
書誌レコードの操作
- 目録編集者
- 目録者(拡張)
- 目録管理者
- 目録マネージャー
書誌レコードを作成
MARC 21書誌レコードの作成
- メタデータエディタを開きます([リソース] > [目録] > [メタデータエディタを開く])。
- 書誌レコードを入力するには、 [新規] > [MARC 21 書誌] を選択し、デフォルト テンプレートを選択します。 メタデータエディタにより、このテンプレートが開かれます。
- 書誌レコードのデータを入力します。メタデータエディタの使用に関する追加情報については、 メタデータエディタメニューとツールバーオプションセクションを参照してください。 ヘブライ語でレコードコンテンツを入力する方法については、文字の入力方向を表示および方向特性文字を挿入を参照してください。
ヘブライ語での目録の詳細については、ヘブライ語での目録における特別な問題を参照してください。010または035フィールドを目録化するとき、このフィールドに保存する各スペースにハッシュ記号(#)を入力します。コンテンツは、スペースとしてAlmaデータベースに(入力されたハッシュ記号ごとに)保存されますが、フィールド内のスペースの正確な数をより明確に識別するために、メタデータエディタにハッシュ記号として表示されます。次のフィールドでは、最初の3文字を入力すると、システムがポップアップアシスタンスを提供します(下の図を参照)。- 260 $$a、b、e、f
- 264 $$a、b
- 505 $$r、t
- 561 $a
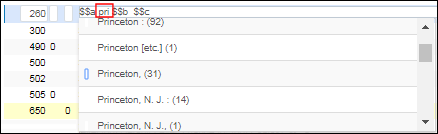 ポップアップアシスタンスの例(推奨する標目ではない)特殊文字を入力すると、ポップアップパラメータはユーザーパラメータ設定を使用して、次の方法で実装されます。
ポップアップアシスタンスの例(推奨する標目ではない)特殊文字を入力すると、ポップアップパラメータはユーザーパラメータ設定を使用して、次の方法で実装されます。- レコードコンテンツを入力し、メタデータエディタによる候補が挙げられる際(最初の数文字入力後)、Eszett文字またはEszettの代わりにssを使用する場合、提案される候補は入力内容に固有のものとなります。つまり、Großbritannienなどのßという値を入力すると、ßを含む結果のみが表示され、Grossbritannienなどのssで値を入力すると、ssを含む結果のみが表示されます。
- レコードコンテンツを入力し、メタデータエディタによる候補が挙げられる際(最初の数文字入力後)、ウムラウト 文字またはウムラウトなしの文字を使用する場合、提案される候補は入力内容に固有のものとなります。したがって、Müllerと入力すると、 üを含んだ候補が表示され、Mullerと入力すると、 üなしの候補が表示されます。
- レコードコンテンツを入力し、メタデータエディタによる候補が挙げられる際(最初の数文字入力後)、 ハイフンを入力すると、Baden-Badenなどのハイフンを含む結果のみが表示されます。たとえば、ハイフンなしでBaden Badenと入力すると、ハイフンを含まない結果のみが表示されます。
メタデータエディタによる候補を希望する方法で処理するため、サポートに連絡して、サブフィールド候補の顧客パラメータを設定してください。これらのフィールドに提供されるポップアップアシスタンスは、典拠または書誌の標目には推奨するものではありません。このポップアップアシスタンスは、[語彙の制御レジストリ]で作成および保存した説明によって決定され(語彙の制御レジストリの設定を参照)、[語彙の制御を選択](フィールドの編集を参照)を使用したメタデータ設定で識別し、以前に作成した [語彙の制御レジストリ]リストの説明を選択できるようにします。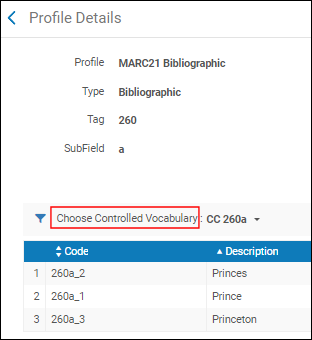 語彙の制御を選択推奨される典拠と書誌の標目にアクセスするには、入力/チェックしているフィールドでF3を押します。システムは選択したオプションのリストを開きます(サブフィールドは元の目録順に従って抽出されることに注意してください)。標目の候補がない場合、Almaは「一致する標目が見つかりません」と表示します。 詳細については、F3の使用を参照してください。
語彙の制御を選択推奨される典拠と書誌の標目にアクセスするには、入力/チェックしているフィールドでF3を押します。システムは選択したオプションのリストを開きます(サブフィールドは元の目録順に従って抽出されることに注意してください)。標目の候補がない場合、Almaは「一致する標目が見つかりません」と表示します。 詳細については、F3の使用を参照してください。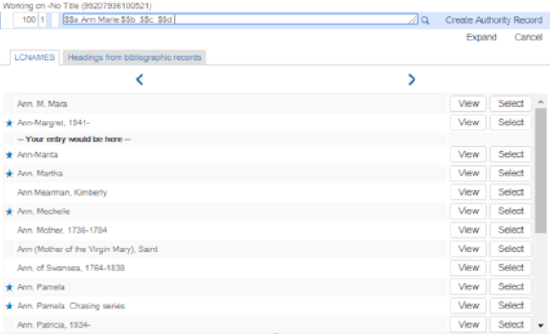 F3の例 - 推奨される典拠と書誌の標目IEで作業していてF3を押す場合は、テキストにフォーカスされているときにEnterを押してください。そうしないと、標目リストが正しく表示されない場合があります。複数の典拠語彙に優先順位が定義されている場合、システムは優先順位順に一致をチェックし、F3を使用することで、左から右の優先順位で別々のタブ(GNDやLCSHなど)に結果を表示します。詳細については、典拠の優先順位を参照してください。
F3の例 - 推奨される典拠と書誌の標目IEで作業していてF3を押す場合は、テキストにフォーカスされているときにEnterを押してください。そうしないと、標目リストが正しく表示されない場合があります。複数の典拠語彙に優先順位が定義されている場合、システムは優先順位順に一致をチェックし、F3を使用することで、左から右の優先順位で別々のタブ(GNDやLCSHなど)に結果を表示します。詳細については、典拠の優先順位を参照してください。- ローカルの典拠は、括弧内の単語(ローカル)で識別されます。
- 優先語は星印で識別されます。好ましくない用語は、左側が空白です(星印がありません)。
- [表示]を選択して、典拠レコード全体を表示します。
- [選択]を選択して、作業中のレコードにコンテンツを挿入します。
