
使用书目记录
- 编目员
- 编目员扩展
- 编目管理员
- 编目经理
创建书目记录
创建MARC 21书目记录
- 打开元数据编辑器(资源 >编目> 打开元数据编辑器)。
- 选择新建 > MARC 21书目并选择输入书目记录的默认模板。 元数据编辑器打开该模板。
- 输入您的书目记录数据。有关使用元数据编辑器的其他信息,见元数据编辑器菜单和工具栏选项部分。 编制010或035字段时,请为要为此字段保存的每个空格输入一个井号(#)。内容作为空格(输入每个#号符)保存到Alma数据库,但作为#号符显示在元数据编辑器中,以便更清楚地标识字段中精确的空格数。以下字段中,系统会在输入前三个字符后提供弹出窗口帮助(见下文说明):
- 260 $$a, b, e, f
- 264 $$a, b
- 505 $$r, t
- 561 $a
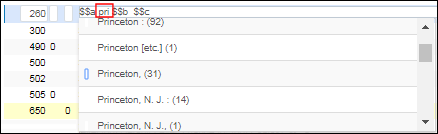 弹出窗口帮助示例(非建议主题)输入特殊字符时,弹窗帮助按以下客户参数设置方式显示:
弹出窗口帮助示例(非建议主题)输入特殊字符时,弹窗帮助按以下客户参数设置方式显示:- 输入记录内容且元数据编辑器提供建议(输入开头部分字符后)并使用Eszett字符或在Eszett处使用ss时,根据您输入的内容提供相应建议。也就是说,输入含有ß的值,例如Großbritannien,只显示含有ß的结果,输入含有ss的值时,例如Grossbritannien,只显示含有ss的结果。
- 输入记录内容且元数据编辑器提供建议(输入开头部分字符后)并使用umlaut字符或不含有umlat的字母时,根据您输入的内容提供相应建议。所以,如果输入Müller,会得到含有ü的建议;如果输入Muller。会得到不含有ü的建议。
- 输入记录内容且元数据编辑器提供建议(输入开头部分字符后)并输入连字符时,仅显示含有连字符的结果,例如Baden-Baden。例如,如果输入没有连字符的Baden Baden,仅显示不含连字符的结果。
联系客户支持设置子字段建议的客户参数以按照你所希望的方式处理元数据编辑器建议。为这些字段提供的弹出帮助不是推荐的规范/书目主题。弹出帮助由在控制词汇注册表(见配置控制词表注册表)中创建和保存的说明,然后,使用选择受控词汇(见编辑字段)在元数据配置中识别以选择之前创建的说明的受控词汇列表。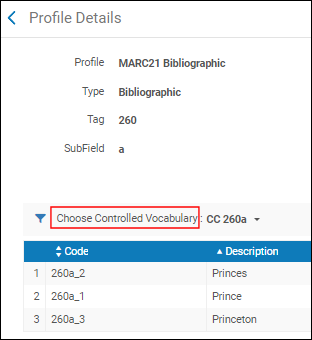 选择受控词汇要访问推荐规范和书目主题,在您输入/检查的字段中按F3。系统打开选定的选项列表。如果没有主题推荐可用,Alma显示找不到匹配主题。有关更多信息,见使用F3。
选择受控词汇要访问推荐规范和书目主题,在您输入/检查的字段中按F3。系统打开选定的选项列表。如果没有主题推荐可用,Alma显示找不到匹配主题。有关更多信息,见使用F3。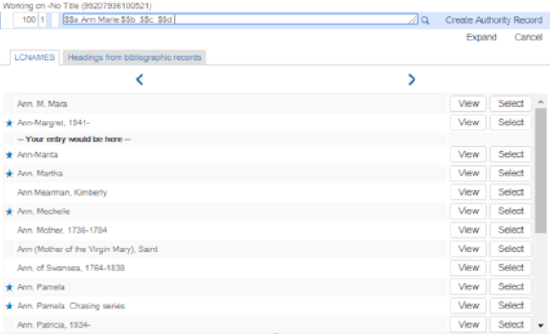 F3 示例 - 推荐规范和书目主题如果使用IE并使用F3,请确保选定文本时按回车。否则,主题列表可能不会正常显示。对多个规范词汇定义优先级时,系统按照优秀级顺序检查匹配并在单独选项卡中按照使用F3时的优先级顺序从左至右显示结果(如GND和LCSH)。有关更多信息,见规范优先级。
F3 示例 - 推荐规范和书目主题如果使用IE并使用F3,请确保选定文本时按回车。否则,主题列表可能不会正常显示。对多个规范词汇定义优先级时,系统按照优秀级顺序检查匹配并在单独选项卡中按照使用F3时的优先级顺序从左至右显示结果(如GND和LCSH)。有关更多信息,见规范优先级。- 本地规范文件使用含有(本地)字样的括号标识。
- 优先选项用星号标识。非优先选项的左边为空白(没有星号)。
- 选择查看显示完整的规范记录。
- 点击选择将内容插入到您正在操作的记录中。
- 选择来自书目记录的主题选项卡查看推荐书目主题。
- 其他信息见 处理规范记录。
- 点击保存图标。有关保存记录的其他信息,见在元数据编辑器中保存记录。
处理GND记录的统一题名主题
- 075 $b u
- 130字段和500,510或511的$9含有以下内容:
- 4:auta
- 4:koma
- 4:regi
- 4:kuen
