
Export von Alma-Datensätzen für Primo
- Katalog-Administrator
- Bestands-Administrator
- Allgemeiner Systemadministrator
-
Diese Seite ist nur für Alma-Primo-Umgebungen maßgeblich (nicht für Primo VE).
-
Für Primo-VE-Umgebungen müssen in Alma verwaltete Titelsätze nicht zu Primo VE exportiert werden. Wenn das Publishing-Profil Titelsätze für Primo publishen aktiv ist, deaktivieren Sie es auf der Seite Publishing-Profile (Ressourcen > Publishing > Publishing-Profile).
-
Für Alma-Summon-Umgebungen müssen Sie das Publishing-Profil Titelsätze für Summon publishen konfigurieren und aktivieren. Weitere Details finden Sie unter Publishing von Titelsätzen für Summon.
-
Das Profil Titelsätze für Primo publishen publisht alle Datensatztypen, nicht nur MARC21-Datensätze. Beachten Sie, dass Sie separate Pipes in Primo konfigurieren müssen, um jeden Ausgabetypen zu unterstützen.
-
MODS-Datensätze werden beim Publishing nach Primo in MARC21 konvertiert und erfordern keine separate Konfiguration. Die Konvertierung basiert auf der Zuordnung der Library of Congress.
Export von Alma-Datensätzen für Primo
- Konfigurieren Sie eine S/FTP-Verbindung, die von Alma und Primo verwendet wird (siehe Konfiguration von S/FTP-Definitionen). Achten Sie darauf, dass Port 22 im Primo-Server offen für den Alma-Server ist.
- Klicken Sie auf der Seite Seite Publishing-Profildetails (Ressourcen > Publishing > Publishing-Profile) in der Zeilen-Aktionsliste auf Bearbeiten für das Publishing-Profil Titelssätze für Primo publishen. Die Seite Publishing-Profildetails erscheint für das Publishing-Profil Primo.
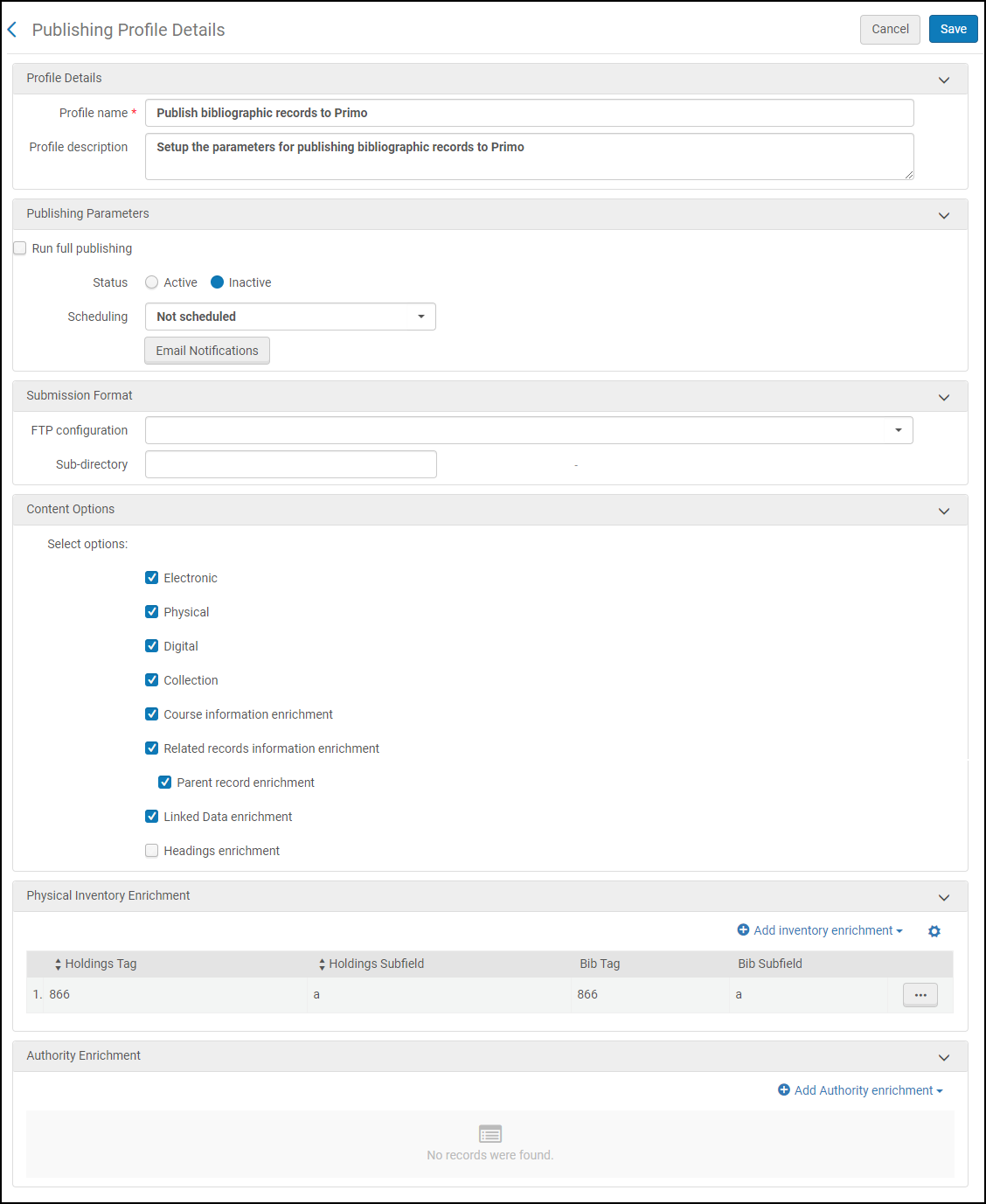 Seite Publishing-Profildetails
Seite Publishing-Profildetails - Konfigurieren Sie die Parameter der Seite Details des Publishing-Profils wie folgt.