- [書誌レコードからの標目]タブを選択して、候補に提案された書誌の標目を表示します。
- 追加情報については、典拠レコードの操作を参照してください。
- [保存]アイコンを選択します。レコードの保存に関する追加情報については、メタデータエディタにおけるレコードの保存を参照してください。
GNDレコードの統一タイトルの標目の操作
- 075 $b u
- 130フィールドおよび$9に次のいずれかを含む500、510、または511。
- 4:auta
- 4:koma
- 4:regi
- 4:kuen
$tで始まる統一タイトルの典拠標目の生成
240フィールドと統一タイトルの書誌標目の操作
メタデータ エディターでの書誌ランキング
Almaは、識別子、名前、件名、有益なLDRおよび008フィールド、出版物の詳細などを含む情報に基づいて、MARC 21書誌レコードの完全性と豊富さを評価します。これは、 書誌ランクは、図書館が注意を必要とする可能性のあるレコードを特定するための便利なツールを提供することを目的としています。新しい書誌ランクがレコード ビューおよびメタデータ エディタで表示されます。
書誌ランキングの詳細については、 書誌ランクアルゴリズムを参照してください。
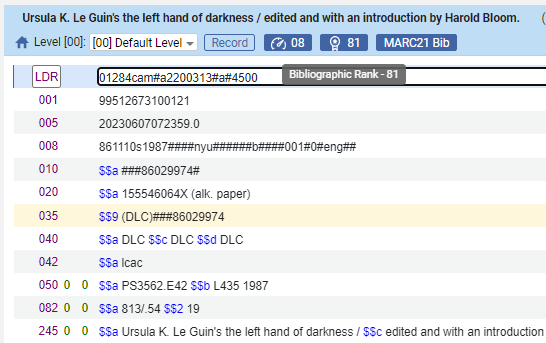
コミュニティゾーンコレクションの書誌ランキング
この情報はコレクションレベルで 表示されます: すべての管理ラベル(Ex Librisによる管理、コミュニティによる管理、寄贈、未管理、削除保留)のコレクション検索結果。
書誌ランクフィールドは、コミュニティゾーンのコレクションで表示されます。 このフィールドは、コレクション内の書誌レコードの平均的なランクを示し、異なる3つのレベルで機能します:
- 下位 - 0-39
- 中位 40-79
- 上位 80-150
書誌ランキングの範囲は 1 ~ 150 です。一般に、 75位以上にランクされるレコードは良いレコードとみなされます。
上記の3つの品質カテゴリーは、書誌レコードの書誌ランキングのコレクション内での 分布に基づいています。書誌ランキング のロジックは、関連するすべての書誌レコードの書誌ランキングの平均をコレクションレベルで表示することで、ユーザーはどのコレクションをアクティブにするのがよいか、さらに、アクティブにする前にコレクションにどのような品質を求めるべきかを知ることができます。
平均書誌ランクなどのコミュニティゾーンコレクションの品質データを含めることにより、ユーザーは特定のコミュニティゾーンコレクション内のMARCレコードの品質に関する問い合わせに対処できるようになります。
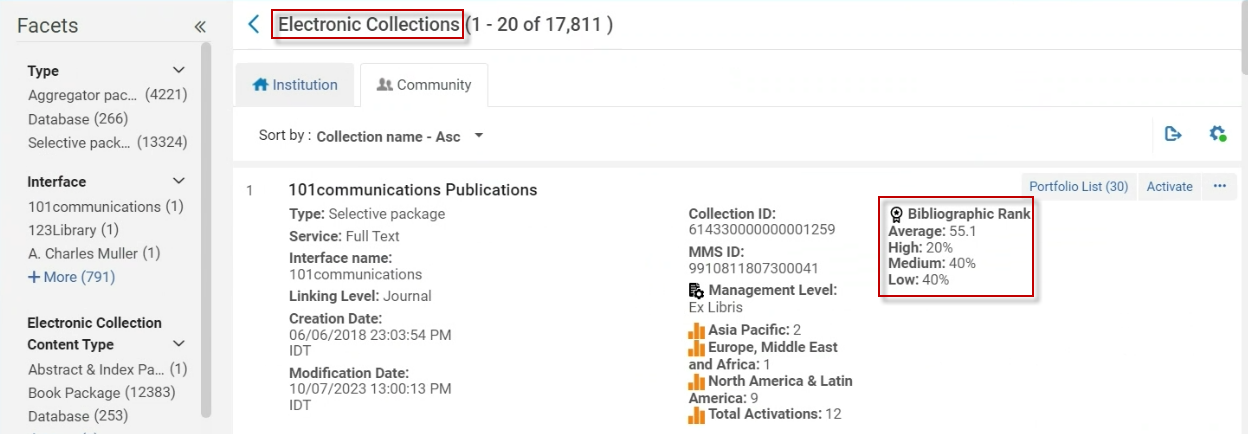
ユーザーには、コミュニティゾーンコレクションのレベルに関する次の追加情報が表示されます:
| 書誌レコード | 説明 |
|---|---|
| 平均 | 個々の書誌ランキングの 合計をレコード総数で割ったもの。 |
| 高 | 書誌ランキング 「上位」 のレコードの割合(上記の3つの異なるレベルで算出(80~150))。 |
| 中 | 書誌的ランキング が 「中位」 のレコードの割合(前述の3つの異なるレベルにより算出(40~79))。 |
| 低 | 書誌的ランキング が 「下位」 のレコードの割合(前述の3つの異なるレベルにより算出(最大39))。 |
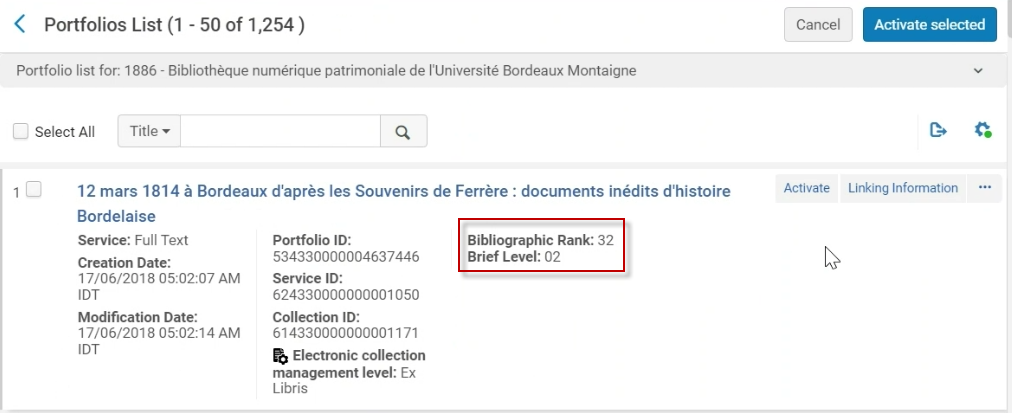
ビューをカスタマイズするオプションが拡張され、ポートフォリオレベルの情報として、 書誌ランク と 簡易レベル フィールドが追加されました。ユーザーは必要に応じて、検索結果にこれらの詳細を表示することを選択できます。簡易レベルフィールドの計算の詳細については、書誌ランクアルゴリズムのレベル1 - 幅を参照してください。
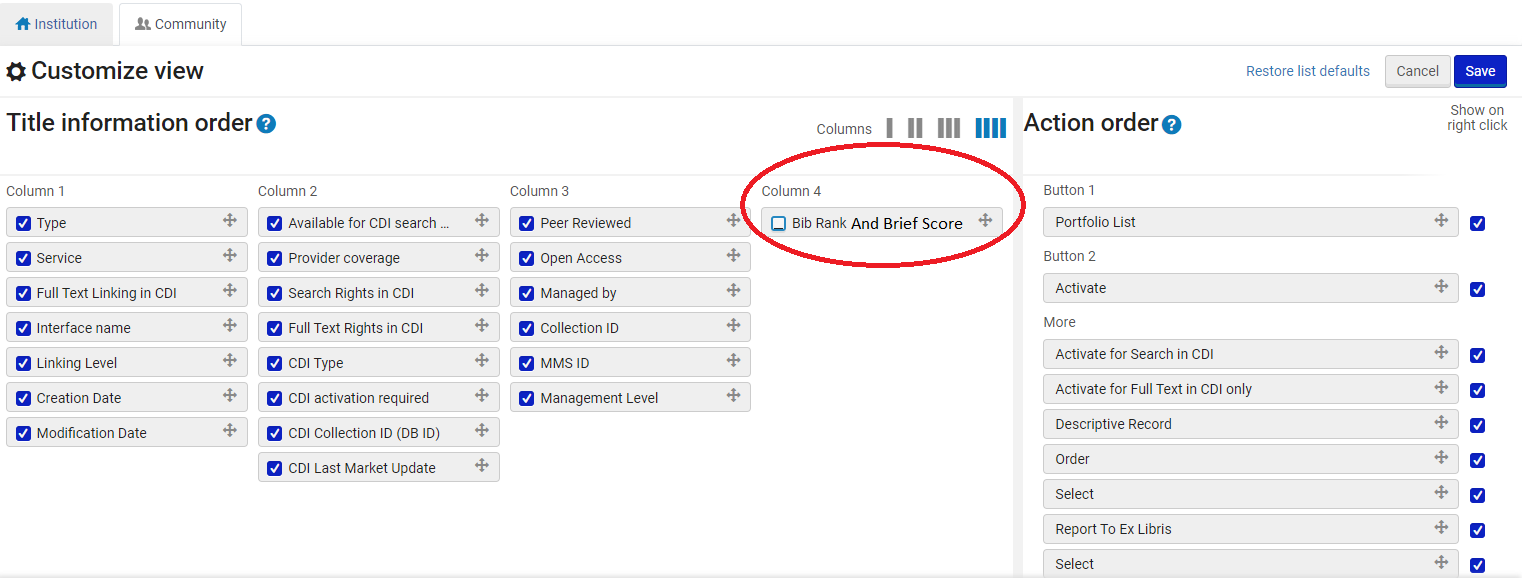
- 検索レコードのエンティティにアクセスし、[列表示の管理]アイコンを選択します(
![[列表示の管理]アイコン](https://knowledge.exlibrisgroup.com/@api/deki/files/154540/ManageColumnDisplay_icon.png?revision=1) )。
)。 - カスタマイズ表示画面の列4で、「書誌ランクと簡易スコア」オプションを選択します。
注: 表示を無効にするには、書誌ランクと簡易スコアオプションの選択を解除します。 - 保存を選択します。
書誌ランクアルゴリズム
Almaは、識別子、名前、件名、有益なLDRおよび008フィールド、出版物の詳細などを含む情報に基づいて、MARC 21書誌レコードの完全性と豊富さを評価します。これは、 書誌ランクは、図書館が注意を必要とする可能性のあるレコードを特定するための便利なツールを提供することを目的としています。新しい書誌ランクが レコード ビュー およびメタデータ エディタで表示されます。
書誌ランキングの範囲は 1 ~ 150 です。一般に、 75位以上にランクされるレコードは良いレコードとみなされます。
書誌ランキングは、以下でさらに説明するアルゴリズムを通じて生成されます。
一般モデル
これは 2レベル のアプローチです:
- レベル 1 - 幅: ここでの焦点はカバレッジです:フィールドはカテゴリにグループ化され、レコードがカテゴリのいずれかのフィールドを持つ場合、その カテゴリの重要度に応じて、スコアが与えられます。
- 重要度が低い場合は1ポイントが与えられます
- 重要度が中程度の場合は3ポイントが与えられます
- 重要度が高い場合は7ポイントが与えられます
例えば、「主題」 カテゴリは重要度が高いので、7ポイントが割り当てられます。キャンセルされた識別子 カテゴリはそれほど重要ではないため、スコアは1のみです。27 カテゴリがあります。全リストは下記のカテゴリーにある通りです。