生成以$ t开头的统一题名的规范标题
处理240字段和统一题名书目主题
元数据编辑器中的书目排序
Alma根据标识符、名称、主题、LDR和008字段、出版详情等信息评估MARC 21书目记录的完成性和丰富性。这体现在书目排序中,这提供了一个帮助性的工具使图书馆可以识别哪些记录需要特别注意。新书目排序显示在记录视图和元数据编辑器中。
关于书目排序的更多信息,见书目排序算法。
共享区资源库中的书目排名
此信息显示在资源库级别:所有管理标签的资源库检索结果(由Ex Libris管理、由共享区管理、已提交、未维护、待删除)。
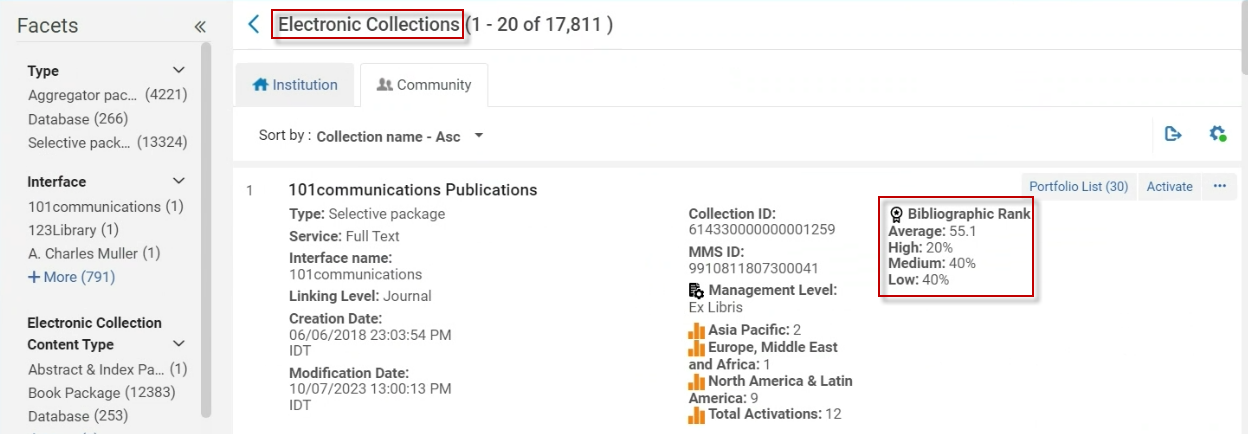
“书目排名”字段在共享区资源库中可见。该字段显示资源库内书目记录的平均排名,并在三个不同的级别上运作:
- 低 - 0-39
- 中 - 40-79
- 高 - 80-150
书目排名范围在1 - 150之间。一般来说,排名高于75的记录视为良好记录。
上述三个质量类别基于书目记录的书目排名资源库内的分布。书目排名的逻辑是在资源库级别上显示所有关联书目记录的书目排名的平均值,以便用户知道哪个资源库更适合激活,以及在激活资源库之前期望从中获得何种质量。
包含共享区资源库质量数据(例如平均书目排名)可授权用户解决有关特定共享区资源库内MARC记录质量的查询。
用户将获得以下有关共享区资源库级别的附加信息:
| 书目排名 | 描述 |
|---|---|
| 平均值 | 所有单个书目排名的总和除以记录总数。 |
| 高 | 具有“高”书目排名的记录百分比(按上述三个不同级别计算 - 80-150)。 |
| 中间 | 具有“中间”书目排名的记录百分比(按上述三个不同级别计算 - 40-79)。 |
| 低 | 具有“低”书目排名的记录百分比(按上述三个不同级别计算 - 39以下)。 |
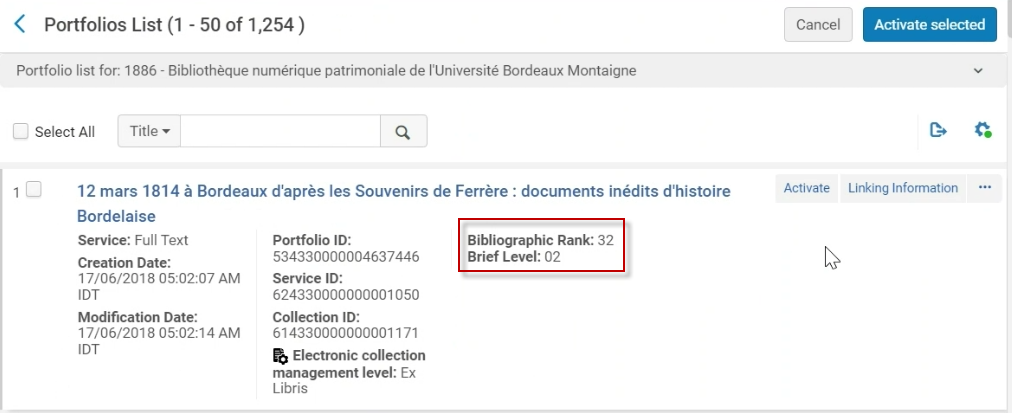
自定义视图的选项已扩展为包括资源库列表级别信息的书目排名和简明级别字段。如果需要,用户可以选择在检索结果中显示这些详细信息。有关简明级别字段资源的更多信息,见书目排名算法中的级别1 - 广度。
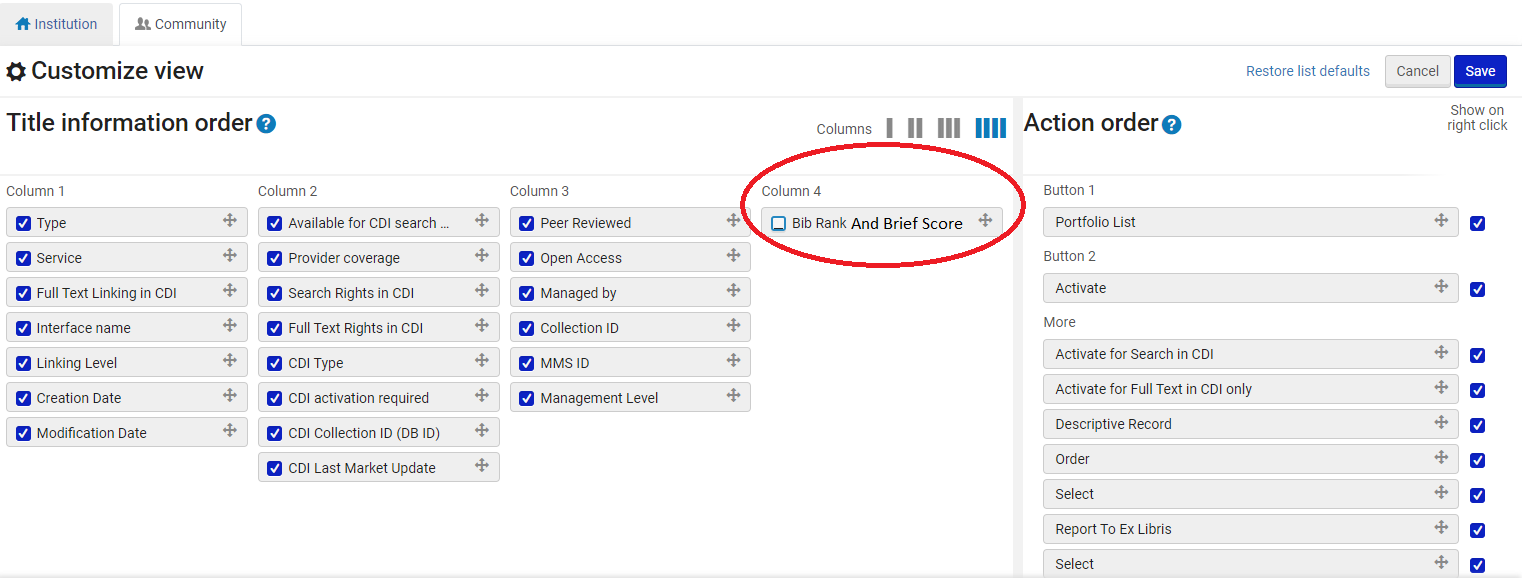
- 访问任何搜索记录实体并选择“管理列显示”图标(
 ).
). - 在“自定义视图”屏幕的第4列中,选择“书目排名和简明分数”选项。
注意:要禁用视图,请取消选择书目排名和简明分数选项。 - 选择保存。
书目排序算法
Alma根据标识符、名称、主题、LDR和008字段、出版详情等信息评估MARC 21书目记录的完成性和丰富性。这体现在书目排序中,这提供了一个帮助性的工具使图书馆可以识别哪些记录需要特别注意。新书目排序显示在记录视图和元数据编辑器中。
书目排名范围在1 - 150之间。一般来说,排名高于75的记录视为良好记录。
书目排名是通过下面进一步描述的算法生成的。
通用模型
这是两个级别的方法:
- 级别1 - 广度:该级别中的重点是覆盖范围:字段按类别分组,并且如果记录具有类别中的任何一个字段,则根据该类别的重要性给出分数。
- 低重要性为1分
- 中等重要性为3分
- 高度重要性为7分
例如,主题类别重要性很高,因此分数为7。取消的标识符类别不太重要,因此分数仅为1。我们提供27个类别。完整列表在类别中描述如下。
- 级别2 - 深度:第二个重点是深度。例如,不只是检查是否有6XX字段,还要注意包括多少6XX字段。 深度仅与某些类别相关。当一条记录具有这样的类别时,该类别中的字段就会被计数。字段的数量就是该类别的深度分数。每个相关类别都有一个“深度限制”,以避免为拥有多个字段的类别提供太高的权重。
总分数是广度分数 + 深度分数。
类别
以下是完整的类别列表。对于每个类别,都包含以下信息:
- 类别中的字段列表
- 重要性
- 指示是否与深度相关,如果是:
- 深度限制
| # | 类别名称 | 字段 | 重要性 | 与深度相关吗? | 深度限制 |
|---|---|---|---|---|---|
| 1 | 取消的标识符 |
| 低 | 否 | |
| 2 | 分类和索书号 |
| 高 | 是 | 3 |