Parameter: Beschreibung Abschnitt Profildetails: Profilname und -beschreibung Ändern Sie diese Felder nach Bedarf. Abschnitt Mitglieder-Publishing-Parameter: Die Parameter in diesem Abschnitt sind für Mitgliedsinstitutionen einer Netzwerkzone.Siehe Publishing von Datensätze für die einzelnen Primo-Instanzen der Mitgliedsinstitutionen für Informationen zur Option Auch Netzwerkdaten publishen. Wenn Sie diese Option auswählen, sind die verbleibenden Profiloptionen auf diejenigen eingeschränkt, die für diesen Publishing-Modus relevant sind.
Mitglieder-Publishing-Format
Wählen Sie Als einzelne Institution publishen, wenn Sie eine Mitgliedsinstitution sind und nur die in Ihrer Institutionszone für Sie verfügbaren Datensätze für Primo publishen möchten (was in dem hier beschriebenen Szenario nicht der Fall wäre). Beispiele für den Unterschied, ob Sie die Option Als einzelne Institution publishen finden Sie unten.
Beispiel – wenn Els einzelne Institutionen publishen ausgewählt ist:
<datafield tag="987" ind1=" " ind2=" ">
<subfield code="a">12259269</subfield>
</datafield>
<datafield tag="INT" ind1=" " ind2=" ">
<subfield code="a">E</subfield>
</datafield>
<datafield tag="INST" ind1=" " ind2=" ">
<subfield code="a">ALMA_UNIVERSITY</subfield>
</datafield>Beispiel – wenn Els einzelne Institutionen publishen nicht ausgewählt ist:
<datafield tag="987" ind1=" " ind2=" ">
<subfield code="a">12259269</subfield>
</datafield>
<datafield tag="INST" ind1=" " ind2=" ">
<subfield code="a">ALMA_UNIVERSITY</subfield>
<subfield code="b">E</subfield>
<subfield code="c">5164099790001858</subfield>
</datafield>
<datafield tag="MMS" ind1=" " ind2=" ">
<subfield code="b">99900178515201858</subfield>
<subfield code="a">ALMA_UNIVERSITY</subfield>
</datafield>Abschnitt Publishing-Parameter: Vollständiges Publishing ausführen Wenn diese Option ausgewählt wurde (beispielsweise, um Indexeinträge-Anreicherungsdaten für Primo zu publishen - siehe Publishing der Indexeinträge-Anreicherung für Primo), publisht Alma alle Datensätze und ersetzt die zuvor gepublishten Daten. Wenn diese Option nicht ausgewählt ist, publisht Alma Datensätze, die seit ihrem letzten Publishing geändert wurden. Dies sind unter anderem Titelsätze, die hinzugefügt, geändert, gelöscht und mit Bestands-Datensätzen verknüpft wurden, die geändert wurden. Das vollständige Publishing wird nur für nicht gelöschte Datensätze ausgeführt. Sie müssen zudem sicherstellen, dass alte Datensätze, die aus Alma gelöscht/unterdrückt wurden, wie erwartet behandelt werden. Aus diesem Grund wird empfohlen, dass Sie ein schrittweises Publishing ausführen, um alle kürzlich gelöschten Datensätze als gelöscht zu publishen, die gelöschten Datensatzinformationen in Primo mithilfe der regulären, fortlaufenden Pipe laden (siehe Harvesting und Publishing von Alma-Datensätzen für Primo), ein vollständiges Publishing auszuführen und dann die gepublishten Alma-Datensätze in Primo zu laden (erneut mit der regulären, fortlaufenden Pipe).Planung Wählen Sie eine der Planungsoptionen. E-Mail-Benachrichtigungen Legen Sie fest, welche Benutzer und E-Mail-Adressen E-Mail Benachrichtigungen erhalten werden, wenn das Publishing-Profil abgeschlossen wurde. Status Wählen Sie Aktiv. Abschnitt Einreichungsformat: FTP-Konfiguration Standardmäßig legt der Publishing-Prozess