- レベル 2 - 深さ: 2番目の焦点は深さです。例えば、6XXフィールドがあるかどうかをただチェックするのではなく、6XXフィールドがいくつ含まれているかに気を配ります。 深さは一部のカテゴリにのみ関係します。レコードにこうしたカテゴリがある場合、カテゴリ内のフィールド が カウントされます。フィールドの数は、カテゴリの深さスコアです。関連するカテゴリにはそれぞれ「深さ制限」があり、多くのフィールドを持つことに重きが置かれすぎないようになっています。
合計スコアは、幅のスコア+深さのスコアです。
カテゴリ
以下はカテゴリの全リストです。カテゴリごとに、この情報には以下が含まれています:
- カテゴリ内のフィールドのリスト
- 重要度
- それが深さに関連しているかどうか、関連している場合は次を示します:
- 深さ制限
| No. | カテゴリ名 | [フィールド] | 重要度 | 深さに関係ありますか? | 深さ制限 |
|---|---|---|---|---|---|
| 1 | キャンセルされた識別子 |
| 低 | いいえ | |
| 2 | 分類と請求記号 |
| 高 | はい | 3 |
| 3 | コード化された言語/場所/時間 |
| 低 | はい | 3 |
| 4 | 制御フィールド |
| 媒体 | いいえ | |
| 5 | 008 共通データ | 以下のうち1つ以上、|でも#でもない値を含める必要があります:
| 高 | はい | 5 |
| 6 | 008 図書データ (リーダー/06=a、リーダー/07=a、c、d、またはmの場合) | 以下のうち1つ以上、|でも#でもない値を含める必要があります:
| 低 | いいえ |
|
| 7 | 008 コンピューターファイルデータ (リーダー/06=m) | 以下のうち1つ以上、|でも#でもない値をを含める必要があります:
| 低 | いいえ |
|
| 8 | 008 音楽データ (リーダー/06 = c、d、i、または j) | 以下のうち1つ以上、|でも#でもない値をを含める必要があります:
| 媒体 | はい | 5 |
| 9 | 008 視覚資料データ (リーダー/06 = g、k、o、またはr) | 以下のうち1つ以上、|でも#でもない値をを含める必要があります:
| 媒体 | はい | 5 |
| 10 | 008 マップデータ リーダー/06 = e、またはf) | 以下のうち1つ以上、|でも#でもない値をを含める必要があります:
| 媒体 | はい | 5 |
| 11 | 008 継続的なリソース (リーダー/06 = a およびリーダー/07 = b、i、またはs) | 以下のうち1つ以上、|でも#でもない値をを含める必要があります:
| 媒体 | いいえ |
|
| 12 | 版 | 250 -版表示 | 高 | いいえ | |
| 13 | [識別子] |
| 高 | はい | 10 |
| 14 | リーダー |
| 高 | いいえ | |
| 15 | 名称 |
| 高 | はい | 5 |
| 16 | メモ |
| 低 | いいえ | |
| 17 | 書誌 |
| 低 | いいえ |
|
| 18 | 主題 | 以下の1つ以上は、2番目のインジケータが0/1/2/3/5/6/7である必要があります。
| 高 | はい | 15 |
| 19 | その他の冊子情報 |
| 媒体 | はい | 3 |
| 20 | 冊子説明 | • 300 - 冊子に関する説明 | 媒体 | はい | 5 |
| 21 | 出版物に関する詳細 | • 260 - 出版、流通など。(出版社名) | 高 | いいえ | |
| 22 | 関連アイテム | 以下の1つ以上。$aまたは $tを含める必要があります: | 低 | いいえ | |
| 23 | シリーズ | 以下の1つ以上。$a を含める必要があります: 780 - 先行エントリ 785 - 後続のエントリ | 媒体 | はい | 3 |
| 24 | 概要 | • 520 - 概要 等 | 媒体 | いいえ | |
| 25 | 目次 | • 505 - フォーマットされたコンテンツに関する注記 | 媒体 | いいえ | |
| 26 | タイトル | • 245最低$aまたは $k を含む | 高 | いいえ | |
| 27 | 統一タイトル | • 130 - メインエントリ - 統一タイトル | 低 | いいえ |
著者番号の自動生成
- 905 $d - Alma正規化ルールを使用して093 $aをコピーして作成
- 905 $e - 100、110、111、または245フィールドの$aのコンテンツ、[著者番号リスト]のマッピング表で設定されたマッピング表、およびメタデータエディタの[著者番号生成メニュー]オプションに基づいて作成されます(以下の手順を参照)
- 905 $s - Alma正規化ルールを使用して作成され、905 $d、905 $e、905 $v(必須ではない)、および905 $y(必須ではない)のコンテンツを、各サブフィールドのコンテンツを区切るスラッシュ(/)で連結します 。
- [著者番号リスト]のマッピング表で著者番号リストを構成します。 (Cutter Sanborn Three-Figure 著者番号表から取得した)中国の著者の請求番号が標準化されたリストは、Almaで維持され、[著者番号リスト]のマッピング表で設定できることに注意してください。このテーブルの設定方法に関する詳細については、著者番号リストの構成を参照してください。
- 905 $dおよび905 $sを生成するための正規化ルールを作成します。
- メタデータエディタで、905著者番号に追加したい書誌レコードを開きます。
- 100、110、111、または245フィールドをアクティブフィールドにします。アクティブなフィールドとして選択するフィールドには、$aのコンテンツが必要です。
- [アクションの編集]> [著者番号生成] を選択します (または F4 を押します)。905 $eは著者番号で自動的に生成されます。
- レコードを保存します。
UNIMARC書誌レコードの作成
- メタデータエディタを開きます([リソース] > [目録] > [メタデータエディタを開く])。
- デフォルトの書誌テンプレートを開きます([新規] > [UNIMARC書誌])。