| 3 | 编码语言/地点/时间 |
| 低 | 是 | 3 |
| 4 | 控制字段 |
| 中等 | 否 | |
| 5 | 008 - 公共数据 | 以下一项或多项必须具有不是|或#的值:
| 高 | 是 | 5 |
| 6 | 008 - 图书数据 (如果头标区/06 = a且头标区/07 =a、c、d或m) | 以下一项或多项必须具有不是|或#的值:
| 低 | 否 |
|
| 7 | 008 - 计算机文件数据 (头标区/06 = m) | 以下一项或多项必须具有不是|和#的值:
| 低 | 否 |
|
| 8 | 008 - 音乐数据 (头标区/06 = c、d、i或j) | 以下一项或多项必须具有不是|和#的值:
| 中等 | 是 | 5 |
| 9 | 008 - 视觉材料数据 (头标区/06 = g、k、o或r) | 以下一项或多项必须具有不是|和#的值:
| 中等 | 是 | 5 |
| 10 | 008 - 地图数据 头标区/06 = e或f) | 以下一项或多项必须具有不是|和#的值:
| 中等 | 是 | 5 |
| 11 | 008 - 持续资源 (头标区/06 = a,头标区/07 = b、i或s) | 以下一项或多项必须具有不是|和#的值:
| 中等 | 否 |
|
| 12 | 版本 | 250 - 版本声明 | 高 | 否 | |
| 13 | 标识符 |
| 高 | 是 | 10 |
| 14 | 头标区 |
| 高 | 否 | |
| 15 | 名称 |
| 高 | 是 | 5 |
| 16 | 备注 |
| 低 | 否 | |
| 17 | Bibliography |
| 低 | 否 |
|
| 18 | 主题 | 以下一项或多项必须有值为0/1/2/3/5/6/7的第二个指示符。
| 高 | 是 | 15 |
| 19 | 其他纸本信息 |
| 中等 | 是 | 3 |
| 20 | 纸本描述 | • 300 - 纸本描述 | 中等 | 是 | 5 |
| 21 | 出版详细信息 | • 260 - 出版、发行等。(出版项) | 高 | 否 | |
| 22 | 相关单册 | 一个或多个以下项。必须包含$a或$t: | 低 | 否 | |
| 23 | 连续出版物 | 一个或多个以下项。必须包含$a: 780 - 先前条目 785 - 后续条目 | 中等 | 是 | 3 |
| 24 | 概要 | • 520 - 概要等 | 中等 | 否 | |
| 25 | 目录 | • 505 - 格式化内容备注 | 中等 | 否 | |
| 26 | 题名 | • 245,至少具有$a或$k | 高 | 否 | |
| 27 | 统一题名 | • 130 - 主条目 - 统一题名 | 低 | 否 |
自动生成著者号
- 905 $d - 通过使用Alma规范化规则复制093 $a创建
- 905 $e - 基于100,110,111或245字段的$a,著者列表映射表中配置的映射表和元数据编辑器中的生成著者号菜单选项创建(见下列步骤)
- 905 $s - 使用用于连接905 $d、905 $e、905 $v(非必需)和905 $y(非必需)的内容并用斜杠(/)分隔子字段内容的Alma规范化规则创建。
- 在著者号码列表映射表中配置著者号码列表。 请注意,中文作者索书号(从卡特三位数著者表获得)的标准列表在Alma中维护,可以配置作者号码列表映射表。有关如何配置此表格的详细信息,见著者号码列表配置。
- 创建用于生成905 $d和905 $s的规范化规则。
- 在元数据编辑器中,打开要添加905著者号的书目记录。
- 使100,110,111或245字段成为有效字段。选定为有效的字段必须在$a中有内容。
- 选择编辑操作 > 生成著者号(或按F4)。905 $e自动生成著者号。
- 保存记录。
创建UNIMARC书目记录
- 打开元数据编辑器(资源 >编目> 打开元数据编辑器)。
- 打开默认书目模板(新建 > UNIMARC书目)。
