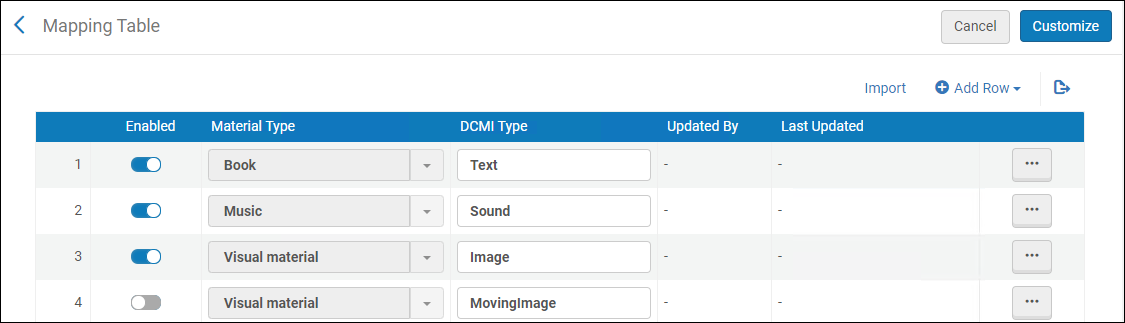
Configurer le catalogage
- Administrateur de catalogue
Ce rôle est nécessaire pour modifier des profils basés sur MARC à l'aide des packs d'extension. Ajouter, supprimer et contribuer des fichiers de pack d'extension au niveau de la Zone de communauté nécessite des autorisations spéciales attribuées à ce rôle. Si vous ne pouvez pas travailler avec ces fichiers de pack d'extension, contactez l'assistance client pour vous faire attribuer ces autorisations.)
- Administrateur général du système
Cette section concerne la configuration de l'environnement des métadonnées. Les profils configurés dans la section Profils actifs de la page Liste de configuration des métadonnées définissent l'environnement de catalogage que vous utilisez lorsque vous travaillez dans l'Éditeur de métadonnées. Les profils bibliographiques disponibles et configurables sur la page Liste de configuration des métadonnées sont déterminés par le Registre actif défini par Ex Libris pour votre institution. Les registres actifs suivants peuvent être configurés pour Alma :
- MARC 21
- UNIMARC
- KORMARC
- CNMARC
- Dublin Core
- MODS
- ETD
- Profils d'application DC
- Quels champs et sous-champs de métadonnées apparaissent dans l'Éditeur de métadonnées et s'ils sont répétables
- Si les sous-champs utilisent un vocabulaire contrôlé
- Processus de normalisation
- Processus de validation
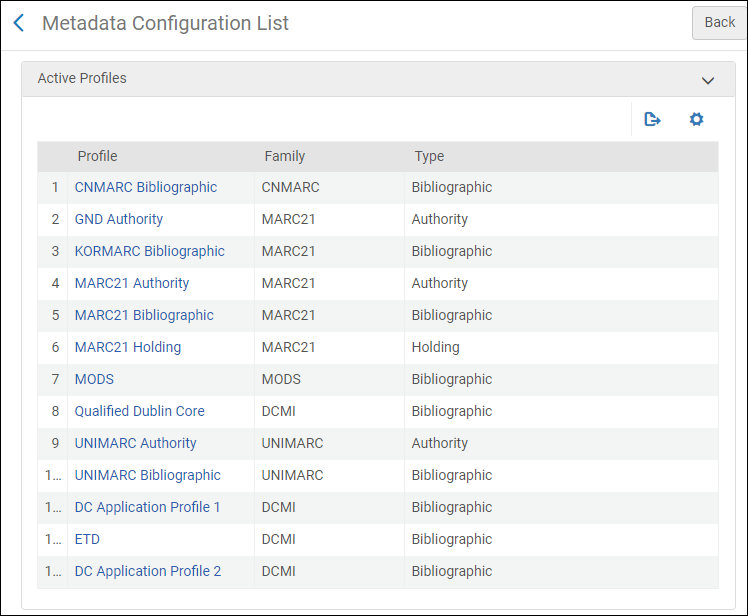
Consulter les détails d'un profil de métadonnées
- Informations générales (Profils d'application DC uniquement)
- Champs
- Formulaires
- Processus de normalisation
- Processus de validation
- Liste des profils de gestion des erreurs
- Autres paramètres
- Sur la page Liste de configuration des métadonnées (Menu de configuration > Ressources > Catalogage > Configuration des métadonnées), cliquez sur le lien (par exemple Bibliographique MARC 21) du profil que vous voulez consulter. La page Détails du profil s'ouvre.
 Page Détails du profil Bibliographique MARC 21
Page Détails du profil Bibliographique MARC 21 - Sélectionnez Consulter dans la liste des actions sur la ligne pour voir les détails du profil sélectionné. La page Détails du champ apparait.
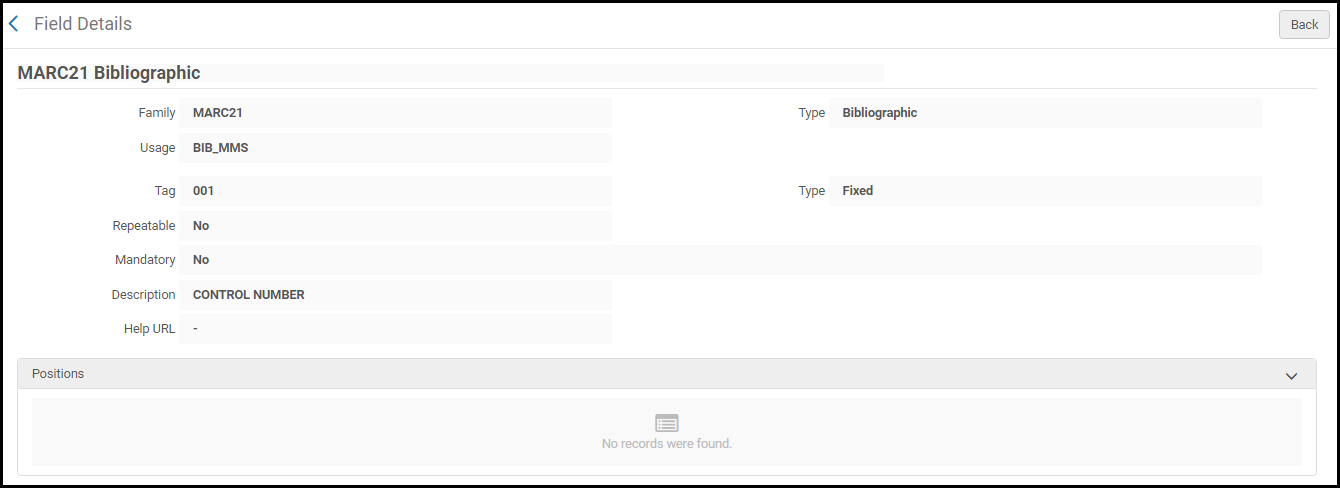 Page Détails du champ
Page Détails du champ
Modifier les détails de profil
- Informations générales (Profils d'application DC uniquement) – pour plus d'informations, voir Profils d'application DC - Onglet Informations générales
- Champs – Voir Modifier les champs.
- Formulaires - Voir Travailler avec des formulaires.
- Processus de normalisation – Voir Travailler avec des processus de normalisation.
- Processus de validation – Voir Modifier les processus de validation.
- Liste des profils de gestion des erreurs – Voir Travailler avec les profils de gestion des erreurs.
- Autres paramètres - voir Configurer d'autres paramètres.
Modifier les champs
- Sur la page Liste de configuration des métadonnées (Menu de configuration > Ressources > Catalogage > Configuration des métadonnées), cliquez sur le lien (par exemple Bibliographique MARC 21) du profil que vous voulez modifier. La page Détails du profil s'ouvre.
- Pour les champs fixes qui proposent un formulaire pour le catalogage dans l'Éditeur de métadonnées, activez l'option Forcer la modification du formulaire pour que le formulaire soit bien utilisé lors du catalogage. Lorsque cette fonctionnalité est activée pour un champ, le catalogage par texte libre n'est pas en option dans l'Éditeur de métadonnées.
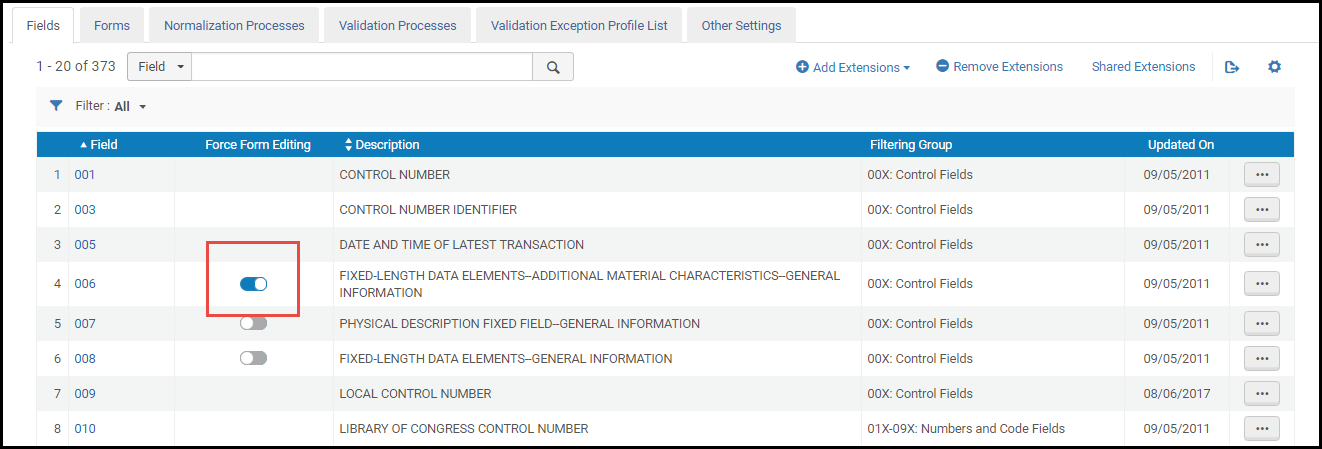 Barre de défilement Forcer la modification du formulaireVoir L'interface utilisateur d'Alma pour plus d'informations sur l'utilisation des barres de défilement.
Barre de défilement Forcer la modification du formulaireVoir L'interface utilisateur d'Alma pour plus d'informations sur l'utilisation des barres de défilement. - Sélectionnez Personnaliser (ou Modifier) dans la liste des actions possibles sur la ligne pour le champ que vous voulez modifier. La page Détails du champ apparaît.
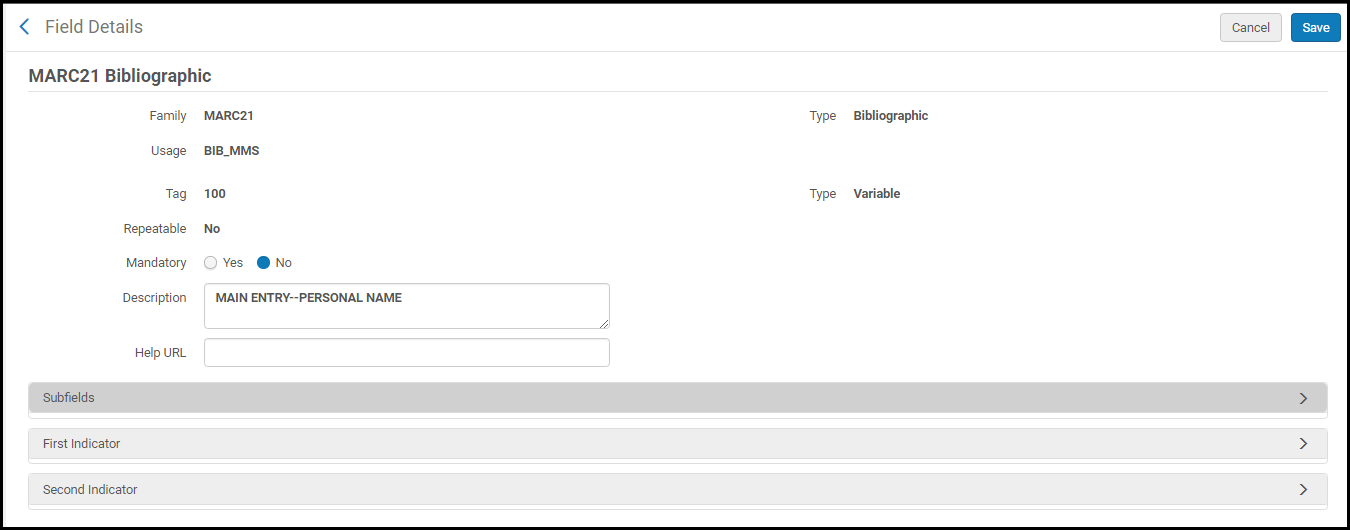 Option Personnaliser (Modifier) sur la page Détails du champ
Option Personnaliser (Modifier) sur la page Détails du champ - Modifiez les options de champ suivantes (qui peuvent varier) pour répondre à vos exigences :
- Obligatoire – Oui ou Non.
- Description – Les détails de votre référence.
-
URL d'aide – Une URL qui peut être utilisée pour obtenir de l'aide. Les informations d'aide auxquelles cette URL fait référence apparaissent sur l'onglet Info dans l'Éditeur de métadonnées. Si vous ne remplissez pas ce champ, les informations standards relatives au catalogage de la Library of Congress correspondent à l'option par défaut.
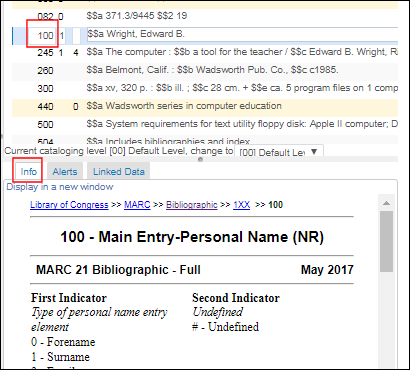 Éditeur de métadonnées Onglet Info relatif à l'option d'aide URL
Éditeur de métadonnées Onglet Info relatif à l'option d'aide URL -
Sous-champs – Pour chaque sous-champ, vous pouvez sélectionner Oui ou Non pour indiquer que le sous-champ est obligatoire et/ou répétable.
- Cliquez sur Attribuer des vocabulaires contrôlés dans la liste des actions possibles sur la ligne pour le sous-champ auquel vous souhaitez attribuer le vocabulaire contrôlé concerné. La page Détail du profil s'ouvre et affiche la section Créer une nouvelle valeur dans le vocabulaire contrôlé.
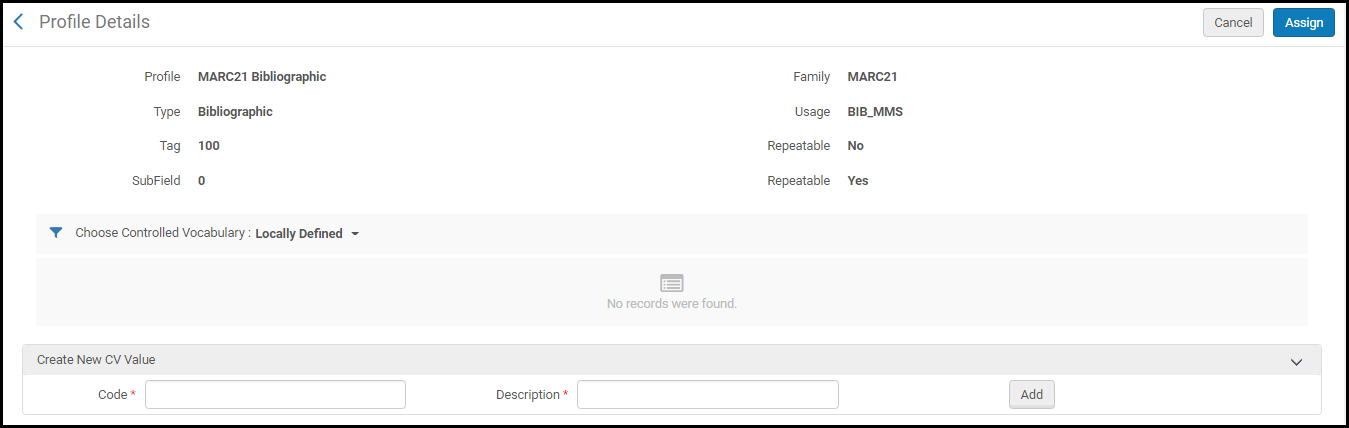
- Sélectionnez un vocabulaire contrôlé (CV) dans la liste déroulante Choisir un vocabulaire contrôlé. Les options dans cette liste sont configurées dans Configurer la liste de vocabulaires contrôlés. Les détails du vocabulaire contrôlé que vous avez sélectionné s'affichent. Sélectionnez Attribuer pour enregistrer cette sélection.