- 書誌内容を入力してください。 MARC 21書誌レコードと同様に、UNIMARC書誌レコードのメタデータエディタも、アラートタブを使用したUNIMARCに固有の検証サポートを提供します。MARC 21フィールドにおける複数のAlmaのメタデータエディタのポップアップ・アシスタント機能と同様に、オートコンプリート機能は特定のUNIMARCフィールドにコンテンツの候補を提供することで目録者をサポートします。UNIMARC 327 $aおよび327 $bに関連して、既知の問題があります。これらのサブフィールドは、同じ機能に基づいています。その結果、327 $aまたは327 $bのいずれかにコンテンツを入力すると、ポップアップが両方のサブフィールドの値を提案します。オートコンプリート機能で提供される同等のUNIMARCフィールドのリストについては、以下の表を参照してください。最初の3文字を入力した後、システムは入力されているフィールド/サブフィールドの候補を提供します。
オートコンプリートに提供される同等のUNIMARCフィールド MARC 21書誌フィールド UNIMARCフィールド 260 $a 210 $a 260 $b 210 $c 260 $e 210 $e 260 $f 210 $g 505 $r 327 $z 505 $t 327 $a 505 $t 327 $b 561 $a 317 $a
4XX UNIMARCフィールドでは、ユーザーアシスタンスは提供されません。 - 変更を保存する前に、[レコードアクション]メニューと[編集アクション]メニューを開いて、UNIMARC レコードを操作するためのすべてのアクティブなオプションを表示します。MARC 21レコードの操作と同様に、テンプレートの作成、レコードの拡張(正規化を使用)、テンプレートからの展開などを行うことができます。
- [保存] を選択して、UNIMARC書誌レコードを保存します。
表示されたUNIMARCレコードの句読点を実装
| UNIMARCマッピング | 句読点 | 説明 |
|---|---|---|
| 700ab, 701ab, 710a,b,c,d,f,e, 711a,b,c,d,f,e if $7=ba or does not exist | 70X a, b Example: Vian, Boris 71X a. b. c (d ; e ; f) Example: Canadian andrology society.Meeting (4th ; 1976 ; Toronto) | 70X bは接頭語に「,^」(「^」はスペース) 71X bは接頭語に「.^」 cは接頭語に「.^」 eは接頭語に「^;^」 fは接頭語に「^;^」 サブフィールドグループdefは接頭語と接尾語に「-」がつきます。 3つのサブフィールドが常に存在するわけではなく、(d) または (d ; f) または(d ; e ; f) などになる可能性があることに注意してください。 |
| 700a-z, 701a-z, 710a-z, 711a-z if $7=ba or does not exist | aからzのすべてのサブフィールドが表示されます | 70Xサブフィールドbcは接頭語に「,^」 サブフィールドfgは接頭語「(」および接尾語に「)」 全てのその他サブフィールドは接頭語に「^」が付きます 71X cの接頭語は「.^」 eの接頭語は「^;^」 fの接頭語は「^;^」 です。サブフィールドグループdefは接頭語に「(」および接尾語に「)-」がつきます。 3つのサブフィールドが常に存在するわけではなく、(d) または (d ; f) または(d ; e ; f) などになる可能性があることに注意してください。 他のすべてのサブフィールドには、先頭語に^が付きます |
| 500a-z (first indicator = 1) if $7=ba or does not exist | aからzのすべてのサブフィールドが表示されます | mは接頭語(および接尾語)に iはhの後ろにある場合、接頭語に「,」が付きます。そうでない場合、iには接頭語として「.^」 が付きます。他のすべてのサブフィールド(ただし、サブフィールドa以外)には接頭語に「.^」が付きます |
| 200a,e if $7=ba or does not exist | 200 a : e | eは接頭語に「^:^」が付きます(^はスペース) |
| 200a,e | 200 a : e | eは接頭語に「^:^」が付きます(^はスペース) |
| 200a,b,c,e,d,h,i,f,g if $7=ba or does not exist | 200 a [b] . c : e d .h, i /f ; g | bの接頭語に[(および接尾語に])が付きます。 cは接頭語に「 .^」が付きます。 dは接頭は付かず、句読点がレコードに目録されます。 eの接頭語は「^:^」 fの接頭語は「^/^」 gの接頭語は「^;^」 hの接頭語は「.^」 iはhの後ろにある場合、接頭語に「,」が付きます。そうでない場合、iは接頭語に「.^」が付きます |
| 200a,b,e,h,i,f,g if $7=ba or does not exist | 200 a [b] : e .h, i /f ; g | bは接頭語に「[」および接尾語に「]」 が付きます。eの接頭語は「^:^」 fの接頭語は「^/^」 gの接頭語は「^;^」 hの接頭語は「.^」 iはhの後ろにある場合、接頭語に「,」が付きます。そうでない場合、iは接頭語に「.^」が付きます |
| 205a if $7=ba or does not exist | ||
| 205a,b,f,g if $7=ba or does not exist | 205 a b / f ; g | fは接頭語に「^/^」が付き gは接頭語に「^; ^」が付きます |
| 206a-z, 208a,b, 230a | ||
| 210a if $7=ba or does not exist | ||