- 输入您的书目内容。 与MARC 21书目记录类似,UNIMARC书目记录的元数据编辑器使用提示选项卡提供UNIMARC的验证支持。类似于Alma元数据编辑器在一些MARC 21字段的弹出窗口帮助功能,也提供了相同的自动完善功能来为某些UNIMARC字段提供内容建议以协助编目员。有一个与UNIMARC 327 $a和327 $b有关的已知问题。这些子字段基于相同的功能。因此,在327 $a或327 $b中输入内容时,弹出窗口建议子字段的值。有关自动完成功能提供的等效UNIMARC字段的列表,见下表。输入前三个字符后,系统会尝试为输入的字段/子字段提供建议。
提供自动完成的等效UNIMARC字段 MARC21书目字段 UNIMARC字段 260 $a 210 $a 260 $b 210 $c 210 $c 210 $e 260 $f 210 $g 505 $r 327 $z 505 $t 327 $a 505 $t 327 $b 561 $a 317 $a
没有为4XX UNIMARC字段提供用户帮助。 - 保存更改之前,打开记录操作和编辑操作菜单查看处理UNIMARC记录的所有活动选项。类似于处理MARC 21记录,您可以创建模板、完善记录(使用规范化)和从模板展开等等。
- 选择保存保存您的UNIMARC书目记录。
为显示的UNIMARC记录实施标点符号
| UNIMARC 映射 | 标点 | 说明 |
|---|---|---|
| 700ab, 701ab, 710a,b,c,d,f,e, 711a,b,c,d,f,e如果$7= ba或不存在 | 70X a, b 例如: Vian, Boris 71X a. b. c (d ; e ; f) 例如: Canadian andrology society.Meeting (4th ; 1976 ; Toronto) | 70X b前缀是 ,^(^为空格) 71X b的前缀是.^ c 前缀是.^ e的前缀是^;^ f的前缀是^;^ 子字段def的前缀是(后缀是)- 注意,有3个子字段并非经常出现,有可能是(d)或(d ; f)或 (d ; e ; f)等。 |
| 700a-z, 701a-z, 710a-z, 711a-z 如果$7=ba 或不存在 | 由a到z显示全部子字段 | 70X 子字段 bc前缀是 ,^ 子字段 fg 前缀是(后缀是) 所有其他子字段前缀都为^ 71X b is 前缀是.^ c 前缀是 .^ e 前缀是^;^ f前缀是 ^;^ 子字段def组合前缀是 (后缀是) - 注意,有3个子字段并非经常出现,有可能是(d) 或 (d ; f)或 (d ; e ; f) 等. 所有其他子字段前缀为^ |
| 500ba-z(第1指示符 = 1)如果 $7= ba或不存在 | 显示全部子字段a到z | m前缀是(后缀是), i如果在在h后,前缀是,。否则,i前缀是.^ 所有其它子字段(除子字段a)前缀是 .^ |
| 200a,e 如果$7=ba 或不存在 | 200 a : e | e 前缀是^:^ (^为空格) |
| 200a,e | 200 a : e | e 前缀是^:^ (^为空格) |
| 200a,b,c,e,d,h,i,f,g 如果$7= ba或不存在 | 200 a [b] . c : e d .h, i /f ; g | b前缀为[后缀为] c前缀是.^ d没有前缀,标点符号被编目在记录中 e前缀为^:^ f 前缀是^/^ g前缀是^;^ h前缀是.^ i如果在h后前缀为,否则,i前缀是点^ |
| 200a,b,e,h,i,f,g 如果$7=ba 或不存在 | 200 a [b] : e .h, i /f ; g | b 前缀是[后缀是] e前缀是^:^ f 前缀是 ^/^ g前缀是 ^;^ h前缀是. i如果在在h后,前缀是,否则,i前缀是点^ |
| 205a 如果$7=ba 或不存在 | ||
| 205a,b,f,g 如果$7=ba 或不存在 | 205 a b / f ; g | f前缀是 ^/^ g前缀是 ^;^ |
| 206a-z, 208a,b, 230a | ||
| 210a 如果$7=ba 或不存在 | ||
| 210c 如果$7=ba 或不存在 | ||
| 210d | ||
| 328a-z, 210c 如果$7=ba 或不存在 | 每个子字段前缀是^ | 所有子字段前缀都是^ |