Pour vous faciliter la tâche, vous pouvez utiliser la section Créer une nouvelle valeur dans le vocabulaire contrôlé pour ajouter des termes au vocabulaire contrôlé. Les termes que vous ajoutez ici ne s'appliquent qu'au champ que vous êtes en train de modifier. Si vous souhaitez utiliser ces termes avec un autre champ ou un champ différent, utilisez la Liste de vocabulaires contrôlés (se reporter à Configurer la liste de vocabulaires contrôlés) pour créer un vocabulaire contrôlé qui pourra être utilisé pour plus d'un champ.Pour ajouter une nouvelle valeur au vocabulaire contrôlé dans la section Créer une nouvelle valeur dans le vocabulaire contrôlé, saisissez un code et une description, puis cliquez sur Ajouter. Quand vous avez fini d'ajouter des termes, sélectionnez Attribuer.
- Cliquez sur Attribuer des vocabulaires contrôlés dans la liste des actions possibles sur la ligne pour le sous-champ auquel vous souhaitez attribuer le vocabulaire contrôlé concerné. La page Détail du profil s'ouvre et affiche la section Créer une nouvelle valeur dans le vocabulaire contrôlé.
- Premier indicateur – Dans la section Premier indicateur sur la page Détails du champ, effectuez toutes les modifications nécessaires.
- Deuxième indicateur – Dans la section Deuxième indicateur sur la page Détails du champ, effectuez toutes les modifications nécessaires.
- Sélectionnez Enregistrer. Les modifications de champ sont enregistrées dans le profil de métadonnées.
- Sélectionnez Déployer.
Restaurer des détails du champ de profil
- Dans l'onglet Champs sur la page Détails du profil, sélectionnez Actions > Restaurer dans la liste des actions pour la ligne pour les détails de profil que vous souhaitez restaurer. Les modifications de profil qui ont été personnalisées localement sont restaurées à la valeur par défaut du champ.
- Sélectionnez Déployer.
Modifier des profils basés sur MARC avec des packs d'extension
| Élément d'un profil | LDR | Champ de contrôle/Champ fixe | Champ de données |
|---|---|---|---|
|
Étiquettes |
Les champs prédéfinis et tout champ personnalisé qui existent dans le profil sont conservés. Les nouveaux champs issus du pack d'extension sont ajoutés. |
Les champs prédéfinis et tout champ personnalisé qui existent dans le profil sont conservés. Les nouveaux champs issus du pack d'extension sont ajoutés. |
|
|
Sous-champ Codes |
Les codes prédéfinis et tout code personnalisé qui existent dans le profil sont conservés. Les nouveaux codes issus du pack d'extension sont ajoutés. |
||
|
Positions |
Les positions prédéfinies qui existent dans le profil sont supprimées. Toute position personnalisée qui existe dans le profil est conservée. Les nouvelles positions issues du pack d'extension sont ajoutées. |
Les positions prédéfinies qui existent dans le profil sont supprimées. Toute position personnalisée qui existe dans le profil est conservée. Les nouvelles positions issues du pack d'extension sont ajoutées. |
|
|
Valeurs de position |
Les valeurs prédéfinies qui existent dans le profil sont conservées. Toute valeur personnalisée qui existe dans le profil est remplacée par la nouvelle valeur issue du pack d'extension. |
Les valeurs prédéfinies qui existent dans le profil sont conservées. Toute valeur personnalisée qui existe dans le profil est remplacée par la nouvelle valeur issue du pack d'extension. |
|
|
Valeurs d'indicateur |
Les valeurs prédéfinies qui existent dans le profil sont conservées. Toute valeur personnalisée qui existe dans le profil est remplacée par la nouvelle valeur issue du pack d'extension. |
||
|
Sous-champ Vocabulaire contrôlé |
Toute valeur personnalisée ou prédéfinie qui existe dans le profil est remplacée par la nouvelle valeur issue du pack d'extension. |
Gérer les packs d'extension
- Créez un fichier d'extension .xml localement (voir Exemple de fichier .xml de packs d'extension pour plus d'informations).
- Cliquez sur le lien du profil MARC que vous souhaitez étendre sur la page Liste de configuration des métadonnées (Menu de configuration > Ressources > Catalogage > Configuration des métadonnées).
-
Dans l'onglet Champs, sélectionnez une option dans le menu Ajouter des extensions.
- Vers institution
Utilisez cette option pour ajouter un fichier .xml de packs d'extension au profil que vous êtes en train de configurer.Lorsque vous sélectionnez cette option, vous devez choisir d'ajouter un pack d'extension (fichier .xml) à votre profil MARC local depuis la Zone de communauté ou à partir d'un de vos fichiers locaux.
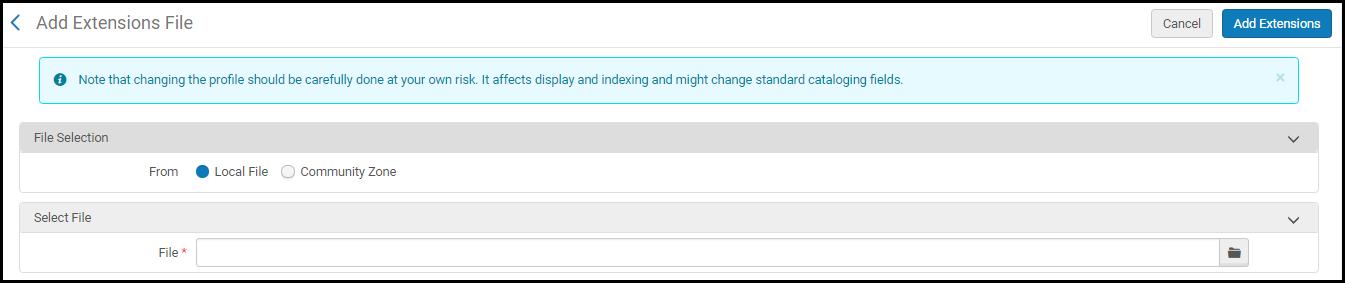 Ajouter un fichier .xml de packs d'extension à votre profil MARCSi vous sélectionnez l'option de la Zone de communauté, une liste des fichiers .xml partagés dans la Zone de communauté s'affiche. Vous pouvez choisir de télécharger un fichier .xml de packs d'extension vers votre stockage local ou de l'ajouter directement à votre profil.
Ajouter un fichier .xml de packs d'extension à votre profil MARCSi vous sélectionnez l'option de la Zone de communauté, une liste des fichiers .xml partagés dans la Zone de communauté s'affiche. Vous pouvez choisir de télécharger un fichier .xml de packs d'extension vers votre stockage local ou de l'ajouter directement à votre profil.
- Vers institution
- Vers la Communauté
Utilisez cette option pour ajouter un fichier .xml de packs d'extension à la Zone de communauté afin de le partager avec d'autres institutions.Lorsque vous sélectionnez cette option, vous êtes invité à renseigner les informations suivantes concernant le pack d'extension : nom du pack d'extension, description, nom du contact pour le pack d'extension, adresse email du contact et fichier .xml du pack d'extension.
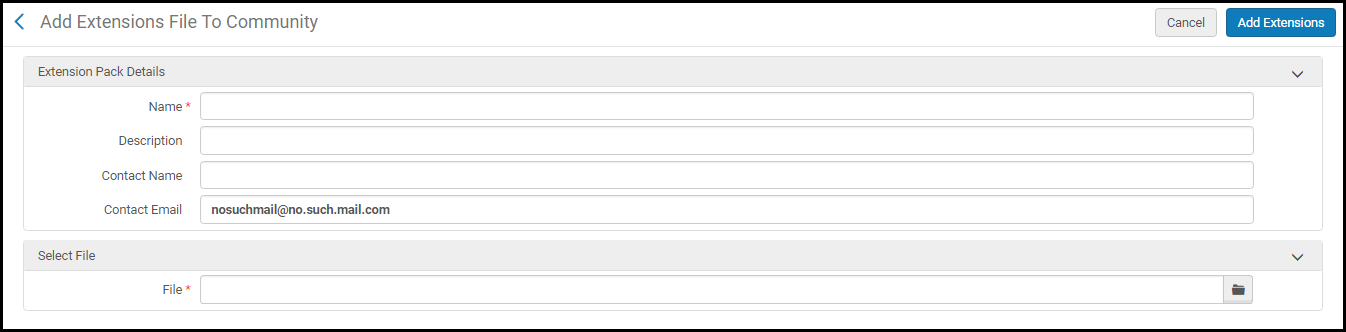 Ajouter un pack d'extension à la Zone de communauté
Ajouter un pack d'extension à la Zone de communauté - Sélectionnez Ajouter des extensions.
Pour les fichiers .xml de packs d'extension ajoutés à la Zone de communauté, le fichier ajouté et le message de partage s'affichent sur la page Extensions partagées.
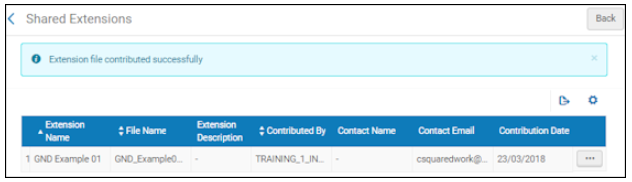 Page Extensions partagéesDurant le processus, si le système rencontre plusieurs occurrence de la même valeur, la première occurrence est appliquée et les autres occurrences redondantes sont ignorées.
Page Extensions partagéesDurant le processus, si le système rencontre plusieurs occurrence de la même valeur, la première occurrence est appliquée et les autres occurrences redondantes sont ignorées. - Vérifiez/confirmez vos modifications.
- Sélectionnez Déployer.
Quand un membre modifie une notice de la Zone Institution d'un profil MARC qui dispose d'un pack d'extension au niveau de la Zone Institution, uniquement lors du catalogage d'un champ d'extension Local (avec l'icône d'institution
Pack d'extension .xsd
<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema"
elementFormDefault="qualified" targetNamespace="http://com/exlibris/repository/mdprofile/xmlbeans"
xmlns="http://com/exlibris/repository/mdprofile/xmlbeans">
<!-- marc_profile element definition -->
<xs:element name="marc_profile">
<xs:complexType>
<xs:sequence>
<xs:element ref="leader_configuration" minOccurs="1"
maxOccurs="1" />
<xs:element ref="control_fields_list" minOccurs="1"
maxOccurs="1" />
<xs:element ref="data_fields_list" minOccurs="1"
maxOccurs="1" />
</xs:sequence>
</xs:complexType>
</xs:element>
<!-- XSD element definition -->
<!-- leader element definition -->
<xs:element name="leader_configuration">
<xs:complexType>
<xs:sequence>
<xs:element name="positions_list" minOccurs="1"
maxOccurs="1" type="positionsListType" />
</xs:sequence>
</xs:complexType>
</xs:element>
<!-- control_fields_list element definition -->
<xs:element name="control_fields_list">
<xs:complexType>
<xs:sequence>
<xs:element name="control_field_configuration" minOccurs="0"
maxOccurs="unbounded">
<xs:complexType>
<xs:sequence>
<xs:element name="description" minOccurs="1"
maxOccurs="1" type="xs:string" />
<xs:element name="help_url" minOccurs="0"
maxOccurs="1" type="xs:string" />
<xs:element name="materials_type_list" minOccurs="1"
maxOccurs="1" type="materialstypeListType" />
</xs:sequence>
<xs:attribute name="tag" type="tagType" use="required" />
<xs:attribute name="repeatable" type="xs:boolean"
use="required" />
<xs:attribute name="mandatory" type="xs:boolean" use="optional" />
</xs:complexType>
</xs:element>
</xs:sequence>
</xs:complexType>
</xs:element>
<!-- data_fields_list element definition -->
<xs:element name="data_fields_list">
<xs:complexType>
<xs:sequence>
<xs:element name="data_field_configuration" minOccurs="0"
maxOccurs="unbounded">
<xs:complexType>
<xs:sequence>
<xs:element name="description" minOccurs="1"
maxOccurs="1" type="xs:string" />
<xs:element name="help_url" minOccurs="0"
maxOccurs="1" type="xs:string" />
<xs:element name="first_indicator_configuration" type="indicatorType"
minOccurs="0" maxOccurs="1" />
<xs:element name="second_indicator_configuration"
type="indicatorType" minOccurs="0" maxOccurs="1" />
<xs:element name="sub_fields_list" minOccurs="0"
maxOccurs="1" type="subfieldType">
<xs:key name="sub_field_configuration-unique">
<xs:selector xpath="sub_field_configuration" />
<xs:field xpath="@code" />
</xs:key>
</xs:element>
</xs:sequence>
<xs:attribute name="tag" type="tagType" use="required" />
<xs:attribute name="repeatable" type="xs:boolean"
use="required" />
<xs:attribute name="mandatory" type="xs:boolean" use="optional" />
</xs:complexType>
</xs:element>
</xs:sequence>
</xs:complexType>
</xs:element>
<!-- XSD complex type definition -->
<xs:complexType name="positionsListType">
<xs:sequence>
<xs:element name="position_configuration" type="positionType"
minOccurs="0" maxOccurs="unbounded" />
</xs:sequence>
</xs:complexType>
<xs:complexType name="positionType">
<xs:sequence>
<xs:element name="description" minOccurs="1" maxOccurs="1"
type="xs:string" />
<xs:element name="values" minOccurs="1" maxOccurs="1"
type="valuesType" />
</xs:sequence>
<xs:attribute name="start" type="customIntegerType" use="required" />
<xs:attribute name="end" type="customIntegerType" use="required" />
</xs:complexType>
<xs:complexType name="valuesType">
<xs:sequence>
<xs:element name="value" minOccurs="0" maxOccurs="unbounded">
<xs:complexType>
<xs:simpleContent>
<xs:extension base="xs:string">
<xs:attribute name="code" type="codeType" use="required" />
</xs:extension>
</xs:simpleContent>
</xs:complexType>
</xs:element>
</xs:sequence>
</xs:complexType>
<xs:complexType name="subfieldValuesType">
<xs:sequence>
<xs:element name="value" minOccurs="0" maxOccurs="unbounded">
<xs:complexType>
<xs:simpleContent>
<xs:extension base="xs:string">
<xs:attribute name="code" type="codeType" use="required" />
</xs:extension>
</xs:simpleContent>
</xs:complexType>
</xs:element>
</xs:sequence>
<xs:attribute name="codeTable" type="xs:string" />
</xs:complexType>
<xs:complexType name="indicatorType">
<xs:sequence>
<xs:element name="description" minOccurs="1" maxOccurs="1"
type="xs:string" />
<xs:element name="values" minOccurs="1" maxOccurs="1"
type="valuesType" />
</xs:sequence>
<xs:attribute name="mandatory" type="xs:boolean" use="optional" />
</xs:complexType>
<xs:complexType name="subfieldType">
<xs:sequence>
<xs:element name="sub_field_configuration" minOccurs="0"
maxOccurs="unbounded">
<xs:complexType>
<xs:sequence>
<xs:element name="description" minOccurs="1" maxOccurs="1"
type="xs:string" />
<xs:element name="values" minOccurs="0" maxOccurs="1"
type="subfieldValuesType" />
<xs:element name="materials_type_list" minOccurs="0"
maxOccurs="1" type="materialstypeListType" />
</xs:sequence>
<xs:attribute name="code" type="subfieldCodeType" use="required" />
<xs:attribute name="repeatable" type="xs:boolean" use="required" />
<xs:attribute name="mandatory" type="xs:boolean" use="optional" />
</xs:complexType>
</xs:element>
</xs:sequence>
</xs:complexType>
<xs:complexType name="materialstypeListType">
<xs:sequence>
<xs:element name="material_type_configuration" minOccurs="0"
maxOccurs="unbounded" type="materialtypeType">
</xs:element>
</xs:sequence>
</xs:complexType>
<xs:complexType name="materialtypeType">
<xs:sequence>
<xs:element name="positions_list" minOccurs="1" maxOccurs="1"
type="positionsListType" />
</xs:sequence>
<xs:attribute name="name" type="xs:string" use="required" />
</xs:complexType>
<!-- XSD simple type definition -->
<xs:simpleType name="tagType">
<xs:restriction base="xs:string">
<xs:pattern value="[0-9]{3}" />
</xs:restriction>
</xs:simpleType>
<xs:simpleType name="customIntegerType">
<xs:restriction base="xs:string">
<xs:pattern value="[0-9]+" />
</xs:restriction>
</xs:simpleType>
<xs:simpleType name="codeType">
<xs:restriction base="xs:string">
<xs:pattern value="[a-z#0-9|]+" />
</xs:restriction>
</xs:simpleType>
<xs:simpleType name="subfieldCodeType">
<xs:restriction base="xs:string">
<xs:pattern value="[a-z0-9]{1}" />
</xs:restriction>
</xs:simpleType>
</xs:schema>
Fichier d'exemple de pack d'extension .xml
<marc_profile xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:noNamespaceSchemaLocation="marc21_profile_configuration.xsd">
<control_fields_list>
<control_field_configuration mandatory="true" repeatable="false"
tag="003">
<description>PERSISTENT RECORD IDENTIFIER</description>
<materials_type_list />
</control_field_configuration>
</control_fields_list>
<data_fields_list>
<data_field_configuration repeatable="true" mandatory="false" tag="020" xmlns="http://com/exlibris/repository/mdprofile/xmlbeans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<sub_fields_list>
<sub_field_configuration code="9" mandatory="false" repeatable="true">
<description>Former ISBN
</description>
</sub_field_configuration>
</sub_fields_list>
</data_field_configuration>
<data_field_configuration repeatable="true" mandatory="false" tag="024" xmlns="http://com/exlibris/repository/mdprofile/xmlbeans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<sub_fields_list>
<sub_field_configuration code="9" mandatory="false" repeatable="true">
<description>Former ISSN
</description>
</sub_field_configuration>
</sub_fields_list>
</data_field_configuration>
<data_field_configuration repeatable="false" mandatory="false" tag="689" xmlns="http://com/exlibris/repository/mdprofile/xmlbeans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<description>SUBJECT HEADING CHAIN</description>
<help_url>http://www.google.com</help_url>
<first_indicator_configuration>
<description>Type of subject heading chain</description>
<values>
<value code="0">Simple chain</value>
<value code="1">Complex chain</value>
</values>
</first_indicator_configuration>
<second_indicator_configuration>
<description>Undefined</description>
<values>
<value code="#">Undefined</value>
</values>
</second_indicator_configuration>
<sub_fields_list>
<sub_field_configuration code="a" mandatory="true" repeatable="false">
<description>Heading chain first element
</description>
</sub_field_configuration>
<sub_field_configuration code="b" mandatory="false" repeatable="true">
<description>Heading chain second element</description>
</sub_field_configuration>
<sub_field_configuration code="c" mandatory="true" repeatable="true">
<description>Type of chain</description>
<values>
<value code="0">GND chain</value>
<value code="1">DNB chain</value>
</values>
</sub_field_configuration>
</sub_fields_list>
</data_field_configuration>
</data_fields_list>
</marc_profile>
Travailler avec les formulaires
Vous pouvez également convertir les champs MARC en étiquettes qui seront utilisées pour créer des formulaires. Voir MARC Configuration Slim.