| 210c if $7=ba or does not exist | ||
| 210d | ||
| 328a-z, 210c if $7=ba or does not exist | 各サブフィールドは接頭語に「^」が付きます | すべてのサブフィールドは接頭語に「^」が付きます |
| 210d (1),h (2), 100/09-16 (3), 207a (4) | 100/09-12 - 13-16 | 100/09-16では、位置12と13の間にハイフンが追加されています |
| 例:1981-2003 | ||
| 326a | ||
| 326b | ||
| 3XX -3X9 -39X,327,330 | 各サブフィールドは接頭語に「^」が付きます | |
| 3X9、39X | 各サブフィールドは接頭語に「^」が付きます | |
| 225a,e,i | 225 a : e . i | eは接頭語に「^:^」が付きます(^はスペース) iは接頭語に「.^」が付きます 225フィールドには接頭語に「(」、接尾語に「)」がつきます |
| 225v | ||
| 60Xa-z -23, 616a-z -23, 617a-z -23, 610a | 各サブフィールドは接頭語に「^」が付きます | |
| 69Xおよび6X9 | 各サブフィールドは接頭語に「^」が付きます | |
| 010a | ||
| 019 (Sudoc) | ||
| 011a,f | ||
| LDR/06がlでない場合は011f | ||
| /001 | ||
| 200b | ||
| 327a-z, 330a | 各サブフィールドは接頭語に「^」が付きます | |
| LDR | ||
| 101a | ||
| $7が存在し、baと等しくない場合、700a-z, 701a-z, 710a-z, 711a-z | aからzのすべてのサブフィールドが表示されます | 70Xサブフィールドbcは接頭語に「,^」 サブフィールドfgは接頭語に「(」および接尾語に「)」 全てのその他サブフィールドは接頭語に「^」が付きます 71X bは接頭語に「.^」 cの接頭語は「.^」 eの接頭語は「^;^」 fの接頭語は「^;^」です。 サブフィールドグループdefの接頭語に「(」および接尾語に「)-」がつきます。 3つのサブフィールドが常に存在するわけではなく、(d) または (d ; f) または(d ; e ; f) などになる可能性があることに注意してください。他のすべてのサブフィールドには、先頭語に「^」が付きます |
| $7が存在し、baと等しくない場合は500a-z | mは接頭語(および接尾語)に iはhの後ろにある場合、接頭語に「,」が付きます。そうでない場合、iには接頭語として「.^」 が付きます。他のすべてのサブフィールド(ただし、サブフィールドa以外)には接頭語に「.^」が付きます | |
| 200a、e $ 7が存在し、baと等しくない場合 | 200 a : e | eは接頭語に「^:^」が付きます(^はスペース) |
| $7が存在し、baと等しくない場合、200a,b,c,d,e,h,i,f,g | 200 a [b] . c : e d .h, i /f ; g | bは接頭語に「[」および接尾語に「]」が付きます cは接頭語に「.^」が付きます dには接頭語は付かず。句読点がレコードに目録されます eは接頭語に「^:^」 fは接頭語に「^/^」 gは接頭語に「^;^」 hは接頭語に「.^」が付きます iはhの後ろにある場合、接頭語に「,」が付きます。そうでない場合、iは接頭語に「.^」が付きます |
| $7が存在し、baと等しくない場合は205a | ||
| $7が存在し、baと等しくない場合、205a, b, f, g | 205 a b / f ; g | fは接頭語に「^/^」が付き gは接頭語に「^; ^」が付きます |
| LDR/06 | ||
| LDR/07 | ||
| 200 $b | ||
| 100a/08 | ||
| 100a/09-12 | ||
| 100a/13-16 | ||
| 102a,c | ||
| 010a,z | ||
| 200a,b,c,d,e,h,i,f,g | 200 a [b] . c : e d .h, i /f ; g | bは接頭語に「[」および接尾語に「]」が付きます cは接頭語に「.^」が付きます dには接頭語は付かず。句読点がレコードに目録されます eは接頭語に「^:^」 fは接頭語に「^/^」 gは接頭語に「^;^」 hは接頭語に「.^」が付きます iはhの後ろにある場合、接頭語に「,」が付きます。そうでない場合、iは接頭語に「.^」が付きます |
| 020a | ||
| 035a(1),z (2) | ||
| 700a-z, 701a-z, 710a-z, 711a-z | aからzのすべてのサブフィールドが表示されます | 70Xサブフィールドbcは接頭語に「,^」 サブフィールドfgは接頭語に「(」および接尾語に「)」 全てのその他サブフィールドは接頭語に「^」が付きます 71X bは接頭語に「.^」 cの接頭語は「.^」 eの接頭語は「^;^」 fの接頭語は「^;^」です。 サブフィールドグループdefの接頭語に「(」および接尾語に「)-」がつきます。 3つのサブフィールドが常に存在するわけではなく、(d) または (d ; f) または(d ; e ; f) などになる可能性があることに注意してください。 他のすべてのサブフィールドには、先頭語に「^」が付きます |
| 410 a,t,o,h,i,x | 400 a t : o. h, i | hは接頭語に「.^」が付きます iはhの後ろにある場合、接頭語に「,」が付きます。そうでない場合は、iの接頭語は「.^」で、 oの接頭語は「^:^」です |
| 203a,b | ||
| 203c | ||
| 一致なし | ||
| 126a,b | ||
| 125a,b | ||
| 115a,b | ||
| 135a, 230a | ||
| 一致なし | ||
| 145a-i,146a-i |