die exportierten Dateien in ein Verzeichnis, das Primo verwendet, um die Dateien zu entnehmen. Das Feld spezifiziert ein vordefiniertes Profil, das die FTP-Informationen enthält. Wenn der Transfer fehlschlägt, fügt Alma einen Link zu den gepublishten Dateien im Publishing-Bericht ein. Das Verzeichnis muss vorab in Primo konfiguriert werden, da es nicht von Alma erstellt werden kann.Wählen Sie den Namen der S/FTP-Verbindung. Für weitere Details siehe Konfiguration zulässiger S/FTP-Verbindungen.Unterverzeichnis Das Unterverzeichnis, in welches die exportierten Dateien gelegt werden. Wenn Sie beispielsweise bei der Konfiguration der S/FTP-Verbindung Alma im Unterverzeichnis-Feld spezifiziert haben, und in diesem Feld Primo eingeben, werden die Daten in das Verzeichnis Alma/Primoexportiert.Abschnitt Inhalts-Optionen: Elektronisch, Physisch, Digital und Sammlung Der Datensatztyp, den Sie publishen möchten. Um digitales Volltext-Publishing zu aktivieren, kontaktieren Sie den Ex Libris Support.Seminarinformation Anreicherung Legen Sie fest, ob Seminarapparat-Informationen in den Titelsätzen enthalten sind. Beachten Sie, dass Seminarapparate nicht als unabhängige Datensätze gepublisht werden. Stattdessen fügt Alma diese Informationen den CNO-Feldern im verbundenen Titelsatz hinzu. Literatur-Details werden nicht für Primo gepublisht. Nur der Titelsatz des angehängten Bestandsexemplars der Literatur (MMS-Datensatz) wird geublisht.Legen Sie fest, ob die zugehörigen Datensatz-Informationen (die im Feld PLK gespeichert sind) in den Titelsätzen enthalten sind. Es können maximal 500 PLK-Felder für einen einzelnen Datensatz veröffentlicht werden. Wenn ein Datensatz mehr als 500 verknüpfte Datensätze enthält, sind in den Veröffentlichungsinformationen nur 500 PLK-Felder vorhanden.
Unten finden Sie ein XML-Beispiel für das PLK-Feld, das Informationen zum verknüpften Datensatz enthält.
<datafield tag="PLK" ind1=" " ind2=" ">
<subfield code="a">Zusätzliches Formular.</subfield>
<subfield code="b">99110387010001451</subfield>
</datafield>Parent-Datensatz-Anreicherung Wenn das Feld Informationsanreicherung über die verbundenen Datensätze aktiviert ist, können Sie Parent-Titelinformationen am Feld PLK anhängen.
Um die Anreicherungsdaten für Anzeige, Facetten und Suche in der Primo-UI zu verwenden, müssen Sie Primo-Normalisierungsregeln definieren, mit denen Informationen in den PLK-Unterfeldern bei Bedarf zu PNX-Feldern zugeordnet werden. Andernfalls werden diese Informationen nicht in Primo angezeigt.
Titeldaten werden in die folgenden Unterfelder des Feldes PLK gesendet: d, e, f, g, h, i, m und v. Informationen zur Zuordnung des MARC-21-Feldes 245 und des UNIMARC-Feldes 200 zu den Unterfeldern PLK finden Sie in der nachfolgenden Tabelle.
Unterfeld-Beschreibung PLK-Unterfelder MARC-21-Unterfelder 245 UNIMARC-Unterfelder 200 Andere Titelinformationen d d Verbleibende Titelinformationen/andere Titelinformationen d C d Verfasserangabe/Erste Verfasserangabe f c f Medium/Allgemeine Materialbezeichnung g h C Nummer des Teils/Abschnitts eines Werks/Nummer eines Teils h n h Bezeichnung des Teils/Abschnitts eines Werks/Bezeichnung eines Teils i p i Titel m a a Bandbezeichnung v v Unten finden Sie ein XML-Beispiel für das PLK-Feld, das Informationen zum übergeordneten Datensatz enthält.