| 210d (1),h (2), 100/09-16:16 (3), 207a (4) | 100/09-12 - 13-16 | 100/09-16在12号和13号之间加了连字符 |
| 例如: 1981-2003 | ||
| 326a | ||
| 326b | ||
| 3XX -3X9 -39X,327,330 | 每个子字段前缀是^ | |
| 3X9, 39X | 每个子字段前缀是^ | |
| 225a,e,i | 225 a : e . i | e前缀是^:^(^为空格) i前缀是.^ 225字段前缀是(后缀是) |
| 225v | ||
| 60Xa-z -23, 616a-z -23, 617a-z -23, 610a | 每个子字段前缀是^ | |
| 69X and 6X9 | 每个子字段前缀是^ | |
| 010a | ||
| 019 (Sudoc) | ||
| 011a,f | ||
| 011f 如果LDR/06不是l | ||
| /001 | ||
| 200b | ||
| 327a-z, 330a | 每个子字段前缀是^ | |
| LDR | ||
| 101a | ||
| 700a-z, 701a-z, 710a-z, 711a-z 如果$7存在且不等于ba | 由a到z显示全部子字段 | 70X 子字段 bc前缀是 ,^ 子字段 f 前缀是(后缀是) 所有其他子字段前缀都为^ 71X b is 前缀是.^ c 前缀是 .^ e 前缀是^;^ f前缀是 ^;^ 子字段def组合前缀是 (后缀是) - 注意,有3个子字段并非经常出现,有可能是(d) 或 (d ; f)或 (d ; e ; f) 等. 所有其他子字段前缀为^ |
| 500a-z 如果$7存在且不等于ba | m前缀是(后缀是), i如果在在h后,前缀是,。否则,i前缀是.^ 所有其它子字段(除子字段a)前缀是 .^ | |
| 200a,e如果$7存在且不等于ba | 200 a : e | e 前缀是^:^ (^为空格) |
| 200a,b,c,d,e,h,i,f,g 如果$7存在且不等于ba | 200 a [b] . c : e d .h, i /f ; g | b前缀为[后缀是] c 前缀是.^ d 不是前缀分号; 标点符号被编目在记录中 e的前缀为^:^ f 的前缀是^/^ g的前缀是^;^ h 的前缀是.^ i如果在h后前缀为逗号。否则,i前缀是点^ |
| 205 a 如果$7存在且不等于ba | ||
| 205a,b,f,g,如果$7存在且不等于ba | 205 a b / f ; g | f前缀是 ^/^ g前缀是 ^;^ |
| LDR/06 | ||
| LDR/07 | ||
| 200 $b | ||
| 100a/08 | ||
| 100a/09-12 | ||
| 100a/13-16 | ||
| 102a,c | ||
| 010a,z | ||
| 200a,b,c,d,e,h,i,f,g | 200 a [b] . c : e d .h, i /f ; g | b前缀为[后缀是] c 前缀是.^ d 不是前缀分号; 标点符号被编目在记录中 e的前缀为^:^ f 的前缀是^/^ g的前缀是^;^ h 的前缀是.^ i如果在h后前缀为逗号。否则,i前缀是点^ |
| 020a | ||
| 035a(1),z (2) | ||
| 700a-z, 701a-z, 710a-z, 711a-z | 由a到z显示全部子字段 | 70X 子字段 bc前缀是 ,^ 子字段 f 前缀是(后缀是) 所有其他子字段前缀都为^ 71X b is 前缀是.^ c 前缀是 .^ e 前缀是^;^ f前缀是 ^;^ 子字段def组合前缀是 (后缀是) - 注意,有3个子字段并非经常出现,有可能是(d) 或 (d ; f)或 (d ; e ; f) 等. 所有其他子字段前缀为^ |
| 410 a,t,o,h,i,x | 400 a t : o. h, i | h前缀是.^ i如果在在h后,前缀是,否则,i前缀是.^ o前缀是^:^ |
| 203a,b | ||
| 203c | ||
| 无匹配 | ||
| 126a,b | ||