マルチスクリプトUNIMARC書誌レコードの操作
ラテン表示
- 200、205、206、207、208、210
- 327
- すべての4XXフィールド:410、411、412、413、421、422、423、424、425、430、431、432、433、434、435、436、437、440、441、442、443、444、445、 446、447、448、451、452、453、454、455、456、461、463、464、470、481、482、488
- すべての5XXフィールド:500、501、503、510、511、512、513、514、515、516、517、518、520、530、431、532、540、541、545
- 600、601、602、605
- すべての7XXフィールド:700、701、702、710、711、712、716、720、721、722
典拠管理
- 典拠 - 書誌の標目をリンクする
- 典拠 - 優先語の修正
- F3
UNIMARCの複数のアクセスポイントの使用
KORMARC書誌レコードの作成
- メタデータエディタを開きます([リソース] > [目録] > [メタデータエディタを開く])。
- デフォルトの書誌テンプレートを開きます([新規] > [KORMARC書誌])。
- 書誌内容を入力してください。 次のフィールドに入力する際、最初の3文字の入力後、システムはポップアップアシスタンスを提供します。
- 260 $$a、b、e、f
- 264$b
- 505 $$r、t
- 561$a
MARC 21書誌レコードと同様に、KORMARC書誌レコードのメタデータエディタも、アラートタブを使用してKORMARCに固有の検証サポートを提供します。KORMARC 008コントロールフィールドのフォームエディタ([アクションの編集] > [フォームエディタを開く])を開くと、次のKORMARCフィールドオプションが提供されます。- 韓国政府機関
- 韓国大学
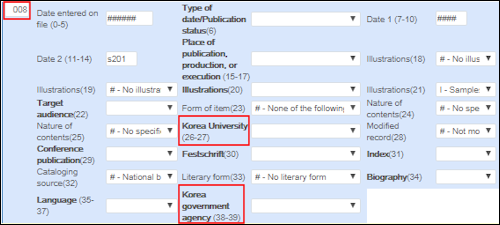 メタデータエディタのKORMARC 008コントロール・フィールド・オプション
メタデータエディタのKORMARC 008コントロール・フィールド・オプション - [保存]を選択して、KORMARC書誌レコードを保存します。
KORMARC書誌レコードの090ローカル請求番号フィールドの著者番号の自動生成
- 090 $a-082 $aからコピーされたデューイ請求番号
- 090 $b-著者の姓の最初のイニシャルで構成される接頭辞と、G329wなどのタイトルの最初のイニシャルを含む接尾辞を持つ標準化された著者番号のリストから取得される著者番号
- 090$ c - 260 $cからコピーされた年
- メタデータエディタで、090著者番号に追加したい書誌レコードを開きます。
- 100または700の著者フィールドをアクティブフィールドにします。
- [アクションの編集] > [著者番号生成]を選択します(またはF4を押します)。[著者番号リスト]の設定([設定メニュー > リソース > 目録 > 著者番号リスト])で1つの著者 番号リストのみを有効にしている場合、 [著者番号リスト]の設定 で特定したターゲットフィールドとサブフィールドが、著者番号とともに自動的に生成されます。[著者番号リスト]の設定で複数の著者 番号リストの設定を有効にしている場合、システムは使用する著者番号 リストを選択するようプロンプトします。
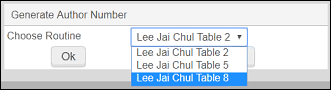 著者番号リストを選択詳細については、標準著者番号リストの設定を参照してください。
著者番号リストを選択詳細については、標準著者番号リストの設定を参照してください。 - レコードを保存します。
CNMARC書誌レコードの作成
- メタデータエディタを開きます([リソース] > [目録] > [メタデータエディタを開く])。
- デフォルトの書誌テンプレートを開きます([新規] > [CNMARC書誌])。
- 書誌内容を入力してください。 MARC 21書誌レコードと同様に、CNMARC書誌レコードのメタデータエディタも、アラートタブを使用してCNMARCに固有の検証サポートを提供します。検証基準は、CNMARCメタデータプロファイルでカスタマイズできます(検証ルーチンの編集を参照)。
- [ファイル]メニューを使用するか、[保存]アイコンを選択してCNMARC書誌レコードを保存します。
CNMARC 6XXフィールドに複数のアクセスポイントを使用する

Dublin Core書誌レコードの作成
- メタデータエディタを開きます([リソース] > [目録] > [メタデータエディタを開く])。
- [新規] > [Dublin Core] を選択します。 メタデータエディタにより、Dublin Coreレコードを入力するためのデフォルトのテンプレートが開かれます。
- Dublin Coreレコードのデータを入力します。詳細については、メタデータエディタメニューとツールバーオプションセクションを参照してください。

書誌レコードの統合
- 目録者(拡張)
- 注文明細
- 電子コレクション
- 電子ポートフォリオ
- 冊子アイテム
- デジタル表記
- 貸出
- リクエスト
- リーディングリスト
- 関連レコードの関係(MMS IDに基づく)
目録の統合と結合プロセスのセカンダリレコードに、76X〜78Xフィールドのいずれかで指定されたセカンダリレコードのMMS IDの関連レコードがある場合、MMS IDは、関係を維持するため(また親関係のない関連レコード、つまり孤立したレコードを持たないようにするため)、 統合プロセス中にプライマリレコードのMMS IDに更新されます。
-
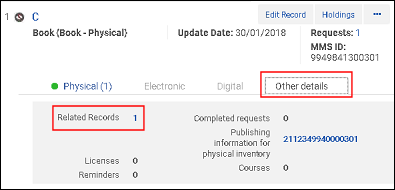
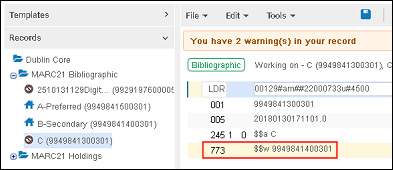 統合前のセカンダリレコードに関連するレコード/773$wのMMS ID