<datafield tag="PLK" ind1=" " ind2=" ">
<subfield code="a">Zusätzliches Formular.</subfield>
<subfield code="b">99110387010001451</subfield>
<subfield code="m">Harry Potter und der Stein der Weisen /</subfield>
<subfield code="f"> by J.K. Rowling ; Illustrationen von Mary GrandPré.</subfield>
</datafield>Verknüpfte Daten-Anreicherung Legen Sie fest, ob URLs im Unterfeld 0 der betreffenden Titelfelder eingegeben werden können. Indexeinträge-Anreicherung Legen Sie fest, ob Indexeinträge-Anreicherungsdaten für Primo gepublisht werden sollen. Für weitere Informationen siehe Publishing der Indexeinträge-Anreicherung für Primo unten. Wenn Sie diese Option auswählen, erscheint das Feld Indexeinträge-Anreicherung – Anreicherung mit “Siehe auch”-Feldern. Das Hinzufügen verknüpfter Begriffe wird in Primo standardmäßig nicht unterstützt. Bevor Sie diese Option aktivieren, stellen Sie sicher, dass Sie sich entschieden haben, wie die verknüpften Begriffe in Primo verwendet werden und dass Sie Ihre Normalisierungsregeln geändert haben, falls notwendig. Für weitere Informationen siehe Andere Überlegungen zur Implementierung unten.Indexeinträge-Anreicherung – Anreicherung mit “Siehe auch”-Feldern Erscheint, wenn Indexeinträge-Anreicherung ausgewählt ist. Legen Sie fest, ob die 5XX "Siehe auch"-Felder beim Publishing von Indexeinträge-Anreicherungsdaten für Primo einbezogen werden sollen. Für weitere Informationen siehe Publishing der Indexeinträge-Anreicherung für Primo unten. Klassifizierungsanreicherung Kontaktieren Sie den Ex Libris Support, um dieses Feld zu aktivieren.Legen Sie fest, ob die für Primo gepublishten Titelsätze mit Klassifizierungsdaten angereichert werden sollen, die Ansetzungsformen und Veweisungsformen enthalten. Die Klassifizierungsdaten, die für die Anreicherung verwendet werden sollen, werden im Feld 084 des Titelsatzes identifiziert, wobei $2 angibt, welches Klassifizierungsschema verwendet wird (wie RVK, BK und MSC) und $a die Signatur enthält, die zur Verknüpfung des Klassifizierungs-(Norm-)Datensatzes verwendet wird.Wenn diese Option ausgewählt ist und der Publishing-Prozess ausgeführt wird, werden die Titelsätze mit Ansetzungsformen und Verweisungsformen angereichert, die aus den Feldern 153 und 70X/75X des Klassifizierungs-(Norm-)Datensatzes entnommen werden, der durch die Felder 084 des Titelsatzes verknüpft wird und in die Felder 084 eingefügt wird, die zu den gepublishten Titelsätzen hinzugefügt werden.Für jedes 084-Feld im Alma-Titelsatz, das mit einem Klassifizierungs-(Norm)-Datensatz verknüpft und für Primo gepublisht wird, werden ein oder mehrere 084-Felder zum gepublishten Datensatz hinzugefügt. Wenn zum Beispiel der verknüpfte Klassifikations-Datensatz ein 153-Feld und zwei 7XX-Felder enthält, werden dem gepublishten Datensatz drei neue 084-Felder hinzugefügt. $9 im hinzugefügten 084-Feld enthält Y (ja) oder N (nein), um anzugeben, ob es sich um eine Ansetzungsform handeltAbschnitt physische Bestandanreicherung Sie können Bestand-Feldcodes/Unterfelder aus dem Lokalsatz Feldcodes/Unterfeldern im gepublishten Datensatz zuordnen: Bestand - Feldcode, Bestand - Unterfeld, BIB-Feldcode und BIB-Unterfeld. Klicken Sie auf Neue Bestandsanreicherung und geben Sie die Informationen ein. Klicken Sie auf Hinzufügen, um die neue Zuordnung zur Liste hinzuzufügen.Abschnitt Normdatei-Anreicherung: - Die Normdatei-Anreicherung wird in SB/PSB nicht unterstützt, da die Normdatei-Datenbank, die die Quelle für die Anreicherung ist, nicht in SB/PSB gepflegt wird, sondern nur in der Produktion.
- In der Produktion kann es ab dem Zeitpunkt der Aktualisierung einer Normdatei (die mit dem Titelsatz verknüpft ist) bis zu zwei Tage dauern, bis der Bib-Datensatz mit den aktualisierten Normdatei-Informationen erneut veröffentlicht wird.
Verwenden Sie die Konfiguration Normdaten-Anreicherung, um den für Primo gepublishten Titelsatz mit dem Inhalt eines Feldes aus dem mit den Titeldaten verknüpften Normdatensatz anzureichern.