| 125a,b | ||
| 115a,b | ||
| 135a, 230a | ||
| 无匹配 | ||
| 145a-i,146a-i |
处理多文本UNIMARC书目记录
拉丁语显示
- 200, 205, 206, 207, 208, 210
- 327
- 所有4XX字段:410, 411, 412, 413, 421, 422, 423, 424, 425, 430, 431, 432, 433, 434, 435, 436, 437, 440, 441, 442, 443, 444, 445, 446, 447, 448, 451, 452, 453, 454, 455, 456, 461, 463, 464, 470, 481, 482, 488
- 所有5XX字段:500, 501, 503, 510, 511, 512, 513, 514, 515, 516, 517, 518, 520, 530, 431, 532, 540, 541, 545
- 600, 601, 602, 605
- 所有7XX字段:700, 701, 702, 710, 711, 712, 716, 720, 721, 722
规范控制
- 规范 - 链接书目主题
- 规范 - 首选词更正
- F3
使用UNIMARC的多个访问点
创建KORMARC书目记录
- 打开元数据编辑器(资源 >编目> 打开元数据编辑器)。
- 打开默认书目模板(新建 > KORMARC书目)。
- 输入您的书目内容。 输入以下字段时,系统会在输入前三个字符后提供弹出窗口帮助:
- 260 $$a, b, e, f
- 264$b
- 505 $$r, t
- 561$a
与MARC 21书目记录类似,KORMARC书目记录的元数据编辑器使用提示选项卡提供KORMARC的验证支持。对KORMARC 008控制字段打开表单编辑器(编辑操作 > 打开表单编辑器)时,提供以下KORMARC字段选项:- 韩国政府机构
- 韩国大学
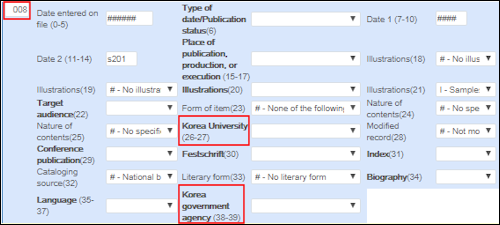 元数据编辑器中的KORMARC 008控制字段选项
元数据编辑器中的KORMARC 008控制字段选项 - 选择保存保存您的KORMARC书目记录。
在KORMARC书目记录中为090本地索书号字段自动生成著者号
- 090 $a - 从082 $a复制的杜威类号
- 090 $b - 著者号是从著者号的标准化列表中提取的,前缀包含作者姓氏的第一个字符和包含标题的第一个字符的后缀如G329w
- 090 $c - 年份从260 $c复制
- 在元数据编辑器中打开要添加090著者号的书目记录。
- 使100或700著者字段成为有效字段。
- 选择编辑操作 > 生成著者号(或按F4)。如果在著者号列表配置(配置菜单 > 资源 > 编目 > 著者号列表)中仅启用一个著者号列表,在著者号列表配置中标识的目标字段和子字段自动生成著者号。如果在著者号列表配置中启用多个著者号列表配置,系统提示选择著者号列表。
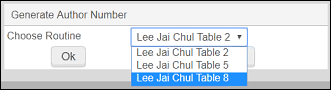 选择著者号列表有关更多信息,见配置标准著者号列表。
选择著者号列表有关更多信息,见配置标准著者号列表。 - 保存记录。
创建CNMARC书目记录
- 打开元数据编辑器(资源 >编目> 打开元数据编辑器)。
- 打开默认书目模板(新建 > CNMARC书目)。
- 输入您的书目内容。 与MARC 21书目记录类似,CNMARC书目记录的元数据编辑器使用“提示”选项卡提供CNMARC的验证支持。可以在CNMARC元数据配置文件中定制验证标准(见编辑验证例程)。
- 使用文件菜单或点击保存图标保存CNMARC书目记录。
为CNMARC 6XX字段使用多个接入点

创建都柏林核心元数据书目记录
- 打开元数据编辑器(资源 >编目> 打开元数据编辑器)。
- 选择新建 > 都柏林核心元数据。 元数据编辑器打开用于输入都柏林核心记录的模板。
- 输入您的都柏林核心记录的数据。欲知更多信息,见元数据编辑器菜单和工具栏选项。

合并书目记录
- 编目员扩展
- 订单行
- 电子资源库
- 电子资源库列表
- 纸本单册
