized title (as long as it is > 4 words) + ISSN
Fetching Records from CDI
If the record has a DOI or PMID the identifier is used. If there is no DOI or PMID, the query to CDI is based on the title and the researcher name.
CSV/Excel Job Report
The report includes the following events:
- Smart Expansion ran for researcher (N) -> the number and list of valid researchers included in the CSV, i.e., for whom a matching ID was found.
- Records dedup - Stage 1 (N) - Number of records deduped within the CSV. The event includes the row numbers.
- Records dedup – Stage 2 (N) – Number of records deduped after records are fetched from CDI. The event includes row number with the asset ID created from one of the rows.
- Records not found / Found only in restricted sources / Unsupported asset type(0).
- Records found but could not be validated — The number and list of records which were found in CDI but could not be validated. The event includes metadata from the row - (row, title, DOI). If there are duplicate rows they are included in brackets.
- Records not imported -- matched with asset/provisional asset. Number, list and reason of records that matched with an existing asset/task.
- Skipped records – too many authors (N)
- Invalid rows (N) - number and list of rows with invalid data – Researcher could not be found for the ID or the row could not be validated.
- Total assets imported (N) – number of assets imported. The Event includes the asset ID and title.
- Automatically approved author matches (N) – number of automatically approved author-researcher matches excluding active researchers.
- Assets with missing researcher/added by system
- New non-affiliated researchers created (N) - number and list
- General error (N)
- Python is down
- Unexpected errors
Author Matching Approval & Asset Approval for Smart Expansion via Alma
This process works in the same way as for Smart Expansion via Citations. See Smart Expansion via Citations for more information.