Wählen Sie Neue Normdatei-Anreicherung und geben Sie Werte für die folgenden Parameter ein:
- Normdatei-Feldcode – Geben Sid die Feldnummer des Feldcodes aus dem Normdatensatz ein, der zum gepublishten Titelsatz hinzugefügt werden soll.
- Wert im Unterfeld '9' – Geben Sie einen beschreibenden Wert ein, der im Feld $9 des gepublishten Datensatzes positioniert werden soll. Sie können die Feldnummer oder einen anderen beschreibenden Text eingeben. Im folgenden Beispiel wurde 382 für den Parameter Wert im Unterfeld '9' eingegeben.
Beispiel für die Konfiguration einer Normdatei-Anreicherung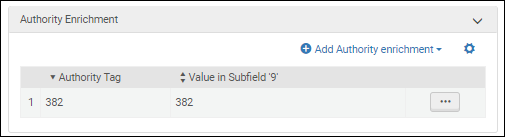 Beispiel für den Wert im Unterfeld '9' in einem gepublishten Datensatz:240 $$9382 $$0 41-GND-300569947 $$0 (DE-101)040197913 $$0 (DE-588)4019791-8 $$0 http://d-nb.info/gnd/4019791-8 $$a Violine |n 2 $$2 gnd
Beispiel für den Wert im Unterfeld '9' in einem gepublishten Datensatz:240 $$9382 $$0 41-GND-300569947 $$0 (DE-101)040197913 $$0 (DE-588)4019791-8 $$0 http://d-nb.info/gnd/4019791-8 $$a Violine |n 2 $$2 gndFür weitere Informationen siehe Indexeinträge-Anreicherung.
- Klicken Sie auf Speichern. Das geänderte Publishing-Profil ist gespeichert. Daten, die den definierten Kriterien entsprechen, werden an die spezifizierte FTP-Speicherstelle exportiert, wenn das Profil nach dem ausgewählten Plan durchgeführt wird.
Der Prozess Publishing für Primo publisht bis zu 1.000 Zuordnungen für jeden Titelsatz.Für Informationen zum Überwachen eines Publishing-Exportprozesses siehe Laufende Prozesse anzeigen. Für Informationen zum Prozessbericht siehe Abgeschlossene Prozesse anzeigen.Weil die Überwachung von Prozessen einen erfolgreichen Abschluss berichten kann, auch wenn das FTP fehlgeschlagen ist, ist es wichtig, den Prozessbericht auf Fehler zu überprüfen.
Publishing der Indexeinträge-Anreicherung für Primo
Die Funktion der Indexeinträge-Anreicherung ist für die Primo-Versionen ab 4.1.1 relevant. Bevor Sie Alma für das Publishing der Indexeinträge-Anreicherungsdaten für Primo konfigurieren, müssen Sie Ihre Normalisierungsregeln in Primo ändern. Zusätzliche Informationen finden sie unten im Abschnitt Andere Überlegungen zur Implementierung. Wenn Sie entscheiden, dass ein vollständiges Publishing von Datensätzen für Primo erforderlich ist, siehe die Anweisungen unter Vollständiges Publishing ausführen.
Indexeinträge-Anreicherung
- MARC 21 – 100-199, 600, 610, 611, 630, 648, 650, 651, 654, 655, 700, 710, 711, 730, 751, 752, 754, 800, 810, 811 or 830
- UNIMARC – 410, 411, 416, 500, 600, 601, 602, 605, 606, 607, 616, 617 700, 701, 702, 703, 710, 711, 712, 713, 720, 721, 722, 723, 730, 740, 741, or 742
- MARC 21 – 500, 510, 511, 530, 548, 550, 551, 555, 562, 580, 581, 582, or 585
- UNIMARC – 500, 510, 511, 515, 530, 550, 580
| Änderung des Unterfeldes | Beschreibung |
|---|---|
| $2 | Enthält den Wortschatz-Code, der für die Autorisierung verwendet wird. Die derzeit unterstützen Werte sind unter anderem:
Wenn der zweite Indikator des Feldes 4 oder 7 ist, wird $2 nicht überschrieben.
|
| $0 (Unterfeld Null) | Enthält die Alma Normdatensatz-ID. Wenn das Felde im MARC 21/UNIMARC-Datensatz autorisiert ist, Normdatensätze in Alma zu verwenden (entweder lokale oder Gemeinschaftszonen-Normdatensätze), wird $0 hinzugefügt. Andere Überlegungen zu $0 sind Folgende:
|
| $9 | Enthält Y, N,R, oder <value>
$9 wird zu jedem Feld im ursprünglichen MARC 21/UNIMARC-Datensatz hinzugefügt, der autorisiert ist.
|
| $L | Enthält die Sprachinformationen (für mehrsprachige Normdateien). |
- Ein Feld, das denselben Feldcode hat wie das ursprüngliche, autorisierte Feld, wird zum MARC-Datensatz hinzugefügt.