統合前のセカンダリレコードに関連するレコード/773$wのMMS ID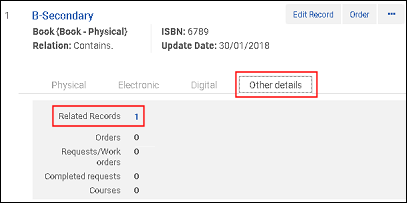 統合前の関連レコードを含むセカンダリレコード
統合前の関連レコードを含むセカンダリレコード
- 2つの書誌レコードを統合できるのは、両方のレコードが機関ゾーンレコードであるか、両方がネットワークゾーンレコードである場合のみです。 機関ゾーン 書誌 レコードをネットワークゾーン書誌レコードと統合することはできません。
- レコードを統合する際にセカンダリレコードから識別子を取得し、プライマリレコードにそれを配置することについての詳細は、書誌リダイレクトフィールドの設定を参照してください。
- ネットワークゾーンで書誌レコードを統合するとき、プロセスは、非優先書誌レコードが 他のメンバーによって保持されているかどうかをチェックします。保持されている場合、プロセスはすべてのメンバーの目録を優先書誌レコードに移動します。この場合、非優先レコードが抑制されると、抑制は優先レコードに継承されます。
- 統合する2つの書誌レコードを探します。プライマリレコードは、セカンダリレコードからの情報で更新されます。
- メタデータエディタの[レコード]タブに両方が表示されるように、両方のレコードを編集します。
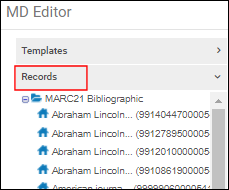
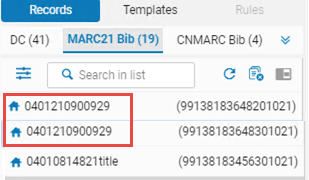 レコードタブ下の書誌レコード
レコードタブ下の書誌レコード - [レコード]タブの[ナビゲーション]ペインから、プライマリレコードを選択します。
- [編集画面の分割表示]アイコンを選択し、セカンダリレコードを選択して右側に表示します。
- [アクションの記録] > [記録をマージして結合] を選択します。
レコードの統合と目録の統合ダイアログボックスが表示されます。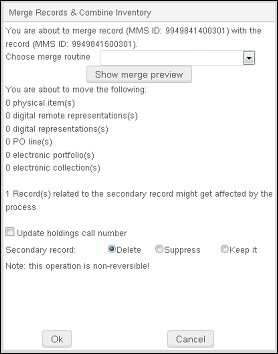 統合と結合を実行する場合、移動されるセカンダリ(非優先)レコードの目録は、 ローカル レコードである場合にのみカウンターに表示されます。 これは、次の2つの場合に当てはまります。
統合と結合を実行する場合、移動されるセカンダリ(非優先)レコードの目録は、 ローカル レコードである場合にのみカウンターに表示されます。 これは、次の2つの場合に当てはまります。
- ローカル(キャッシュ)バージョンのNZレコードがあり、目録がある機関にログインしている場合。
- 統合と結合がスタンドアローンで実行され、いずれの場合も両方のレコードがローカルになる場合。 - 表示されたメッセージを確認します。特にこの操作は元に戻すことができないことに注意してください。 次の項目を移動しようとしていますの下に、統合後に生じる変更の一覧が表示されます。さらにセカンダリレコードに添付されている所蔵リクエスト、貸出、およびリーディングリストが更新されます。さらに、セカンダリレコードに関連するレコードでは、関連レコードの76X〜78Xフィールドのいずれかで指定されたMMS IDが、[レコードの統合と目録の統合]プロセスで指定されたプライマリレコードのMMS IDに変更されます。リクエストがある場合、リクエストの数が表示されます。技術的な制限により、リクエストがない場合、ダイアログボックスには「0リクエスト」が表示されません。代わりに、リクエストに関する行が表示されません。
- ドロップダウンリストから統合ルーチンを選択します。リストに表示される統合ルーチンは、メタデータエディタのルールタブにある統合ルールリストから取得されます。
- 統合結果をプレビューするには、[統合プレビューを表示]を選択します。統合プレビュー表示を閉じるには[OK]を選択します。
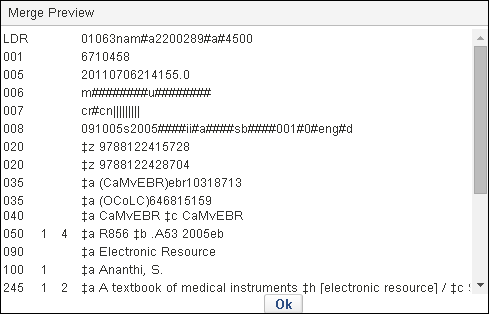 統合プレビュー
統合プレビュー - 必要に応じて、[所蔵請求番号のアップデート]を選択します。このオプションを選択すると、システムは、プライマリレコードに関連付けられている(書誌請求番号を使用した)すべての所蔵請求番号情報を更新します。この変更は、書誌統合が処理された後、プライマリレコードに関連付けられた所蔵に適用されます。書誌レコードの請求番号フィールドの1つが更新されると、最終的に所蔵レコードに表示される請求番号に影響する可能性があることに注意してください。
- 次のオプションから、セカンダリ書誌レコード(統合後)の処理方法を選択します。
- [削除]
- サプレス
- [そのままにする]
- 2つのレコードを統合する準備ができたら、[OK]を選択します。
書誌レコードの表示
書誌レコードの管理
書誌レコードの削除
- 目録者(拡張)
メタデータエディターで削除する前に、レコードをローカライズする必要があります。このためには、 ポートフォリオがないコミュニティゾーンの書誌レコードを機関ゾーンから削除するを参照してください。
ユーザーは削除できる レコードの起源がコミュニティ ゾーンにある場合でも、機関タブからネットワーク ゾーンの書誌レコードを取得できます。
書誌記録の保存としてマークされたレコードは削除されないように保護されます。詳細については、 書誌記録の保存を参照してください。
- メタデータエディタツールバーの [レコードアクション]の下にある[書誌レコードを削除する]を選択します。
書誌レコードは次の場合にのみ削除できます。
-
注文明細なし
-
注文明細を閉じる
-
注文明細をキャンセル
-
アクティブな購入リクエストはありません
機関ゾーンで書誌レコードを削除し、それを保持するコンソーシアムの最後の図書館である場合、そのレコードは ネットワークゾーンで自動的に削除されます。 ネットワークゾーンで自動的に削除せず、 代わりにネットワークゾーンから手動で削除したい場合は、 delete_nz_bib_without_inventory 顧客パラメーター([設定] > [リソース] > [一般] > [その他の設定])をfalseに設定します(「 その他の設定(リソース管理)」を参照)。