- 数字化表现
- 外借
- 请求
- 阅读列表
- 相关记录关系(基于MMS ID)
当次级记录有在76X-78X字段含有次级记录的MMS ID的相关记录时,MMS ID在合并进程中更新为主记录的MMS ID以保持关系(并避免有没有父关系的相关记录)。
-
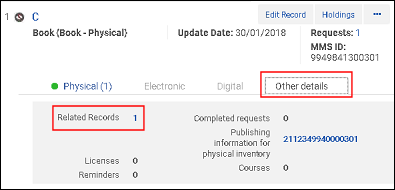
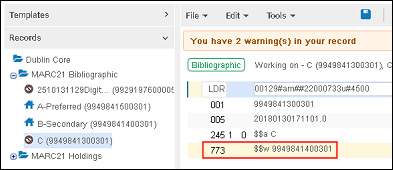 在合并前与次级记录关联的记录/MMS ID 在773$w中
在合并前与次级记录关联的记录/MMS ID 在773$w中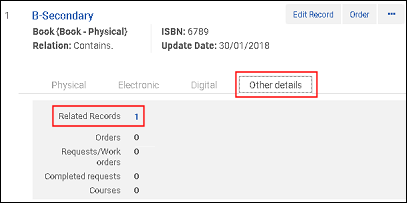 合并前关联记录中的次级记录
合并前关联记录中的次级记录
- 您只能在两个记录均为机构区记录或网络区记录时可以合并两个书目记录。您不能将机构区书目记录与网络区书目记录合并。
- 有关从次级记录提取标识符并在合并时放在主记录中的信息,见配置书目重定向字段。
- 在网络区合并书目记录时,进程检查非首选书目记录是否由其他成员保留。如果该情况发生,进程会移动全部成员的馆藏到首选书目记录。这种情况下,如果非首选记录屏蔽,该屏蔽设置也会由首选记录继承。
- 查找要合并的两个书目记录。主记录将更新来自次级记录的信息。
- 编辑这两个记录,使它们都显示在元数据编辑器的记录选项卡下。
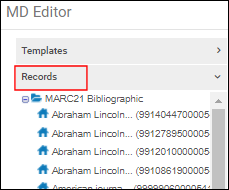
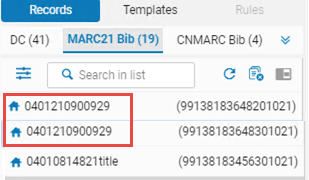 记录选项卡下的书目记录
记录选项卡下的书目记录 - 从记录选项卡下的导航面板中,选择主记录。
- 点击拆分编辑器图标,然后点击次要记录,使其显示在右侧(见下例)。
- 选择记录操作 > 合并记录与合并馆藏。
合并记录与合并馆藏对话框显示。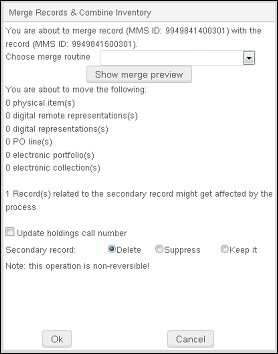 合并时,要移动的二级(非首选)记录的馆藏只有在有本地记录时显示在计数器中。这在以下情况下均为真:
合并时,要移动的二级(非首选)记录的馆藏只有在有本地记录时显示在计数器中。这在以下情况下均为真:
- 如果登录的机构有网络记录的本地(缓存)版本,且有馆藏。
- 在独立机构中执行合并时,两个记录在任何情况下均为本地。 - 查看显示的消息。特别注意,这个操作是不可逆的。 在您即将移动下列项目中,系统列出合并后的更改。此外,附加到次级记录的馆藏请求、外借和阅读列表将被更新。另外,在与次级记录关联的记录中,关联记录的76X-78X字段中的MMS ID会在合并记录与合并馆藏进程中更改为主记录的MMS ID。如果有请求,则显示请求数。由于技术限制,当没有请求时,对话框不显示“0请求”;相反,请求行根本不出现。
- 从下拉列表中选择合并进程。出现在列表中的合并进程从元数据编辑器中的规则选项卡下的合并规则列表中提取。
- 要预览合并结果,点击 显示合并预览。点击 确定 关闭合并预览.
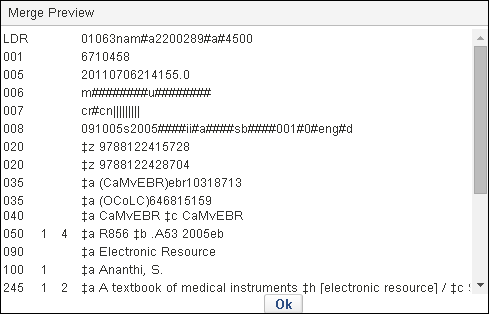 合并预览
合并预览 - 可选择 更新馆藏索书号。当您选择此选项时,系统会更新与主记录相关联的所有馆藏索书号信息(使用书目索书号)。该更改应用于书目合并之后与主记录关联的馆藏。请注意,如果在书目记录中更新了其中一个索书号字段,则这可能会影响最终出现在馆藏记录中的索书号。
- 从以下选项中选择您要如何处理次要书目记录(合并后):
- 删除
- 屏蔽
- 保留
- 当您准备合并这两个记录时点击确定。
管理书目记录
删除书目记录
- 编目员扩展
在元数据编辑器中可删除前,记录需要本地化。要这样做,见从机构区移除没有资源库列表的共享区书目记录。
用户可以从“机构”选项卡中删除网络区域书目记录(即使该记录源自共享区)。
标记为书目记录保留的记录不会被删除。有关详情,见书目记录保留。
- 从记录操作下的元数据编辑器工具栏选择删除书目记录。
仅当以下情况时可以删除书目记录:
-
没有订单行
-
关闭的订单行
-
取消的订单行
-
没有有效的采购请求