- $0 und $2 werden zu diesem neuen Feld mit denselben Werten wie im ursprünglichen Feld hinzugefügt.
- $9 wird zum neuen Feld hinzugefügt, mit dem Wert Y für bevorzugt, dem Wert N für nicht bevorzugt, dem Wert R und <Wert>!, der in der Tabelle oben und in den zusätzlichen Informationen/im Beispiel unten beschrieben ist.
- Die Werte der anderen Unterfelder für das neue Feld werden Ursprungssystem dem Normdatensatz-Feld kopiert.
Andere Überlegungen zur Implementierung
- Im Allgemeinen müssen die Regeln wie folgt geändert werden:
- Der Abschnitt Indexsuche muss geändert werden, sodass Schlagwörter der Indexsuche mit Kreuzverweisen erstellt werden können.
- Eine Reihe an Regeln muss geändert werden (Details finden Sie in der Primo-Dokumentation), um zu vermeiden, dass Verweisungsformen in der Anzeige, in Facetten, Deduplikationen und Sortierungen verwendet werden.
- Die Alma MARC-Vorlage (in Primo) wurde geändert, um die Alma Indexeinträge-Anreicherung ab Primo V4.1 zu unterstützen, mit einigen Korrekturen, die in V4.5 hinzugefügt wurden. Es ist daher wahrscheinlich, dass Sie die notwendigen Regeln bereits in Einsatz haben; oder wenn nicht, ist es möglich, dass Sie Ihre Regeln bereits geändert haben. Um den Status Ihrer Regeln zu bestätigen, überprüfen Sie zunächst den Abschnitt Indexsuche. Wenn es im Abschnitt Indexsuche keine Regeln gibt, müssen die Regeln geändert werden. Wenn es Regeln im Abschnitt Indexsuche gibt, wurden die Regeln wahrscheinlich bereits geändert, aber Sie sollten auch überprüfen, ob die anderen Felder, die im Abschnitt Normalisierungsregeln-Vorlage der Primo-Dokumentation gekennzeichnet sind, geändert wurden.
- Mit Vorlage synchronisieren - Diese Option wird in Informationen zu Implementierung und Upgrade beschrieben
- Dieses Ziel in ein weiteres Zuordnungs-Set kopieren - Diese Option wird in Bearbeiten von Normalisierungsregel-Sets beschrieben
Die Ausgabe des Publishing-Prozesses
- IEP*.tar.gz – Enthält Titelsätze mit dem gedruckten Bestand.
- IEE*.tar.gz – Enthält Datensätze mit elektronischem Bestand.
- IED*.tar.gz – Enthält Datensätze mit digitalem Bestand.
- IE_MMS*.tar.gz – Enthält Datensätze ohne verbundenem Bestand.
Das Format gepublishter Daten
Eine gepublishte Datei beginnt immer mit:
<?xml version="1.0" encoding="UTF-8"?>
-<OAI-PMH xsi:schemaLocation="http://www.openarchives.org/OAI/2.0/ http://www.openarchives.org/OAI/2.0/OAI-PMH.xsd" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns="http://www.openarchives.org/OAI/2.0/">
-<ListRecords>
-
Alma Intellektuelle Entität-ID – Gespeichert in der Kopfzeile des gepublishten Datensatzes und verwendet als Basis für die Datensatz-ID in Primo:
<header status="new">
<identifier>urm_publish:21239404420001021</identifier>
</header> - 001 – Enthält die MMS-ID.
-
INT - Zeigt den Entitätstyp an, der im Unterfeld $$a gespeichert ist. Alma publisht die folgenden Datensatz-Typen für Primo:
- P (Physisch) – Dies zeigt an, dass der exportierte Titelsatz einen verbundenen Lokalsatz hat (mit oder ohne Exemplare). Wenn die Kriterien für D, E oder C nicht erfüllt sind, ist P der Standardwert (selbst wenn es keine verknüpften Lokalsätze gibt).
- D (Digital) – Dies zeigt an, dass der exportierte Titelsatz eine verbundene Repräsentation enthält. Weitere Informationen erhalten Sie in dem Feld TYP .
-
E (Elektronisch) – Datensatz ist einer der folgenden elektronischen Typen:
- Elektronisch– Dies zeigt an, dass der Titelsatz ein verbundenes Portfolio hat.
- Elektronische Sammlung – Datensätze diesen Typs enthalten keine verbundenen Portfolios, werden aber von anderen elektronischen Datensätzen durch das Feld ECT unterschieden.
- C (Sammlung). Dies zeigt an, dass der Datensatztyp eine Sammlung ist und gemischte Materialarten enthalten kann.
- TYP – Dies zeigt den Entitätstyp von digitalen Datensätzen an, der im Unterfeld $$a gespeichert wird.