- Sélectionnez l'onglet Formulaires lors de la configuration des profils Dublin Core qualifiés, des profils bibliographiques MARC ou des profils MODS.
- Sélectionnez Ajouter un formulaire et sélectionnez l'une des options suivantes :
Les éléments suivants apparaissent :
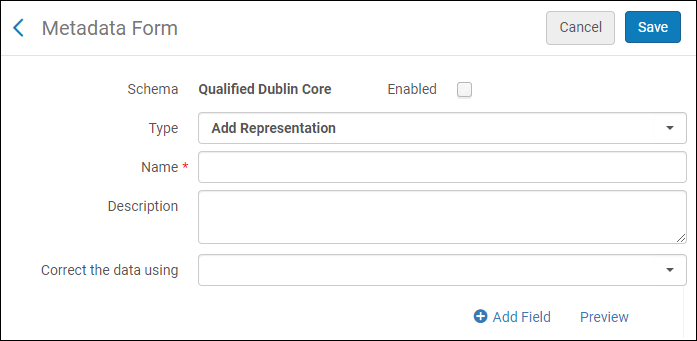 Formulaire de métadonnées
Formulaire de métadonnées - Remplissez les champs du formulaire et cliquez surAjouter un champ. Une liste des types de champ s'affiche :
- Case à cocher - Une case à cocher unique, qui peut être cochée ou décochée
- Case combo - Sélection multiple – une liste déroulante de cases à cocher. Plusieurs cases à cocher peuvent être sélectionnées.
- Champs communs – une liste déroulante d'options. Seule une case peut être sélectionnée.
- Date – un sélectionneur de date
- Masqué – un champ masqué utilisé pour ajouter automatiquement des valeurs et des champs prédéterminés à la notice de métadonnées.
- Bouton radio – plusieurs boutons radio sont affichés. Seule une case peut être sélectionnée.
- Zone de texte - une zone de texte à plusieurs lignes
- Text Box – une case de texte à une seule ligne
- Recherche – des options s'affichent à mesure que vous tapez ou sélectionnez l'icône pour ouvrir une page d'options. Seule une case peut être sélectionnée.
L’ajout du champ Recherche aux formulaires n’est disponible que pour les réprésentations et les dépôts par le personnel.
- Sélectionnez un type de champ. Les champs du type de champ sélectionné s'affichent. Par exemple :
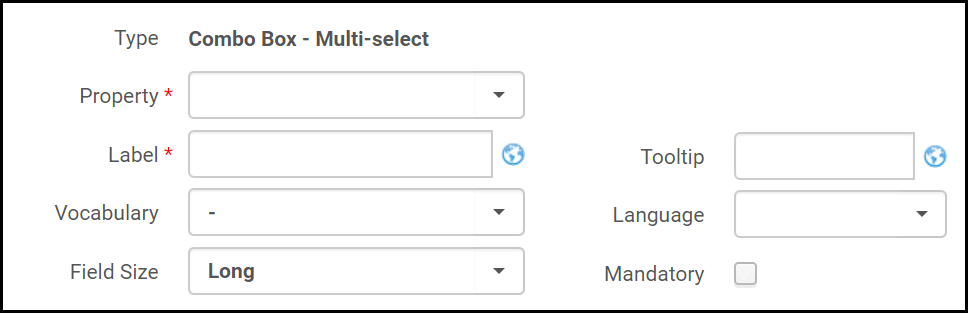 Champs de formulaire (formulaire Dublin Core)
Champs de formulaire (formulaire Dublin Core) - Remplissez les champs comme suit :
- Propriété / Champ – La propriété que vous souhaitez ajouter au formulaire (pour Dublin Core), ou le champ que vous souhaitez ajouter au formulaire (pour MARC 21).
- Nom de l'attribut – (MODS uniquement) sélectionnez un nom d'attribut pour le champ sélectionné.
- Valeur de l'attribut – (MODS uniquement) sélectionnez une valeur pour l'attribut sélectionné.
- Étiquette – L'étiquette de la propriété.
- Vocabulaire - Sélectionnez un vocabulaire pour déterminer les options qui s'affichent à l'utilisateur pour ce champ. Pour plus d'informations, voir Liste de vocabulaires contrôlés - Formulaires.
- Taille du champ – Sélectionnez si vous souhaitez que le champ soit court ou long.
- Info-bulle – un message de type info-bulle à afficher.
- Langue - les langues que l'institutiona accepte en tant que langue de thèse ou mémoire.
- Valeur par défaut – Sélectionnez une valeur par défaut à afficher dans le formulaire.
- Obligatoire – Sélectionnez cette option si vous voulez que le champ soit obligatoire.
- Répétable – Sélectionnez cette option pour autoriser l'utilisateur à ajouter plusieurs instances au champ.
- Sélectionnez Enregistrer dans la liste. La propriété est ajoutée au formulaire.
- Répétez les étapes ci-dessus pour ajouter d'autres champs au formulaire. Sélectionnez Prévisualiser pour prévisualiser le formulaire.
- Lorsque vous avez fini d'ajouter des champs au formulaire, sélectionnez Enregistrer.
Travailler avec des processus de normalisation
- Créez un processus de normalisation personnalisé. Voir Configurer le catalogage ci-dessous.
- Modifier un processus de normalisation – Sélectionnez Modifier dans la liste des actions possibles sur la ligne. Les paramètres concernant un processus de normalisation existant apparaissent dans les onglets suivants :
- Information générale
- Liste de tâches
- Paramètres de tâche
- Dupliquez un processus de normalisation pour apporter des changements à la copie dupliquée – Sélectionnez Copier dans la liste des actions sur la ligne.
- Désactiver un processus de normalisation – Si le processus de normalisation n'est plus requis pour le moment mais peut être nécessaire dans le futur, vous pouvez le désactiver (l'activer) dans la colonne Actif.
- Supprimer un processus de normalisation – Sélectionnez Supprimer dans la liste des actions possibles sur la ligne.
Créer un processus de normalisation
- Sur la page Détails du profil dans l'onglet Processus de normalisation, sélectionnez Ajouter un processus (Menu de configuration > Ressources > Catalogage > Configuration des métadonnées), puis cliquez sur le lien d'un profil). Sinon, vous pouvez également créer des processus sur la page Liste des processus (Menu de configuration > Ressources > Général > Processus).
Pour créer une copie d'un processus existant, sélectionnez Copier dans la liste des actions sur la ligne. Une fois le processus copié, vous pouvez le modifier si nécessaire.
- Dans la section Informations générales :
- Renseignez le nom et une description pour le processus. Ces valeurs seront visibles pour les utilisateurs sur la page Liste des processus.
- Dans le champ Status, sélectionnez si le processus est activé (Actif) ou non. Un processus désactivé peut être conservé et modifié dans le système sans être exécuté. Il peut être activé à tout moment.
- Cliquez sur Suivant puis sélectionnez Ajouter des tâches.
- Sélectionnez les tâches requises, puis cliquez sur Ajouter et fermer.
Cette page contient une liste prédéfinie des tâches que vous pouvez inclure dans votre processus (ou chaîne de tâches). Consultez Options de la liste des tâches pour voir des descriptions des tâches.
Vous ne pouvez pas définir de tâche supplémentaire et la plupart de ces tâches ont des paramètres fixes. En fonction de la configuration des métadonnées en cours de modification, les tâches peuvent varier.
Sélectionnez la tâche MarcDroolNormalization (DcDroolNormalization ou Marc XSL Normalization) pour pouvoir sélectionner les règles de normalisation que vous avez créées dans l'Éditeur de métadonnées (se reporter à Travailler avec des règles de normalisation) à la prochaine étape. - Utilisez les flèches vers le haut et vers le bas pour déterminer l'ordre dans lequel les tâches sont exécutées.
- Sélectionnez Suivant. La page suivante de l'assistant s'ouvre.
Les paramètres qui apparaissent dépendent des tâches sélectionnées. - Sélectionnez Enregistrer.
Options de la Liste des tâches
| Nom du processus | Description |
|---|---|
|
Normalisation du champ 852 |
Exécute une tâche qui récupère le numéro de contrôle d'une notice bibliographique et le place dans le sous-champ adéquat de la notice de collections. Voir Travailler avec des profils de collections MARC 21 pour plus d'informations. |
| addBibToCollectionNormalizationTask | Permet d'attribuer des titres numériques importés à une collection en fonction de la valeur du champ 787 de la notice MARC. Pour plus d'informations, voir Gérer les profils d'import. |
| Ajouter les translittérations Hanja vers Hangul | Convertit du contenu, tel qu'un titre, de l'Hanja vers l'Hangul en configurant les champs source et cible comme indiqué ci-dessous. Pour plus d'informations, voir Travailler avec les translittérations CJK dans le Catalogage. Ce processus de translittération peut être utilisé dans les configurations Bibliographique MARC 21 et Autorité MARC 21, ainsi que pour toutes les configurations MARC, telles que KORMARC, UNIMARC, CNMARC, etc. |
| Ajouter les translittérations Hanja vers Hangul CK | Convertit du contenu, tel qu'un titre, de l'Hanja vers l'Hangul CK en configurant les champs source et cible comme indiqué ci-dessous. Pour plus d'informations, voir Travailler avec les translittérations CJK dans le Catalogage. Ce processus de translittération peut être utilisé dans les configurations Bibliographique MARC 21 et Autorité MARC 21, ainsi que pour toutes les configurations MARC, telles que KORMARC, UNIMARC, CNMARC, etc. |
| Ajouter les translittérations Hanja vers Hangul MOE | Convertit du contenu, tel qu'un titre, de l'Hanja vers l'Hangul MOE en configurant les champs source et cible comme indiqué ci-dessous. Pour plus d'informations, voir Travailler avec les translittérations CJK dans le Catalogage. Ce processus de translittération peut être utilisé dans les configurations Bibliographique MARC 21 et Autorité MARC 21, ainsi que pour toutes les configurations MARC, telles que KORMARC, UNIMARC, CNMARC, etc. |
| Ajouter les translittérations Hanja vers Pinyin | Convertit du contenu, tel qu'un titre, de l'Hanja vers le Pinyin en configurant les champs source et cible comme indiqué ci-dessous. Pour plus d'informations, voir Travailler avec les translittérations CJK dans le Catalogage. Ce processus de translittération peut être utilisé dans les configurations Bibliographique MARC 21 et Autorité MARC 21, ainsi que pour toutes les configurations MARC, telles que KORMARC, UNIMARC, CNMARC, etc. |
| Ajouter les translittérations Hanzi vers Pinyin | Convertit du contenu chinois en Pinyin.
Configuration
La configuration pour ce processus nécessite que vous spécifiez les champs/sous-champs source et cible comme indiqué de l'Hanzi vers Pinyin.
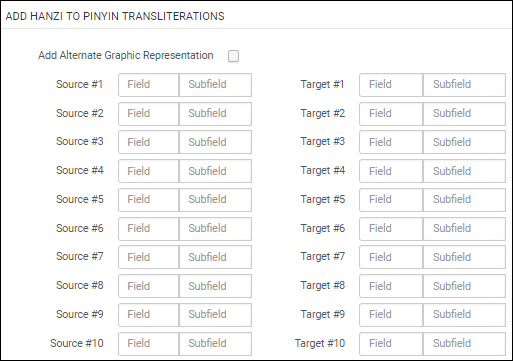 Configuration de la tâche Hanzi vers Pinyin
Lorsque la normalisation s'effectue, les premier et deuxième indicateurs dans le champ cible sont les mêmes que les indicateurs dans le champ source.
Les mots translittérés sont placés dans le champ/sous-champ cible et seuls les mots qui ont plus d'une translittération sont placés entre les guillemets < > dans le champ/sous-champ cible. Le catalogueur doit alors choisir le bon et supprimer les autres.
Veuillez noter que les institutions qui sont configurées pour la langue de recherche chinois Hong Kong, le processus de translittération de Hanzi à Pinyin ajoute la translittération du mot la plus communément utilisée à la notice au lieu de de fournir toutes les options de translittération possibles entre crochets.
Si du contenu existe dans le sous-champ cible, le processus de normalisation l'écrasera.
La suppression de sous-champs n'est pas prise en compte au sein de ce processus de normalisation. Pour supprimer des sous-champs, sélectionnez un processus de normalisation dédié à cette tâche.
Sélectionnez l'option Ajouter une représentation graphique alternative pour identifier le champ 880 en tant que cible pour la translittération Hanzi vers Pinyin. Lorsque vous utilisez cette option, vous devez uniquement spécifier les champs source. Tous les sous-champs dans les champs source seront translittérés vers les champs 880.
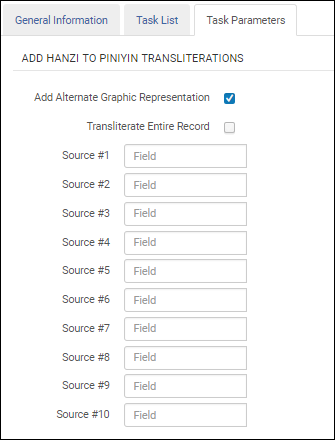 Ajouter une représentation graphique alternative
Sélectionnez l'option Translittérer la notice entière pour translittérer tous les champs dans une notice de l'Hanzi vers le Pinyin. Cette option s'affiche après avoir sélectionné l'option Ajouter une représentation graphique alternative. Comme tous les champs seront translittérés (excepté ceux en chinois), il n'est pas nécessaire de préciser les champs source dans la configuration de la tâche.
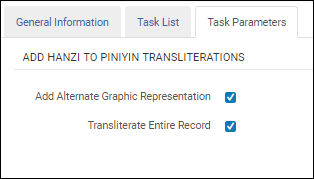 Translittérer la notice entière
Capitalisation
Pour tous les champs MARC 21 qui commencent par un caractère chinois et sont translittérés, le premier caractère translittéré est écrit en lettre capitale.
Noms de personne
Lorsque vous utilisez la tâche de normalisation Ajouter les translittérations Hanzi vers Pinyin et que la langue de recherche de votre institution est configurée par Ex Libris sur Hong-Kong, les noms de personnes situés dans le sous-champ $a des champs 100, 600, 700 et 800 sont gérés de la manière suivante :
Voir l'exemple ci-dessous pour la translittération de Hong-Kong comparée à la translittération chinoise.