如果在机构区删除书目记录,且您是联盟中最后一个持有该记录的图书馆时,记录会在网络区中自动删除。如果不希望在网络区中自动删除记录,而是希望从网络区手动删除,设置delete_nz_bib_without_inventory客户参数(配置 > 资源 > 通用 > 其他设置)为false(见配置其他设置(资源管理))。
删除来自共享区的书目记录时,系统会向用户显示一条通知消息,表明不会删除共享区记录,而只会删除本地记录。
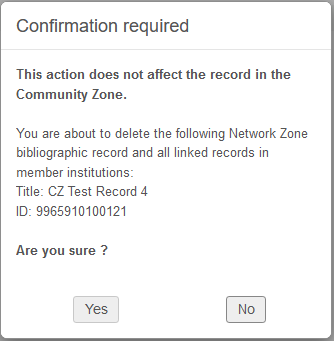
删除书目记录结果集
- 编目管理员
- 编目经理
- 运行删除书目记录作业。由于上述条件之一而无法删除的记录在作业报告中标识。
如果要删除与这些记录关联的馆藏,选择“删除全部相关的馆藏资源”。
书目记录保留
Alma使图书馆能够防止删除书目记录。为实现此功能,可配置书目资源库保留定义表(配置菜单 > 资源 > 馆藏保留 > 书目馆藏保留定义)。管理员可以指定记录保留条件。添加字段和子字段,以便在子字段包含任何值时保护记录不被删除。或者,指定特定值,仅保留子字段中具有该值的记录。

配置该表后,Alma会在尝试删除书目记录时执行验证。它验证记录是否包含表中的指定内容。如果内容存在,则书目记录将受到保护,不会被删除。此外,表更新后,任何符合定义条件的记录都将被标记为已提交,以便在下次索引时(更改和保存时,或每半年重新索引期间)保留。这样就可以在系统内检索保留的记录。
标记为用于保留的记录会显示“用于保留”图标(![]() ),表示该记录受到删除保护。
),表示该记录受到删除保护。
对于网络区记录,根据网络区表中指定的配置确定保留政策。当尝试删除链接到共享区的书目记录时,从本地机构删除链接记录受到限制,具体取决于该机构设置的特定配置。本地扩展字段不能作为保留字段。在机构区中使用的非本地扩展字段可以用作保留字段。
在处理书目记录时使用关联数据
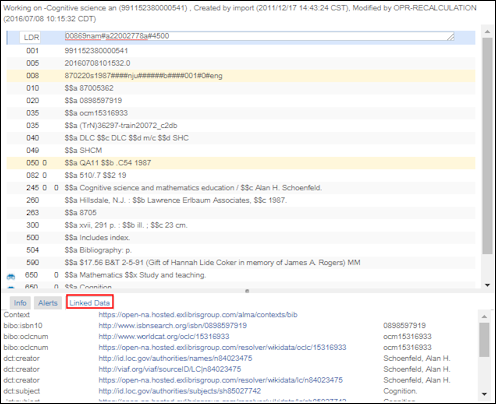
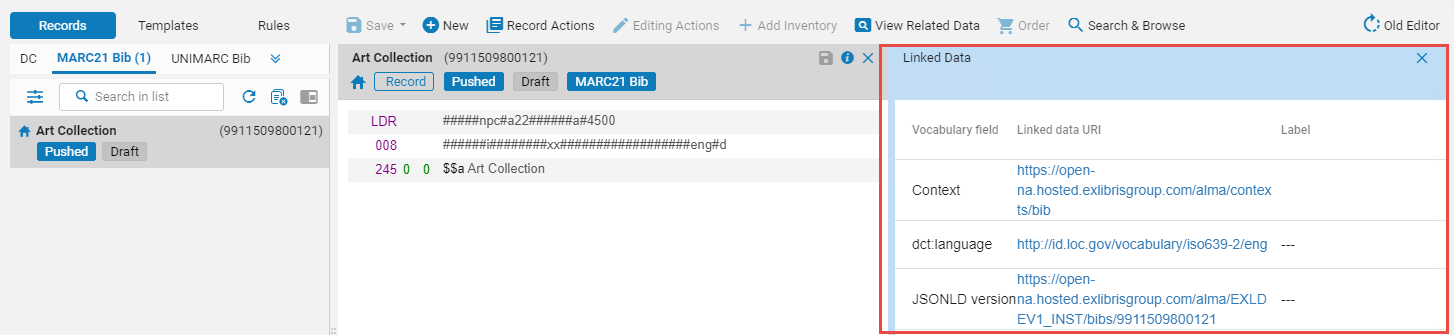
- 词汇字段 - 这是通过上下文进行的。默认上下文为cname.alma.exlibrisgroup.com/[format]/[works_or_instances]/[MMSID]。例如,bgu.alma.exlibrisgroup.com/bf/instances/9922819700121。
如果有含有上下文路径的有效关联数据集成配置文件(见关联数据),则使用此上下文。任何以前的Alma URI格式都会重定向到新的Alma URI格式:cname.alma.exlibrisgroup.com/[format]/[works_or_instances]/[MMSID]。
如果机构希望,他们可以将网址的开头(URL前缀)从cname.alma.exlibrisgroup.com更改为自己的前缀或任何其他前缀。例如,bgu.ac.il。此更改可以在链接的数据集成配置文件中进行,只要该机构的IT部门将域名注册到同一IP地址,记录就会得到解析。不必为了从Alma仓储检索结果中访问管理数据而创建管理数据集成配置文件。然而,需要以JSON-LD格式显示链接数据(更多信息见 链接数据)。 - 关联数据URI 链接到IdRef规范的书目记录的关联数据现在也会生成IdRef规范记录的URI。
- 标签 - 对于ISBN、ISSN和OCLC,显示字段内容。对于创建者和主题,将显示主题的值。
处理UTF完整/分解Unicode表现(UTF-8和有附加符号的字符)
Alma支持在保存书目或规范记录时规范化分解的字符到完整的形式。
例如,单词Amélie可以有两种相同的Unicode形式:
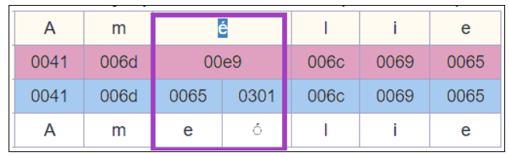
通过该功能,当保存含有这些字符的记录时,分解的形式(0065+0301)会规范化为完整的形式(00e9)。
当设置Alma处理UTF组成/分解Unicode表现时,也可以避免处理首选词校正作业的更新。在书目记录的主题和规范主题有相同的UTF表现时(完整和分解),PTC跳过校正。这会过滤掉规范任务控制列表的冗余更新并直接发布。
请注意,这可以对全部Alma记录定义,也可以对特定本地词汇定义。
该功能默认禁用。联系Ex Libris人员启用。