-
AVA – Dieses Feld ist nur für gedruckte Materialien erstellt. Es enthält Standort- und Verfügbarkeit-Informationen für den gepublishten Datensatz und verknüpften Datensätze in den folgenden Unterfeldern:
- $$8 – Enthält die MMS-ID des Lokalsatzes. Dieses Unterfeld wird von Primo nicht verwendet, allerdings können sie von Benutzern abgerufen werden, die die REST-API Bib abrufen und SRU verwenden.
- $a - Institutionscode
- $$b – Bibliothekscode
- $$c – Standort-Anzeigename
- $$d – Signatur
- $$e – Verfügbarkeit (wie etwa verfügbar, nicht verfügbar oder Bestand überprüfen).
- $$f – Exemplare gesamt
- $$g – Nicht verfügbare Exemplare
- $$j – Standortcode
- $$k - Signaturtyp - Wenn ein Standort eine Zugangsnummer verwendet, wird dieses Unterfeld nicht veröffentlicht.
- $$p – Priorität
- $$q – Bibliotheksname der Bestände
- $$t – Text-Repräsentationen aus den MARC-Feldern 866, 867 und/oder 868. Dieses Unterfeld wird von Primo nicht verwendet, allerdings können sie von Benutzern abgerufen werden, die die REST-API Bib abrufen und SRU verwenden. Dieses Unterfeld ist wiederholbar.
-
AVD – Dieses Feld wird nur für digitale Materialien erstellt. Es wird für Titelsätze mit digitalem Bestand gepublisht. Es enthält die folgenden Unterfelder:
- $a - Institutionscode
- $$b – Repräsentations-PID
- $$c – Repräsentationsart: REPRÄSENTATION oder EXTERNE_REPRÄSENTATION
- $$d – Name der externen Repräsentation (wenn dies eine externe Repräsentation ist)
- $$e – Beschriftung der Repräsentation
- $$f – Öffentliche Notiz
- $$h – Volltext, falls aktiviert.
-
AVE – Dieses Feld enthält "Verfügbar für"-Gruppeninformationen (Elektronisch verfügbar; siehe Konfiguration des zugeteilten Zugriffs auf elektronische Ressourcen) in den folgenden Unterfeldern:
- $$i – enthält den "Verfügbar für"-Institutionscode einer einzelnen E-Ressource
- $$c – enthält den "Verfügbar für"-Campuscode einer einzelnen E-Ressource
- $$l – enthält den "Verfügbar für"-Bibliothekscode einer einzelnen E-Ressource
Wenn Sie eine separate Primo-Institution pro Alma Campus definiert haben, ist dieses Feld die Basis für die Definition der Primo-Institution in den PNX-Datensätzen. Andernfalls können Sie diese Informationen verwenden, um Suchbereiche zu erstellen und campusspezifische E-Ressourcen zu suchen. -
CAT – Für jedes MARC21 050 Feld erstellt der Prozess Erstellt eine Zeitschrift-Kategoriedatei bis zu drei Ebenen an Zeitschriften-Kategorien durch Zuordnung der LCC-Nummer, die im Unterfeld 050 $ a gespeichert ist, an Columbias hierarchische Schnittstelle zur LC-Klassifikation (HILCC) und speichert die Kategorien in den folgenden Unterfeldern: a (Ebene 1), b (Ebene 2) und c (Ebene 3). Weitere Details unter https://www1.columbia.edu/sec/cu/libraries/bts/hilcc/.
Beispielsweise erstellt ein Datensatz mit einer LCC-Nummer N7445 die folgenden Kategorieebenen.
<datafield tag="CAT" ind1=" " ind2=" ">
<subfield code="a">Arts_Architecture_Applied_Arts</subfield><subfield code="b">Visual_Arts</subfield><subfield code="c">Visual_Arts_General</subfield></datafield>
-
COL – Dieses Feld enthält gesammelte Informationen in den folgenden Unterfeldern:
- a – Parent-Sammlungs-ID
- b – Sammlungstitel
- c – Sammlungsname
- A – Die besitzende Institution. Aktuell wird dieses Feld nur für zentrales Publishing verwendet, aber es wird zukünftig auch für Standard-Publishing verwendet werden.
-
CNO – Dieses Feld wird im MD-Editor nicht verwaltet. Stattdessen werden seine Informationen während des Veröffentlichungsprozesses aus verschiedenen Konfigurationseinstellungen abgerufen und in die folgenden Unterfelder exportiert:
- $a - Institutionscode
- $$b – Startdatum
- $$c – Enddatum
- $$e – Der Name der akademischen Abteilung wird dem Feld Beschreibung in der Codetabelle Seminar-Fakultäten entnommen (siehe Konfiguration von akademischen Abteilungen).