Hong-Kong:
毛澤東 => Mao, Zedong
Chinois
毛澤東 => mao ze dong
Pour plus d'informations, voir Travailler avec les translittérations CJK dans le Catalogage. Ce processus de translittération peut être utilisé pour des profils Bibliographique MARC 21 et CNMARC.
|
| Ajouter les translittérations Kana vers Hangul | Convertit du contenu, tel qu'un titre, du Kana vers l'Hangul en configurant les champs source et cible comme indiqué ci-dessous. Pour plus d'informations, voir Travailler avec les translittérations CJK dans le Catalogage. Ce processus de translittération peut être utilisé dans les configurations Bibliographique MARC 21 et Autorité MARC 21, ainsi que pour toutes les configurations MARC, telles que KORMARC, UNIMARC, CNMARC, etc. |
| Ajouter les translittérations Kana vers Kana latinisé | Convertit du contenu, tel qu'un titre, du Kana vers du Kana latinisé en configurant les champs source et cible comme indiqué ci-dessous. Pour plus d'informations, voir Travailler avec les translittérations CJK dans le Catalogage. Ce processus de translittération peut être utilisé dans les configurations Bibliographique MARC 21 et Autorité MARC 21, ainsi que pour toutes les configurations MARC, telles que KORMARC, UNIMARC, CNMARC, etc. |
| addMmsIdToDcIdentifier | Ajoute l'identifiant MMS au champ dc:identifier des notices DC. |
| AuthorityGenerateControlNumberSequence | Exécute une tâche qui génère une séquence de numéro de contrôle pour une notice d'autorité. |
| BibGenerateControlNumberSequence | Exécute une tâche qui génère une séquence de numéro de contrôle pour une notice bibliographique. |
|
BibGenerateLocalControlNumberSequence |
Exécute une tâche (en MARC 21) qui génère un numéro de cote local qui est stocké dans le champ 035 quand, par exemple, l'option Modifier > Améliorer la notice est sélectionnée lors de la modification d'une notice dans l'Éditeur de métadonnées.
Quand vous ajoutez un nouveau processus, sélectionnez Ajouter des tâches, Generate Local Control Number Sequence, Ajouter et fermer et Suivant dans l'ordre pour définir les paramètres de tâche.
Veuillez noter que « Champ Cible bibliographique » ne liste qu'une seule option : 'sous-champ a 035'. |
| BibGenerateHandle | |
| CnmarcBibAdd005Task | Le champ 005 est ajouté seulement lors d'une sauvegarde dans l'Éditeur de métadonnées. |
| CnmarcBibClearEmptyFieldsTask | Ce processus exécute une tâche qui supprime les champs bibliographiques vides. |
| CnmarcBibReSequenceTask | Ce processus exécute une tâche qui re-séquence les champs bibliographiques en fonction de leur ordre propre - par exemple, 001, 100, 200, etc.
Les champs entre 500 et 899 ne sont pas triés (ou uniquement par centaines).
|
| CnmarcBibTag100OpenDateTask | Si le champ 100 existe, la date actuelle est placée au début du champ 100 $a aux positions 00-07 en utilisant le format AAAAMMJJ. |
| CnmarcBibTag100Task | Alma insère ou corrige automatiquement les dates dans les positions 09-12 et 13-16 du champ 100 CNMARC selon la date indiquée dans le champ 210$d CNMARC (et 210 $h quand il contient quatre chiffres consécutifs). En outre, les dates dans le champ 210 $d sont standardisées. Pour des dates comme 198? ou 19?, par exemple, Alma remplace les points d'interrogation et espaces par des "-" (tirets). |
| Create210BasedOn010 | La tâche du processus de normalisation ajoute le champ MARC 210 $a à la notice et place l'éditeur chinois dans le champ 210 en fonction du ISBN dans le champ MARC 010 $a et selon une table gérée dans Alma. Après la création et l'enregistrement d'un processus de normalisation avec cette tâche sélectionnée, vous pouvez utiliser l'option Modifier > Améliorer la notice dans l'Éditeur de métadonnées pour mettre à jour les notices que vous cataloguez.
Voir Améliorer la notice dans la table Éditeur de métadonnées - Menu Modifier sur la page Naviguer dans l'Éditeur de métadonnées pour plus d'informations.
|
| DcBibClearEmptyFieldsTask | Exécute une tâche qui supprime les champs Dublin Core vides. |
| DcBibResequenceTask | Exécute une tâche qui reséquence les champs Dublin Core en fonction de leur propre ordre. |
| DcDroolNormalization | Sélectionnez les règles de normalisation à exécuter. Pour plus d'informations, voir Normalisation MARC Drool.
Seules les règles de normalisation créées en tant que règles partagées dans l'Éditeur de métadonnées peuvent être sélectionnées.
Pour plus d'informations, voir Travailler avec des règles de normalisation.
|
| Identifier le niveau de notice abrégée | Exécute une tâche qui calcule le niveau de notice abrégée. |
| Générer une cote de rangement d'un auteur chinois | Exécute une tâche (en CNMARC) qui génère un numéro de cote d'un auteur chinois qui est stocké dans le champ 905 quand, par exemple, l'option Modifier > Améliorer la notice est sélectionnée lors de la modification d'une notice dans l'Éditeur de métadonnées.
Lorsque vous ajoutez un nouveau processus, sélectionnez Ajouter des tâches, puis Générer une cote de rangement d'un auteur chinois, cliquez ensuite sur Ajouter et fermer puis sur Suivant afin d'accéder et de sélectionner une routine de génération de numéro d'auteur dans la liste déroulante Choisir une routine de génération de numéro d'auteur.
Sélectionnez une des options suivantes de routine de génération de numéro d'auteur :
Ceci est la routine de génération de cote pour les notices bibliographiques CNMARC d'après la table des Numéros généraux chinois d'auteurs qui génère le numéro d'auteur dans le champ 090 à l'aide de la routine 2.
Ceci est la routine de génération de cote pour les notices bibliographiques CNMARC d'après la table des Numéros généraux chinois d'auteurs qui génère le numéro d'auteur dans le champ 090 à l'aide de la routine 3.
La séquence suivante sera générée dans le champ 905.
Cette routine ne doit être utilisée que lors de la modification manuelle d'une notice et non dans un processus par lot.
Cette routine de maintenance enregistre la séquence dans Alma à partir du champ 905 de la notice bibliographique. Elle ne génère pas de nouvelle séquence mais enregistre la séquence existante issue de la notice bibliographique. Elle peut être utilisée après des mises à jour par lot telles qu'une migration ou un import dans l'Éditeur de métadonnées. Ceci garantit que la séquence dans Alma et celle qui est enregistrée dans la notice bibliographique soient identiques.
Sélectionnez le paramètre Utiliser lors de la génération du numéro d'auteur dans l'Éditeur de métadonnées (F4) afin d'activer, dans l'Éditeur de métadonnées, le type de génération de numéro d'auteur sélectionné dans le paramètre Choisir la routine de génération du numéro d'auteur.
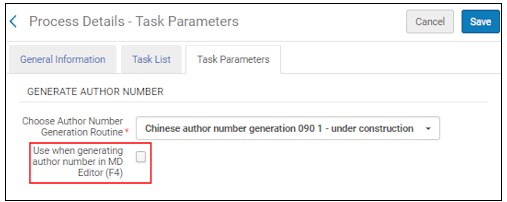 Utiliser lors de la génération du numéro d'auteur dans le paramètre Éditeur de métadonnées (F4)
Lorsque vous sélectionnez cette option pour la normalisation et que vous appuyez sur F4 dans l'Éditeur de métadonnées, le système utilisera la routine de génération de numéro d'auteur identifiée dans ce profil à la place de la génération habituelle de numéro d'auteur.
|
| Générer une cote de rangement d'auteur | Exécute une tâche (en MARC 21) qui génère un numéro de cote d'un auteur chinois qui est stocké dans le champ 905 quand, par exemple, l'option Modifier > Améliorer la notice est sélectionnée lors de la modification d'une notice dans l'Éditeur de métadonnées. Ceci est la version MARC 21 du traitement Générer une cote de rangement d'un auteur chinois.
Lorsque vous ajoutez un nouveau processus, cliquez sur Ajouter des tâches, puis sélectionnez Générer une cote de rangement d'un auteur chinois, puis Ajouter et fermer et cliquez enfin sur Suivant afin d'accéder et de sélectionner une routine de génération de numéro d'auteur dans la liste déroulante Choisir une routine de génération de numéro d'auteur.
Ceci est la routine de génération de cote pour les notices bibliographiques MARC 21 d'après la table des Numéros généraux d'auteurs chinois qui génère le numéro d'auteur dans le champ 090 à l'aide de la routine 3.
Ceci est la routine de génération de cote pour les notices bibliographiques MARC 21 d'après la table des Numéros généraux d'auteurs chinois qui génère le numéro d'auteur dans le champ 090 à l'aide de la routine 4.
Ceci est la routine de génération de cote pour les notices bibliographiques MARC 21 d'après la table des Numéros généraux d'auteurs chinois qui génère le numéro d'auteur dans le champ 905 à l'aide de la routine 1.
La séquence suivante sera générée dans le champ 905.
Cette routine ne doit être utilisée que lors de la modification manuelle d'une notice et non dans un processus par lot.
Cette routine de maintenance enregistre la séquence dans Alma à partir du champ 905 de la notice bibliographique. Elle ne génère pas de nouvelle séquence mais enregistre la séquence existante issue de la notice bibliographique. Elle peut être utilisée après des mises à jour par lot telles qu'une migration ou un import dans l'Éditeur de métadonnées. Ceci garantit que la séquence dans Alma et celle qui est enregistrée dans la notice bibliographique soient identiques.
Sélectionnez le paramètre Utiliser lors de la génération du numéro d'auteur dans l'Éditeur de métadonnées (F4) afin d'activer, dans l'Éditeur de métadonnées, le type de génération de numéro d'auteur sélectionné dans le paramètre Choisir la routine de génération du numéro d'auteur.
Lorsque vous sélectionnez cette option pour la normalisation et que vous appuyez sur F4 dans l'Éditeur de métadonnées, le système utilisera la routine de génération de numéro d'auteur identifiée dans ce profil à la place de la génération habituelle de numéro d'auteur.
|
| Règles de normalisation MARC | Exécute les règles de normalisation qui sont sélectionnées en tant que paramètres dans l'onglet Paramètres de tâche. |
|
MARC 21 Étendre la collection par la tâche 863/4/5 |
Exécute une tâche qui ajoute un champ de collection de mention récapitulative 863/864/865. Voir Travailler avec des profils de collections MARC 21 pour plus d'informations. |
|
MARC 21 Étendre la collection par la tâche 866/7/8 |
Exécute une tâche qui ajoute une description aux champs de données sur les fonds textuelles 866/867/868. Voir Travailler avec des profils de collections MARC 21 pour plus d'informations. |
| Marc21AuthClearEmptyFieldsTask | Exécute une tâche qui supprime les champs d'autorité vides. |
| Marc21AuthResequenceTask | Exécute une tâche qui reséquence les champs d'une notice d'autorité en fonction de leur propre ordre. |
| Marc21BibClearEmptyFieldsTask |
Exécute une tâche qui supprime les champs bibliographiques vides. Cette tâche ne peut pas être supprimée du processus prédéfini, car les notices ayant des champs vides ne peuvent pas être enregistrées. |
| Marc21BibResequenceTask | Exécute une tâche qui reséquence les champs bibliographiques en fonction de leur propre ordre - par exemple, 001, 100, 200, etc.
Les champs entre 500 et 899 ne sont pas triés (ou uniquement par centaines). Le champ 689 (pertinent pour le marché allemand uniquement) est classé en fonction de ses indicateurs.
|
| Marc21createControlNumber | Exécute une tâche qui crée un nouveau numéro de contrôle à partir des champs 001 et 003 des notices bibliographiques et le place dans le champ 035. |
|
Marc21HoldingClearEmptyFieldsTask |
Exécute une tâche qui supprime les champs de collections vides. Voir Travailler avec des profils de collections MARC 21 pour plus d'informations. |
|
Marc21HoldingResequenceTask |
Exécute une tâche qui reséquence les champs de collections en fonction de leur propre ordre. Les champs 5XX et 8XX ne sont pas triés. Voir Travailler avec des profils de collections MARC 21 pour plus d'informations. |
|
Écris un champ 001 pour la notice de collection. Voir Travailler avec des profils de collections MARC 21 pour plus d'informations. |
|
| MarcDroolNormalization | Sélectionnez les règles de normalisation à exécuter. Les processus de normalisation se basent sur les règles de normalisation partagées qui ont déjà été définies et enregistrées dans l'Éditeur de métadonnées (consultez Travailler avec des règles de normalisation).
Les règles de normalisation privées ne peuvent pas être utilisées telles quelles dans un processus de normalisation.
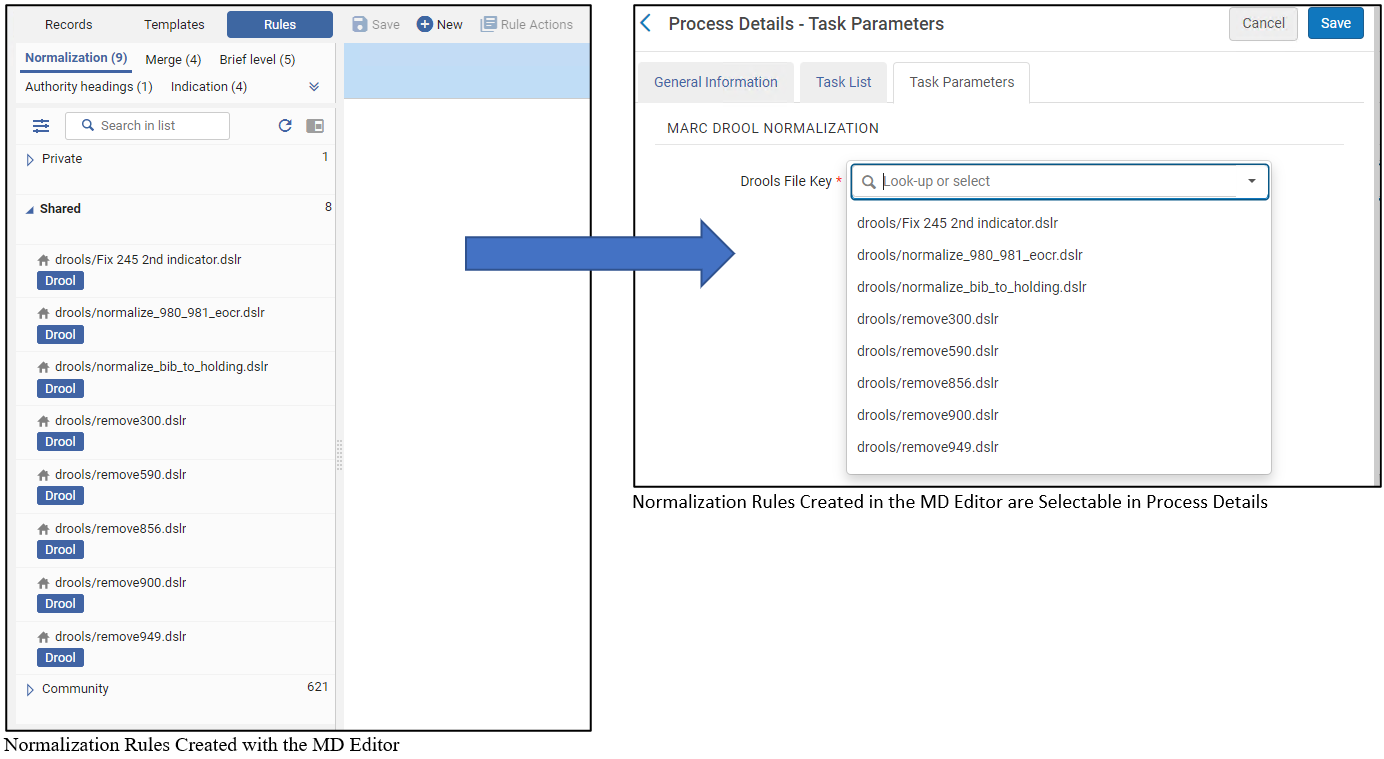 Pour plus d'informations concernant la création de règles de normalisation, consulter Travailler avec des règles de normalisation. |
| MarcXSLNormalization | Sélectionnez les règles de normalisation à exécuter.
Les processus de normalisation se basent sur les règles de normalisation partagées qui ont déjà été définies et enregistrées dans l'Éditeur de métadonnées (consultez Travailler avec des règles de normalisation). Les règles de normalisation privées ne peuvent pas être utilisées telles quelles dans un processus de normalisation.