コミュニティ ゾーンから生成された書誌レコードを削除すると、コミュニティ ゾーン レコードは削除されず、ローカル レコードのみが削除されることを示す通知メッセージがユーザーに表示されます。
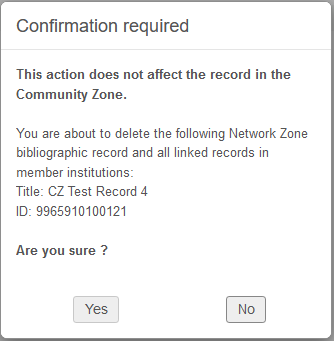
書誌レコードのセットの削除
- 目録管理者
- 目録マネージャー
- 書誌レコードの削除ジョブを実行します。上記の条件のいずれかが原因で削除できないレコードは、ジョブレポートで識別されます。 これらのレコードに関連付けられている目録を 削除する場合は、
[関連するすべての目録リソースを削除]オプションを選択します。
書誌レコードの保持
Alma を使うことで、図書館は書誌レコード削除を防止することが可能になります。 これを実装するために、書誌コレクションの保持の定義 テーブル (設定メニュー > リソース > コレクション保持 > 書誌コレクション保持定義)を設定することが可能です。管理者 はレコード保持の条件を指定できます。サブフィールドに値が含まれている場合にレコードが削除されないようにするには、フィールドとサブフィールドを追加します。あるいは、特定の値を指定することで、サブフィールドにその値を持つレコードのみが 保持されます。

テーブルの設定後は、Almaは書誌レコードを削除しようとする際 検証 を実行します。レコードにテーブルから指定された内容が含まれているかどうかを 検証します。コンテンツが存在する場合、bib レコードは 削除から保護されます。さらに、テーブルが更新された後は、定義された基準に一致するレコードはすべてコミット済みとしてマークされ、次回のインデックス作成時 (変更および保存時、または半年ごとの再インデックス作成時) に保持されます。これにより、保持されたレコードをシステム内で検索できるようになります。
Committed to Retain (所蔵を確約)マークされたレコードは、 Committed to Retain(所蔵を確約) アイコン(![]() )、を表示し、 レコードが削除されないよう保護されていることを示します。
)、を表示し、 レコードが削除されないよう保護されていることを示します。
ネットワークゾーンレコードの場合、保持ポリシーは ネットワークゾーンテーブルで指定された設定に基づいて決定されます。コミュニティゾーンにリンクされている書誌レコードを削除しようとすると、ローカル機関が行った特定の設定に基づいて、 リンクされたレコードの機関からの削除が制限されます。ローカル拡張フィールドは保持フィールドとして使用できません。ローカル拡張機能ではなく機関ゾーンで使用されるフィールドは、保持フィールドとして使用できます。
書誌レコードを操作しながらリンクされたデータを使用する
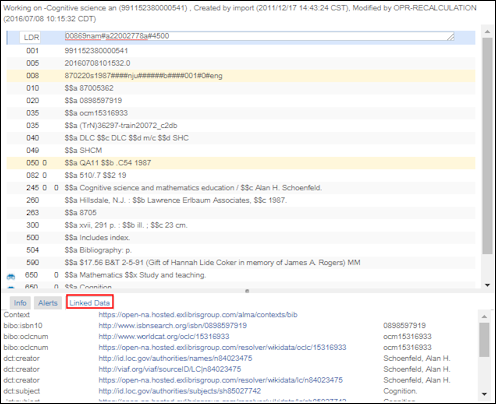
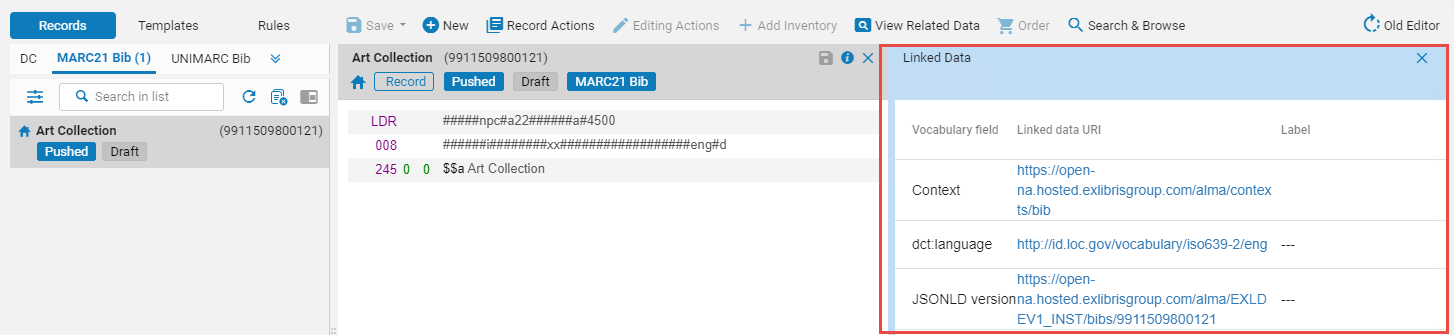
- 語彙フィールド - これはコンテキストに従って取得されます。デフォルトのコンテキストは、cname.alma.exlibrisgroup.com/[format]/[works_or_instances]/[MMSID]です。 たとえば、bgu.alma.exlibrisgroup.com/bf/instances/9922819700121です。
コンテキストへのパスを持つアクティブなリンク済みデータ統合プロファイル(リンク済みデータを参照)がある場合、このコンテキストが使用されます。以前のAlma URIフォーマットは すべて、以下の新しいAlma URIフォーマットにリダイレクトされます:cname.alma.exlibrisgroup.com/[format]/[works_or_instances]/[MMSID]。
機関が希望する場合は、Webアドレスの先頭(URLプレフィックス)をcname.alma.exlibrisgroup.comから独自のプレフィックスまたは他のプレフィックスに変更できます。たとえば、bgu.ac.ilなどです。この変更はリンクされたデータ統合プロファイルで行うことができ、機関のIT部門によってドメインが同じIPアドレスに登録されている限り、レコードは解決さ れます。Almaリポジトリ検索結果からリンクされたデータにアクセスするために、 リンク済みデータ統合プロファイル を作成する必要はありません。ただし、リンクされたデータをJSON-LDフォーマットで公開する必要があります(詳細については、リンク済みデータを参照)。 - リンク済みデータURI IdRef 権限にリンクされている書誌レコードのリンク データは、IdRef 権限レコードへの URI も生成するようになりました。
- ラベル - ISBN、ISSN、およびOCLCの場合、フィールドの内容が表示されます。作成者と件名については、標目の値が表示されます。
UTFで構成/分解されたUnicode表現の処理(UTF-8および発音区別符号付きの文字)
Almaは、書誌レコードまたは典拠レコードを保存するときに、分解された文字を構成された形式に正規化することをサポートしています。
たとえば、Amélie という単語は、正規に同等の2つのUnicode形式を持つことができます。
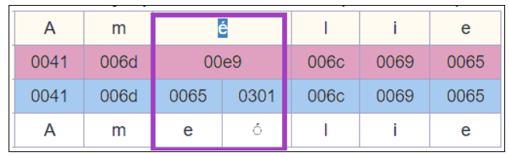
この機能により、これらの 文字を含むレコードが保存されると、分解された形式(0065+0301)が構成された形式(00e9)に正規化されます。
UTFで構成/分解された表現を処理するようにAlmaを設定すると、 優先語修正ジョブでの標目の更新も回避されます。 書誌レコードの標目と典拠の標目が同じ同等のUTF 表現(構成されたものと分解されたもの)を持っている場合、PTCは修正をスキップします。これにより、 典拠タスク制御リスト と公開から冗長な 標目の更新が除外されます。
これは、すべてのAlmaレコード、または特定のローカル単語に対して定義できることに注意してください。
この機能はデフォルトでは無効になっています。Ex Librisの スタッフに連絡して、 所属機関と連携してアクティブ化してください。