- $$f – Der Code der akademischen Abteilung wird dem Feld Code in der Codetabelle Seminar-Fakultäten entnommen.
- $$g – Seminar-Dozenten werden der Registerkarte Dozenten auf der Seite Seminar-Information verwalten (siehe Verwalten von Seminaren) entnommen.
- $$j – Der Seminarname wird dem Feld Name auf der Seite Seminar-Information verwalten entnommen.
- $$k – Der Seminarcode wird dem Feld Code auf der Seite Seminar-Information verwalten entnommen.
- $$l – Der Seminarabschnitt wird dem Feld Abschnitt auf der Seite Seminar-Information verwalten entnommen.
- $$o – Durchsuchbare IDs werden den Feldern Durchsuchbare IDs auf der Seite Seminar-Information verwalten entnommen.
- $$r – Das Seminarjahr wird dem Feld Jahr auf der Seite Seminar-Information verwalten entnommen.
- $$v – Der Literaturlisten-Veröffentlichungsstatus wird dem Feld Status auf der Seite Literaturlisten entnommen (siehe Verwalten von Literaturlisten).
- $$w – Der Literaturlisten-Name wird dem Feld Name auf der Seite Literaturliste bearbeiten entnommen. Neu für Februar! Wenn mehr als eine Liste mit demselben Seminar verknüpft ist, wird jede Liste in einem separaten $w in Primo veröffentlicht.
Die CNO enthält Seminardetails, aber keine Literatur-Details. Wenn das Literaturlistenzitat ein Artikel in einer Zeitschrift ist, die zu einer Bibliothek gehört, muss der Artikel als MMS-Datensatz katalogisiert werden, damit die Artikelinformationen in Primo erscheinen. Es reicht nicht aus, die Artikeldetails im Literaturlistenzitat einzugeben und dann an die Ressource anzuhängen, die der Titelsatz der Zeitschrift ist. Die beigefügte Ressource wird in Primo gepublisht, nicht das Literaturzitat.Beispiel:
<datafield tag="CNO" ind1="" ind2=""><subfield code="a">01TRAINING_INST</subfield><subfield code="b">201412150317+-317</subfield><subfield code="c">201503310217+-217</subfield><subfield code="e">Fine Arts</subfield><subfield code="f">FINART</subfield><subfield code="g">Howell, Stanley P.</subfield><subfield code="j">Einführung in die Kunst</subfield><subfield code="k">Art 101</subfield><subfield code="l">01</subfield><subfield code="o">WI1516771</subfield><subfield code="o">mrl</subfield><subfield code="r">2015</subfield><subfield code="v">ENTWURF</subfield><subfield code="w">Art History</subfield></datafield> -
ECT – Wenn ausgefüllt, zeigt dies an, dass es sich bei dem elektronischen Datensatz um eine elektronische Sammlung handelt.
- $$a – auf Datenbank eingestellt
-
INST – Enthält den Institutionscode (wird benötigt für Datensätze des Typs E, für die AVA nicht erstellt wird). Beachten Sie, dass der Institutionscode im Unterfeld $$a gespeichert wird. Wenn die Funktionalität Elektronisch verfügbar verwendet wird, wird die Institution möglicherweise nur im AVE-Feld angezeigt.
Für gemeinsame Umgebungen, die zentrales Publishing verwenden, enthält das Unterfeld $$b den Entitätstyp anstatt des INT-Feldes. Wenn beispielsweise die Entität eine Sammlung ist, würde das Unterfeld$$b ein C enthalten.Für Alma-D und Alma-C-Datensätze enthält das Unterfeld $$c die intellektuelle Entität-ID von Alma, die in der Vorlage alma_thumb2 zur Anzeige von Miniaturbildern verwendet wird.
-
OWN – Dieses Feld enthält in den folgenden Unterfeldern Besitz-Informationen (Eigentum) und ist nicht in der Alma MARC - Vorlage enthalten:
- $$i – enthält einen einzelnen mit dem Titelsatz (der Institutions-ID) verbundenen E-Ressourcen-Besitz
- $$l – enthält einen einzelnen mit dem Titelsatz (der Bibliothek) verbundenen E-Ressourcen-Besitz
-
PLK - Dieses Feld enthält Verknüpfungsinformationen aus den Feldern MARC 76X-78X und 830. Die Verwendung dieser Daten erfordert die Definition zusätzlicher Normalisierungsregeln in Primo. Für eine zusätzliche Anreicherung siehe Parent-Datensatz-Anreicherung.
- $$a - enthält die MARC-Beziehung zwischen diesem Datensatz und dem Datensatz, mit dem es verknüpft.
- $$b - enthält die MMS-ID des Datensatzes, mit dem dieser Datensatz verknüpft.