 Pour plus d'informations concernant la création de règles de normalisation, consulter Travailler avec des règles de normalisation. |
| MmsTagSuppressed | Exécute une tâche qui supprime/annule la suppression de notices bibliographiques du système de découverte en fonction de la valeur sélectionnée Vrai ou Faux (Vrai pour les notices qui doivent être supprimées de la publication dans Primo et Faux pour autoriser cette publication). |
| MmsTagSyncExternal |
Exécute une tâche qui définit la règle de synchronisation pour les notices bibliographiques avec le catalogue externe en fonction de l'une des valeurs sélectionnées suivantes :
|
| MmsTagSyncNationalCatalog | Exécute une tâche qui définit la règle de synchronisation pour les notices bibliographiques avec le catalogue national en fonction de l'une des valeurs sélectionnées suivantes :
|
|
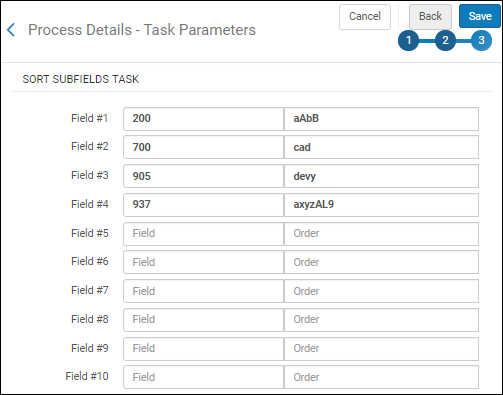
Sélectionnez cette tâche pour trier l'ordre des sous-champs pour un champ spécifique lors de la normalisation. Après avoir ajouté cette tâche aux Détails de processus - page Ajouter des tâches et après avoir sélectionné Suivant, la tâche Tri des sous-champs apparaît là où vous pouvez personnaliser l'ordre des sous-champs pour un champ spécifique, ce qui est possible pour jusqu'à dix champs différents.
Tâche de tri des sous-champs
Lorsqu'il y a d'autres sous-champs dans le champ qui ne sont pas précisés dans l'ordre de tri, ils sont annexés après les sous-champs triés dans leur ordre originel. N'importe quel champ qui n'est pas personnalisé pour le tri garde son ordre de sous-champs originel. La personnalisation du tri est sensible aux majuscules et minuscules. Les versions minuscule et majuscule d'une lettre sont traités séparément. |
|
|
UnimarcBibAdd005Task |
Le champ 005 est ajouté seulement lors d'une sauvegarde dans l'Éditeur de métadonnées. Pour les institutions utilisant SBN, voir Configuring the Task UnimarcBibAdd005Task for SBN / UNIMARC pour plus d'informations. |
| UnimarcBibClearEmptyFieldsTask | Ce processus exécute une tâche qui supprime les champs bibliographiques vides. |
| UnimarcBibResequenceTask | Ce processus exécute une tâche qui re-séquence les champs bibliographiques en fonction de leur ordre propre - par exemple, 001, 100, 200, etc.
Les champs entre 500 et 899 ne sont pas triés (ou uniquement par centaines).
|
| UnimarcBibTag100OpenDateTask | Si le champ 100 existe, la date actuelle est placée au début du champ 100 $a aux positions 00-07 en utilisant le format AAAAMMJJ. |
| UnimarcBibTag100Task | Alma insère ou corrige automatiquement les dates dans les positions 09-12 et 13-16 du champ 100 UNIMARC selon la date indiquée dans le champ 210$d UNIMARC (et 210 $h quand il contient quatre chiffres consécutifs). En outre, les dates dans le champ 210 $d sont standardisées. Pour des dates comme 198? ou 19?, par exemple, Alma remplace les points d'interrogation et espaces par des "-" (tirets). |
| Mettre à jour les informations du système d'origine | Utilisez cette option pour configurer le paramètre Version du système d'origine. Il est utilisé pour le suivi de version lors de l'import des notices et s'affiche lorsque les paramètres En cas de correspondances (associé aux options Remplacer et Fusionner) et Tenir compte du système d'origine ou Ignorer le système d'origine sont sélectionnés. Les notices enregistrées dans le système avant la version de septembre 2015 ne possèdent pas les informations vis-à-vis de ce paramètre Version du système d'origine. Alma offre la possibilité de mentionner ces informations en utilisant un traitement d'automatisation de processus en sélectionnant Mettre à jour les informations du système d'origine dans la Liste de réserve des processus. Pour les notices importées après la version de septembre 2015, les paramètres Système d'origine et Version du système d'origine sont ajoutés automatiquement.
Lorsque vous opérez sur des notices existantes avant la version de septembre 2015, soyez attentifs au fait que la tâche de normalisation ne modifiera aucune notice liée à la Zone de communauté.
Voir la procédure Configurer la normalisation de la gestion des informations sur le Système d'origine et la version du système d'origine pour les étapes concernant la configuration d'un processus via le champ Mettre à jour les informations du système d'origine. |
Configurer la normalisation pour gérer le système d'origine
- Sur la page Liste des processus (Menu de configuration > Général > Processus), sélectionnez Ajouter un processus.
- Sélectionnez les options suivantes pour les paramètres identifiés ci-dessous et cliquez sur Suivant :
- Entité économique – Titre bibliographique
- Type – Normalisation Bib Marc 21 (ou autre type d'option en fonction de votre environnement)
- Complétez la section Informations générales puis cliquez sur Suivant.
- Cliquez sur Ajouter des tâches et sélectionnez Mettre à jour les informations du système d'origine.
- Sélectionnez Ajouter et fermer, puis cliquez sur Suivant.
- Sélectionnez l'un des paramètres suivants en fonction de vos besoins :
Vous devez également préciser le paramètre associé aux paramètres sélectionnés (si nécessaire).
-
Mettre à jour le système d'origine – Le système d'origine que vous souhaitez identifier dans les métadonnées de la notice importée.
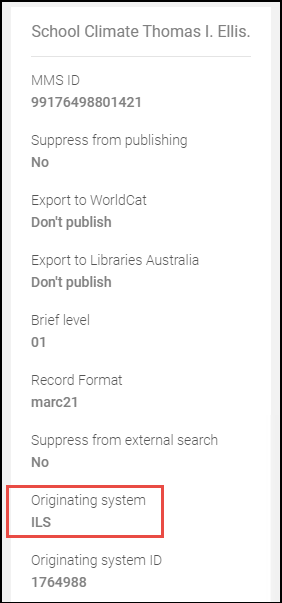 Système d'origine
Système d'origine -
Mettre à jour la version du système d'origine – La date que vous souhaitez enregistrer dans les métadonnées de la notice. Cette date est utilisée lorsque vous sélectionnez les options permettant d'éviter un remplacement/une fusion dans votre profil d'import pour le traitement des correspondances de notices (voir Créer/Modifier un profil d'import : Profil de correspondance). Le format de ce paramètre de date est MM/JJ/AAAA. Le format de la Version du système d'origine est AAAAMMJJhhmmss.f (où hhmmss.f correspond aux heures, minutes, secondes et fraction de seconde au fomat 24h). Lors d'un processus de normalisation pour lequel ce paramètre est précisé, Alma indique AAAAMMJJ000000.0. Des zéros sont indiqués pour la portion hhmmss.f de la Version du système d'origine.
Lors de l'utilisation de l'import de métadonnées, Alma extrait la date et heure (formatées selon AAAAMMJJhhmmss.f) à partir du champ de contrôle 005 de la notice importée pour le champ de la Version du système d'origine. Voir la figure ci-dessous pour un exemple du champ de contrôle 005 et du format de la date et de l'heure :
 Le processus de normalisation actualise le champ Version du système d'origine en fonction de la date indiquée ou de celle sélectionnée dans le calendrier dans le paramètre Version du système d'origine. Lorsque vous exécutez un traitement Normalisation Bib MARC 21 qui utilise un processus de normalisation avec une date sélectionnée pour le paramètre Version du système d'origine, la date que vous spécifiez est appliquée à toutes les notices de l'ensemble sélectionné pour le traitement.
Le processus de normalisation actualise le champ Version du système d'origine en fonction de la date indiquée ou de celle sélectionnée dans le calendrier dans le paramètre Version du système d'origine. Lorsque vous exécutez un traitement Normalisation Bib MARC 21 qui utilise un processus de normalisation avec une date sélectionnée pour le paramètre Version du système d'origine, la date que vous spécifiez est appliquée à toutes les notices de l'ensemble sélectionné pour le traitement. - Mettre à jour les champs de la Version du système d'origine existante – Si la version du système d'origine sélectionnée (ci-dessus) remplace n'importe quelle version existante. Si elle n'est pas sélectionnée, la version existante reste telle quelle.
-
Mettre à jour le système d'origine – Le système d'origine que vous souhaitez identifier dans les métadonnées de la notice importée.
- Sélectionnez Enregistrer.
Pour exécuter le processus que vous venez de créer afin de mettre à jour les informations sur la Version du système d'origine pour un ensemble de notices, suivez les étapes de la page Exécuter des traitements manuels sur des ensembles définis. Facultativement, vous pouvez modifier/remplacer les paramètres Système d'origine et/ou Version du système d'origine lors de l'exécution du traitement.
Modifier des processus de validation
- Validation de correspondance Bib MARC 21 – définit la manière dont la validation est traitée lorsqu'une correspondance de notice bibliographique est effectuée durant le processus d'import ou dans l'Éditeur de métadonnées.
- Validation lors de l'enregistrement Bib MARC 21 – définit la manière dont la validation est traitée lors de l'import de notice MARC via un profil d'import, lors du catalogage d'exemplaire via une ressource externe (comme WorldCat ou LoC) et lors de l'enregistrement d'une notice bibliographique dans l'Éditeur de métadonnées.
- Validation de correspondance autorité MARC 21 – définit la manière dont la validation est traitée lorsqu'une correspondance de notice d'autorité est effectuée durant le processus d'import ou dans l'Éditeur de métadonnées.
- Validation lors de l'enregistrement autorité MARC 21 – définit la manière dont la validation est traitée lors de l'import de notices MARC via un profil d'import, lors du catalogage d'exemplaire via une ressource externe et lors de l'enregistrement d'une notice d'autorité dans l'Éditeur de métadonnées.
- Sélectionnez l'action Modifier sur la ligne correspondante au processus que vous souhaitez modifier dans l'onglet Processus de validation sur la page Détails du profil (Menu de configuration > Ressources > Catalogage > Configuration des métadonnées puis cliquez sur le lien d'un profil).
 Onglet Processus de validationLa page Détails du processus s'ouvre sur l'onglet Informations générales pour le processus de validation.
Onglet Processus de validationLa page Détails du processus s'ouvre sur l'onglet Informations générales pour le processus de validation. Processus de validation Onglet Informations générales
Processus de validation Onglet Informations générales -
Modifiez les détails relatifs à la validation si nécessaire en sélectionnant les onglets du processus de validation (Informations générales, Liste de tâches et Paramètres de tâches) pour accéder aux informations que vous souhaitez modifier.Sur l'onglet Liste de tâches, les tâches de validation décrites dans les tables ci-dessous peuvent :
- être ajoutées à l'aide du lien Ajouter des tâches ;
- être supprimées de la liste des tâches existantes à l'aide de l'action sur la ligne Supprimer ;
- voir leur ordre de priorité modifié dans la liste des tâches existantes, grâce aux flèches haut/bas.
Les tâches de validation décrites dans les tables Résumé des tâches de validation de configuration des métadonnées MARC21 Bibliographique et Résumé des tâches de validation de configuration des métadonnées MARC21 Autorité sont disponibles pour les processus de validation Bib Marc21 validation des correspondances et Bib Marc 21 validation à l'enregistrement, ainsi que Marc21 Autorité Validation des correspondances et Validation lors de l'enregistrement autorité MARC 21, respectivement.Résumé des tâches de validation de configuration des métadonnées MARC21 Bibliographique Validation Tâches Description MARC21 Validation des champs reconnus Valide que tous les champs sont reconnus par le profil. MARC 21 Validation des champs obligatoires Valide l'existence des champs obligatoires MARC21 Validation des champs répétables Valide les champs répétables. Validation des positions des champs fixés de la collection MARC 21 Valide les données légitimes dans le champ de contrôle. MARC21 Validation des champs variables Valide les données légitimes dans les indicateurs. MARC 21 Validation des sous-champs reconnus Valide que tous les sous-champs sont reconnus par le profil. MARC 21 Validation des sous-champs obligatoires Valide l'existence des sous-champs obligatoires MARC 21 Validation des sous-champs répétables Valide les sous-champs répétables. Marc21BibFindMatchesValidationTask Marc21Bib trouve s'il a la validation des correspondances. MARC21 Validation des sous-champs de vocabulaire Valide les données de vocabulaire. Valider une représentation graphique alternative Valide les représentations graphiques alternatives. Valider Bib_Heading Auteur Valide si les vedettes bibliographiques sont autorisées. Utilisez cette tâche pour vérifier que la cote locale est unique parmi toutes les notices bibliographiques du répertoire.
Pour cette tâche, vous pouvez préciser les paramètres de tâche suivants (à partir de l'onglet Paramètres de tâche) : 090, 091, 092, 093, 094, 095, 096, 097, 098, 099 et 905.
 Valide l'unicité des cotes locales
Valide l'unicité des cotes localesPar défaut, tous les champs 09X sont spécifiés. Vous pouvez également choisir d'ajouter 905 à la liste (qui valide $s dans le champ 905).
Lorsque vous affichez toute la liste déroulante, vous sélectionnez une valeur à supprimer ou cochez pour indiquer le champ 09X que vous voulez valider pour son unicité.
Dans le cas où tous les champs 09X ne sont pas sélectionnés, la vérification de l'unicité est faite pour le même champ 09X dans d'autres notices bibliographiques. Ainsi, par exemple, si vous sélectionnez le champ 093 dans la liste champs BIB pour la validation des cotes de rangement, le contrôle de validation compare tous les autres champs bibliographiques 093 du répertoire pour déterminer s’il existe des cotes de rangement en double.
Dans le cas où tous les champs 09X sont sélectionnés, la vérification de l'unicité est faite pour tous les champs 09X dans d'autres notices bibliographiques. Ainsi, par exemple, si la notice bibliographique a une cote de rangement locale dans le champ 093, le contrôle de validation compare tous les autres champs bibliographiques 09X (pas seulement du champ 093) du répertoire pour déterminer s’il existe des cotes de rangement en double.
Comme raccourci, vous pouvez sélectionner le x à côté du champ 09X pour le supprimer de la liste.
Pour plus d'informations, voir How to make a check on the uniqueness of the 090 call number when saving a record in the metadata editor (fichier .docx).
Valider le chiffre de vérification Autre numéro ou code normalisé
Lorsque vous configurez le profil bibliographique MARC21, sélectionnez cette tâche de validation pour valider les autres identifiants standard suivants dans le champ 024 :
- UPC (1er indicateur = 1)
- ISMN (1er indicateur = 2)
- IAN (1er indicateur = 3)
Une fois la tâche de validation Valider le chiffre de vérification Autre numéro ou code normalisé ajoutée à la liste des tâches sur l'onglet Liste de tâches, sélectionnez l'onglet Paramètres de tâche et indiquez les sous-champs que vous souhaitez valider dans le champ 024. Si vous spécifiez plusieurs sous-champs, séparez-les par une virgule et pas par des espaces.
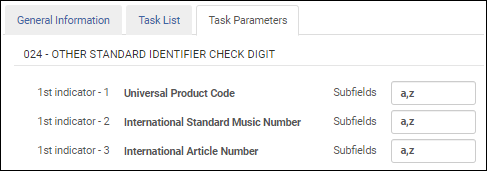 Paramètres de la tâche de validation d'autre numéro standard - MARC 21 / KORMARC
Paramètres de la tâche de validation d'autre numéro standard - MARC 21 / KORMARCValider le chiffre de vérification ISBN
Sélectionnez cette tâche de validation pour valider le numéro international normalisé du livre (ISBN).
Une fois la tâche de validation Valider le chiffre de vérification ISBN ajoutée à la liste des tâches sur l'onglet Liste de tâches, sélectionnez l'onglet Paramètres de tâche et sélectionnez Add fields and subfields pour indiquer les champs/sous-champs que vous souhaitez valider. Si vous spécifiez plusieurs sous-champs, séparez-les par une virgule et pas par des espaces.
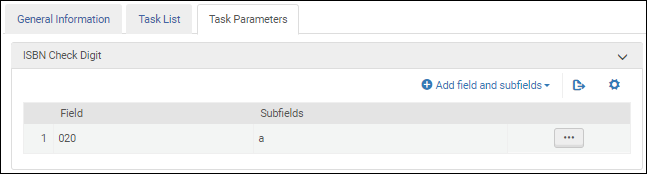 Paramètres de la tâche de validation d'ISBN - MARC 21/ KORMARC
Paramètres de la tâche de validation d'ISBN - MARC 21/ KORMARC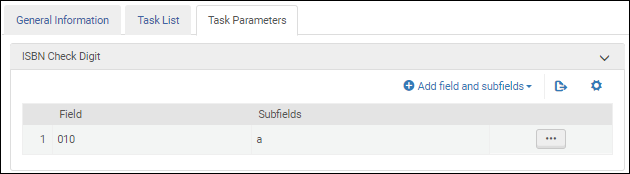 Paramètres de la tâche de validation d'ISBN - UNIMARC / CNMARC
Paramètres de la tâche de validation d'ISBN - UNIMARC / CNMARCValider des champs vides dans le profil bibliographique MARC21 Nouveau (Ceci est également valable pour les profils de configuration de métadonnées bibliographiques KORMARC, UNIMARC et CNMARC).
Après avoir ajouté la tâche de validation Valider des champs vides dans le profil bibliographique MARC21 Nouveau à la liste des tâches, sélectionnez l'onglet Paramètres de tâche et indiquez les champs vides que vous souhaitez valider. 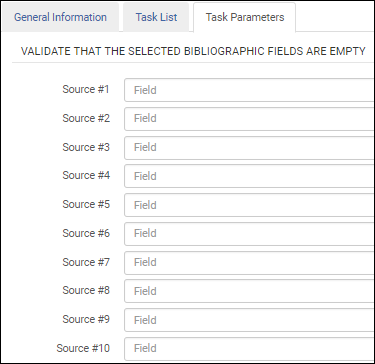 Champs à valider comme vides
Champs à valider comme videsPour définir un message d'erreur ou d'avertissement spécial pour cette validation, vous devez créer un Profil de gestion des erreurs. Pour plus d'informations, voir Travailler avec des profils de gestion des erreurs.
Ce processus de validation ne concerne que les nouvelles notices, pas celles existantes que vous êtes en train de mettre à jour.
Pour chaque fonctionnalité qui utilise le processus de validation (Éditeur de métadonnées, API, import, ligne de commande et catalogage rapide), un message d'erreur et d'avertissement est affiché lorsque la validation identifie un champ non vide dans l'onglet Paramètres de la tâche. Dans l'Éditeur de métadonnées, par exemple, les messages s'affichent de la manière suivante lorsque le champ 009 est configuré comme champ à valider sur l'onglet Paramètres de la tâche :
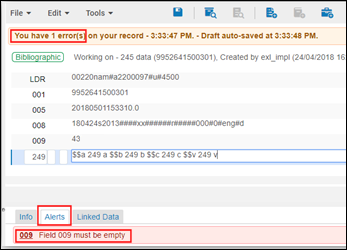 Messages de validation pour un champ non vide
Messages de validation pour un champ non videFormulaire de validation de matériel MARC21
Valide si la forme de matériel dans le champ 006 (position 0) correspond bien au type de matériel dans la position LDR.
Validate ISSN check digit
Sélectionnez cette tâche de validation pour valider le numéro international normalisé des publications en série (ISSN).
Une fois la tâche de validation Validate ISSN check digit ajoutée à la liste des tâches sur l'onglet Liste de tâches, sélectionnez l'onglet Paramètres de tâche et sélectionnez Add fields and subfields pour indiquer les champs/sous-champs que vous souhaitez valider. Si vous spécifiez plusieurs sous-champs, séparez-les par une virgule et pas par des espaces.
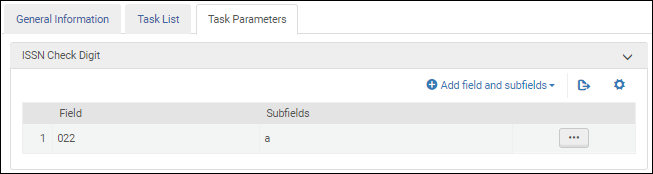 Paramètres de la tâche de validation d'ISSN - MARC 21/ KORMARC
Paramètres de la tâche de validation d'ISSN - MARC 21/ KORMARC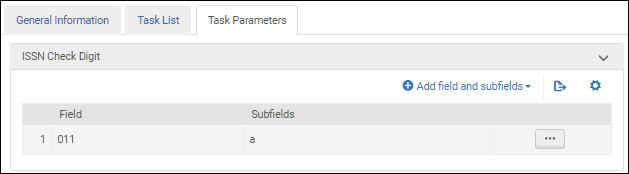 Paramètres de la tâche de validation d'ISSN - UNIMARC / CNMARC
Paramètres de la tâche de validation d'ISSN - UNIMARC / CNMARCValidate UPC check digit
Quand vous configurez le profil bibliographique UNIMARC, sélectionnez cette tâche de validation pour valider le code de produit universel (UPC).
Une fois la tâche de validation Validate UPC check digit ajoutée à la liste des tâches sur l'onglet Liste de tâches, sélectionnez l'onglet Paramètres de tâche et sélectionnez Add fields and subfields pour indiquer les champs/sous-champs que vous souhaitez valider. Si vous spécifiez plusieurs sous-champs, séparez-les par une virgule et pas par des espaces.
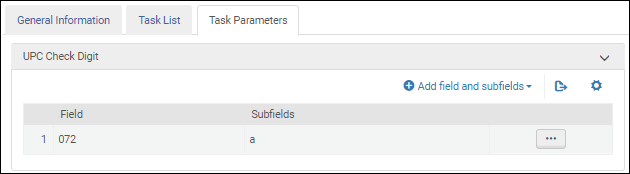 Paramètres de la tâche de validation de code de produit universel - UNIMARC / CNMARC
Paramètres de la tâche de validation de code de produit universel - UNIMARC / CNMARCValidate ISMN check digit
Quand vous configurez le profil bibliographique UNIMARC, sélectionnez cette tâche de validation pour valider le numéro international normalisé de la musique (ISMN).
Une fois la tâche de validation Validate ISMN check digit ajoutée à la liste des tâches sur l'onglet Liste de tâches, sélectionnez l'onglet Paramètres de tâche et sélectionnez Add fields and subfields pour indiquer les champs/sous-champs que vous souhaitez valider. Si vous spécifiez plusieurs sous-champs, séparez-les par une virgule et pas par des espaces.
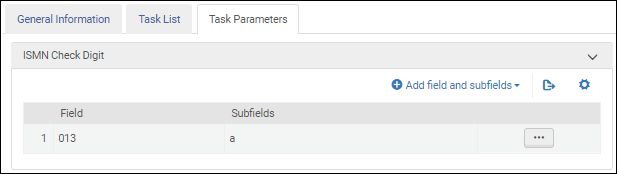 Paramètres de la tâche de validation du numéro international normalisé de la musique - UNIMARC / CNMARC
Paramètres de la tâche de validation du numéro international normalisé de la musique - UNIMARC / CNMARCUne fois la tâche de validation Validate IAN check digit ajoutée à la liste des tâches sur l'onglet Liste de tâches, sélectionnez l'onglet Paramètres de tâche et sélectionnez Add fields and subfields pour indiquer les champs/sous-champs que vous souhaitez valider. Si vous spécifiez plusieurs sous-champs, séparez-les par une virgule et pas par des espaces.
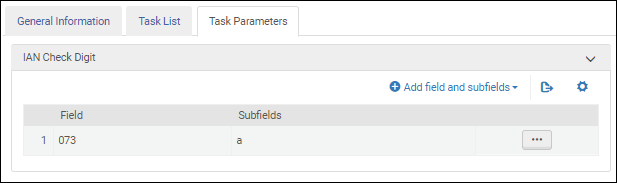 Paramètres de la tâche de validation du numéro international de l'article - UNIMARC / CNMARC
Paramètres de la tâche de validation du numéro international de l'article - UNIMARC / CNMARC - Lorsque vous avez terminé vos modifications des détails de processus sur les onglets Informations générales, Liste de tâches et Paramètres de tâche, sélectionnez Enregistrer.
Travailler avec des profils de gestion des erreurs
- MARC XML Bib Import - Il est recommandé de sélectionner ce profil d'exception pour traiter des données invalides au fur et à mesure de leur importation.
- MARC XML Mise à jour des métadonnées bibliographique lors de l'enregistrement – Ce profil de gestion des erreurs est utilisé lors du catalogage d'exemplaire via une ressource externe (telle que WorldCat ou LoC) et lors du catalogage/de l'enregistrement d'une notice bibliographique dans l'Éditeur de métadonnées.
À l'inverse des profils de validation (voir Modifier des processus de validation), vous définissez un comportement par défaut et vous pouvez également définir des exceptions à ce comportement. La section supérieure de la page vous permet de spécifier la sévérité par défaut, qui correspond à la sévérité par défaut de tous les problèmes de validation détectés dans la notice. Dans la section inférieure, vous pouvez spécifier des exceptions à cette valeur par défaut. Il s'agit des règles que vous souhaitez traiter de la manière opposée à la valeur par défaut. Dans la capture d'écran ci-dessous, comme la valeur par défaut est réglée sur « Avertissement », tout ce qui se trouve dans la liste d'exception sera traité comme une erreur, car il s'agit d'une exception à la valeur par défaut.
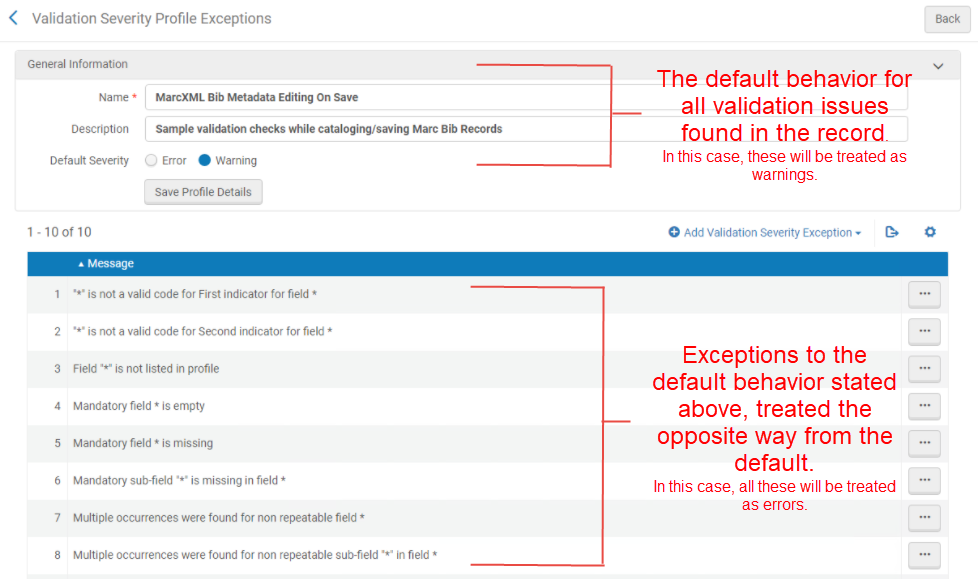
Sur cette page, vous pouvez également modifier ou copier les profils existants. Vous pouvez supprimer les profils que vous avez créés.
Ajouter un profil de gestion des erreurs
- Sur la page Détails du profil (Menu de configuration > Ressources > Catalogage > Configuration des métadonnées et cliquez sur le lien d'un profil), sélectionnez l'onglet Liste des profils de gestion des erreurs.
Sélectionnez Ajouter un profil de sévérité pour la validation.
 Pour copier un profil d'exception de validation existant et le modifier pour en créer un nouveau, sélectionnez l'action Copier sur la ligne et modifiez le profil en double afin qu'il corresponde à vos exigences (voir Modifier un profil de gestion des erreurs).
Pour copier un profil d'exception de validation existant et le modifier pour en créer un nouveau, sélectionnez l'action Copier sur la ligne et modifiez le profil en double afin qu'il corresponde à vos exigences (voir Modifier un profil de gestion des erreurs). - Renseignez les éléments suivants pour le profil de gestion des erreurs :
- Un nom (requis) et une description pour le profil de validation de la sévérité que vous souhaitez ajouter
- Sélectionnez Erreur ou Avertissement pour indiquer le degré de sévérité par défaut. Cette dernière détermine si les violations des paramètres de champs définis dans l'onglet Champs (par exemple, obligatoire, non-répétable) sont traitées comme des avertissements (pouvant être ignorés) ou comme des erreurs (devant être résolues).
- Sélectionnez Ajouter un profil de sévérité pour la validation. Le profil est ajouté à la liste des Profils de gestion des erreurs. Voir Modifier un profil de gestion des erreurs pour plus d'informations sur l'ajout d'un message à votre profil de gestion des erreurs.
Modifier un profil de gestion des erreurs
- Dans l'onglet Liste des profils de gestion des erreurs sur la page Détails du profil (Menu de configuration > Ressources > Catalogage > Configuration des métadonnées et cliquez sur le lien d'un profil), sélectionnez Modifier dans la liste des actions sur la ligne du profil de gestion des erreurs que vous souhaitez mettre à jour.
- Dans la section Informations générales, modifiez le nom, la description ou la sévérité par défaut si besoin.
- Dans la section Message, sélectionnez Supprimer dans la liste des actions possibles sur la ligne pour supprimer les messages indésirables.
- Sélectionnez Ajouter une exception au blocage de validation puis un message d'exception de validation dans la liste déroulante Message.
La syntaxe des messages de la liste déroulante Message n'est pas configurable. - Sélectionnez Ajouter un niveau de gestion des erreurs.
- Sélectionnez Enregistrer les détails du profil puis cliquez sur Retour.
Configurer d'autres paramètres
- Sélectionnez une Règle de niveau de notice abrégée (voir Définir la règle par défaut de niveau de notice abrégée dans la Configuration des métadonnées).
- Sélectionnez les paramètres pour traiter certains champs d'une façon particulière quand vous sauvegardez des notices (voir Configurer d'autres paramètres)
Configurer d'autres paramètres
- Désactiver la suppression 003 - Sélectionnez ce paramètre pour maintenir le contenu du champ 003 quand vous sauvegardez des notices. Quand ce paramètre n'est pas sélectionné, le comportement par défaut lors de la sauvegarde d'une notice est de supprimer le champ 003 après avoir concaténé son contenu avec l'ID MMS du champ 001 pour créer un ID comme (OCoLC) 35397863 placé dans le champ 035.
- Exclure la génération de 035 sur la base d'un ID MMS - Sélectionnez cette option pour désactiver la génération automatique du champ 035 qui concatène les contenus du champ 003 avec l'ID MMS dans le champ 001 quand on sauvegarde des notices.
- Générer 035 depuis 001 uniquement - (profils de configuration des métadonnées d'autorité et bibliographique UNIMARC uniquement) Sélectionnez cette option pour créer un champ 035 depuis les contenus du champ 001 (ID MMS) quand vous sauvegardez des notices.
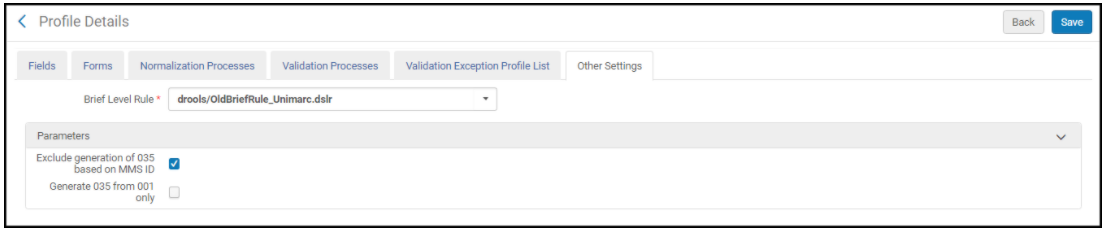 Onglet Autres paramètres de configuration des métadonnées pour UNIMARC
Onglet Autres paramètres de configuration des métadonnées pour UNIMARC - Ajouter une représentation graphique alternative – Utilisez ce paramètre pour ajouter ou omettre l'indication de langue du script dans le sous-champ $6 lors de la création du champ 880. Lorsque vous sélectionnez ce paramètre, l'indicateur de langue du script est ajouté au sous-champ $6 dans le champ 880. Voir Travailler avec les champs liés 880 dans les notices bibliographiques pour plus d'informations.
Travailler avec la normalisation et la validation des champs UNIMARC
- Sélectionner le lien Bibliographique UNIMARC sur la page Liste de configuration des métadonnées (Menu de configuration > Ressources > Catalogage > Configuration des métadonnées). La page Détails du profil s'ouvre.
- Sélectionnez l'onglet Processus de normalisation. Le processus de normalisation par défaut apparaît sur l'onglet Processus de normalisation :
- Bib Unimarc Normalisation initiale
- Bib Unimarc Normaliser lors de l'enregistrement
- Bib Unimarc Reséquencer
- Bib Unimarc Reséquencer et effacer les champs vides
-
Sélectionnez Modifier dans la liste des actions possibles sur la ligne pour l'un des processus de normalisation et sélectionnez l'onglet Liste de tâches pour consulter les tâches UNIMARC fournies.Voir Configuring the Task UnimarcBibAdd005Task for SBN / UNIMARC pour plus d'informations.
- Lorsque vous avez terminé, cliquez sur Enregistrer.
- Sélectionner le lien Bibliographique UNIMARC sur la page Liste de configuration des métadonnées (Menu de configuration > Ressources > Catalogage > Configuration des métadonnées). La page Détails du profil s'ouvre sur l'onglet Champs.
- Recherchez un des champs 9XX.
- Sélectionnez Personnaliser dans la liste des actions possibles sur la ligne afin de consulter les sous-champs et indicateurs disponibles pour la personnalisation.
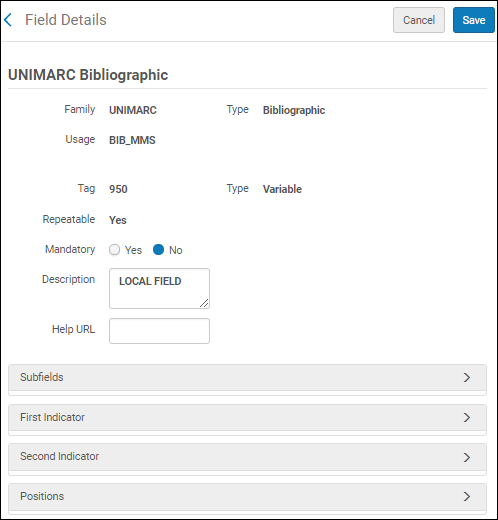 Détails du champ UNIMARC
Détails du champ UNIMARC - Agrandissez les sections Sous-champs, Premier indicateur et Deuxième indicateur pour voir les options personnalisables.
- Sélectionner le lien Bibliographique UNIMARC sur la page Liste de configuration des métadonnées (Menu de configuration > Ressources > Catalogage > Configuration des métadonnées). La page Détails du profil s'ouvre sur l'onglet Champs.
- Filtrez l'onglet Champs en sélectionnant l'option 1XX : Bloc des informations codées.
- Pour le champ 100, sélectionnez Consulter dans la liste des actions possibles sur la ligne. La page Détails du champ s'ouvre.
- Agrandissez la section Positions pour voir les positions en attente de validation.
Les validations de position suivantes ont été ajoutées pour UNIMARC :
- Date de création de la notice
- Type de date
- Date de publication 1
- Date de publication 2
- Lorsque vous avez terminé, cliquez sur Retour pour revenir sur la page Liste de configuration des métadonnées.
Gestion des notices d'autorité locale UNIMARC
- Sur la page Liste de configuration des métadonnées (Menu de configuration > Ressources > Catalogage > Configuration des métadonnées), sélectionnez Ajouter une autorité locale. La fenêtre popup Ajouter une autorité locale apparaît.
- Complétez les paramètres requis pour le profil d'autorité locale UNIMARC.
- Nom – Saisissez le nom du vocabulaire que vous voulez afficher sur la page Registre d'autorité locale du profil.
- Code – Indiquez le code de vocabulaire que vous voulez afficher lors de la configuration de votre profil d'import, par exemple.
- Famille – Sélectionnez UNIMARC dans la liste déroulante.
- Type – Sélectionnez un des types suivants dans la liste déroulante :
- Sujet
- Nom
- Noms et sujets
- Classification
- Préfixe d'identifiant direct – Indiquez le préfixe d'identifiant s'il est utilisé.
- Multilingue – Sélectionnez Oui ou Non dans la liste déroulante.
- Cliquez sur Ajouter et fermer. Le registre d'autorité locale que vous avez créé apparaît dans la liste sur la page Registre d'autorité locale.
- Cliquez sur Enregistrer. Votre profil d'autorité locale apparaît dans la liste sur la page Liste de configuration des métadonnées.
- Sélectionner le lien Autorité UNIMARC pour ouvrir la page Détails du profil et configurer les champs, la normalisation et la validation comme MARC 21.
- Lorsque vous avez terminé de faire des modifications, cliquez sur Déployer.
Travailler avec la normalisation et la validation des champs KORMARC
- Ouvrez la page Liste de configuration des métadonnées (Menu de configuration > Ressources > Catalogage > Configuration des métadonnées).
- Sélectionner le lien Bibliographique KORMARC . La page Détails du profil s'ouvre.
- Sélectionnez l'onglet Processus de normalisation. Le processus de normalisation par défaut apparaît sur l'onglet Processus de normalisation :
- Bib Kormarc Normaliser à l'enregistrement
- Bib Kormarc Reséquencer
- Bib Kormarc Reséquencer et effacer les champs vides
- Sélectionnez Modifier dans la liste des actions possibles sur la ligne pour l'un des processus de normalisation et sélectionnez l'onglet Liste de tâches pour consulter les tâches KORMARC fournies.
- Lorsque vous avez terminé, cliquez sur Enregistrer.
Travailler avec la normalisation et la validation des champs CNMARC
- Ouvrez la page Liste de configuration des métadonnées (Menu de configuration > Ressources > Catalogage > Configuration des métadonnées).
- Sélectionner le lien Bibliographique CNMARC. La page Détails du profil s'ouvre.
- Sélectionnez l'onglet Processus de normalisation. Les processus de normalisation par défaut apparaissent sur l'onglet Processus de normalisation :
- Bib CNMARC Normalisation initiale
- Bib Cnmarc Normaliser à l'enregistrement
- Bib CNMARC Normaliser lors d'une recherche Z39.50/SRU
- Bib Cnmarc Reséquencer
- Bib Cnmarc Reséquencer et effacer les champs vides
- Sélectionnez Modifier dans la liste des actions possibles sur la ligne pour l'un des processus de normalisation et sélectionnez l'onglet Liste de tâches pour consulter les tâches CNMARC fournies. Voir la table Options de la Liste des tâches pour une explication des tâches de normalisation.
- Lorsque vous avez terminé, cliquez sur Enregistrer.
Travailler avec la normalisation et la validation des champs MODS
- Ouvrez la page Liste de configuration des métadonnées (Menu de configuration > Ressources > Catalogage > Configuration des métadonnées).
- Sélectionnez le lien MODS. La page Détails du profil s'ouvre.
- Sélectionnez l'onglet Processus de normalisation. Le processus de normalisation par défaut apparaît sur l'onglet Processus de normalisation :
- Ajouter une notice bibliographique MODS à la collection
- Normalisation Bib MODS lors de l'enregistrement
- Supprimer des notices Bib de la découverte MODS
- Sélectionnez Modifier dans la liste des actions possibles sur la ligne pour l'un des processus de normalisation et sélectionnez l'onglet Liste de tâches pour consulter les tâches MODS fournies.
- Sélectionnez Ajouter des tâches pour ajouter une tâche au processus. La table suivante liste les tâches MODS disponibles :
Tâche Description ModsDroolNormalization Sélectionnez les règles de normalisation à exécuter depuis l'onglet Paramètres de tâche. addBibToCollectionNormalizationTask Ajouter la notice bibliographique à une collection MmsTagSuppressed Définit le marqueur Supprimé de MMS MODS Gère la tâche de migration Copier les handles des métadonnées de la notice bibliographique dans le champ Identifiant de handle de la notice. Mettre à jour l'identifiant de notice avec l'identifiant MMS Met à jour l'élément recordIdentifier avec l'identifiant MMS. Cochez la case Record Change in a recordIdentifier Element pour enregistrer la modification de l'élément recordinfoNote sous l'élément recordIdentifier . - Sélectionnez les tâches que vous souhaitez ajouter.
- Une fois que vous avez terminé, cliquez sur Ajouter et fermer, puis cliquez sur Enregistrer.
Travailler avec les champs, la normalisation et la validation Dublin Core
- Ouvrez la page Liste de configuration des métadonnées (Menu de configuration > Ressources > Catalogage > Configuration des métadonnées).
- Sélectionner le lien Dublin Core qualifié. La page Détails du profil s'ouvre.
- Sélectionnez l'onglet Processus de normalisation. Le processus de normalisation par défaut apparaît sur l'onglet Processus de normalisation :
- Ajouter BIB à la collection
- DC qualifié Bib Normaliser à l'enregistrement
- Dublin Core qualifié Bib Normaliser lors d'une recherche sur Z39.50/SRU
- Sélectionnez Modifier dans la liste des actions possibles sur la ligne pour l'un des processus de normalisation et sélectionnez l'onglet Liste de tâches pour consulter les tâches Dublin Core fournies.
- Lorsque vous avez terminé, cliquez sur Enregistrer.
Travailler avec des profils d'application DC
- Dans l'Éditeur de métadonnées, quand vous ajoutez des champs à une notice Dublin Core (Ressources > Ouvrir l'Éditeur de métadonnées).
- Dans le champ Format de notice, quand vous ajoutez une représentation dans le champ Format de notice (Ressources > Ajouter une représentation numérique).
- Dans le champ Format de notice, quand vous ajoutez une nouvelle collection (Ressources > Gérer les collections).
- Dans le champ Format cible, lors de la configuration des profils d'import (Ressources > Gérer les profils d'import).
- Dans le champ Formats de notice bibliographique à inclure, quand vous exécutez le traitement Exporter des titres numériques (Admin > Exécuter un traitement).
- Dans les sections où vous configurez les métadonnées qui apparaissent dans Alma :
- Dans les Index de recherche, où vous configurez les champs à rechercher dans le répertoire Alma (Configuration > Ressources > Configuration de la recherche > Index de recherche).
- Dans Métadonnées de profils de service d'accès, où vous configurez les champs de métadonnées qui sont affichés quand vous consultez du contenu numérique dans la visionneuse Alma (Configuration > Services aux usagers > Métadonnées de profils de service d'accès).
Profils d'application DC - Onglet Informations générales
Ajouter des champs aux profils d'application DC
- Standard – permet d'ajouter un champ DC qualifié standard. Les éléments suivants apparaissent :
 Ajouter un champ standard
Ajouter un champ standard- Dans la liste déroulante Champ, sélectionnez un champ DC adéquat.
- Entrez une description pour le champ.
- Sélectionnez une langue.
- Choisissez si vous voulez que le champ soit obligatoire – Oui/Non.
- Choisissez si vous voulez que le champ soit répétable – Oui/Non.
- Local – permet d'ajouter un champ DC local Les éléments suivants apparaissent :
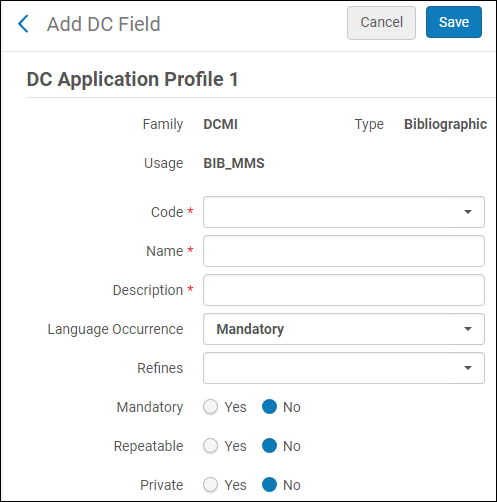 Ajouter un champ local
Ajouter un champ local- Dans le champ Code, sélectionnez un code pour le champ DC local.
- Entrez un nom pour le champ DC local.
- Renseignez une description pour le champ DC local.
- Sélectionnez une langue.
- Dans le champ Affiner, vous pouvez sélectionner un champ DC simple qui contiendra la valeur du champ local quand il est exporté.
- Choisissez si vous voulez que le champ soit obligatoire – Oui/Non.
- Choisissez si vous voulez que le champ soit répétable – Oui/Non.
- Choisissez si vous voulez que le champ soit privé – Oui/Non. Si vous sélectionnez Oui, le champ n'est pas exporté (mais il est indexé).
- Il est possible d’ajouter un total de 50 champs locaux dans l’ensemble des profils sur lesquels des champs locaux peuvent être configurés (DCAP1, DCAP2 et ETD).
- Configurez chaque champ local une seule fois sur l’ensemble des profils, c’est-à-dire que vous ne devez pas répéter le même code de champ local dans plusieurs profils.
Travailler avec le profil Autorité GND
- Des index de recherche qui facilitent la recherche de notices GND (voir la section Conversion des index de recherche d'autorité GND )
- Des définitions de champ/sous-champ qui aident lors du catalogage
- Définissant tous les champs GND, notamment les définitions obligatoires
- Mettant en place les vocabulaires contrôlés GND
- Définissant des règles de normalisation spécifiques
Travailler avec des profils de collections MARC 21
- Champs
- Processus de normalisation
- Processus de validation
- Liste des profils de gestion des erreurs
Contrôler l'affichage et l'accès des autorités globales dans l'Éditeur de métadonnées
- Géré localement
La colonne Géré localement vous permet d'identifier quels vocabulaires d'autorité afficher dans l'Éditeur de métadonnées. Pour ce faire, vous pouvez activer ou désactiver les vocabulaires dans cette colonne.
- Géré dans la Communauté
La colonne Géré dans la Communauté identifie les vocabulaires qui sont conservés dans la Zone de communauté. Notez que cette colonne n'a qu'une valeur informative. Il n'existe pas d'option vous permettant d'activer ou de désactiver la ligne du vocabulaire dans cette colonne.
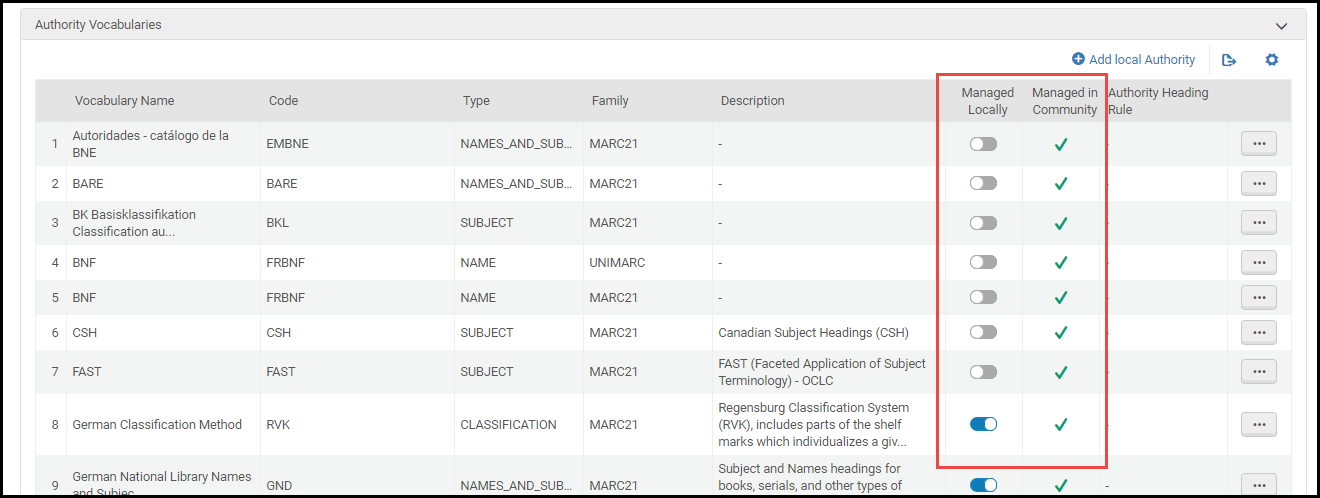
- Les onglets Modèles et Notices dans l'Éditeur de métadonnées
- Les options de notice sous Fichier > Nouveau dans l'Éditeur de métadonnées
- La liste déroulante des options du paramètre Code de vocabulaire sur la page Détails du profil d'import
- Ouvrez la page Liste de configuration des métadonnées (Menu de configuration > Section Catalogage > Configuration des métadonnées). La page Liste de configuration des métadonnées apparaît.
Dans l'Éditeur de métadonnées, la liste d'options sous Fichier > Nouveau affiche les options du vocabulaire qui est identifié comme étant Géré localement dans la configuration des métadonnées.
 Options du vocabulaire d'autorité dans l'Éditeur de métadonnées
Options du vocabulaire d'autorité dans l'Éditeur de métadonnées - Cochez les cases dans la colonne Géré localement pour indiquer les vocabulaires que vous voulez afficher dans l'Éditeur de métadonnées (et dans le Profil d'import).
Configurer la liste de vocabulaires contrôlés
- Administrateur de catalogue
- Administrateur général du système
- Créez un vocabulaire contrôlé.
- Attribuez le vocabulaire contrôlé à un sous-champ spécifique MARC 21.
- Consulter les détails d'un vocabulaire contrôlé (sélectionnez Consulter dans la liste d'actions)
- Ajouter un vocabulaire contrôlé (voir Ajouter/Modifier un vocabulaire contrôlé)
- Ajouter ou supprimer les valeurs de code d'un vocabulaire contrôlé (voir Ajouter/Modifier un vocabulaire contrôlé)
- Restaurer un vocabulaire contrôlé modifié dans sa forme prédéfinie (sélectionnez Restaurer dans la liste d'actions)
- Supprimer un vocabulaire contrôlé ajouté (sélectionnez Supprimer dans la liste des actions possibles sur la ligne)
Ajouter/Modifier un vocabulaire contrôlé
- Sur la page Liste de vocabulaires contrôlés (Menu de configuration > Ressources > Catalogage > Liste de vocabulaires contrôlés), cliquez sur Ajouter un vocabulaire contrôlé. La page Détails du vocabulaire contrôlé s'ouvre.
- Renseignez un nom et une description.
Ce nom et cette description apparaissent ensuite sur la page Liste de vocabulaires contrôlés et dans la liste d'options déroulante pour Choisir un vocabulaire contrôlé lorsque vous attribuez un vocabulaire contrôlé à un sous-champ MARC 21 dans le profil de configuration des métadonnées. Voir l'étape 4 dans la section Modifier les champs ci-dessus. Notez que vous ne pouvez utiliser ce vocabulaire contrôlé dans l'Éditeur de métadonnées qu'après l'avoir attribué à un sous-champ MARC 21, comme indiqué dans l'étape 4 ci-dessous.
- Après avoir ajouté au moins un nom de vocabulaire contrôlé, cliquez sur Enregistrer pour enregistrer toute modification future dans la description.
- Dans la section Ajouter une nouvelle valeur, indiquez un code ainsi qu'une description. Notez que le code peut contenir des espaces ou des caractères spéciaux, mais pas de délimiteur de sous-champ.
Le code renseigné est le terme qui est validé ou fourni comme option lors de la saisie d'une notice dans l'Éditeur de métadonnées.
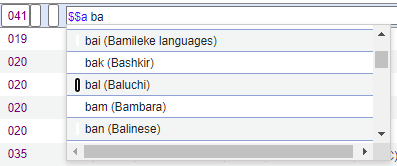 Exemple de vocabulaire contrôléDans l'exemple ci-dessus, les codes que vous entrez apparaissent en premier dans chaque ligne et la description s'affiche à droite de chaque code entre parenthèses.La description associée au code que vous avez saisi dans la liste de vocabulaires contrôlés peut fournir des informations supplémentaires sur le terme saisi.
Exemple de vocabulaire contrôléDans l'exemple ci-dessus, les codes que vous entrez apparaissent en premier dans chaque ligne et la description s'affiche à droite de chaque code entre parenthèses.La description associée au code que vous avez saisi dans la liste de vocabulaires contrôlés peut fournir des informations supplémentaires sur le terme saisi. - Cliquez sur Ajouter. La valeur du code est ajoutée à la liste des vocabulaires contrôlés.
- Répétez les étapes 3 et 4 pour ajouter des valeurs de code supplémentaires (termes).
- Cliquez sur Supprimer à côté de n'importe quelle valeur de code pour la supprimer. Un message d'avertissement s'affiche si vous tentez de supprimer une valeur de code qui était incluse à l'origine dans un vocabulaire intégré par défaut.
- Cliquez sur Annuler pour revenir à la page Liste de vocabulaires contrôlés.
- Sur la page Liste de vocabulaires contrôlés (Menu de configuration > Ressources > Catalogage > Liste de vocabulaires contrôlés), sélectionnez Actions > Configurer ou Actions > Modifier. La page Détails du vocabulaire contrôlé s'ouvre.
- Suivez les étapes décrites dans la procédure ci-dessus, en commençant par l'étape 3.
Configurer la liste de vocabulaires contrôlés - Formulaires
- Administrateur de catalogue
- Administrateur général du système
- Sur la page Liste de vocabulaires contrôlés - Formulaires (Menu de configuration > Ressources > Catalogage > Liste de vocabulaires contrôlés - Formulaires), cliquez sur Ajouter un vocabulaire contrôlé. La page Détails du vocabulaire contrôlé s'ouvre.
- Renseignez un nom et une description. Ce nom et cette description s'affichent sur la page Liste de vocabulaires contrôlés et dans la liste déroulante des options du champ Vocabulaire lors de la configuration des formulaires.
- Depuis la page Liste de vocabulaires contrôlés - Formulaires, sélectionnez le vocabulaire.
- Sélectionnez Ajouter une ligne.
- Saisissez un code, une description et sélectionnez une valeur par défaut, si vous le souhaitez. Cette description correspond au terme fourni comme option aux utilisateurs pour le champ.
- Sélectionnez Ajouter une ligne.
- Ajoutez des lignes supplémentaires pour ajouter des valeurs supplémentaires au vocabulaire.
Configurer les listes de numéros d'auteur
- Administrateur de catalogue
- Administrateur général du système
Configurer les listes de numéros d'auteur standard
- cutter_three_figure_cn.txt
- cutter_three_figure_kor.txt
- lee_jai_chul_1.txt
- lee_jai_chul_2.txt
- lee_jai_chul_3.txt
- lee_jai_chul_4.txt
- lee_jai_chul_5.txt
- lee_jai_chul_6.txt
- lee_jai_chul_7.txt
- lee_jai_chul_8.txt
- Sur la page Table de conversion Listes de numéros d'auteur (Menu de configuration > Ressources > Catalogage > Listes de numéros d'auteur), sélectionnez Personnaliser dans la ligne qui contient la table de conversion des numéros d'auteur que vous voulez utiliser. Pour plus d'informations sur les tables de conversion, voir Tables de conversion.
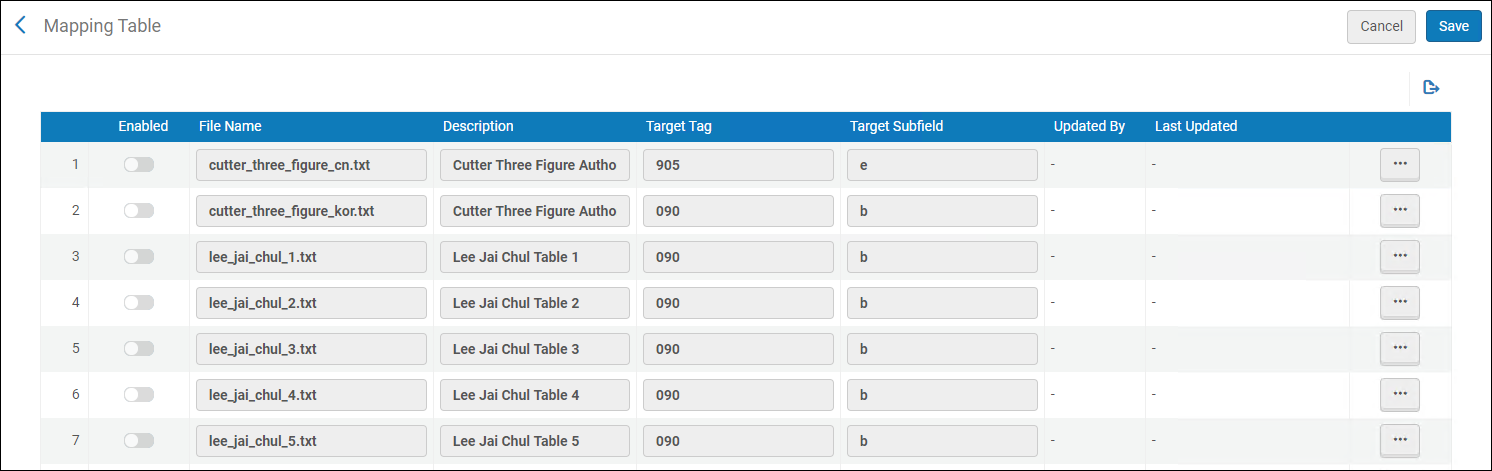 Page Table de conversion Liste des numéros d'auteur
Page Table de conversion Liste des numéros d'auteur - Confirmez que les options Étiquette cible et Sous-champ cible sont personnalisés pour correspondre à vos besoins. Faites des modifications si nécessaire.
- Sélectionnez Enregistrer.
Lee Jai Chul Méthode Logique
La méthode Lee Jai Chul est implémentée dans Alma à l'aide de la logique suivante :
- Le nom de l'auteur coréen est supposé exister dans le champ dans lequel le curseur est positionné. Si aucun nom n'est trouvé dans ce champ, aucun numéro d'auteur n'est généré.
- Le premier caractère Hangul du nom de l'auteur est stocké, et le deuxième caractère du nom de l'auteur est divisé en Hangul Jamo avec un tableau de consonnes et voyelles Hangul (avec deux ou trois Jamo par Hangul comme 도 > ㄷ et ㅗ). Si le premier caractère du nom de l'auteur correspond à l'un des noms de famille les plus populaires, le code de la table de conversion pour le premier Jamo (consonne) et le second Jamo (voyelle) est concaténé. Sinon, le code est récupéré dans la table de conversion pour le premier Jamo.
- Le numéro d'auteur généré est une chaîne qui résulte de la manipulation du premier et second caractères Hangul décrits au point précédent. Cette chaîne est placée dans le champ/sous-champ identifié dans la configuration Listes de numéros d'auteur.
- Le numéro de l'auteur une fois généré peut être modifié par le catalogueur.
- Si le paramètre défini par Ex Libris pour la méthode Lee Jai Chul (pour les noms de l'auteur) contient un astérisque (*), tous les noms sont considérés comme les plus populaires.
Cette logique comprend les exceptions suivantes :
- Lorsque les 5ème, 6ème ou 8ème tables de la méthode Lee Jai Chul sont utilisées et si le premier Jamo est ㄱ, le second Jamo est codé peu importe si le premier caractère est un des noms de famille les plus populaires. Par exemple lors de l'utilisation de la 5ème table, 추경석 > 추14 (et non “추1”).
- Si le code en chiffres pour le premier Jamo comprend deux chiffres, il n'y a pas besoin d'attribuer un code pour le second. Par exemple, lors de l'utilisation de la 2ème table, 정필모> 정84.
- Dans le cas d'un nom d'auteur séparé par une virgule, la virgule et l'espace qui la suit sont copiés vers le numéro d'auteur généré. Par exemple lors de l'utilisation de la 5ème table, 맨, 마가레트 > 맨, 3.
- Lorsque la tâche de distinction de cote définie par l'utilisateur dans la validation au moment du processus d'enregistrement est configurée (voir Valider la collection MARC 21 à l'enregistrement), les doublons sont vérifiés pour trouver un éventuel numéro d'auteur identique dans le répertoire entier. En cas de correspondance, le système affiche un message au catalogueur.
- Certaines tables ont des dépendances qui sont prises en considération. Par exemple lors de l'utilisation de la 3ème table :
- 3 v ㅏ -ㄱㄷㅊ 1
Cela signifie que si la valeur du premier Jamo n'est pas ㄱ, ㄷ, ou ㅊ, le code pour le second Jamoㅏ est 1.
- 3 v ㅓ ㄱㄷ 3
Cela signifie que si la valeur du premier Jamo est ㄱ ouㄷ, le code pour le second Jamo ㅏ est 3.
- 3 v ㅏ -ㄱㄷㅊ 1
Configurer la translittération personnalisée pour la génération de liste de numéros d'auteur
- Hangul (en points de code hexadécimal)
- Hangul romanisé
- Description du caractère
- Cliquez sur l'option Table locale de translittération pour la configuration de numéros d'auteur (Menu de configuration > Ressources > Catalogage > Table locale de translittération pour la configuration de numéros d'auteur). La page local_transliteration_author_number.txt s'affiche.
 Page local_transliteration_author_number.txt
Page local_transliteration_author_number.txt - Copiez/collez votre fichier de translittération personnalisée dans l'espace fourni pour le Contenu.
- Sélectionnez Enregistrer.
Niveau de catalogage par défaut appliqué aux nouvelles notices créées par l'importation de métadonnées
Quand une nouvelle notice est créée à partir du fichier d'entrée, le niveau catalogueur de cette notice correspond au niveau catalogueur par défaut, ou au niveau « 00 », si aucun niveau par défaut n'est défini.
Nous vous recommandons de définir une valeur par défaut dans la configuration « Niveau de permission du catalogueur ». Voir Droits de catalogage pour plus d'informations.
Configurer le niveau catalogueur pour des contributions à des autorités gérées en externe
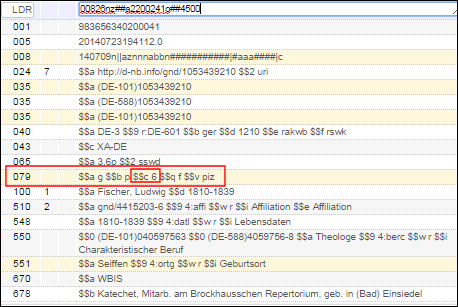
- Sur la table de conversion du niveau catalogueur vers code de vocabulaire (Menu de configuration > Ressources > Catalogage > Conversion du niveau catalogueur pour l'autorité externe), cliquez sur Ajouter une ligne pour convertir un niveau catalogueur Alma vers le niveau catalogueur d'un système externe.
- Sélectionnez un des niveaux catalogueurs Alma. Les niveaux catalogueurs sont déterminés par la configuration Niveau de permission du catalogueur. Voir Droits de catalogage pour plus d'informations.
- Indiquez l'un des niveaux catalogueurs du système externe à convertir vers celui d'Alma sélectionné.
- Sélectionnez Vrai ou Faux pour indiquer si la conversion que vous créez pourle niveau correspond à la conversion par défaut.
Étant donné que la table de conversion vous permet de spécifier des relations entre de nombreux éléments, vous devez indiquer laquelle des relations correspond à la conversion par défaut.
- Sélectionnez le vocabulaire pertinent.
Actuellement, les options sont les suivantes : GND et BARE.
- Sélectionnez Ajouter une ligne.
Si vous avez besoin de modifier une conversion, sélectionnez l'action Supprimer pour la conversion que vous souhaitez modifier puis créez-en une nouvelle. - Lorsque vous avez terminé d'effectuer vos modifications, sélectionnez Enregistrer ou Enregistrer et distribuer. Voir Gestion centralisée des tables de configuration pour plus d'informations, notamment une explication sur l'option Arrêter la gestion du réseau.
Configurer plusieurs points d'accès pour les champs 6XX CNMARC
- Cliquez sur Configuration de vedettes multiples dans les champs CNMARC 6XX dans la section Catalogage de la Configuration de la gestion des ressources (Menu de configuration > Ressources > Catalogage > Configuration de vedettes multiples dans les champs CNMARC 6XX). La table de conversion Catégorie 6XX CNMARC s'ouvre. Pour plus d'informations sur les tables de conversion, voir Tables de conversion.
- Sélectionnez Ajouter une ligne, renseignez le champ 6XX, sa description, puis cliquez sur Ajouter une ligne pour le champ 6XX que vous voulez segmenter.
 Champ 6XX CNMARC ajouté
Champ 6XX CNMARC ajouté - Répétez l'étape 2 pour tous les champs 6XX que vous voulez ajouter à la table de conversion Catégorie 6XX CNMARC.
- Quand vous avez fini d'ajouter ces champs 6XX, cliquez sur Personnaliser.
Configurer plusieurs points d'accès pour UNIMARC
- Cliquez sur Configuration de plusieurs identifiants d'autorité UNIMARC dans la section Catalogage de la Configuration de la gestion des ressources (Menu de configuration > Ressources > Catalogage > Configuration de plusieurs identifiants d'autorité UNIMARC). La liste des champs UNIMARC 6XX contrôlés par plusieurs notices d'autorité s'affiche. Pour plus d'informations sur les tables de conversion, voir Tables de conversion.
 UNIMARC 6XX Fields
UNIMARC 6XX Fields - Activez ou désactiver les champs 6XX que vous souhaitez utiliser pour plusieurs identifiants d'autorité et modifiez le champ Description pour répondre à vos préférences.
- Lorsque vous avez terminé, cliquez sur Personnaliser.
MARC Configuration Slim
Conversion Type de matériel DCMI
Vous pouvez convertir les types de matériel Alma en types DCMI dans les champs dc:type et dcterms:type. Pour ce faire, ouvrez la table Conversion Type de matériel DCMI dans Menu de configuration > Ressources > Catalogage > Conversion Type de matériel DCMI. Pour plus d'informations sur les tables de conversion, voir Tables de conversion.